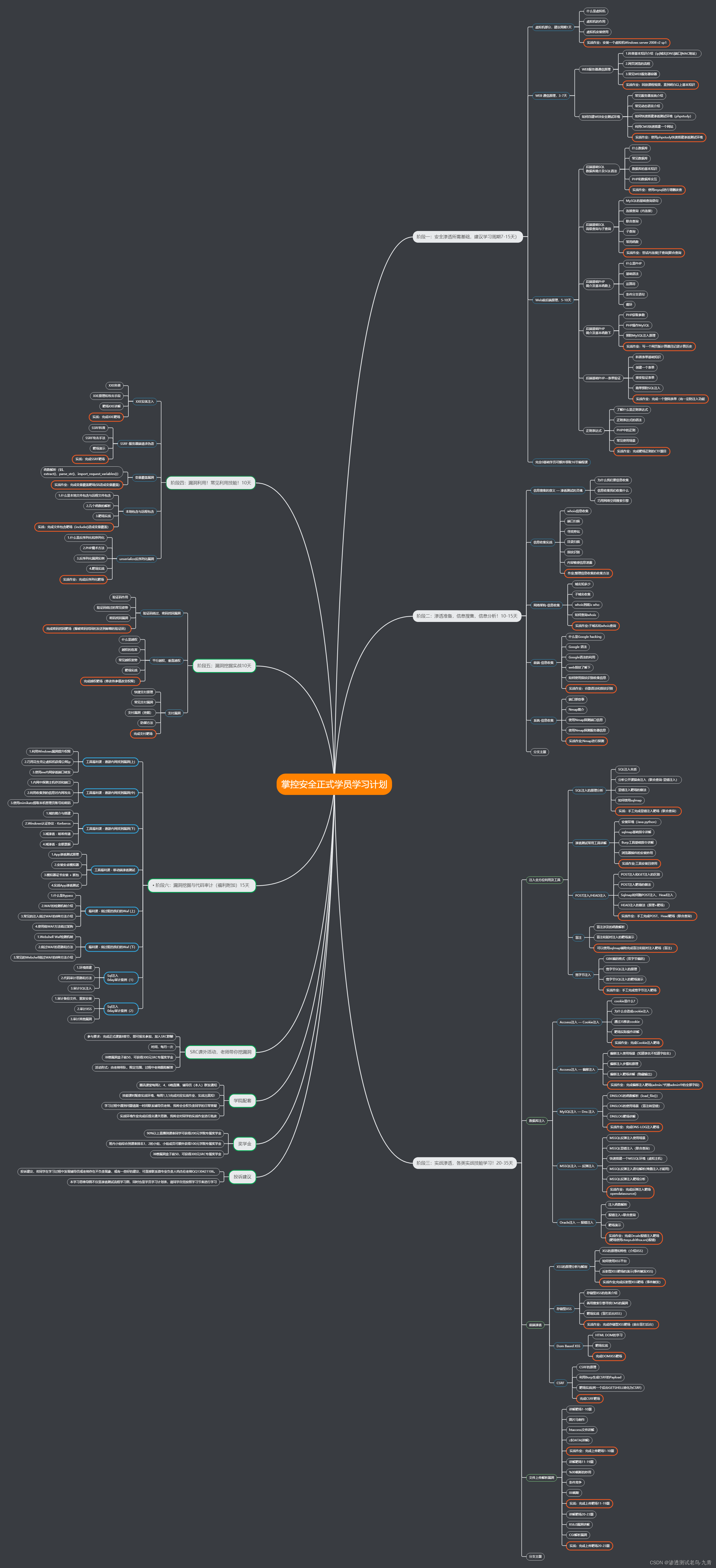
文章目录
- 1.简单感知器分类模型
- 1.1.简单感知器分类模型介绍
- 1.2.简单感知器分类模型实现
- 2线性神经元分类模型
- 2.1.线性神经元分类模型介绍
- 2.2.线性神经元分类模型实现
- 3.基于遍历学习的神经网络计算模型
- 3.1.基于遍历学习的神经网络计算模型介绍
- 3.2.基于遍历学习的神经网络计算模型实现
- 4.基于批量学习的神经网络计算模型}
- 4.1.基于批量学习的神经网络计算模型介绍
- 4.2基于批量学习的神经网络计算模型实现
- 5.BP神经网络回归模型}
- 5.1.BP神经网络回归模型介绍
- 5.1.1.BP神经网络的特点
- 5.1.2.BP神经网络的链式求导法则
- 5.2.BP神经网络回归模型实现
1.简单感知器分类模型
1.1.简单感知器分类模型介绍
假设
n
n
n 维输入连接描述
n
n
n 个输入变量
x
1
x_1
x1,
x
2
x_2
x2,…,
x
n
x_n
xn。输人向量
x
x
x 是
{
x
1
\{x_1
{x1,
x
2
,
⋯
,
x
n
}
x_2,\cdots,x_n\}
x2,⋯,xn},相应的权值向量w 是
{
w
1
,
\{w_1,
{w1,
w
2
,
.
.
.
,
w
n
}
w_2,...,w_n\}
w2,...,wn}。对一个输入向量
x
x
x 相应的网络输入
u
u
u为:
u
=
w
1
x
1
+
w
2
x
2
+
⋯
+
w
n
x
n
u=w_{1}x_{1}+w_{2}x_{2}+\cdots+w_{n}x_{n}
u=w1x1+w2x2+⋯+wnxn
起始设置阈值函数sgn产生一个y值的输出如下所示:
y
=
s
g
n
(
u
)
=
{
0
u
<
0
1
u
≥
0
\left.y=sgn(u)=\left\{\begin{matrix}0&u<0\\1&u\ge0\end{matrix}\right.\right.
y=sgn(u)={01u<0u≥0
如果这个分类是正确的,这个感知器就已经分类正确率,如果分类是错误的,那么就还需要进行对应的调整其他的权值使其分类正确,基于Hebbian学习的改进形式的误差公式如下所示:
E
r
r
o
r
=
E
=
t
−
y
\mathrm{Error}=E=t-y
Error=E=t−y
其中t表示标签值,y表示阈值函数的分类值,基于此方法进行权值的更新如下所示:
w
n
e
w
=
w
o
l
d
+
β
x
E
\begin{array}{rcl}w_\mathrm{new}&=&w_\mathrm{old}+\beta xE\\\end{array}
wnew=wold+βxE
基于上述公式进行化简得到:
w
n
e
w
=
{
w
o
l
d
E
=
0
(
即
t
=
y
)
w
o
l
d
+
β
x
E
=
1
(
即
t
=
1
,
y
=
0
)
(
规则
1
)
w
o
l
d
−
β
x
E
=
−
1
(
即
t
=
0
,
y
=
1
)
(
规则
2
)
w_{_{new}}=\begin{cases}w_{_{old}}&E=0(\text{即}t=y)\\w_{_{old}}+\beta x&E=1(\text{即}t=1,y=0)(\text{规则}1)\\w_{_{old}}-\beta x&E=-1(\text{即}t=0,y=1)(\text{规则}2)\end{cases}
wnew=⎩
⎨
⎧woldwold+βxwold−βxE=0(即t=y)E=1(即t=1,y=0)(规则1)E=−1(即t=0,y=1)(规则2)
其中, w o l d w_{old} wold是老权重, w n e w w_{new} wnew是新权重, β \beta β是学习率。
1.2.简单感知器分类模型实现
如图所示,我们利用这样的一个感知器去进行简单的分类任务.

我们设定
β
=
0.5
\beta=0.5
β=0.5,我们设置最初的权值:
w
1
0
=
0.8
,
w
2
0
=
−
0.5
w_{1}^{0}= 0.8,w_{2}^{0}= -0.5
w10=0.8,w20=−0.5,接下来我们进行简单感知器的分类计算:
第一个点的计算:1-A1:
x
1
=
0.3
,
x
2
=
0.7
,
t
=
1
,
w
1
0
=
0.8
,
w
2
0
=
−
0.5.
x_{1}=0.3,x_{2}=0.7,t=1,w_{1}^{0}= 0.8,w_{2}^{0}= -0.5.
x1=0.3,x2=0.7,t=1,w10=0.8,w20=−0.5.
u
=
(
0.8
)
(
0.3
)
+
(
−
0.5
)
(
0.7
)
=
−
0.11
u
<
0
⇒
y
=
0
\begin{array}{rl}u=(0.8)(0.3)+(-0.5)(0.7)=-0.11\\u<0\Rightarrow y=0\end{array}
u=(0.8)(0.3)+(−0.5)(0.7)=−0.11u<0⇒y=0
此时分类错误,所以我们需要进行权重的调整,由于此时E=t-y=1-0=1,那么权值更新如下所示:
Δ
w
1
1
=
β
x
1
=
(
0.5
)
(
0.3
)
=
0.15
Δ
w
2
1
=
β
x
2
=
(
0.5
)
(
0.7
)
=
0.35
\begin{array}{rcl}{\Delta w_{1}^{1}=\beta x_{1}=(0.5)(0.3)=0.15}\\{\Delta w_{2}^{1}=\beta x_{2}=(0.5)(0.7)=0.35}\end{array}
Δw11=βx1=(0.5)(0.3)=0.15Δw21=βx2=(0.5)(0.7)=0.35
再进行更新即对应的权值如下所示:
w
1
1
=
w
1
0
+
Δ
w
1
1
=
0.8
+
0.15
=
0.95
w
2
1
=
w
2
0
+
Δ
w
2
1
=
−
0.5
+
0.35
=
−
0.15
\begin{array}{rcl}{w_{1}^{1}=w_{1}^{0}+\Delta w_{1}^{1}=0.8+0.15=0.95}\\{w_{2}^{1}=w_{2}^{0}+\Delta w_{2}^{1}=-0.5+0.35=-0.15}\end{array}
w11=w10+Δw11=0.8+0.15=0.95w21=w20+Δw21=−0.5+0.35=−0.15
所以更新之后的权值为: w 1 0 = 0.95 , w 2 0 = − 0.15 , w = [ 0.95 , − 0.15 ] . w_{1}^{0}= 0.95,w_{2}^{0}= -0.15,w=[0.95,-0.15]. w10=0.95,w20=−0.15,w=[0.95,−0.15].
再次代入计算,如下所示:
u
=
(
0.3
)
(
0.95
)
+
(
0.7
)
(
−
0.15
)
=
0.18
>
0
⇒
y
=
1
⇒
分类正确。
\begin{aligned}u&=\left(0.3\right)\left(0.95\right)+\left(0.7\right)\left(-0.15\right)=0.18>0\\&\Rightarrow y=1\Rightarrow\text{分类正确。}\end{aligned}
u=(0.3)(0.95)+(0.7)(−0.15)=0.18>0⇒y=1⇒分类正确。
接下来我们用这个权值进行下一个的计算:
第二个点的计算:2-B1:
x
1
=
−
0.6
,
x
2
=
0.3
,
t
=
0
,
w
1
0
=
0.95
,
w
2
0
=
−
0.15.
x_{1}=-0.6,x_{2}=0.3,t=0,w_{1}^{0}= 0.95,w_{2}^{0}= -0.15.
x1=−0.6,x2=0.3,t=0,w10=0.95,w20=−0.15.
u
=
(
−
0.6
)
(
0.95
)
+
(
0.3
)
(
−
0.15
)
=
−
0.615
u
<
0
⇒
y
=
0
\begin{array}{rl}u=(-0.6)(0.95)+(0.3)(-0.15)=-0.615\\u<0\Rightarrow y=0\end{array}
u=(−0.6)(0.95)+(0.3)(−0.15)=−0.615u<0⇒y=0
此时分类正确,不需要再进行权值修正。
第三个点的计算:2-B2:
x
1
=
−
0.1
,
x
2
=
−
0.8
,
t
=
0
,
w
1
0
=
0.95
,
w
2
0
=
−
0.15.
x_{1}=-0.1,x_{2}=-0.8,t=0,w_{1}^{0}= 0.95,w_{2}^{0}= -0.15.
x1=−0.1,x2=−0.8,t=0,w10=0.95,w20=−0.15.
u
=
(
−
0.1
)
(
0.95
)
+
(
−
0.8
)
(
−
0.15
)
=
0.025
u
>
0
⇒
y
=
1
\begin{array}{rl}u=(-0.1)(0.95)+(-0.8)(-0.15)=0.025\\u>0\Rightarrow y=1\end{array}
u=(−0.1)(0.95)+(−0.8)(−0.15)=0.025u>0⇒y=1
此时分类不正确,需要再进行权值修正。那么权值更新如下所示:
Δ
w
1
2
=
−
β
x
1
=
−
(
0.5
)
(
−
0.1
)
=
0.05
Δ
w
2
2
=
−
β
x
2
=
−
(
0.5
)
(
−
0.8
)
=
0.4
\begin{array}{rcl}{\Delta w_{1}^{2}=-\beta x_{1}=-(0.5)(-0.1)=0.05}\\{\Delta w_{2}^{2}=-\beta x_{2}=-(0.5)(-0.8)=0.4}\end{array}
Δw12=−βx1=−(0.5)(−0.1)=0.05Δw22=−βx2=−(0.5)(−0.8)=0.4
再进行更新即对应的权值如下所示:
w
1
2
=
w
1
1
+
Δ
w
1
2
=
0.95
+
0.05
=
1.0
w
2
2
=
w
2
1
+
Δ
w
2
2
=
−
0.15
+
0.4
=
0.25
\begin{array}{rcl}{w_{1}^{2}=w_{1}^{1}+\Delta w_{1}^{2}=0.95+0.05=1.0}\\{w_{2}^{2}=w_{2}^{1}+\Delta w_{2}^{2}=-0.15+0.4=0.25}\end{array}
w12=w11+Δw12=0.95+0.05=1.0w22=w21+Δw22=−0.15+0.4=0.25
所以更新之后的权值为: w 1 0 = 1.0 , w 2 0 = 0.25 , w = [ 1.0 , 0.25 ] . w_{1}^{0}= 1.0,w_{2}^{0}= 0.25,w=[1.0,0.25]. w10=1.0,w20=0.25,w=[1.0,0.25].
代入计算,结果表示分类正确。
第四个点的计算:1-A2:
x
1
=
0.1
,
x
2
=
−
0.45
,
t
=
1
,
w
1
2
=
1.0
,
w
2
2
=
0.25.
x_{1}=0.1,x_{2}=-0.45,t=1,w_{1}^{2}= 1.0,w_{2}^{2}= 0.25.
x1=0.1,x2=−0.45,t=1,w12=1.0,w22=0.25.
u
=
(
0.1
)
(
1.0
)
+
(
−
0.45
)
(
0.25
)
=
−
0.0125
u
<
0
⇒
y
=
0
\begin{array}{rl}u=(0.1)(1.0)+(-0.45)(0.25)=-0.0125\\u<0\Rightarrow y=0\end{array}
u=(0.1)(1.0)+(−0.45)(0.25)=−0.0125u<0⇒y=0
此时分类不正确,需要再进行权值修正。那么权值更新如下所示:
Δ
w
1
3
=
−
β
x
1
=
(
0.5
)
(
0.1
)
=
0.05
Δ
w
2
3
=
−
β
x
2
=
−
(
0.5
)
(
−
0.45
)
=
−
0.225
\begin{array}{rcl}{\Delta w_{1}^{3}=-\beta x_{1}=(0.5)(0.1)=0.05}\\{\Delta w_{2}^{3}=-\beta x_{2}=-(0.5)(-0.45)=-0.225}\end{array}
Δw13=−βx1=(0.5)(0.1)=0.05Δw23=−βx2=−(0.5)(−0.45)=−0.225
再进行更新即对应的权值如下所示:
w
1
3
=
w
1
2
+
Δ
w
1
3
=
1.0
+
0.05
=
1.05
w
2
3
=
w
2
2
+
Δ
w
2
3
=
0.25
−
0.025
=
0.025
\begin{array}{rcl}{w_{1}^{3}=w_{1}^{2}+\Delta w_{1}^{3}=1.0+0.05=1.05}\\{w_{2}^{3}=w_{2}^{2}+\Delta w_{2}^{3}=0.25-0.025=0.025}\end{array}
w13=w12+Δw13=1.0+0.05=1.05w23=w22+Δw23=0.25−0.025=0.025
所以更新之后的权值为: w 1 3 = 1.05 , w 2 0 = 0.025 , w = [ 1.05 , 0.025 ] . w_{1}^{3}= 1.05,w_{2}^{0}= 0.025,w=[1.05,0.025]. w13=1.05,w20=0.025,w=[1.05,0.025].
所以最终的权重向量为: w = [ 1.05 , 0.025 ] w=[1.05,0.025] w=[1.05,0.025]
我们给出最后的分界线为:
u
=
w
1
x
1
+
w
2
x
2
=
0
x
2
=
−
(
w
1
w
2
)
x
1
\begin{aligned}u&=w_1x_1+w_2x_2=0\\x_2&=-\left(\frac{w_1}{w_2}\right)x_1\end{aligned}
ux2=w1x1+w2x2=0=−(w2w1)x1
最终的方程表示为:
x
2
=
−
42
x
1
x_{2}=-42x_{1}
x2=−42x1
2线性神经元分类模型
2.1.线性神经元分类模型介绍
线性分类器是基于delta规则的学习,假设神经元的输入描述,首先计算网络输出u和输出y,为:
u
=
w
1
x
y
=
u
=
w
1
x
\begin{aligned}u&=w_1x\\y&=u=w_1x\end{aligned}
uy=w1x=u=w1x
对应的误差E表示为:
E
=
t
−
y
=
t
−
w
1
x
E=t-y=t-w_{1}x
E=t−y=t−w1x
利用
ϵ
\epsilon
ϵ来衡量对应的评分误差,计算如下所示:
ε
=
1
2
E
2
=
1
2
(
t
−
w
1
x
)
2
\varepsilon=\frac{1}{2}E^{2}=\frac{1}{2}(t-w_{1}x)^{2}
ε=21E2=21(t−w1x)2
对于权重的更新如下所示:
d
ε
d
w
1
=
2
2
(
t
−
y
)
(
−
x
)
=
−
E
x
\frac{\mathrm{d}\boldsymbol{\varepsilon}}{\mathrm{d}\boldsymbol{w}_{1}}=\frac{2}{2}(t-y)(-x)=-Ex
dw1dε=22(t−y)(−x)=−Ex
增加学习率的因素,权值变化量就变为了:
Δ
w
1
=
β
E
x
\Delta w_{1}=\beta Ex
Δw1=βEx
将这种思想引入到神经网络后,进行迭代更新之后的新权值如下所示:
w
0
i
+
1
=
w
0
i
w
j
i
+
1
=
w
j
i
+
β
x
j
E
\begin{array}{rcl}w_{0}^{i+1}&=&w_{0}^{i}\\w_{j}^{i+1}&=&w_{j}^{i}+\beta x_{j}E\end{array}
w0i+1wji+1==w0iwji+βxjE
对于整个模型的误差衡量,用MSE来进行计算,如下所示:
M
S
E
=
1
2
n
∑
i
=
1
n
E
i
2
\mathbf{MSE}=\frac{1}{2n}\sum_{i=1}^{n}E_{i}^{2}
MSE=2n1i=1∑nEi2
2.2.线性神经元分类模型实现
题目如同第一题所示,我们来对比线性神经网络和简单感知器的计算速度和方式区别,对应的题目图和网络图如下所示:

其中权重更新的计算过程与公式如下所示:
u
=
w
1
x
1
+
w
2
x
2
y
=
u
E
=
t
−
y
Δ
w
=
β
E
x
w
new
=
w
old
+
Δ
w
\begin{array}{l} u=w_{1} x_{1}+w_{2} x_{2} \\ y=u \\ E=t-y \\ \Delta w=\beta E x \\ w_{\text {new }}=w_{\text {old }}+\Delta w \end{array}
u=w1x1+w2x2y=uE=t−yΔw=βExwnew =wold +Δw
∙
\bullet
∙第一个点的计算:1-A1:
x
1
=
0.3
,
x
2
=
0.7
,
t
=
1
,
w
1
0
=
0.8
,
w
2
0
=
−
0.5.
x_{1}=0.3,x_{2}=0.7,t=1,w_{1}^{0}= 0.8,w_{2}^{0}= -0.5.
x1=0.3,x2=0.7,t=1,w10=0.8,w20=−0.5.
u
=
(
0.8
)
(
0.3
)
+
(
−
0.5
)
(
0.7
)
=
−
0.11
u
<
0
⇒
y
=
u
=
−
0.11
<
0
\begin{array}{rl}u=(0.8)(0.3)+(-0.5)(0.7)=-0.11\\u<0\Rightarrow y=u=-0.11<0\end{array}
u=(0.8)(0.3)+(−0.5)(0.7)=−0.11u<0⇒y=u=−0.11<0
E
=
t
−
y
=
1
−
(
−
0.11
)
=
1.11
E=t-y=1-(-0.11)=1.11
E=t−y=1−(−0.11)=1.11
所以分类错误,需要进行权重更新,如下所示:
权重值增量:
Δ
w
1
1
=
(
0.5
)
(
1.11
)
(
0.3
)
=
0.1665
Δ
w
2
1
=
(
0.5
)
(
1.11
)
(
0.7
)
=
0.3885
\begin{aligned}\Delta w_{1}^{1}&=\left(0.5\right)\left(1.11\right)\left(0.3\right)=0.1665\\\Delta w_{2}^{1}&=\left(0.5\right)\left(1.11\right)\left(0.7\right)=0.3885\end{aligned}
Δw11Δw21=(0.5)(1.11)(0.3)=0.1665=(0.5)(1.11)(0.7)=0.3885
第一次更新之后的权重值:
w
1
1
=
0.8
+
0.1665
=
0.9665
w
2
1
=
−
0.5
+
0.3885
=
−
0.1115
\begin{aligned}w_{1}^{1}&=0.8+0.1665=0.9665\\w_{2}^{1}&=-0.5+0.3885=-0.1115\end{aligned}
w11w21=0.8+0.1665=0.9665=−0.5+0.3885=−0.1115
对应的权重向量为:
w
1
=
[
0.9965
,
−
0.1115
]
.
w^{1}=[0.9965,-0.1115].
w1=[0.9965,−0.1115].
∙ \bullet ∙第二个点的计算:2-B1:
x
1
=
−
0.6
,
x
2
=
0.3
,
t
=
0
,
w
1
0
=
0.9665
,
w
2
0
=
−
0.1115.
x_{1}=-0.6,x_{2}=0.3,t=0,w_{1}^{0}= 0.9665,w_{2}^{0}= -0.1115.
x1=−0.6,x2=0.3,t=0,w10=0.9665,w20=−0.1115.
u
=
(
−
0.6
)
(
0.9665
)
+
(
−
0.8
)
(
−
0.1115
)
=
−
0.61335
=
˘
−
0.61335
⇒
y
=
u
=
−
0.61335
<
0
\begin{array}{rl}u=(-0.6)(0.9665)+(-0.8)(-0.1115)=-0.61335\u=-0.61335 \Rightarrow y=u=-0.61335<0\end{array}
u=(−0.6)(0.9665)+(−0.8)(−0.1115)=−0.61335=˘−0.61335⇒y=u=−0.61335<0
第二个点是分类是正确的,不需要再进行权重更新。
∙
\bullet
∙第三个点的计算:2-B2:
x
1
=
−
0.1
,
x
2
=
−
0.8
,
t
=
0
,
w
1
0
=
0.9665
,
w
2
0
=
−
0.1115.
x_{1}=-0.1,x_{2}=-0.8,t=0,w_{1}^{0}= 0.9665,w_{2}^{0}= -0.1115.
x1=−0.1,x2=−0.8,t=0,w10=0.9665,w20=−0.1115.
u
=
(
−
0.1
)
(
0.9665
)
+
(
−
0.8
)
(
−
0.1115
)
=
−
0.00745
=
˘
−
0.00745
⇒
y
=
u
=
−
0.00745
<
0
\begin{array}{rl}u=(-0.1)(0.9665)+(-0.8)(-0.1115)=-0.00745\u=-0.00745\Rightarrow y=u=-0.00745<0\end{array}
u=(−0.1)(0.9665)+(−0.8)(−0.1115)=−0.00745=˘−0.00745⇒y=u=−0.00745<0
第三个点是分类是正确的,不需要再进行权重更新。
∙
\bullet
∙第四个点的计算:1-A2:
x
1
=
0.1
,
x
2
=
−
0.45
,
t
=
1
,
w
1
0
=
0.9665
,
w
2
0
=
−
0.1115.
x_{1}=0.1,x_{2}=-0.45,t=1,w_{1}^{0}= 0.9665,w_{2}^{0}= -0.1115.
x1=0.1,x2=−0.45,t=1,w10=0.9665,w20=−0.1115.
u
=
(
0.1
)
(
0.9665
)
+
(
−
0.45
)
(
−
0.1115
)
=
0.1468
=
˘
0.1468
⇒
y
=
u
=
0.1468
>
0
\begin{array}{rl}u=(0.1)(0.9665)+(-0.45)(-0.1115)=0.1468\u=0.1468\Rightarrow y=u=0.1468>0\end{array}
u=(0.1)(0.9665)+(−0.45)(−0.1115)=0.1468=˘0.1468⇒y=u=0.1468>0
第四个点是分类也是正确的,不需要再进行权重更新。
线性神经元将所有四个模式进行了正确地分类。结果说明对于这个简单的分类任务,使用delta 规则训练的线性神经元,可以比感知器更快地找到最好的权值。这是因为误差的计算是基于线性神经元的输出y而不是基于值函数sgn(x)的输出y。
令y=0且y=u,所以对应的决策面方程如下所示:
y
=
u
=
w
1
x
1
+
w
2
x
2
=
0
x
2
=
−
(
w
1
x
1
)
/
w
2
\begin{array}{rcl}{y=u=w_{1}x_{1}+w_{2}x_{2}=0}\\{x_{2}=-(w_{1}x_{1})/w_{2}}\end{array}
y=u=w1x1+w2x2=0x2=−(w1x1)/w2
代入计算如下所示:
x
2
=
−
(
0.9665
x
1
)
/
(
−
0.1115
)
x
2
=
8.67
x
1
\begin{aligned}x_2&=-(0.9665x_1)/(-0.1115)\\x_2&=8.67x_1\end{aligned}
x2x2=−(0.9665x1)/(−0.1115)=8.67x1
3.基于遍历学习的神经网络计算模型
3.1.基于遍历学习的神经网络计算模型介绍
遍历学习就是在每一次输入模式表达之后就进行权重的更新的调整方式叫做遍历学习即权重在每次计算之后就能够得到更新。
遍历学习的权重计算公式如下所示:
u
=
w
1
x
1
+
w
2
x
2
y
=
u
E
=
t
−
y
Δ
w
=
β
E
x
w
new
=
w
old
+
Δ
w
\begin{array}{l} u=w_{1} x_{1}+w_{2} x_{2} \\ y=u \\ E=t-y \\ \Delta w=\beta E x \\ w_{\text {new }}=w_{\text {old }}+\Delta w \end{array}
u=w1x1+w2x2y=uE=t−yΔw=βExwnew =wold +Δw
3.2.基于遍历学习的神经网络计算模型实现
如下所示,给出对应的数据点,请你给出利用线性神经网络进行逼近的线性方程.

由于第1个点(0,0)就已经确定了y=kx+b中的b为0,所以b对于整体学习没有什么影响,所以之后我们从x=1进行计算求解,我们依然设 w 0 = 0.5 , β = 0.1 w_{0}=0.5,\beta=0.1 w0=0.5,β=0.1。
∙ \bullet ∙对于第一个点: x = 1 x=1 x=1, y = 0.75 y=0.75 y=0.75。
进行遍历学习如下所示:
E
=
t
−
y
=
0.75
−
0.5
=
0.25
w
1
=
w
+
β
x
E
=
0.5
+
0.1
×
0.25
×
1
=
0.5
+
0.025
=
0.525
\begin{aligned} E&=t-y=0.75-0.5=0.25\\ w^1&=w+\beta xE=0.5+0.1\times0.25\times1=0.5+0.025=0.525 \end{aligned}
Ew1=t−y=0.75−0.5=0.25=w+βxE=0.5+0.1×0.25×1=0.5+0.025=0.525
∙ \bullet ∙对于第二个点: x = 2 x=2 x=2, y = w 1 x = 0.525 ∗ 2 = 1.05 y=w^{1}x=0.525*2=1.05 y=w1x=0.525∗2=1.05。
进行遍历学习如下所示:
E
=
t
−
y
=
1.53
−
1.05
=
0.48
w
2
=
w
1
+
β
x
E
=
0.5
+
0.1
×
0.48
×
2
=
0.525
+
0.096
=
0.621
\begin{aligned} E&=t-y=1.53-1.05=0.48\\ w^2&=w^1+\beta xE=0.5+0.1\times0.48\times2=0.525+0.096=0.621 \end{aligned}
Ew2=t−y=1.53−1.05=0.48=w1+βxE=0.5+0.1×0.48×2=0.525+0.096=0.621
∙ \bullet ∙对于第三个点: x = 3 x=3 x=3, y = w 2 x = 0.621 ∗ 3 = 1.863 y=w^{2}x=0.621*3=1.863 y=w2x=0.621∗3=1.863。
进行遍历学习如下所示:
y
=
0.621
×
3
=
1.863
E
=
2.34
−
1.863
=
0.477
w
3
=
0.621
+
0.1
×
0.477
×
3
=
0.621
+
0.1431
=
0.7641
\begin{aligned}y&=0.621\times3=1.863\\E&=2.34-1.863=0.477\\w^3&=0.621+0.1\times0.477\times3=0.621+0.1431=0.7641\end{aligned}
yEw3=0.621×3=1.863=2.34−1.863=0.477=0.621+0.1×0.477×3=0.621+0.1431=0.7641
∙ \bullet ∙对于第四个点: x = 3 x=3 x=3, y = w 3 x = 0.7641 ∗ 4 = 3.0564 y=w^{3}x=0.7641*4=3.0564 y=w3x=0.7641∗4=3.0564。
进行遍历学习如下所示:
y
=
0.7641
×
4
=
3.0564
E
=
3.2
−
3.0564
=
0.1436
w
4
=
0.7641
+
0.1
×
0.1436
×
4
=
0.7641
+
0.05744
=
0.8215
\begin{gathered} y=0.7641\times4=3.0564 \\ E=3.2-3.0564=0.1436 \\ w^{4}=0.7641+0.1\times0.1436\times4=0.7641+0.05744=0.8215 \end{gathered}
y=0.7641×4=3.0564E=3.2−3.0564=0.1436w4=0.7641+0.1×0.1436×4=0.7641+0.05744=0.8215
w 4 = 0.8215 w^{4}=0.8215 w4=0.8215已经很接近参考值0.8了,所以我们认为遍历学习的方法整体是比较不错的。
4.基于批量学习的神经网络计算模型}
4.1.基于批量学习的神经网络计算模型介绍
批量学习就是当所有的输入模式都处理完之后,再进行一个平均意义上的权重调整,这个就是批量学习,目标就是需要去减少整个模式的平均误差。
批量学习的权重更新计算公式如下所示:
u
=
w
1
x
1
+
w
2
x
2
y
=
u
E
=
t
−
y
Δ
w
=
β
(
1
n
∑
i
=
1
n
E
i
x
i
)
w
n
e
w
=
w
o
l
d
+
Δ
w
\begin{aligned} &u=w_1x_1+w_2x_2 \\ &\boldsymbol{y}=\boldsymbol{u} \\ &E=t-y \\ &\Delta w=\beta\Big(\frac1n\sum_{i=1}^{n}E_ix_i\Big) \\ &w_{\mathtt{new}}=w_{\mathtt{old}}+\Delta w \end{aligned}
u=w1x1+w2x2y=uE=t−yΔw=β(n1i=1∑nEixi)wnew=wold+Δw
批量学习与遍历学习的算法计算上唯一不同的就是对于 Δ w \Delta w Δw的更新方式不同。
4.2基于批量学习的神经网络计算模型实现
题目与第三题的题目相同,用对比两个算法的差异。
由于第1个点(0,0)就已经确定了y=kx+b中的b为0,所以b对于整体学习没有什么影响,所以之后我们从x=1进行计算求解,我们依然设 w 0 = 0.5 , β = 0.1 w_{0}=0.5,\beta=0.1 w0=0.5,β=0.1。
我们分别将整体更新一次记作一个周期,每次周期中分别计算当时权重下的y和E值,最后进行均值的计算。
第一周期:
1
◯
x
1
=
1
,
y
1
=
0.5
×
1
=
0.5
,
E
1
=
t
−
y
1
=
0.25
2
◯
x
2
=
2
,
y
2
=
0.5
×
2
=
1
,
E
2
=
t
−
y
2
=
0.53
3
◯
x
3
=
3
,
y
3
=
0.5
×
3
=
1.5
,
z
3
=
t
−
y
3
=
0.84
4
◯
x
4
=
4
,
y
4
=
0.5
×
4
=
2
,
E
4
=
t
−
y
4
=
1.2
Δ
w
1
=
β
(
1
n
∑
i
=
1
n
E
i
X
i
)
=
0.1
×
1
4
(
0.25
×
1
+
0.53
×
2
+
0.84
×
3
+
1.2
×
4
)
=
0.2158
w
1
=
w
+
Δ
w
1
=
0.5
+
0.2158
=
0.7158
\begin{aligned}\text{第一周期:}&\quad\\ \textcircled{1}&\quad x_1=1,\quad y_1=0.5\times1=0.5,E_1=t-y_1=0.25\\ \textcircled{2}&\quad x_2=2,\quad y_2=0.5\times2=1,E_2=t-y_2=0.53\\ \textcircled{3}&\quad x_3=3,\quad y_3=0.5\times3=1.5,z_3=t-y_3=0.84\\ \textcircled{4}&\quad x_4=4,\quad y_4=0.5\times4=2,E_4=t-y_4=1.2\\&\quad\Delta w^{1}=\beta\left(\frac1n\sum_{i=1}^nE_{i}X_{i}\right)\\&\quad=0.1\times\frac14\left(0.25\times1+0.53\times2+0.84\times3+1.2\times4\right)\\&\quad=0.2158\\ &w^{1}=w+\Delta w^1=0.5+0.2158=0.7158\end{aligned}
第一周期:1◯2◯3◯4◯x1=1,y1=0.5×1=0.5,E1=t−y1=0.25x2=2,y2=0.5×2=1,E2=t−y2=0.53x3=3,y3=0.5×3=1.5,z3=t−y3=0.84x4=4,y4=0.5×4=2,E4=t−y4=1.2Δw1=β(n1i=1∑nEiXi)=0.1×41(0.25×1+0.53×2+0.84×3+1.2×4)=0.2158w1=w+Δw1=0.5+0.2158=0.7158
第二周期:
1
◯
x
1
=
1
,
y
1
=
0.7158
,
E
1
=
0.342
2
◯
x
2
=
2
,
y
2
=
1.4316
,
E
2
=
0.0984
3
◯
x
3
=
3
,
y
3
=
2.1474
,
E
3
=
0.1926
4
◯
x
4
=
4
,
y
4
=
2.8632
,
E
4
=
0.3368
Δ
w
2
=
0.0539
w
2
=
w
1
+
Δ
w
2
=
0.7697
\begin{aligned} \text{第二周期:} \\ \textcircled{1}&\quad x_1=1,\quad y_1=0.7158,\quad E_1=0.342 \\ \textcircled{2}&\quad x_2=2,\quad y_2=1.4316,\quad E_2=0.0984 \\ \textcircled{3}&\quad x_3=3,\quad y_3=2.1474,\quad E_3=0.1926 \\ \textcircled{4}&\quad x_4=4,\quad y_4=2.8632,\quad E4=0.3368 \\ &\Delta w^2=0.0539 \\ &w^2=w^{1}+\Delta w^2=0.7697 \end{aligned}
第二周期:1◯2◯3◯4◯x1=1,y1=0.7158,E1=0.342x2=2,y2=1.4316,E2=0.0984x3=3,y3=2.1474,E3=0.1926x4=4,y4=2.8632,E4=0.3368Δw2=0.0539w2=w1+Δw2=0.7697
第三周期: 1 ◯ x 1 = 1 , y 1 = 0.7697 , E 1 = − 0.0197 2 ◯ x 2 = 2 , y 2 = 1.5394 , E 2 = − 0.0094 3 ◯ x 3 = 3 , y 3 = 2.3091 , E 3 = 0.0309 4 ◯ x 4 = 4 , y 4 = 3.0788 , E 4 = 0.1212 Δ w 3 = 0.013475 w 3 = w 2 + Δ w 3 = 0.783175 \begin{aligned} \text{第三周期:}\\ \textcircled{1}&\quad x_1=1,\quad y_1=0.7697,\quad E_1=-0.0197\\ \textcircled{2}&\quad x_2=2,\quad y_2=1.5394,\quad E_2=-0.0094\\ \textcircled{3}&\quad x_3=3,\quad y_3=2.3091,\quad E_3=0.0309\\ \textcircled{4}&\quad x_4=4,\quad y_4=3.0788,\quad E4=0.1212 \\ &\Delta w^3=0.013475 \\ &w^3=w^{2}+\Delta w^3=0.783175 \end{aligned} 第三周期:1◯2◯3◯4◯x1=1,y1=0.7697,E1=−0.0197x2=2,y2=1.5394,E2=−0.0094x3=3,y3=2.3091,E3=0.0309x4=4,y4=3.0788,E4=0.1212Δw3=0.013475w3=w2+Δw3=0.783175
遍历学习算法在经过四次计算到达了相对的优值0.8215,而批量学习算法在3次计算就到达了比较接近的0.7831,值得一提的是遍历学习第一次的计算就已经达到了0.7158的结果,但是在后面的计算中以一个比较慢的速度进行更新与调整。
5.BP神经网络回归模型}
5.1.BP神经网络回归模型介绍
5.1.1.BP神经网络的特点
BP神经网络的改动就是考虑到误差导数或关于权值的误差表面的斜率对权值的调整,在网络训练期间如图4.3所示,所有的输出神经元和隐含神经元权值必须同时调整。因此,有必要找到关于所有权值的误差导数。用
∂
E
∂
b
\frac{\partial E}{\partial b}
∂b∂E 表示相对输出节点权值的导数,用
∂
E
∂
a
\frac{\partial E}{\partial a}
∂a∂E表示相对隐含节点权值的导数。因为E不是直接与b和a相关联的,当误差E与权值的连接不是直接一个接一个相连时,可以使用链式规则的概念来找到导数,然后再去获得
∂
E
∂
b
\frac{\partial E}{\partial b}
∂b∂E。然后通过连接输人与输入-隐含神经元的权值au也与y(隐含节点输出)相关联。因此跟踪从E,z,v,y到输人的相关链就可获得
∂
E
∂
a
\frac{\partial E}{\partial a}
∂a∂E,这个概念叫做BP学习,这也是BP网络有别于其他网络的一个重要特点。

5.1.2.BP神经网络的链式求导法则
我们以最简单的结构来进行链式法则的推导,如下所示,链式求导是基于BP(BackPropagation)原则,所以是从后往前传递求导的过程,所以我们将先决定求b的导数再求a的导数。

首先对于任意隐含层b(权值)的导数,如下推导关系:
∂
E
∂
b
=
∂
E
∂
z
⋅
∂
z
∂
v
⋅
∂
v
∂
b
\frac{\partial E}{\partial b}=\frac{\partial E}{\partial z}\cdot\frac{\partial z}{\partial v}\cdot\frac{\partial v}{\partial b}
∂b∂E=∂z∂E⋅∂v∂z⋅∂b∂v
对于 ∂ E ∂ b \frac{\partial E}{\partial b} ∂b∂E,有三个计算的部分,第一部分是 ∂ E ∂ z \frac{\partial E}{\partial z} ∂z∂E这是误差表面的对于输出的斜率, ∂ z ∂ v \frac{\partial z}{\partial v} ∂v∂z是变量对于激活函数的求导,第三个输入加权和对v对输出神经元权值变化的灵敏度。
对于三个求导值,如下所示:
∂
E
∂
z
=
z
−
t
\frac{\partial E}{\partial z}=z-t
∂z∂E=z−t
∂
z
∂
v
=
(
1
−
z
)
/
z
1
/
z
2
=
z
(
1
−
z
)
\frac{\partial z}{\partial v}=\frac{(1-z)/z}{1/z^{2}}=z(1-z)
∂v∂z=1/z2(1−z)/z=z(1−z)
v
=
b
0
+
b
1
y
∂
v
∂
b
1
=
y
∂
v
∂
b
0
=
1
\begin{aligned}v&=b_0+b_1y\\\frac{\partial v}{\partial b_1}&=y\\\frac{\partial v}{\partial b_0}&=1\end{aligned}
v∂b1∂v∂b0∂v=b0+b1y=y=1
计算所得关于两个权重的误差导数就表示为:
∂
E
∂
b
0
=
(
z
−
t
)
z
(
1
−
z
)
=
p
∂
E
∂
b
1
=
(
z
−
t
)
z
(
1
−
z
)
y
=
p
y
\begin{aligned}\frac{\partial E}{\partial b_0}&=(z-t)z(1-z)=p\\\\\frac{\partial E}{\partial b_1}&=(z-t)z(1-z)y=py\end{aligned}
∂b0∂E∂b1∂E=(z−t)z(1−z)=p=(z−t)z(1−z)y=py
我们还需要求解关于a的隐含神经元的误差梯度,同样使用链式法则,如下所示:
∂
E
∂
a
=
(
∂
E
∂
z
⋅
∂
z
∂
v
⋅
∂
v
∂
y
)
⋅
∂
y
∂
u
⋅
∂
u
∂
a
\frac{\partial E}{\partial a}=\left(\frac{\partial E}{\partial z}\cdot\frac{\partial z}{\partial v}\cdot\frac{\partial v}{\partial y}\right)\cdot\frac{\partial y}{\partial u}\cdot\frac{\partial u}{\partial a}
∂a∂E=(∂z∂E⋅∂v∂z⋅∂y∂v)⋅∂u∂y⋅∂a∂u
又已知
∂
v
∂
y
=
b
1
\frac{\partial v}{\partial y}=b_1
∂y∂v=b1
所以前三项代入得到:
∂
E
∂
y
=
∂
E
∂
z
⋅
∂
z
∂
v
⋅
∂
v
∂
y
=
p
b
1
\frac{\partial E}{\partial y}=\frac{\partial E}{\partial z}\cdot\frac{\partial z}{\partial v}\cdot\frac{\partial v}{\partial y}=pb_{1}
∂y∂E=∂z∂E⋅∂v∂z⋅∂y∂v=pb1
公式的第四项内容还是表示为这一层的u对于激活函数进行求导,如下所示:
∂
E
∂
y
=
y
(
1
−
y
)
\frac{\partial E}{\partial y}=y(1-y)
∂y∂E=y(1−y)
对于最后一项,由于
u
=
a
0
+
a
1
u=a_{0}+a_{1}
u=a0+a1,所以对其进行求导如下所示:
∂
u
∂
a
1
=
x
∂
u
∂
a
0
=
1
\begin{aligned}\frac{\partial u}{\partial a_1}&=x\\\frac{\partial u}{\partial a_0}&=1\end{aligned}
∂a1∂u∂a0∂u=x=1
所以将所有成分都组合在一起得到关于a的权值更新计算公式如下所示:
∂
E
∂
a
1
=
p
b
1
y
(
1
−
y
)
x
=
q
x
∂
E
∂
a
0
=
p
b
1
y
(
1
−
y
)
=
q
q
=
p
b
1
y
(
1
−
y
)
\begin{aligned}\frac{\partial E}{\partial a_1}&=pb_1y(1-y)x=qx\\\frac{\partial E}{\partial a_0}&=pb_1y(1-y)=q\\ &q=pb_1y(1-y)\end{aligned}
∂a1∂E∂a0∂E=pb1y(1−y)x=qx=pb1y(1−y)=qq=pb1y(1−y)
以上我们就实现了图中神经元结构的权重更新。
5.2.BP神经网络回归模型实现
如图所示,我们现在利用神经网络来进行更新和回归的求解,如下所示,表中是一些神经元权重的值和更新的点数据:

首先计算前向网络结果,如下所示:
对于x=0.7853,t=0.707,确定神经网路的前向传递的网络输出:
u
=
a
0
+
a
1
x
=
0.3
+
0.2
(
0.7853
)
=
0.457
y
=
1
1
+
e
−
u
=
1
1
+
e
−
(
0.457
)
=
0.612
v
=
b
0
+
b
1
y
=
−
0.1
+
0.4
(
0.612
)
=
0.143
z
=
1
1
+
e
−
v
=
1
1
+
e
−
(
0.143
)
=
0.536
\begin{array}{l}u=a_{0}+a_{1} x=0.3+0.2(0.7853)=0.457 \\y=\frac{1}{1+\mathrm{e}^{-u}}=\frac{1}{1+\mathrm{e}^{-(0.457)}}=0.612 \\v=b_{0}+b_{1} y=-0.1+0.4(0.612)=0.143 \\z=\frac{1}{1+\mathrm{e}^{-v}}=\frac{1}{1+\mathrm{e}^{-(0.143)}}=0.536\end{array}
u=a0+a1x=0.3+0.2(0.7853)=0.457y=1+e−u1=1+e−(0.457)1=0.612v=b0+b1y=−0.1+0.4(0.612)=0.143z=1+e−v1=1+e−(0.143)1=0.536
所以对于这个点的平均误差如下所示:
E
=
1
2
(
0.536
−
0.707
)
2
=
0.0146
E=\frac{1}{2}(0.536-0.707)^{2}=0.0146
E=21(0.536−0.707)2=0.0146
接下来我们进行b权重的更新,z=0.536,t=0.707,如下所示:
∂
E
∂
b
0
=
(
z
−
t
)
z
(
1
−
z
)
=
p
=
(
0.536
−
0.707
)
(
0.536
)
(
1
−
0.536
)
=
−
0.042
∂
E
∂
b
1
=
p
y
=
(
−
0.042
)
(
0.6120
)
=
−
0.026
\begin{aligned}\frac{\partial E}{\partial b_0}&=(z-t)z(1-z)=p=(0.536-0.707)(0.536)(1-0.536)=-0.042\\\frac{\partial E}{\partial b_1}&=py=(-0.042)(0.6120)=-0.026\end{aligned}
∂b0∂E∂b1∂E=(z−t)z(1−z)=p=(0.536−0.707)(0.536)(1−0.536)=−0.042=py=(−0.042)(0.6120)=−0.026
接下来我们进行a权重的更新,如下所示:(p=-0.042,
b
1
=
0.4
b_{1}=0.4
b1=0.4,y=0.612,x=0.7853)
∂
E
∂
a
0
=
p
b
1
y
(
1
−
y
)
=
q
=
(
−
0.042
)
(
0.4
)
(
0.612
)
(
1
−
0.612
)
=
−
0.004
∂
E
∂
a
1
=
p
b
1
y
(
1
−
y
)
x
=
q
x
=
(
−
0.004
)
(
0.7853
)
=
−
0.00314
\begin{array}{c}\frac{\partial E}{\partial a_{0}}=p b_{1} y(1-y)=q=(-0.042)(0.4)(0.612)(1-0.612)=-0.004 \\\frac{\partial E}{\partial a_{1}}=p b_{1} y(1-y) x=q x=(-0.004)(0.7853)=-0.00314\end{array}
∂a0∂E=pb1y(1−y)=q=(−0.042)(0.4)(0.612)(1−0.612)=−0.004∂a1∂E=pb1y(1−y)x=qx=(−0.004)(0.7853)=−0.00314
另外一个点的[1.571,1.00]通过同样的计算,得出对应的梯度值如下所示:
∂
E
∂
a
0
=
−
0.0104
∂
E
∂
a
1
=
−
0.0163
∂
E
∂
b
0
=
−
0.1143
∂
E
∂
b
1
=
−
0.0742
\begin{aligned}\frac{\partial E}{\partial a_0}&=-0.0104\\ \frac{\partial E}{\partial a_1}&=-0.0163\\ \frac{\partial E}{\partial b_0}&=-0.1143\\ \frac{\partial E}{\partial b_{1}}&=-0.0742\\ \end{aligned}
∂a0∂E∂a1∂E∂b0∂E∂b1∂E=−0.0104=−0.0163=−0.1143=−0.0742
计算得出的平均误差如下所示:
z
=
0.5398
E
=
0.1059
M
S
E
=
E
1
+
E
2
2
=
(
0.0146
+
0.1059
)
2
=
0.0602
\begin{aligned}z&=0.5398\\ E&=0.1059\\ MSE=\frac{E_1+E_2}{2}&=\frac{(0.0146+0.1059)}{2}=0.0602\\ \end{aligned}
zEMSE=2E1+E2=0.5398=0.1059=2(0.0146+0.1059)=0.0602
现在我们利用梯度下降法返回更新,进行权重值的调整,求解梯度和如下所示:
d
1
a
0
=
∑
∂
E
∂
a
0
=
−
0.004
−
0.0104
=
−
0.0144
-
d
1
a
1
=
∑
∂
E
∂
a
1
=
−
0.00314
−
0.0163
=
−
0.01944
d
1
b
0
=
∑
∂
E
∂
b
0
=
−
0.042
−
0.1143
=
−
0.1563
d
1
b
1
=
∑
∂
E
∂
b
1
=
−
0.026
−
0.0742
=
−
0.1002
\begin{gathered} d_{1}^{a_{0}}=\sum\frac{\partial E}{\partial a_{0}}=-0.004-0.0104=-0.0144 \\ \text{-} d_{1}^{a_{1}}=\sum{\frac{\partial E}{\partial a_{1}}}=-0.00314-0.0163=-0.01944 \\ d_{1}^{b_{0}}=\sum\frac{\partial E}{\partial b_{0}}=-0.042-0.1143=-0.1563 \\ d_{1}^{b_{1}}=\sum{\frac{\partial E}{\partial b_{1}}}=-0.026-0.0742=-0.1002 \end{gathered}
d1a0=∑∂a0∂E=−0.004−0.0104=−0.0144-d1a1=∑∂a1∂E=−0.00314−0.0163=−0.01944d1b0=∑∂b0∂E=−0.042−0.1143=−0.1563d1b1=∑∂b1∂E=−0.026−0.0742=−0.1002
所以第二次进行训练时权值更新如下所示:
a
0
2
=
a
0
+
Δ
a
0
=
0.3
+
0.00144
=
0.30144
a
1
2
=
a
1
+
Δ
a
1
=
a
1
−
ε
d
1
a
1
=
0.2
−
(
0.1
)
(
−
0.01944
)
=
0.2019
b
0
2
=
b
0
+
Δ
b
0
=
b
0
−
ε
d
1
b
0
=
−
0.1
−
(
0.1
)
(
−
0.1563
)
=
−
0.0844
b
1
2
=
b
1
+
Δ
b
1
=
b
1
−
ε
d
1
b
1
=
0.4
−
(
0.1
)
(
−
0.1002
)
=
0.410
\begin{aligned}a_{0}^{2}&=a_{0}+\Delta a_{0}=0.3+0.00144=0.30144\\ a_1^2&=a_1+\Delta a_1=a_1-\varepsilon d_1^{a_1}=0.2-(0.1)(-0.01944)=0.2019\\b_0^2&=b_0+\Delta b_0=b_0-\varepsilon d_1^{b_0}=-0.1-(0.1)(-0.1563)=-0.0844\\b_1^2&=b_1+\Delta b_1=b_1-\varepsilon d_1^{b_1}=0.4-(0.1)(-0.1002)=0.410\end{aligned}
a02a12b02b12=a0+Δa0=0.3+0.00144=0.30144=a1+Δa1=a1−εd1a1=0.2−(0.1)(−0.01944)=0.2019=b0+Δb0=b0−εd1b0=−0.1−(0.1)(−0.1563)=−0.0844=b1+Δb1=b1−εd1b1=0.4−(0.1)(−0.1002)=0.410
再次代入计算MSE如下所示:
M
S
E
=
(
0.01367
+
0.1033
)
/
2
⇒
0.0585
\mathrm{MSE}=(0.01367+0.1033)/2\Rightarrow0.0585
MSE=(0.01367+0.1033)/2⇒0.0585
同理再次进行更新训练所得权值如下所示:
d
2
a
0
=
∑
∂
E
∂
a
0
=
−
0.00399
−
0.0105
=
−
0.01449
d
2
a
1
∑
∂
E
∂
a
1
=
−
0.00312
−
0.0165
=
−
0.0196
d
2
b
0
=
∑
∂
E
∂
b
0
=
−
0.04106
−
0.1127
=
−
0.1538
d
2
b
1
=
∑
∂
E
∂
b
1
=
−
0.0251
−
0.0732
=
−
0.0983
\begin{aligned}d_{2}^{a_{0}}&=\sum\frac{\partial E}{\partial a_{0}}=-0.00399-0.0105=-0.01449\\ d_2^{a_1}&\sum\frac{\partial E}{\partial a_1}=-0.00312-0.0165=-0.0196\\d_2^{b_0}&=\sum\frac{\partial E}{\partial b_0}=-0.04106-0.1127=-0.1538\\d_2^{b_1}&=\sum\frac{\partial E}{\partial b_1}=-0.0251-0.0732=-0.0983\end{aligned}
d2a0d2a1d2b0d2b1=∑∂a0∂E=−0.00399−0.0105=−0.01449∑∂a1∂E=−0.00312−0.0165=−0.0196=∑∂b0∂E=−0.04106−0.1127=−0.1538=∑∂b1∂E=−0.0251−0.0732=−0.0983
结合梯度差和学习率进行计算的新权值如下所示:
Δ
a
0
2
=
0.00145
a
0
3
=
0.3029
Δ
a
1
2
=
0.00196
a
1
3
=
0.2039
Δ
b
0
2
=
0.01538
b
0
3
=
−
0.069
Δ
b
1
2
=
0.00983
b
1
3
=
0.4198
\begin{aligned}\Delta a_0^2&=0.00145\quad a_0^3=0.3029\\\Delta a_1^2&=0.00196\quad a_1^3=0.2039\\\Delta b_0^2&=0.01538\quad b_0^3=-0.069\\\Delta b_1^2&=0.00983\quad b_1^3=0.4198\end{aligned}
Δa02Δa12Δb02Δb12=0.00145a03=0.3029=0.00196a13=0.2039=0.01538b03=−0.069=0.00983b13=0.4198
针对两个点进行的MSE求解结果如下所示:
M
S
E
=
(
0.0128
+
0.10085
)
/
2
=
0.0568
\mathrm{MSE}=(0.0128+0.10085)/2=0.0568
MSE=(0.0128+0.10085)/2=0.0568
所以通过不断训练,MSE不断变小,效果越来越好。