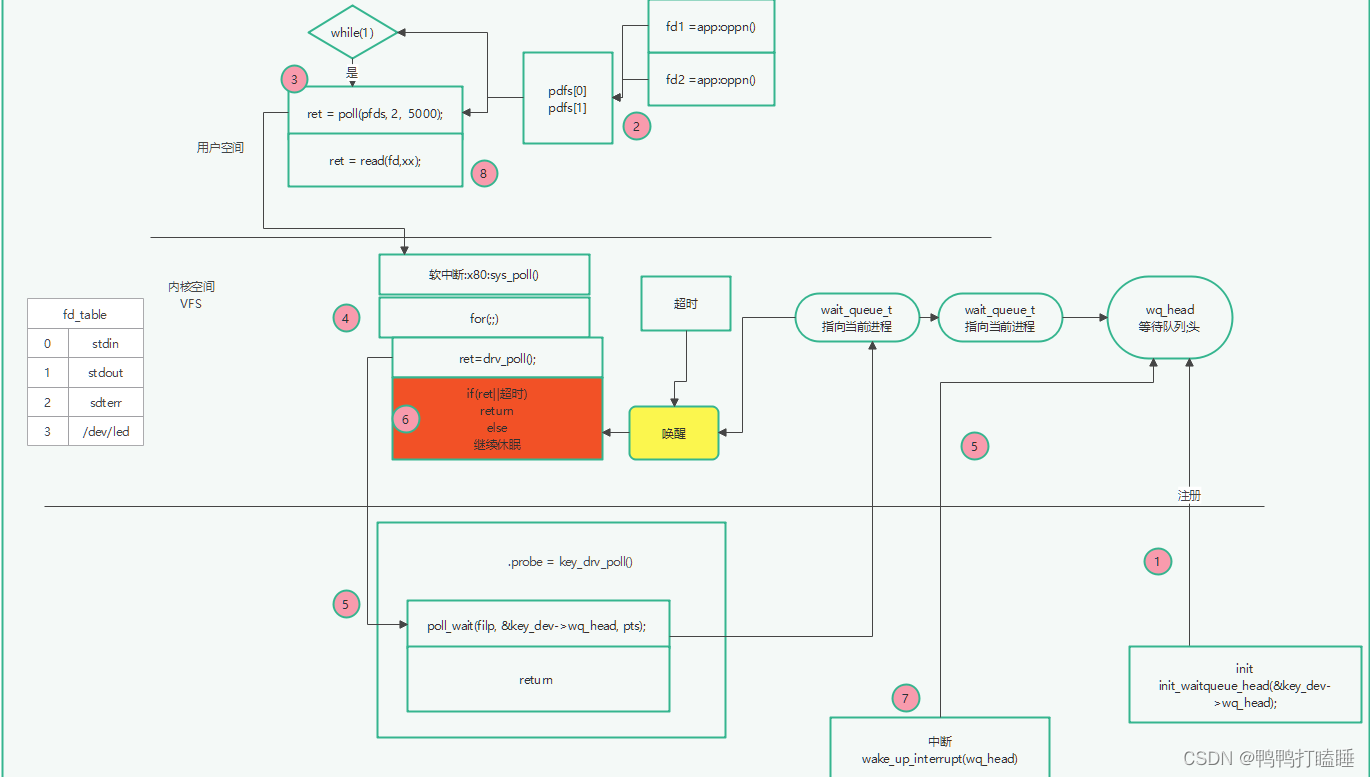
CLIPTeacher:一种基于VLM的通用零样本语义分割框架,有效地利用了可见和忽略区域,而不需要对原CLIP模型进行任何更改,性能提升显著!单位:名古屋大学
现有的通用零样本语义分割(GZLSS)方法应用微调 CLIP 范式或将其制定为掩码分类任务,受益于视觉语言模型(VLM)。 然而,微调方法受到固定骨干模型的限制,这些模型对于分割不灵活,并且掩模分类方法严重依赖于额外的显式掩模提议器。 同时,流行的方法仅利用可见的类别,这是一种极大的浪费,即忽略了存在但未注释的区域。 为此,我们提出了 CLIPTeacher,这是一种新的学习框架,可以应用于各种每像素分类分割模型,而无需引入任何显式掩码proposer或改变 CLIP 的结构,并利用可见区域和忽略区域。 具体来说,CLIPTeacher由两个关键模块组成:全局学习模块(GLM)和像素学习模块(PLM)。 具体来说,GLM 将图像编码器的密集特征与 CLS 令牌(即在 CLIP 中训练的唯一token)对齐,这是从 CLIP 模型中探测全局信息的简单但有效的方法。 相比之下,PLM 仅利用 CLIP 的密集标记来生成用于忽略区域的高级伪注释,而无需引入任何额外的mask proposer。 同时,PLM基于伪标注可以充分利用整个图像。 在三个基准数据集:PASCAL VOC 2012、COCO-Stuff 164k 和 PASCAL Context 上的实验结果显示出巨大的性能提升,即 2.2%、1.3% 和 8.8%
论文地址:https://arxiv.org/abs/2310.02296









更多论文创新点加微信群:Lh1141755859
公众号:CV算法小屋