基于WIN10的64位系统演示
一、写在前面
这一期,我们介绍融合模型模型。
(1)数据源:
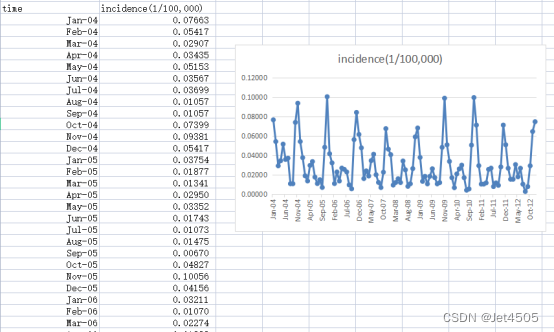
《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome in Jiangsu Province, China》文章的公开数据做演示。数据为江苏省2004年1月至2012年12月肾综合症出血热月发病率。运用2004年1月至2011年12月的数据预测2012年12个月的发病率数据。
(2)融合策略:
时间序列模型融合是指将多种时间序列模型的预测结果组合起来,以期获得比任何单一模型更好的预测效果。以下是一些常见的时间序列模型融合方法:
(a)简单平均法(Simple Averaging):简单地对所有模型的预测结果取平均值。这种方法假设每个模型都有相同的权重。
(b)加权平均法(Weighted Averaging):与简单平均法类似,但每个模型的预测结果按其权重进行加权平均。
(c)模型堆叠(Stacking):使用一个基学习器,例如LSTM、决策树等,将其他所有模型的预测结果作为输入,进行再次的预测。需要将数据集分为两部分或多部分,一部分用于训练初级模型,另一部分用于生成训练数据以训练次级模型。
(d)Bagging:对原始数据进行多次重采样生成多个子数据集,使用同一模型或多种模型对每个子数据集进行训练,对多个模型的预测结果进行平均或加权平均。
(e)Boosting:一个迭代的过程,其中每次迭代都会尝试修正之前所有模型的预测错误。
(f)深度学习模型的融合:设计一个深度学习架构,将多个模型的输出作为输入,进一步进行训练。
三、实战
(a)简单平均法
这个不用演示了吧,直接用把结果简单平均即可。
(b)加权平均法
该方法的关键在于权重如何确定,可以根据几个模型的训练误差来确定这些模型的权重。模型的权重可以被视为其训练误差的反比,这意味着误差越小的模型权重越大。这里的误差,MAE、MAPE、MSE和RMSE都可以。
举个例子:
假设三个模型的训练误差分别为:ARIMA为0.1,LSTM为0.09,KNN为0.15,那么它们的权重分别为:
ARIMA:(1/0.1)/(1/0.1+1/0.09+1/0.15)=9/25
LSTM:(1/0.09)/(1/0.1+1/0.09+1/0.15)=10/25
KNN:(1/0.15)/(1/0.1+1/0.09+1/0.15)=6/25
因此,融合模型的最终数值就是:
预测值 = 9/25 × ARIMA + 10/25 × LSTM + 6/25 × KNN
(c)模型堆叠
模型堆叠(Stacking)是一种集成学习方法,其目标是通过结合多个模型的预测来提高整体的预测准确性。下面是对所提策略的详细解释:
1)基学习器与次级学习器:
基学习器:这是第一层的模型,通常有多个。它们可以是任何类型的模型,例如决策树、神经网络、SVM等。
次级学习器:也被称为“元学习器”或“堆叠器”。这是第二层的模型,它的任务是学习如何最佳地结合基学习器的预测结果。在你描述的策略中,这个模型可以是LSTM、决策树等。
2)训练过程:
首先,将数据集分成至少两部分。例如,可以使用K折交叉验证的方法。使用一部分数据(例如K-1折)训练所有的基学习器。
然后,使用这些基学习器对剩下的一折数据进行预测。这些预测结果被称为“堆叠特征”。使用这些堆叠特征作为输入,对次级学习器进行训练。
3)预测过程:
对于一个新的输入样本,首先使用所有的基学习器进行预测。然后,使用这些预测作为次级学习器的输入,得到最终的预测结果。
4)代码如下:
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV, KFold
# 读取数据
data = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
lag_period = 6
# 创建滞后期特征
for i in range(lag_period, 0, -1):
data[f'lag_{i}'] = data['incidence'].shift(lag_period - i + 1)
data = data.dropna().reset_index(drop=True)
# 划分训练集和验证集
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]
# 定义特征和目标变量
features = ['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']
X_train = train_data[features]
y_train = train_data['incidence']
X_validation = validation_data[features]
y_validation = validation_data['incidence']
# KFold and Out-of-Fold Predictions
kf = KFold(n_splits=5, shuffle=True, random_state=42)
oof_predictions_svr = np.zeros(X_train.shape[0])
oof_predictions_tree = np.zeros(X_train.shape[0])
for train_idx, valid_idx in kf.split(X_train):
X_train_fold, X_valid_fold = X_train.iloc[train_idx], X_train.iloc[valid_idx]
y_train_fold, y_valid_fold = y_train.iloc[train_idx], y_train.iloc[valid_idx]
# Train SVM
param_grid_svr = {
'C': [0.1, 1, 10],
'epsilon': [0.01, 0.1, 1],
'kernel': ['linear', 'rbf']
}
grid_search_svr = GridSearchCV(SVR(), param_grid_svr, cv=5, scoring='neg_mean_squared_error')
grid_search_svr.fit(X_train_fold, y_train_fold)
best_svr = SVR(**grid_search_svr.best_params_)
best_svr.fit(X_train_fold, y_train_fold)
oof_predictions_svr[valid_idx] = best_svr.predict(X_valid_fold)
# Train Decision Tree
param_grid_tree = {
'max_depth': [None, 3, 5, 7, 9],
'min_samples_split': range(2, 11),
'min_samples_leaf': range(1, 11)
}
grid_search_tree = GridSearchCV(DecisionTreeRegressor(), param_grid_tree, cv=5, scoring='neg_mean_squared_error')
grid_search_tree.fit(X_train_fold, y_train_fold)
best_tree = DecisionTreeRegressor(**grid_search_tree.best_params_)
best_tree.fit(X_train_fold, y_train_fold)
oof_predictions_tree[valid_idx] = best_tree.predict(X_valid_fold)
X_train_stacked_oof = pd.DataFrame({
'svm': oof_predictions_svr,
'tree': oof_predictions_tree
})
# Train meta learner (Random Forest)
param_grid_rf = {
'n_estimators': [50, 100, 150],
'max_depth': [None, 5, 7],
}
grid_search_rf = GridSearchCV(RandomForestRegressor(), param_grid_rf, cv=5, scoring='neg_mean_squared_error')
grid_search_rf.fit(X_train_stacked_oof, y_train)
best_rf_oof = RandomForestRegressor(**grid_search_rf.best_params_)
best_rf_oof.fit(X_train_stacked_oof, y_train)
# Predict with base learners
validation_predictions_svr = []
validation_predictions_tree = []
for i in range(len(X_validation)):
if i == 0:
pred_svr = best_svr.predict([X_validation.iloc[0]])
pred_tree = best_tree.predict([X_validation.iloc[0]])
else:
new_features = list(X_validation.iloc[i, 1:]) + [pred_svr[0]]
pred_svr = best_svr.predict([new_features])
new_features = list(X_validation.iloc[i, 1:]) + [pred_tree[0]]
pred_tree = best_tree.predict([new_features])
validation_predictions_svr.append(pred_svr[0])
validation_predictions_tree.append(pred_tree[0])
# Use predictions from base learners as new features
X_validation_stacked = pd.DataFrame({
'svm': validation_predictions_svr,
'tree': validation_predictions_tree
})
# Predict with meta learner
y_validation_pred_stacked_oof = best_rf_oof.predict(X_validation_stacked)
def mean_absolute_percentage_error(y_true, y_pred):
y_true, y_pred = np.array(y_true), np.array(y_pred)
# Avoid division by zero
non_zero_indices = y_true != 0
return np.mean(np.abs((y_true[non_zero_indices] - y_pred[non_zero_indices]) / y_true[non_zero_indices])) * 100
# Calculate evaluation metrics for training set
mae_train_oof = mean_absolute_error(y_train, best_rf_oof.predict(X_train_stacked_oof))
mape_train_oof = mean_absolute_percentage_error(y_train, best_rf_oof.predict(X_train_stacked_oof))
mse_train_oof = mean_squared_error(y_train, best_rf_oof.predict(X_train_stacked_oof))
rmse_train_oof = np.sqrt(mse_train_oof)
# Calculate evaluation metrics for validation set
mae_validation_oof = mean_absolute_error(y_validation, y_validation_pred_stacked_oof)
mape_validation_oof = mean_absolute_percentage_error(y_validation, y_validation_pred_stacked_oof)
mse_validation_oof = mean_squared_error(y_validation, y_validation_pred_stacked_oof)
rmse_validation_oof = np.sqrt(mse_validation_oof)
# Prepare the metrics for display
metrics_df = pd.DataFrame({
'Metric': ['MAE', 'MAPE', 'MSE', 'RMSE'],
'Training Set': [mae_train_oof, mape_train_oof, mse_train_oof, rmse_train_oof],
'Validation Set': [mae_validation_oof, mape_validation_oof, mse_validation_oof, rmse_validation_oof]
})
metrics_df解读:首先在训练数据上使用K折交叉验证训练基学习器(SVM和决策树),并使用其预测结果作为新特征训练次级学习器(随机森林)。然后,使用基学习器对验证数据进行预测,并使用这些预测结果作为新特征,让次级学习器进行预测,结果如下:
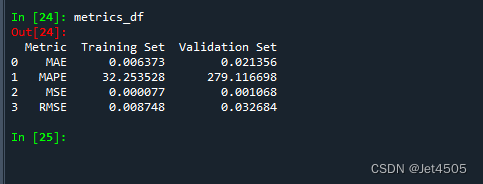
感觉吧,一顿骚操作,效果一般般。当然可能是组合的不好。
(d)Bagging
Bagging是Bootstrap Aggregating的缩写,是一种集成学习方法,它通过从训练数据中采样多个子集(使用重采样)并在每个子集上训练模型来工作。预测结果是所有模型预测结果的平均值(对于回归问题)或是最常见的类别(对于分类问题)。Bagging的主要目的是减少模型的方差,特别是对于容易过拟合的模型,例如决策树。Bagging可以应用于多种机器学习算法,不仅仅是决策树。
随机森林是一种特定的Bagging实现,它专门用于决策树。除了使用Bagging方法外,随机森林在每次分裂时还采用了随机特征选择,这意味着它在决策树的每个节点都会随机选择一部分特征来考虑分裂。这种随机性的引入旨在确保每棵树都是不同的,从而进一步增强整体模型的鲁棒性。
随机森林介绍过了,我们来介绍基于SVM的Bagging:
# 读取数据
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import BaggingRegressor
data = pd.read_csv('data.csv')
# 将时间列转换为日期格式
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
# 拆分输入和输出
lag_period = 6
# 创建滞后期特征
for i in range(lag_period, 0, -1):
data[f'lag_{i}'] = data['incidence'].shift(lag_period - i + 1)
# 删除包含NaN的行
data = data.dropna().reset_index(drop=True)
# 划分训练集和验证集
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]
# 定义特征和目标变量
X_train = train_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']]
y_train = train_data['incidence']
X_validation = validation_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']]
y_validation = validation_data['incidence']
# 初始化SVR模型
svr_model = SVR()
# 定义参数网格
param_grid = {
'C': [0.1, 1, 10],
'epsilon': [0.01, 0.1, 1],
'kernel': ['linear', 'rbf']
}
# 初始化网格搜索
grid_search = GridSearchCV(svr_model, param_grid, cv=5, scoring='neg_mean_squared_error')
# 进行网格搜索
grid_search.fit(X_train, y_train)
# 获取最佳参数
best_params = grid_search.best_params_
# 使用最佳参数初始化SVR模型,并使用Bagging
best_svr_model = BaggingRegressor(base_estimator=SVR(**best_params), n_estimators=10, random_state=42)
best_svr_model.fit(X_train, y_train)
# 对于验证集,我们需要迭代地预测每一个数据点
y_validation_pred = []
for i in range(len(X_validation)):
if i == 0:
pred = best_svr_model.predict([X_validation.iloc[0]])
else:
new_features = list(X_validation.iloc[i, 1:]) + [pred[0]]
pred = best_svr_model.predict([new_features])
y_validation_pred.append(pred[0])
y_validation_pred = np.array(y_validation_pred)
# 计算验证集上的MAE, MAPE, MSE和RMSE
mae_validation = mean_absolute_error(y_validation, y_validation_pred)
mape_validation = np.mean(np.abs((y_validation - y_validation_pred) / y_validation))
mse_validation = mean_squared_error(y_validation, y_validation_pred)
rmse_validation = np.sqrt(mse_validation)
# 计算训练集上的MAE, MAPE, MSE和RMSE
y_train_pred = best_svr_model.predict(X_train)
mae_train = mean_absolute_error(y_train, y_train_pred)
mape_train = np.mean(np.abs((y_train - y_train_pred) / y_train))
mse_train = mean_squared_error(y_train, y_train_pred)
rmse_train = np.sqrt(mse_train)
print("Train Metrics:", mae_train, mape_train, mse_train, rmse_train)
print("Validation Metrics:", mae_validation, mape_validation, mse_validation, rmse_validation)解读:首先导入BaggingRegressor,创建一个BaggingRegressor实例,其基学习器是使用网格搜索找到的最佳参数的SVM,最后使用Bagging进行训练和预测。看看结果:

大同小异的感觉。
(e)Boosting
这个不用介绍了吧,之前的各种boost系列就是了。
(f)深度学习模型的融合
设计一个深度学习架构,将多个模型的输出作为输入,进一步进行训练。其实很类似之前说的模型堆叠了,只不过次级模型我们自己设计模型框架而已。
以下是如何使用Keras来实现深度学习模型的融合的一个基本示范:
1)首先,为每个模型训练一个独立的模型并保存预测结果。
2)使用这些预测结果作为新的特征,输入到一个深度学习模型中进行训练。
代码的示例:
import numpy as np
from keras.models import Model
from keras.layers import Dense, Input, Concatenate
# 假设我们已经有了3个模型的预测输出
model_1_preds = np.random.rand(1000, 1)
model_2_preds = np.random.rand(1000, 1)
model_3_preds = np.random.rand(1000, 1)
# 这是真实的目标值
y_true = np.random.rand(1000, 1)
# 将3个模型的输出合并为一个新的输入特征
merged_inputs = np.concatenate([model_1_preds, model_2_preds, model_3_preds], axis=1)
# 定义深度学习模型的结构
input_layer = Input(shape=(3,))
dense_1 = Dense(10, activation='relu')(input_layer)
dense_2 = Dense(10, activation='relu')(dense_1)
output_layer = Dense(1)(dense_2)
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(merged_inputs, y_true, epochs=50, batch_size=32)解读:在上述示例中,我们创建了一个简单的神经网络,该网络接收三个模型的预测输出作为输入,并进行进一步的训练。这只是一个基本的例子,实际应用中可能会更复杂。
深度学习模型融合的关键是选择合适的网络结构、损失函数和优化器,以及确保你有足够的数据来训练融合模型。如果数据很少,使用深度学习模型进行融合可能会导致过拟合。
四、写在后面
组合模型不是万能的,还得看数据,因地制宜!!!
不要为了融合而融合!!!
五、数据
链接:https://pan.baidu.com/s/1r32fnMI69LgfxEWa7MHt9w?pwd=62uh
提取码:62uh