最近看了lotusdb的源码。lotusdb是一个golang实现的嵌入式的持久化kv存储。
从整体设计上看,lotusdb采用了类似LSM树的架构,并采用了针对SSD的优化,将key和value分开存储。在此基础上,lotusdb将LSM树中存储key的SST使用B+树或者hash table的索引替换。lotusdb作者认为该设计消除了多级SST带来的读放大问题,使lotusdb的读性能更加稳定。这确实没有问题,这样的设计使lotusdb平衡了B+树和LSM树的缺点,同时也平衡了两者的优点,使得lotusdb变得中庸。(中庸不一定不好,实际生产的效果如何还是要看在具体场景下的性能数据)另外,lotusdb还有几个缺陷:
- 目前并没有提供范围查询的接口;
- 没有事务的保证;
- 在容灾恢复方面有所缺陷;
总的来说,博主认为lotusdb还是一个相对比较稚嫩但挺有意思的项目,如果感兴趣,不妨一读。
文章目录
- 整体架构
- 写入流程
- 后台flush
- 读取流程
- 压缩
- 实现原理
- 具体实现
- Index
- B+树
- Hash table
- 容灾恢复
- 总结
整体架构
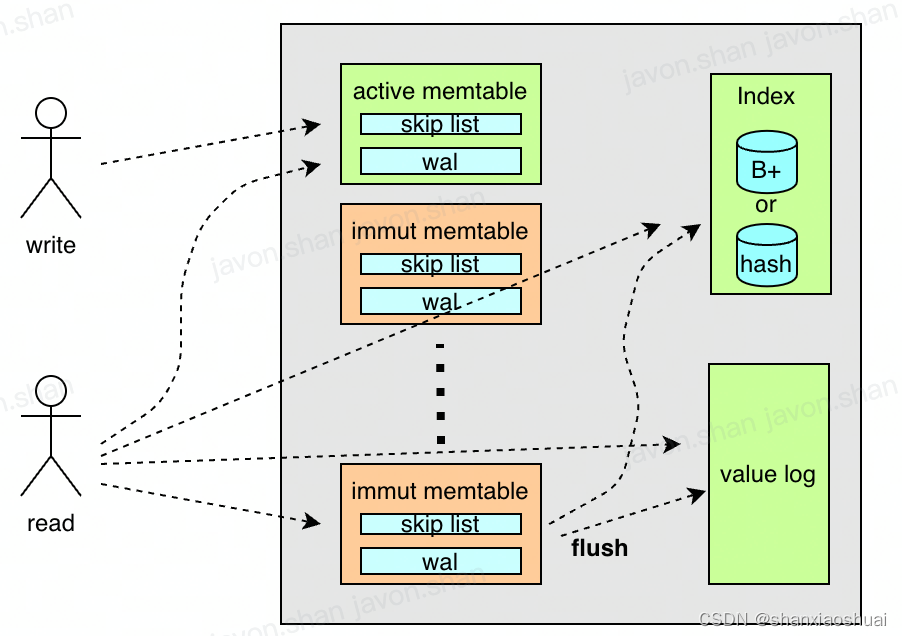
lotusdb的整体架构图如下。lotusdb通过memtable的来缓存用户的写入。其维护多个memtable,最新的一个为active memtable,可以写入;其余为immutable memtable,只读。memtable将写入的key和value维护在内存中的跳表中,并通过wal来保证持久性。immutable memtable会定期的在后台刷入持久化存储。
lotusdb采用了针对ssd的优化,将key和value分开存储。key存储在Index中,value存储在value log中。value log比较简单,是多分片的wal;key的部分,Index为接口,lotusdb中没有提供经典LSM树中多层级SST的实现,只提供了B+树(boltdb)和hash table的实现。
写入流程
写入时,将数据写入active memtable即可返回。memtable由wal和内存态的跳表组成。写入时先将数据写入wal,以保证数据的持久性,再将数据插入跳表。active memtable数据满了后,会创建新的memtable,并将当前active memtable转变为immutable memtable,在后台刷入持久化存储。
后台flush
active memtable在写满以后会转变为immutable memtable,并在后台刷入。首先会将对应表中的内容写入value log。value log的实现比较简单,采用多分片的wal,所以value log的写入为批量的追加写。在value log写入完成后,得到key及对应的值在vlaue log中的位置,将key和position的键值对写入Index。对于Index的写入,无论是B+树还是hash表,这里的写入都是批量的随机写。
LSM树的设计就是通过牺牲读性能来提升写性能。lotus的这一揉杂了B+树和LSM树,其读取性能会比LSM好,但会比B+树差;写入性能会比B+树好,但是会比LSM树差(单纯从设计上分析,实际效果得看具体场景下的数据)。这就是文章开头提到的,会使lotusdb变得中庸。当然中庸并不是个贬义词。
读取流程
在读取时,会依次读取memtable。如果获取到数据则直接返回,否则去查询Index,根据postion信息去value log中获取值并返回。
压缩
在LSM树中,多级SST的设计保证了批量追加写来优化写入性能,但同时带来了读放大和冗余数据的问题。除此之外,SST的compact也是一个复杂度比较高的问题。第一是后台的compact会极大的影响性能,博主曾经就遇到过因为es后台compact消耗大量资源导致写入超时的问题。另一个是compact本身的实现复杂度就相对较高,基于LSM的存储有各种不同的compact策略,感兴趣可以自己去查阅,这里不做展开。
在lotusdb中,Index没有提供SST的实现,而是提供了B+树或者hash table的实现,所以key的部分不需要考虑compact。但是value log的是完全追加写,还是需要compact来消除冗余数据。目前lotusdb仅是提供了compact方法供上层调用,但是没有提供具体的compact策略,这对上层来说是不够友好的。
实现原理
原理部分,主要基于WiscKey: Separating Keys from Values
in SSD-conscious Storage,会单独开一篇进行讲解。
具体实现
lotusdb的主要实现如下。和整体架构部分介绍的一样,主要有三大部分组成:
- memtables。分为active memtable和immutable memtable。
- index。实现Index接口的索引,目前lotusdb提供了B+树和hash table的实现,用来存储key以及对应value在value log中的位置。
- vlog。用来存储实际的值。
type DB struct {
activeMem *memtable // Active memtable for writing.
immuMems []*memtable // Immutable memtables, waiting to be flushed to disk.
index Index // index is multi-partition indexes to store key and chunk position.
vlog *valueLog // vlog is the value log.
fileLock *flock.Flock // fileLock to prevent multiple processes from using the same database directory.
flushChan chan *memtable // flushChan is used to notify the flush goroutine to flush memtable to disk.
flushLock sync.Mutex // flushLock is to prevent flush running while compaction doesn't occur
mu sync.RWMutex
closed bool
options Options
batchPool sync.Pool // batchPool is a pool of batch, to reduce the cost of memory allocation.
}
Index
Index接口定义如下。上面也多次提到了,对于Index,lotus提供了B+树和hash table的实现。
type Index interface {
// PutBatch put batch records to index
PutBatch([]*KeyPosition) error
// Get chunk position by key
Get([]byte) (*KeyPosition, error)
// DeleteBatch delete batch records from index
DeleteBatch([][]byte) error
// Sync sync index data to disk
Sync() error
// Close index
Close() error
}
B+树
B+树的实现如下,可以看到其底层采用了多个blotdb来实现。
关于boltdb,前面我们介绍过,这里就不多介绍,可以参见【存储】etcd的存储是如何实现的(3)-blotdb。
// BPTree is the BoltDB index implementation.
type BPTree struct {
options indexOptions
trees []*bbolt.DB
}
Hash table
Hash table的实现同样采用了多个分片的hash表。
type HashTable struct {
options indexOptions
tables []*diskhash.Table
}
hash表的实现如下。
该hash表要求value的长度固定,所以适应的场景有限,大多数适合来防止metadata等。每个hash表持有两个文件,分布为primary file和overflow file。其中主要的数据结构为bucket,每个bucket中含有31个slot及一个offset,slot中存储了key及value,offset指向overflow的bucket来解决hash冲突的问题。
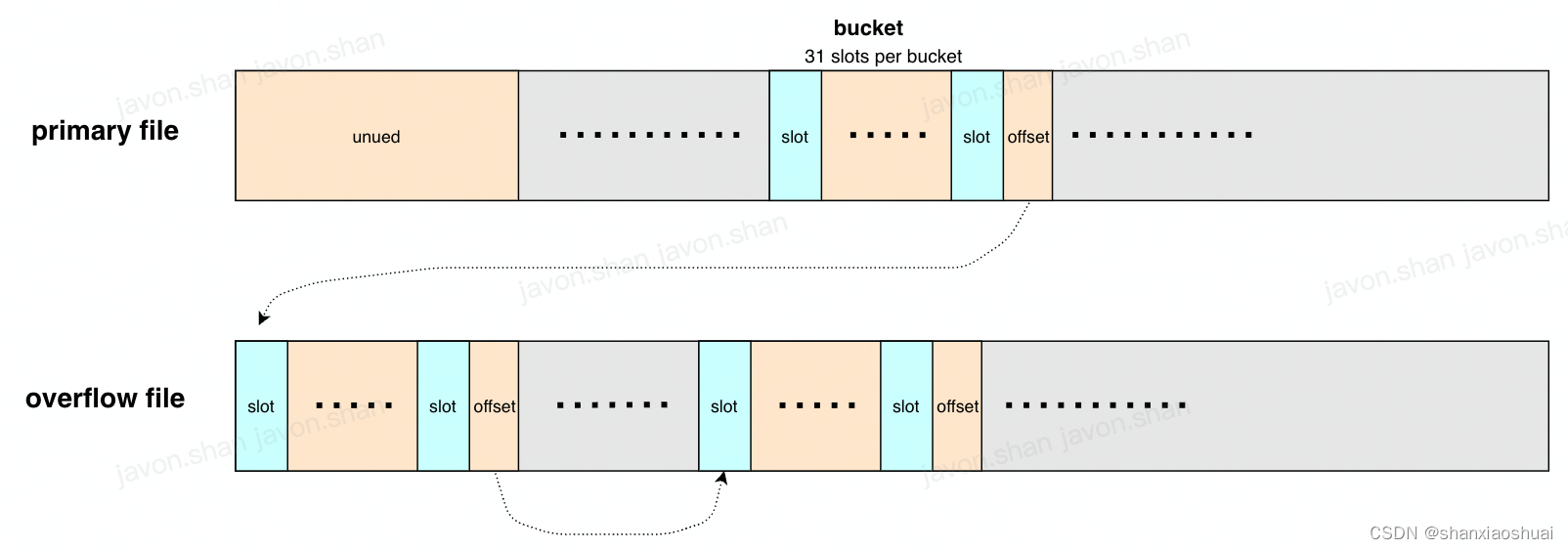
- 读取时,首先根据key来得到primary file中的bucket的index,根据index可以计算出该bucket的offset(每个bucket大小固定)。然后遍历该bucket中的slot,如果没有匹配,则根据offset继续遍历overflow bucket,直到匹配或者遍历结束。
- 写入时,同样根据key来得到primary file中bucket的offset,遍历该bucket及其overflow bucket中的slot,找到匹配的slot或者空的slot。如果有匹配的slot,则进行update,如果有空的slot,则进行insert。如果既没有匹配的slot,也没有空的slot,则会创建新的overflow bucket并进行写入。
- 每次写入成功后,会根据load factor来判断是否需要分裂。如果当前负载大于load factor,则会在primary中创建新的bucket并进行rebalance。
容灾恢复
博主认为lotusdb作为一个持久化存储,最有问题的地方在于其容灾恢复方面。
- 下面是后台刷新的过程,可以看到当flushMemtable方法出错中断,也就是一个immutable写入index和vlog出错了,并没有做任何的补救措施。而是继续刷新过程,这个过程就可能会导致数据的丢失。
func (db *DB) listenMemtableFlush() {
sig := make(chan os.Signal, 1)
signal.Notify(sig, os.Interrupt, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
for {
select {
case table := <-db.flushChan:
db.flushMemtable(table)
case <-sig:
return
}
}
}
func (db *DB) flushMemtable(table *memtable) {
db.flushLock.Lock()
sklIter := table.skl.NewIterator()
var deletedKeys [][]byte
var logRecords []*ValueLogRecord
// iterate all records in memtable, divide them into deleted keys and log records
for sklIter.SeekToFirst(); sklIter.Valid(); sklIter.Next() {
key, valueStruct := y.ParseKey(sklIter.Key()), sklIter.Value()
if valueStruct.Meta == LogRecordDeleted {
deletedKeys = append(deletedKeys, key)
} else {
logRecord := ValueLogRecord{key: key, value: valueStruct.Value}
logRecords = append(logRecords, &logRecord)
}
}
_ = sklIter.Close()
// write to value log, get the positions of keys
keyPos, err := db.vlog.writeBatch(logRecords)
if err != nil {
log.Println("vlog writeBatch failed:", err)
db.flushLock.Unlock()
return
}
// sync the value log
if err := db.vlog.sync(); err != nil {
log.Println("vlog sync failed:", err)
db.flushLock.Unlock()
return
}
// write all keys and positions to index
if err := db.index.PutBatch(keyPos); err != nil {
log.Println("index PutBatch failed:", err)
db.flushLock.Unlock()
return
}
// delete the deleted keys from index
if err := db.index.DeleteBatch(deletedKeys); err != nil {
log.Println("index DeleteBatch failed:", err)
db.flushLock.Unlock()
return
}
// sync the index
if err := db.index.Sync(); err != nil {
log.Println("index sync failed:", err)
db.flushLock.Unlock()
return
}
// delete the wal
if err := table.deleteWAl(); err != nil {
log.Println("delete wal failed:", err)
db.flushLock.Unlock()
return
}
// delete old memtable kept in memory
db.mu.Lock()
if len(db.immuMems) == 1 {
db.immuMems = db.immuMems[:0]
} else {
db.immuMems = db.immuMems[1:]
}
db.mu.Unlock()
db.flushLock.Unlock()
}
总结
就如文章开始所讲,博主认为lotusdb还是一个相对比较稚嫩但挺有意思的项目,能够反映出作者的一些有意思的想法。其中的问题,随着迭代也会慢慢完善。
如果觉得本文对您有帮助,可以请博主喝杯咖啡~








![SHCTF2023 山河CTF Reverse方向[Week1]全WP 详解](https://img-blog.csdnimg.cn/2d40c31e10b54238b566420c750bb564.png)