在本文中,我们提出了一种新的即插即用的联邦学习模块,FedFed,其能够以特征蒸馏的方式来解决联邦场景下的数据异构问题。FedFed首次探索了对数据中部分特征的提取与分享,大量的实验显示,FedFed能够显著地提升联邦学习在异构数据场景下的性能和收敛速度。

论文名称:
FedFed: Feature Distillation against Data Heterogeneity in Federated Learning
论文链接:
https://arxiv.org/abs/2310.05077
代码链接:
https://github.com/visitworld123/FedFed
一、 引言
联邦学习(Federated Learning, FL)近年来引起学术界和工业界越来越多的关注,它旨在保护用户数据隐私的同时完成模型的训练。
然而,在联邦学习的场景中,由于各个联邦参与方(客户端)本身的差异(如地理位置,气候条件等客观因素的不同),导致不同客户端之间的训练数据分布可能存在较大差异,这会造成在不同客户端下训练的模型有一定的差异。进而,聚合这些有差异的模型会严重影响模型的性能。因此,如何在异构的数据分布下(也被称作non-IID)提升模型性能成为了联邦学习领域的研究重点内容。
性能-隐私困境: 为了解决异构给联邦学习带来的挑战,一项开创性工作FedAvg[1]提出在客户端本地训练模型,将本地模型传输至中心服务器,并且在中心服务器以加权聚合的方式得到全局模型。这种方法虽然解决了联邦学习中计算和通信上的多样性问题,但仍面临着由数据异构性带来的模型性能较差的问题。
现有一系列研究致力于缓解数据异构在联邦学习中带来的挑战。一些研究尝试在客户端之间共享数据信息来解决数据异构性问题,这种方法在提升联邦学习系统性能方面展现出了巨大潜力。虽然信息共享策略能够带来性能提升,但是也引入了一些隐私泄漏的风险,造成了联邦学习中的性能-隐私困境。
面对这个困境,我们提出了一个有趣的问题:能否通过共享数据中的极少部分信息的方式来解决数据异构问题?
二、 研究动机
问题1: 是否可以只共享数据中的部分信息就能很好地解决数据异构问题?
受到特征拆分的启发[2],我们尝试把数据中的特征分成两部分,即性能鲁棒特征(performance-robust features)和性能敏感特征(performance-sensitive features)。我们希望性能鲁棒特征包含数据中几乎所有的信息,同时包含极少量信息的性能敏感特征能使模型泛化良好。这样,我们便能够将数据中几乎所有信息都保存于本地,而只需要分享性能敏感特征。因此,若能将数据特征完美地划分为这两类特征,那么性能-隐私困境就可以被很好地解决。
问题2: 如何将数据划分为性能敏感特征和性能鲁棒特征?
问题1中的需求和信息瓶颈理论(Information Bottleneck, IB)存在一些天然的内在联系。理想情况下,信息瓶颈旨在剔除数据中的冗余信息并保留有助于完成正确预测的重要信息。那么,那些被信息瓶颈所丢掉的冗余信息便成为了我们无需共享的信息。因此,信息瓶颈启发我们尽可能多的“丢弃”冗余信息至本地,而仅发送极少量的信息用于解决数据异构问题。
问题3: 如果性能敏感特征中包含了隐私信息该怎么办?
一般来说,如果想使得共享的信息是有意义的,那其中不可避免的会包含一些信息量。因此,联邦学习中的信息共享策略难免会带来隐私泄露问题。幸运的是,我们可以利用差分隐私技术保护被分享的性能敏感特征,以极大程度上避免隐私的泄漏。
基于对上述三个问题的分析,我们提出了FedFed框架来解决联邦学习中的数据异构问题,首先我们定义了什么是性能敏感特征和性能鲁棒特征;随后从信息瓶颈的思想出发我们提出了蒸馏出数据中的敏感特征的方法,即特征蒸馏;最后我们对蒸馏出的敏感特征加入了强噪声以在理论的保证下完成隐私的保护。
三、 方法
3.1 性能敏感与性能鲁棒特征
3.2 特征蒸馏
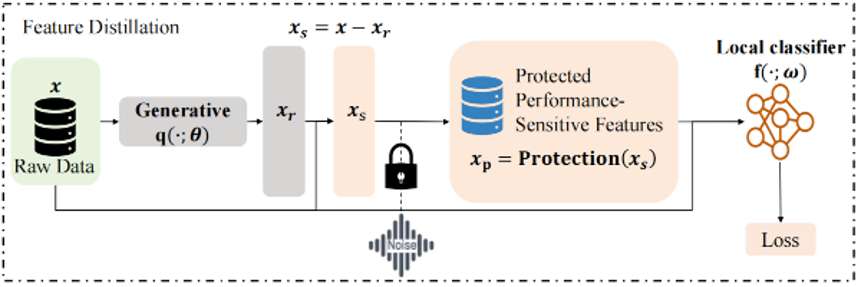

3.3 性能敏感特征的利用与保护
四、实验结果与分析
FedFed可以作为插件部署在现有联邦学习框架下,为了验证FedFed有效性,我们在四个广泛使用的数据集上进行了实验,并测试了不同客户端数量,不同non-IID程度,不同本地epoch次数以及几种主流的FL算法,包括FedAvg、FedProx、FedNova和SCAFFOLD。实验结果表明FedFed在提升模型性能和收敛速度具有显著效果。
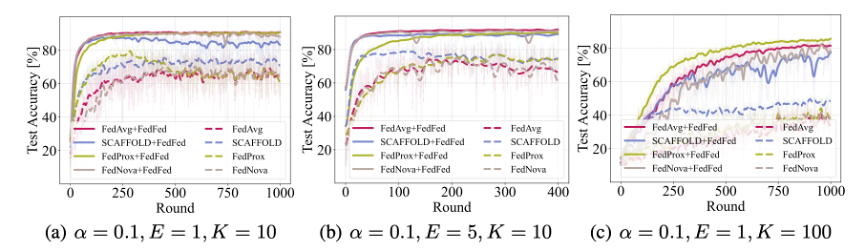
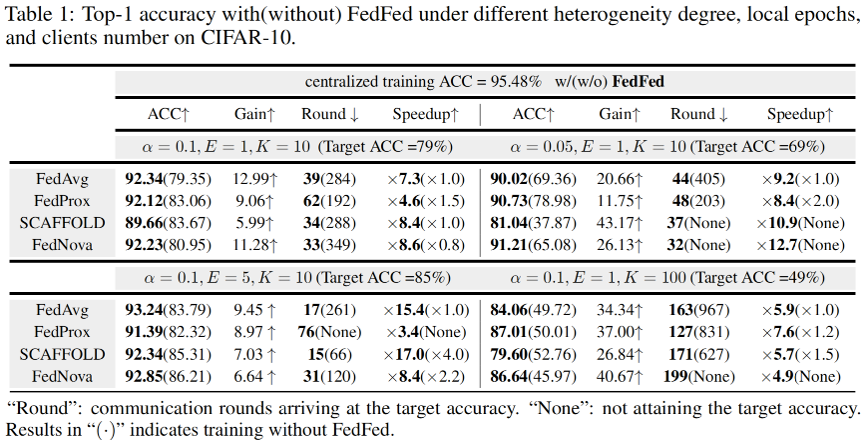
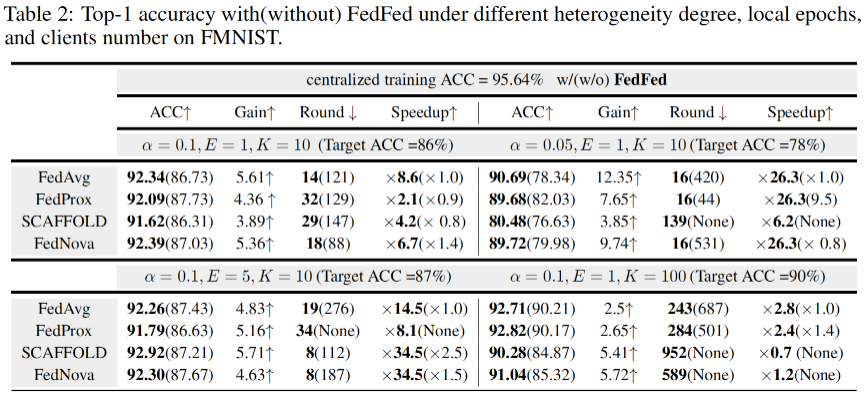
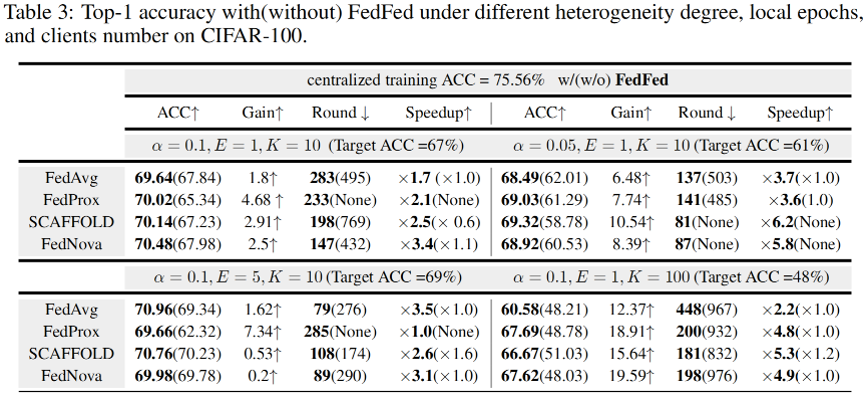
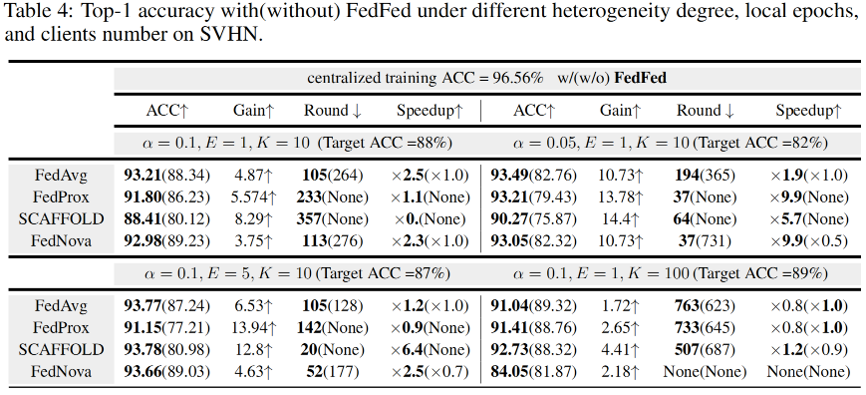
在 CIFAR-10、CIFAR-100、FMNIST 和 SVHN 数据集上的实验结果分别在表 1、表 2、表 3和表 4中展示。可以看出,FedFed在各种实验设置下都能显著提高模型准确率。此外,FedFed 可以加快不同联邦学习算法的收敛速度。
不同异构划分方式:
除此之外,还对FedFed在不同non-IID划分方式下的结果进行了实验,表 5显示,其他两种异构划分方式导致的性能下降比 LDA (α=0.1) 更为严重。即使这种情况下,FedFed依旧显著地提高了模型的性能,表明其对异构划分方式的鲁棒性。
隐私保护验证:
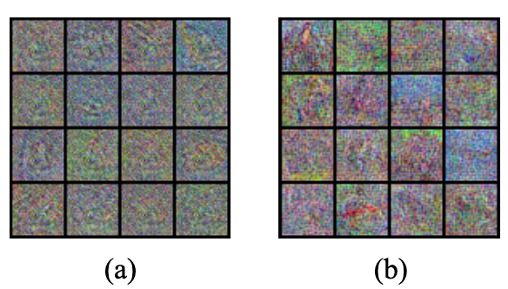
除了理论上的保证,我们还从实验的角度借助隐私攻击验证了FedFed对隐私的保护效果。我们采用了模型逆向攻击方法,该方法被广泛用于重构数据。图3中的结果表明,FedFed 能够保护全局共享的数据。
五、 结论与展望
我们重新思考了联邦学习中的信息共享策略的初衷,提出了分享数据中部分特征的信息共享策略,并将其设计为一个即插即用的模块。大量实验显示引入该模块能够有效地缓解数据异构性问题。我们期望能将特征蒸馏应用在联邦学习中的不同任务和不同场景下,为联邦学习在现实场景中的所遇到的各类复杂问题提供一个新的解决思路。
篇幅原因,我们在本文中忽略了诸多细节,更多细节可以在论文中找到。感谢阅读!
参考文献
[1] McMahan et al. Communication-efficient learning of deep networks from decentralized data. In AISTATS, 2017.
[2] Karimireddy et al. Scaffold: Stochastic controlled averaging for federated learning. In ICML, 2020.
[3] Zhang et al. CausalAdv: Adversarial Robustness Through the Lens of Causality. In ICLR, 2022.Illustration by IconScout Store from IconScout
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区