目录
服务雪崩定义
问题的产生
示例
雪崩产生的几种场景
解决方案
熔断模式
隔离模式(仓壁模式 )
限流模式
超时处理
总结
服务保护技术对比
服务雪崩定义
我们都知道在微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。这种在微服务调用链路中,因为某个服务不可用导致上游服务调用者不可用,最终扩大至整个服务集群产生不可用的问题称之为雪崩效应(一个不可用导致全部不可用)。
分布式系统都存在这样一个问题,由于网络的不稳定性,决定了任何一个服务的可用性都不是 100% 的。当网络不稳定的时候,作为服务的提供者,自身可能会被拖死,导致服务调用者阻塞,最终可能引发雪崩连锁效应。
问题的产生
示例
下面用一个例子来演示这个问题:现在有服务A,他的业务涉及到调用服务1,服务2,服务3。
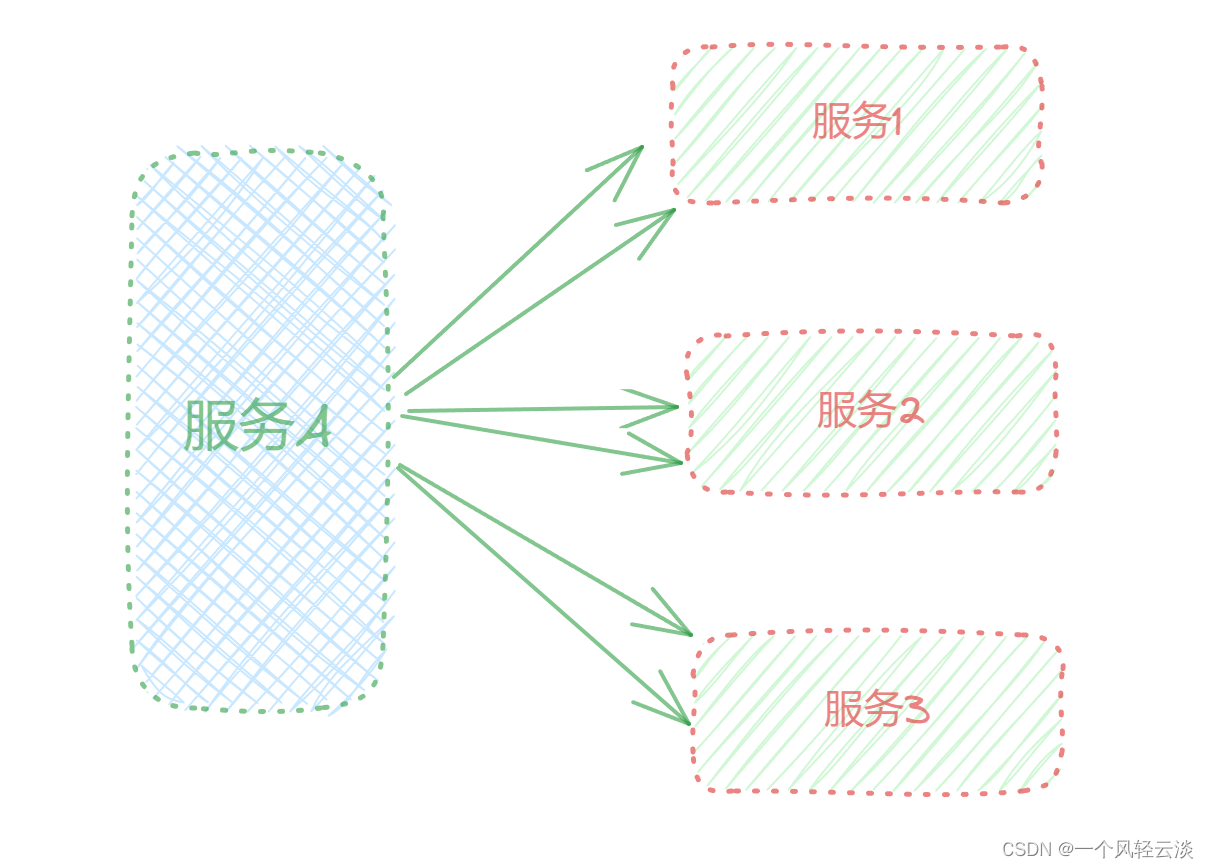
如果服务提供者服务1发生了故障,当前的应用的部分业务因为依赖于服务1,因此也会被阻塞。此时,其它不依赖于服务1的业务似乎不受影响。
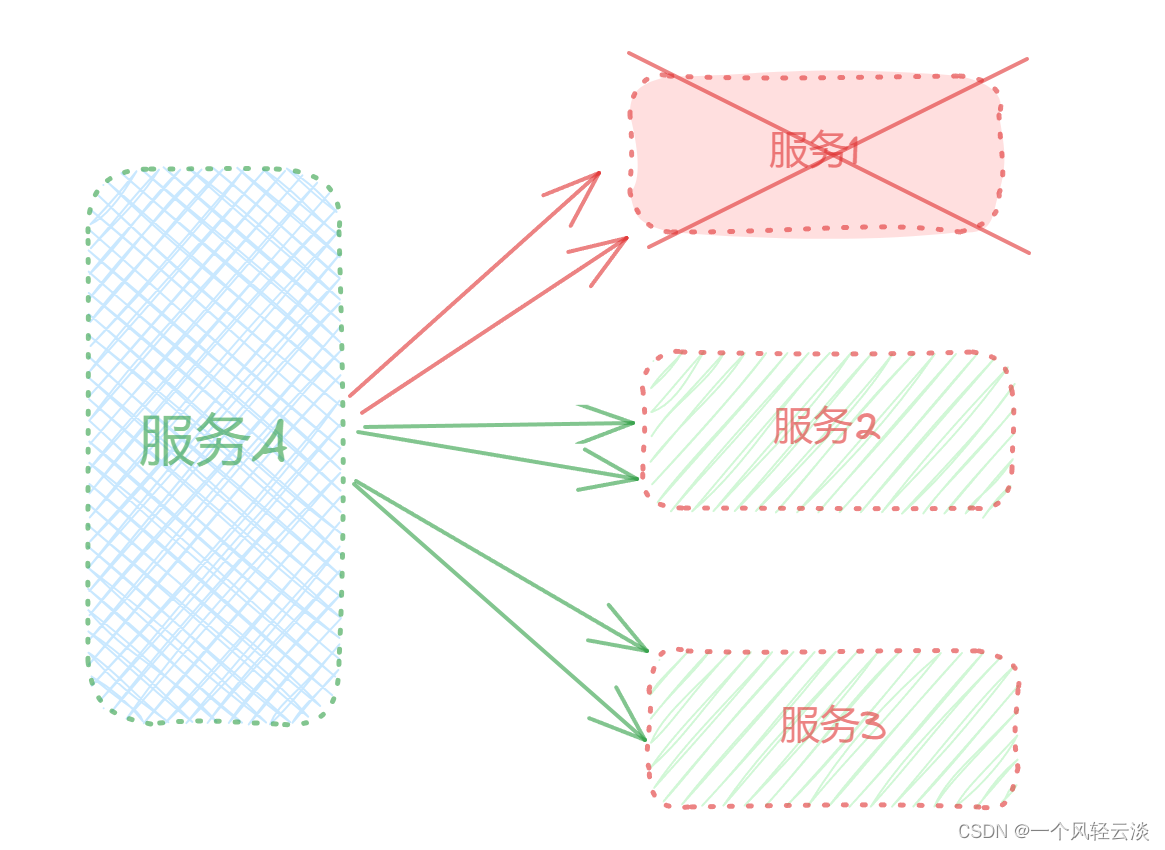
但是,依赖服务1的业务请求被阻塞,用户不会得到响应,则tomcat的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞:
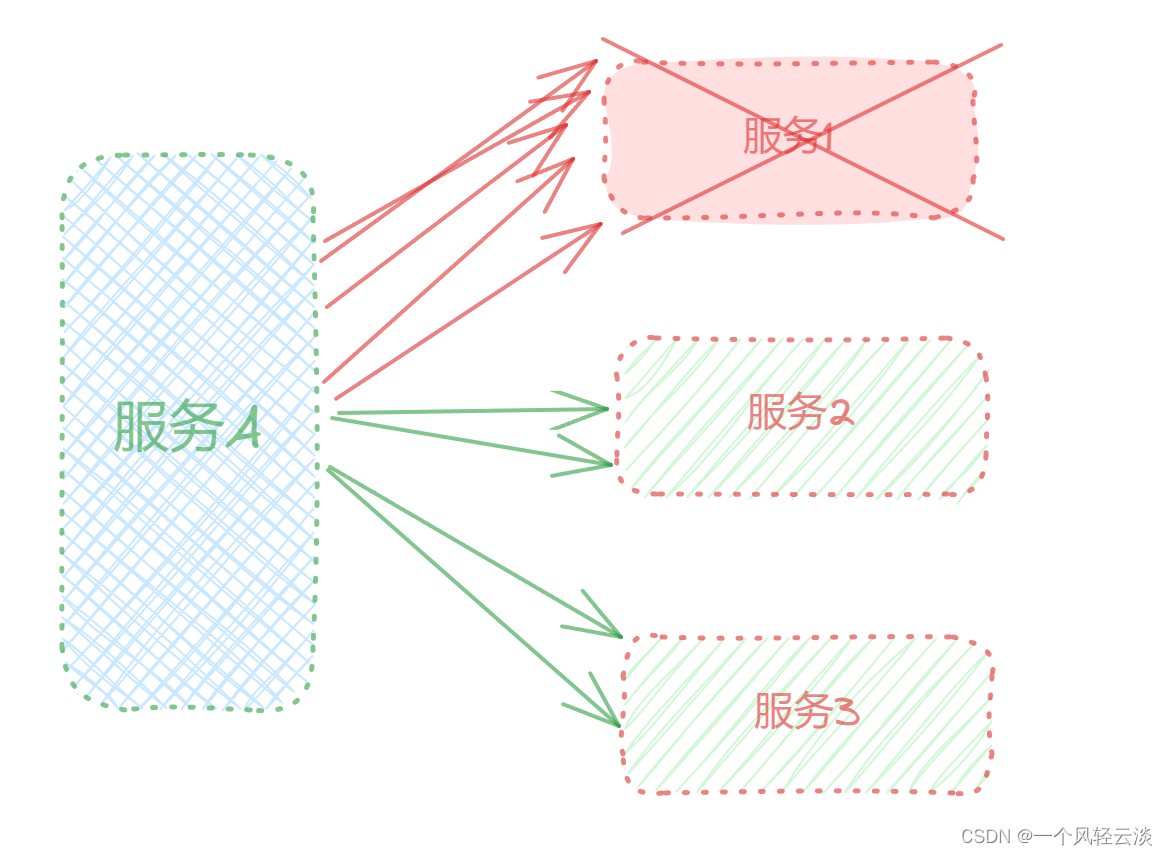
由于服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用,那么当前服务也就不可用了。那么,依赖于当前服务的其它服务(服务2,服务3)随着时间的推移,最终也都会变的不可用,形成级联失败,雪崩就发生了:
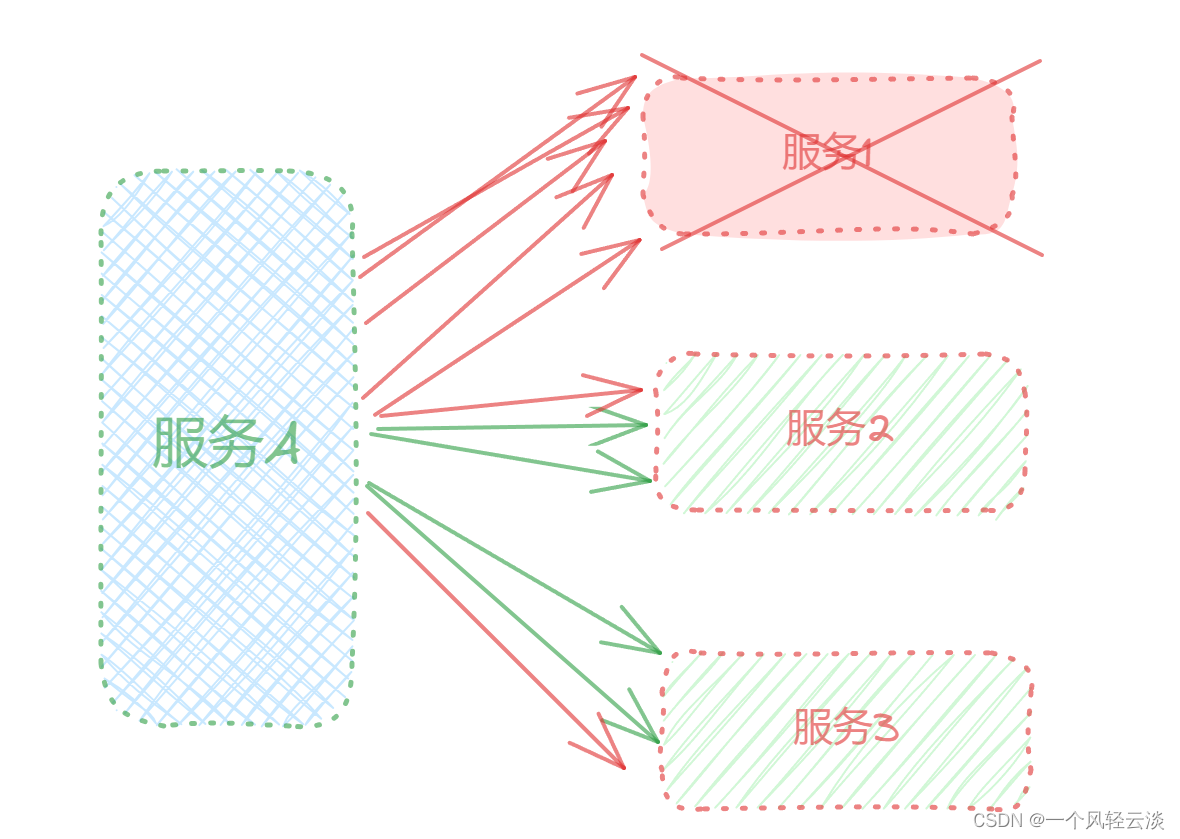
服务调用者不可用的主要原因是当服务调用者使用同步调用时,会产大量的线程等待占用系统资源。一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态,于是服务雪崩效应就产生了。
雪崩产生的几种场景
- 流量激增:比如异常流量、用户重试导致系统负载升高;
- 缓存刷新:假设A为client端,B为Server端,假设A系统请求都流向B系统,请求超出了B系统的承载能力,就会造成B系统崩溃;
- 程序有Bug:代码循环调用的逻辑问题,资源未释放引起的内存泄漏等问题;
- 硬件故障:比如宕机,机房断电,光纤被挖断等。
- 数据库严重瓶颈,比如:长事务、sql超时等。
- 线程同步等待:系统间经常采用同步服务调用模式,核心服务和非核心服务共用一个线程池和消息队列。如果一个核心业务线程调用非核心线程,这个非核心线程交由第三方系统完成,当第三方系统本身出现问题,导致核心线程阻塞,一直处于等待状态,而进程间的调用是有超时限制的,最终这条线程将断掉,也可能引发雪崩;
解决方案
一般情况对于服务依赖的保护主要有4种解决方案:
熔断模式
主要是参考电路熔断,如果一条线路电压过高,保险丝会熔断,防止火灾。放到我们的系统中,如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。断路器会统计访问某个服务的请求数量,异常比例或异常数量,当发现访问服务C的请求异常比例过高时,认为服务C有导致雪崩的风险,会拦截访问服务C的一切请求,形成熔断。
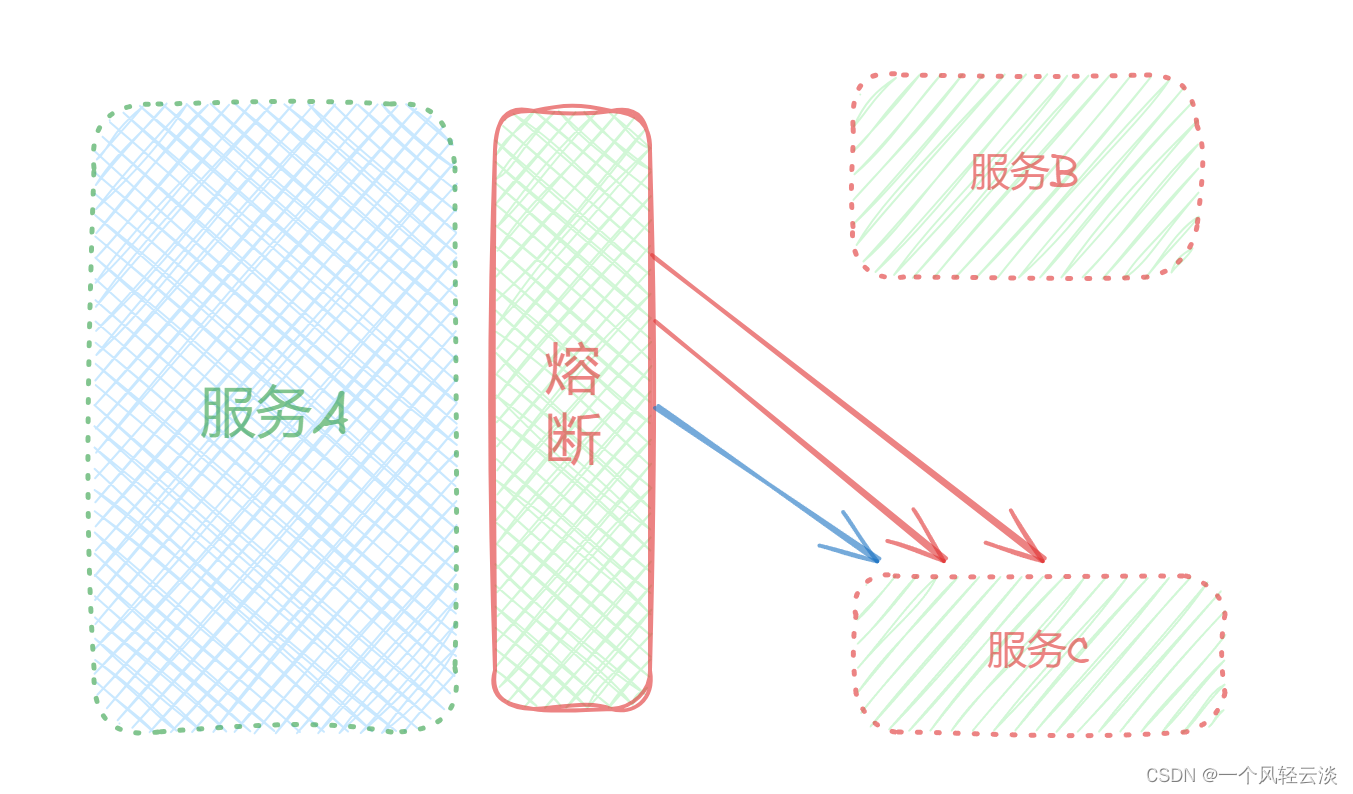
设置异常/失败/慢调用上限,当达到上限就断开调用,再来的请求都不让调用,隔断时间之后再尝试调用,如果服务还能运行再放行,否则继续拒绝。
隔离模式(仓壁模式 )
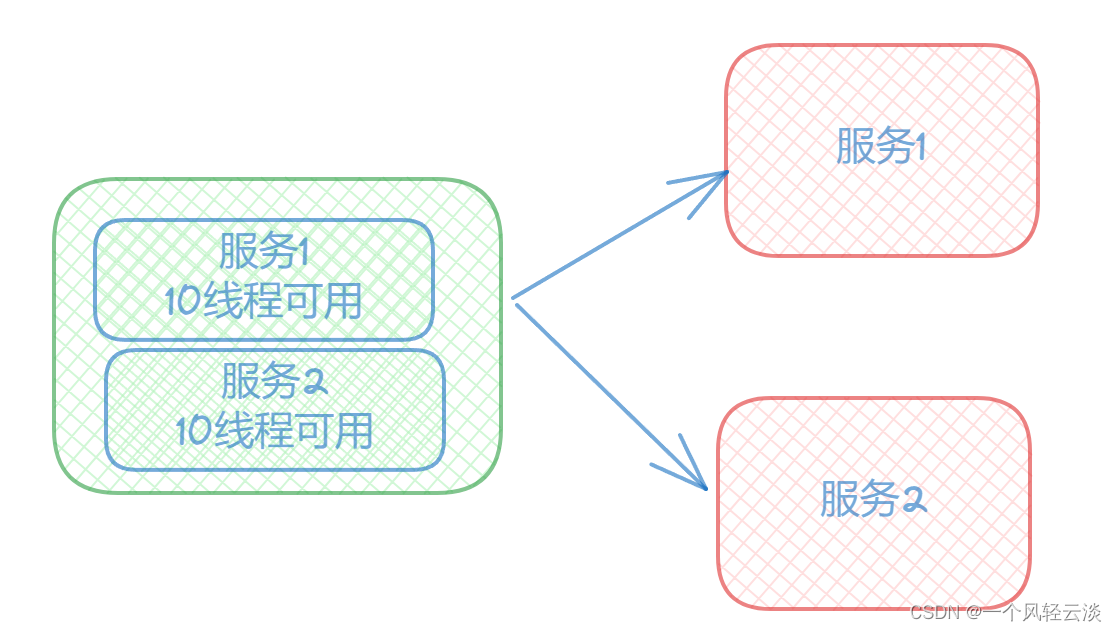
对系统请求按类型划分成一个个小岛的一样,当某个小岛被火少光了,不会影响到其他的小岛。例如:可以对不同类型的请求使用线程池来资源隔离,每种类型的请求互不影响,如果一种类型的请求线程资源耗尽,则对后续的该类型请求直接返回,不再调用后续资源。这种模式使用场景非常多,例如将一个服务拆开,对于重要的服务使用单独服务器来部署,再或者公司最近推广的多中心。
我们可以限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。
限流模式
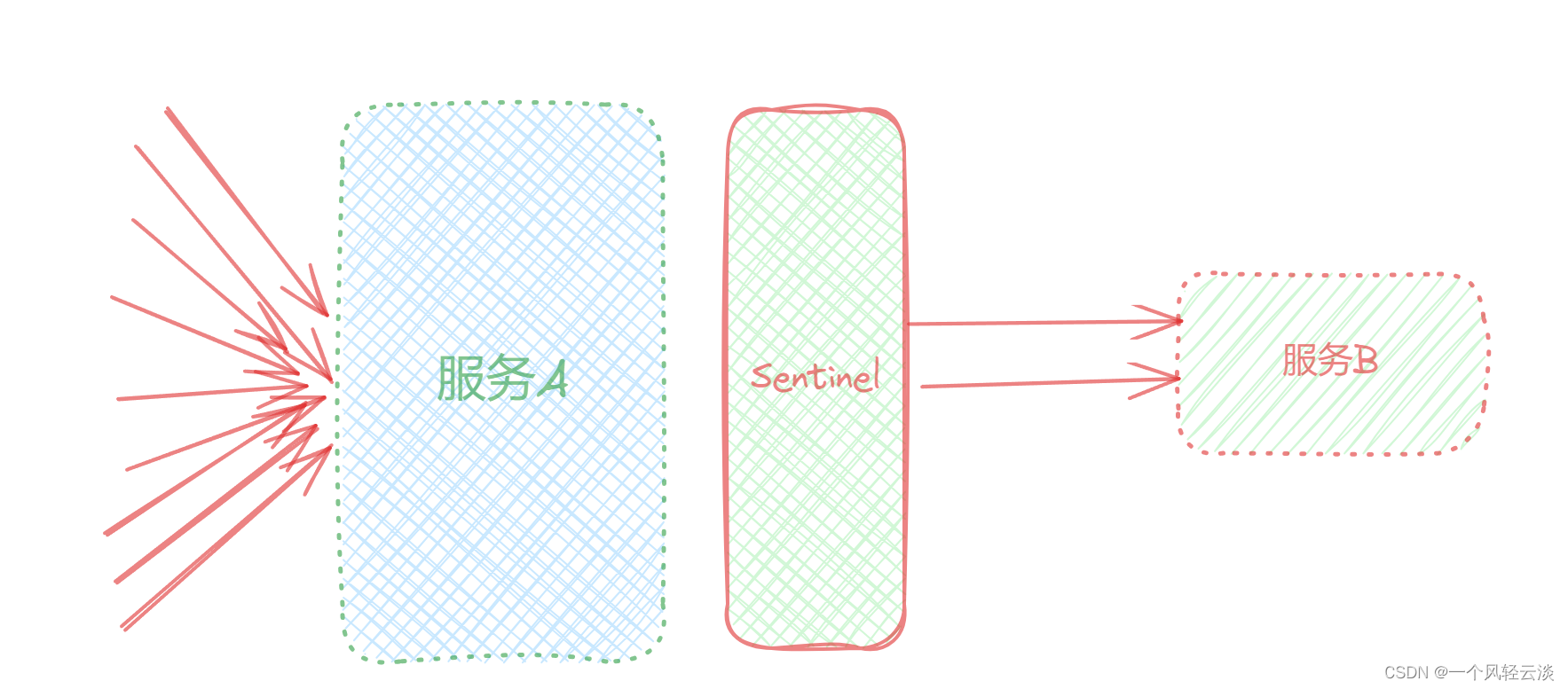
熔断模式和隔离模式都属于出错后的容错处理机制,而限流模式则可以称为预防模式。限流模式主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。这种模式不能解决服务依赖的问题,只能解决系统整体资源分配问题,因为没有被限流的请求依然有可能造成雪崩效应。
流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。
超时处理
设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。超时分两种,一种是请求的等待超时,一种是请求运行超时。
- 等待超时:在任务入队列时设置任务入队列时间,并判断队头的任务入队列时间是否大于超时时间,超过则丢弃任务。
- 运行超时:直接可使用线程池提供的get方法。
(1)线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
(2)信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
总结
限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
服务保护技术对比
在SpringCloud当中支持多种服务保护技术:
-
Netfix Hystrix
-
Sentinel
-
Resilience4J
早期比较流行的是Hystrix框架,但目前国内实用最广泛的还是阿里巴巴的Sentinel框架,这里我们做下对比:
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于慢调用比例或异常比例 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速排队模式 | 不支持 |
| 系统自适应保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
![2023年中国特种运输现状及市场格局分析[图]](https://img-blog.csdnimg.cn/img_convert/1e91aae61ea65f04cc4b1bb9a12f91e3.png)












![[SHCTF 2023新生赛] web题解](https://img-blog.csdnimg.cn/1388309dbbaa425eb305311ea2762dc0.png)