高级特性篇(九)
切片
在Python中,切片(slice)是对序列型对象(如list, string, tuple)的一种高级索引方法。普通索引只取出序列中一个下标对应的元素,而切片取出序列中一个范围对应的元素,这里的范围不是狭义上的连续片段。
要创建切片,可指定要使用的第一个元素和最后一个元素的索引。与函数range() 一样,Python在到达你指定的第二个索引前面的元素后停止。要输出列表中的前三个元素,需要指定索引0~3,这将输出分别为0 、1 和2 的元素。
下面的示例处理的是一个运动队成员列表:
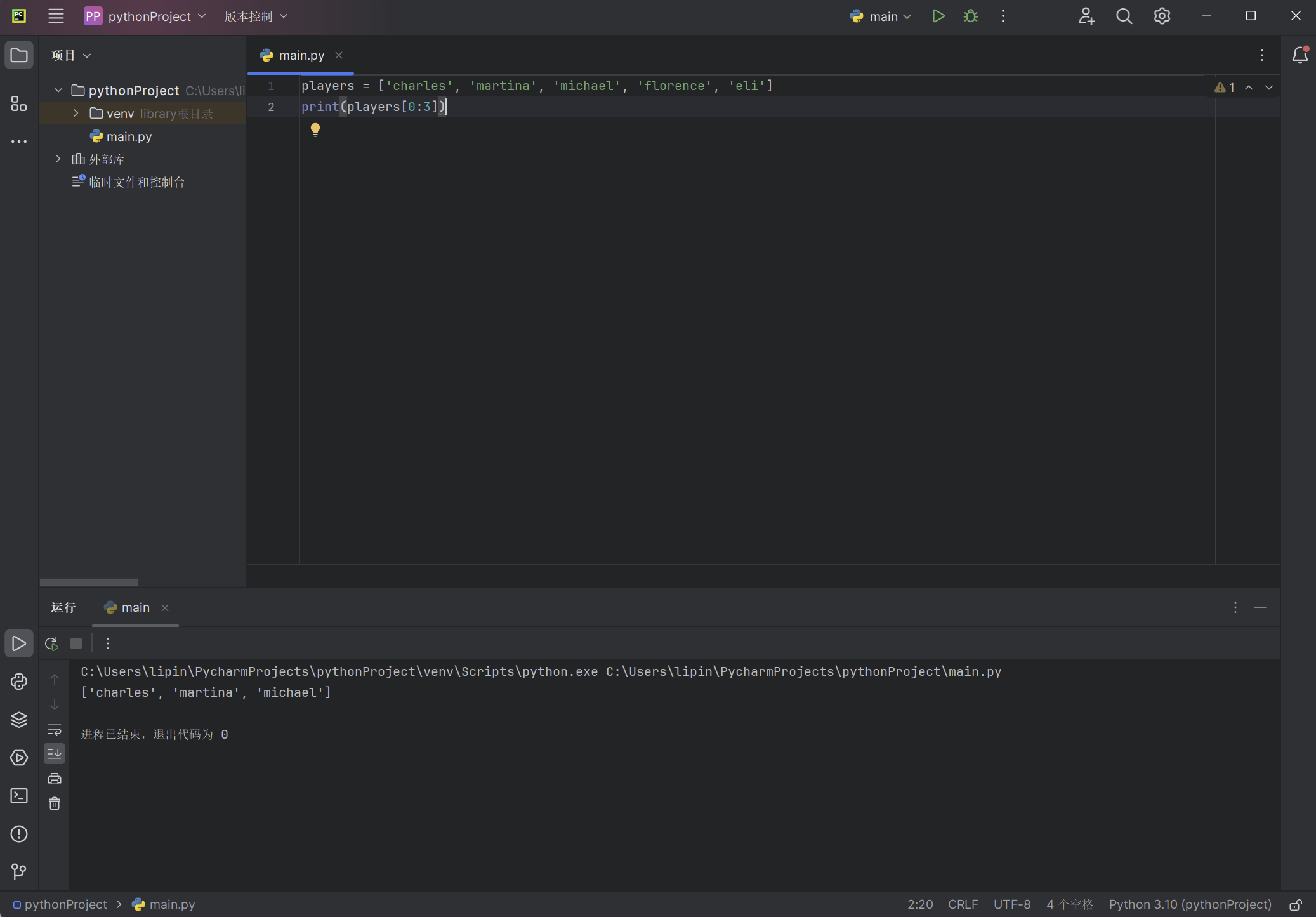
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print(players[0:3])
代码打印该列表的一个切片,其中只包含三名队员。输出也是一个列表,其中包含前三名队员:
你可以生成列表的任何子集,例如,如果你要提取列表的第2~4个元素,可将起始索引指定为1 ,并将终止索引指定为4 :
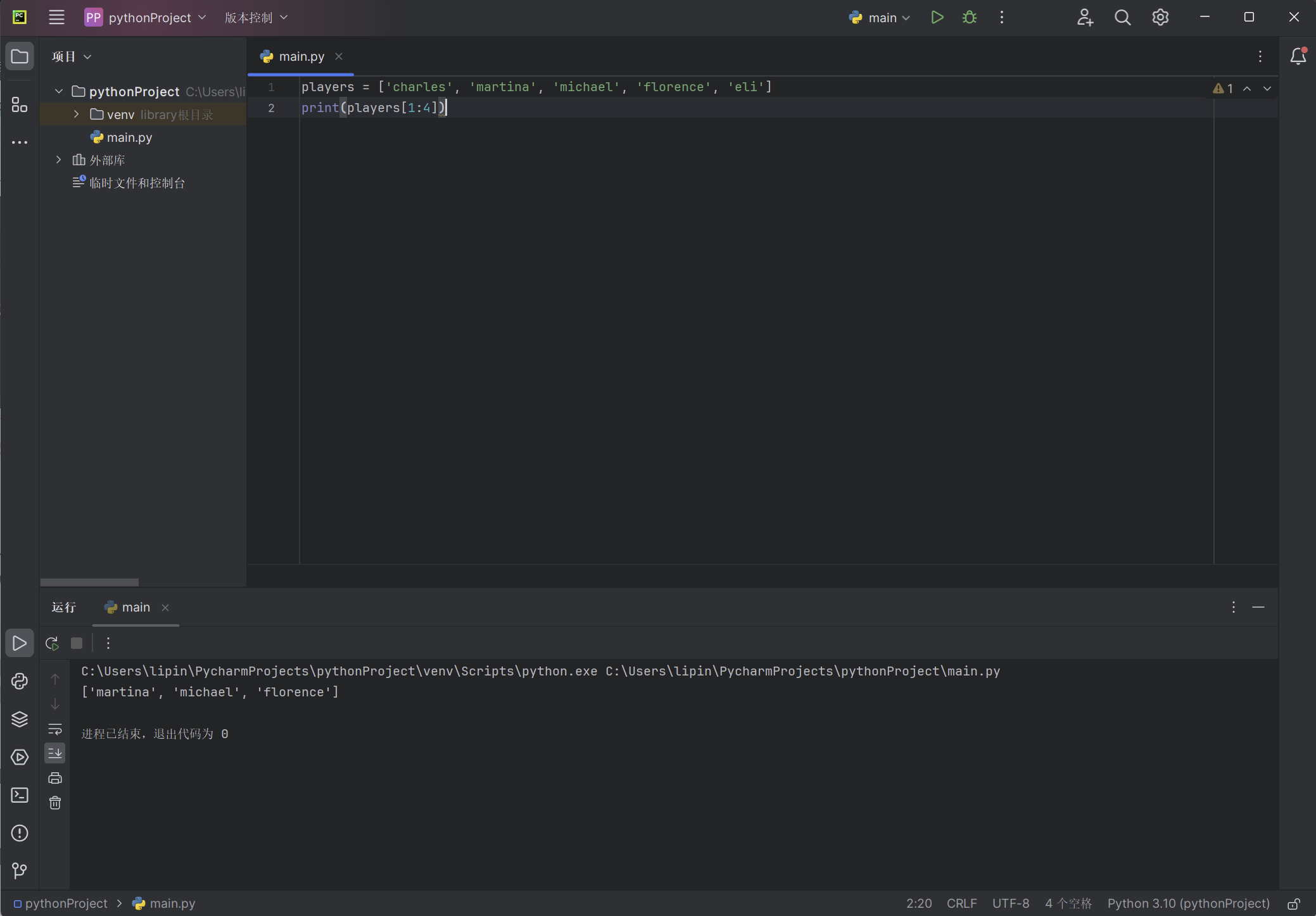
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print(players[1:4])
这一次,切片始于’marita’ ,终于’florence’ :
如果你没有指定第一个索引,Python将自动从列表开头开始:
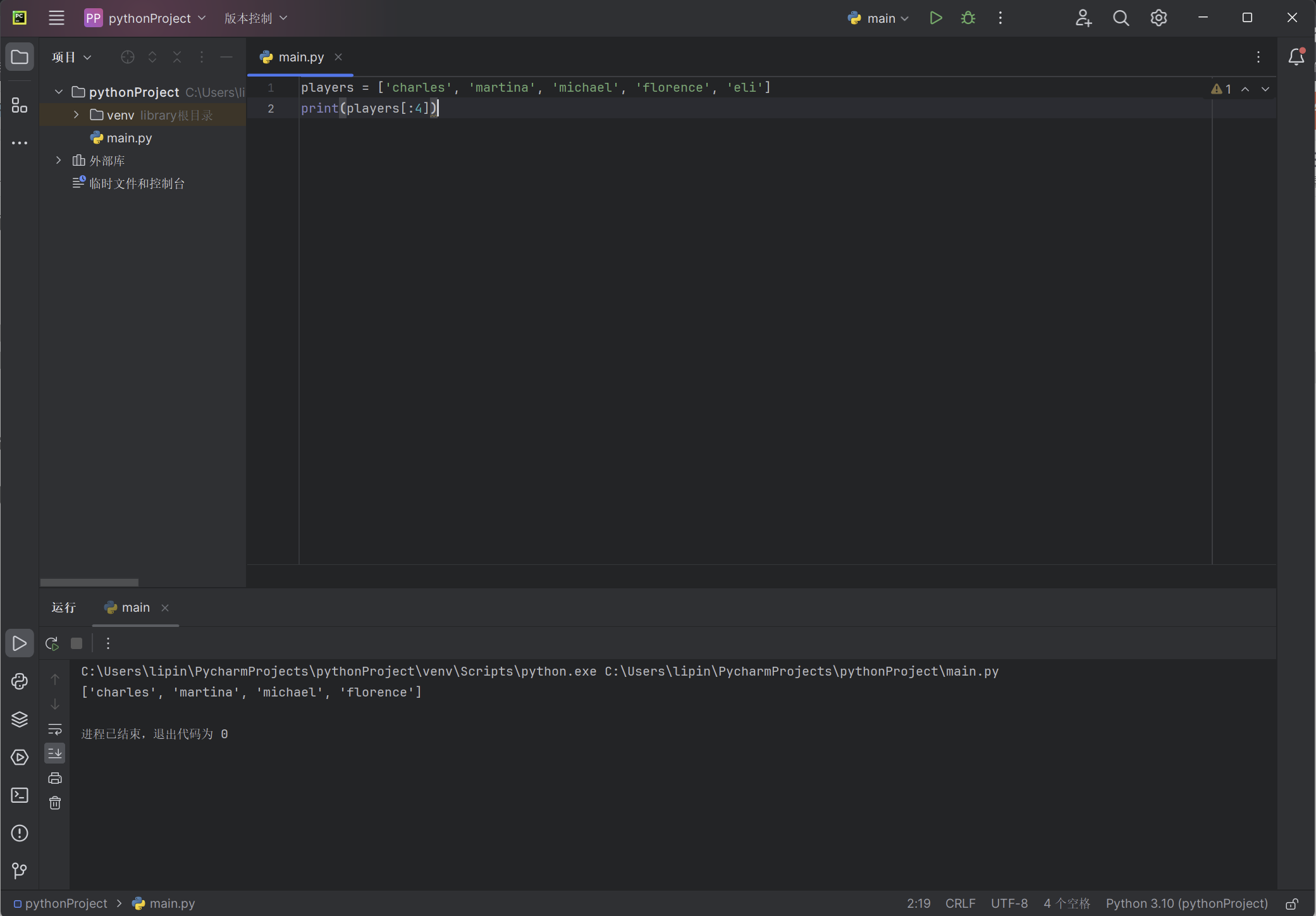
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print(players[:4])
由于没有指定起始索引,Python从列表开头开始提取:
要让切片终止于列表末尾,也可使用类似的语法。例如,如果要提取从第3个元素到列表末尾的所有元素,可将起始索引指定为2 ,并省略终止索引:
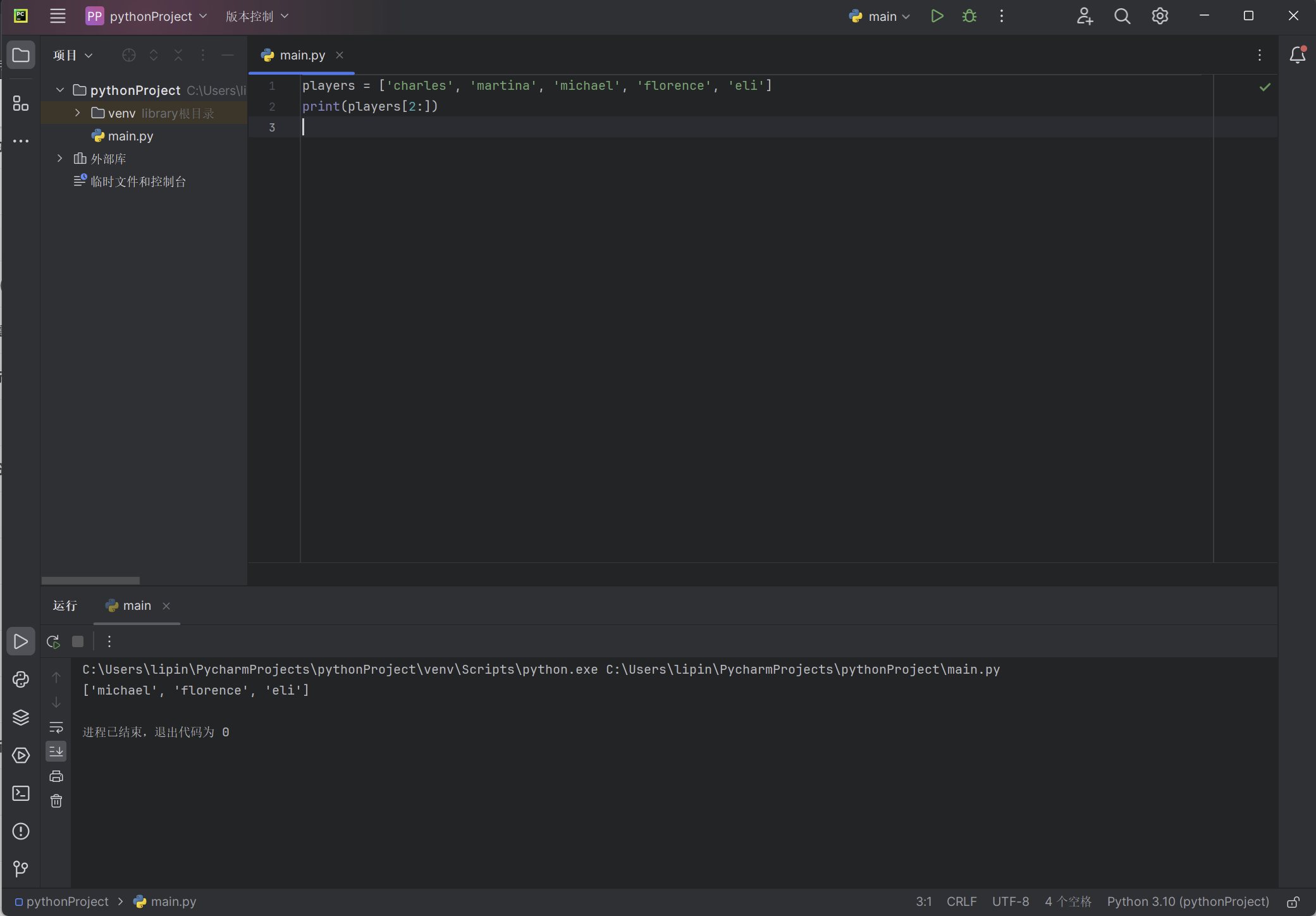
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print(players[2:])
Python将返回从第3个元素到列表末尾的所有元素:
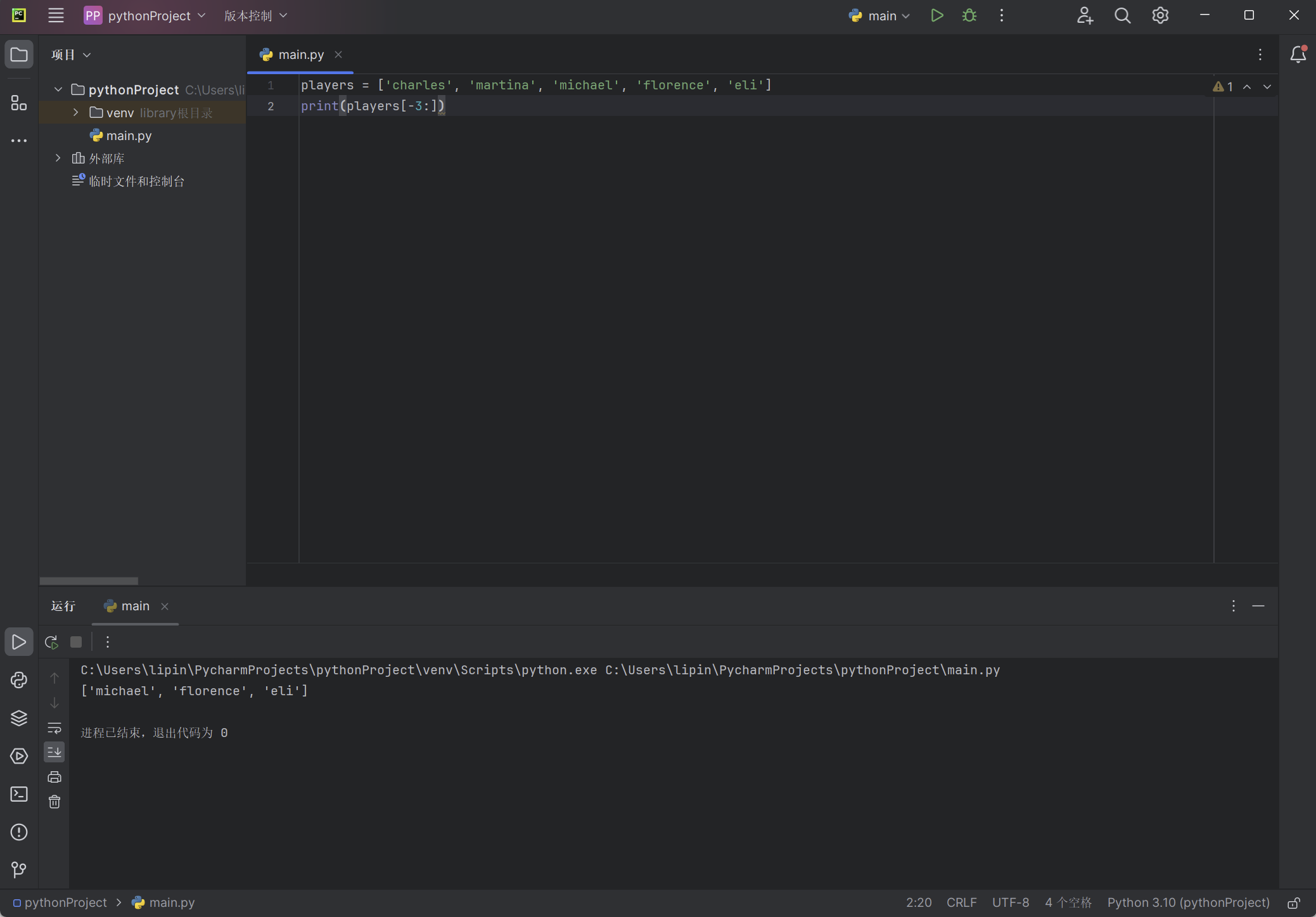
无论列表多长,这种语法都能够让你输出从特定位置到列表末尾的所有元素。本书前面说过,负数索引返回离列表末尾相应距离的元素,因此你可以输出列表末尾的任何切片。例如,如果你要输出名单上的最后三名队员,可使用切片players[-3:] :
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print(players[-3:])
上述代码打印最后三名队员的名字,即便队员名单的长度发生变化,也依然如此:
如果要遍历列表的部分元素,可在for 循环中使用切片。在下面的示例中,我们遍历前三名队员,并打印他们的名字:
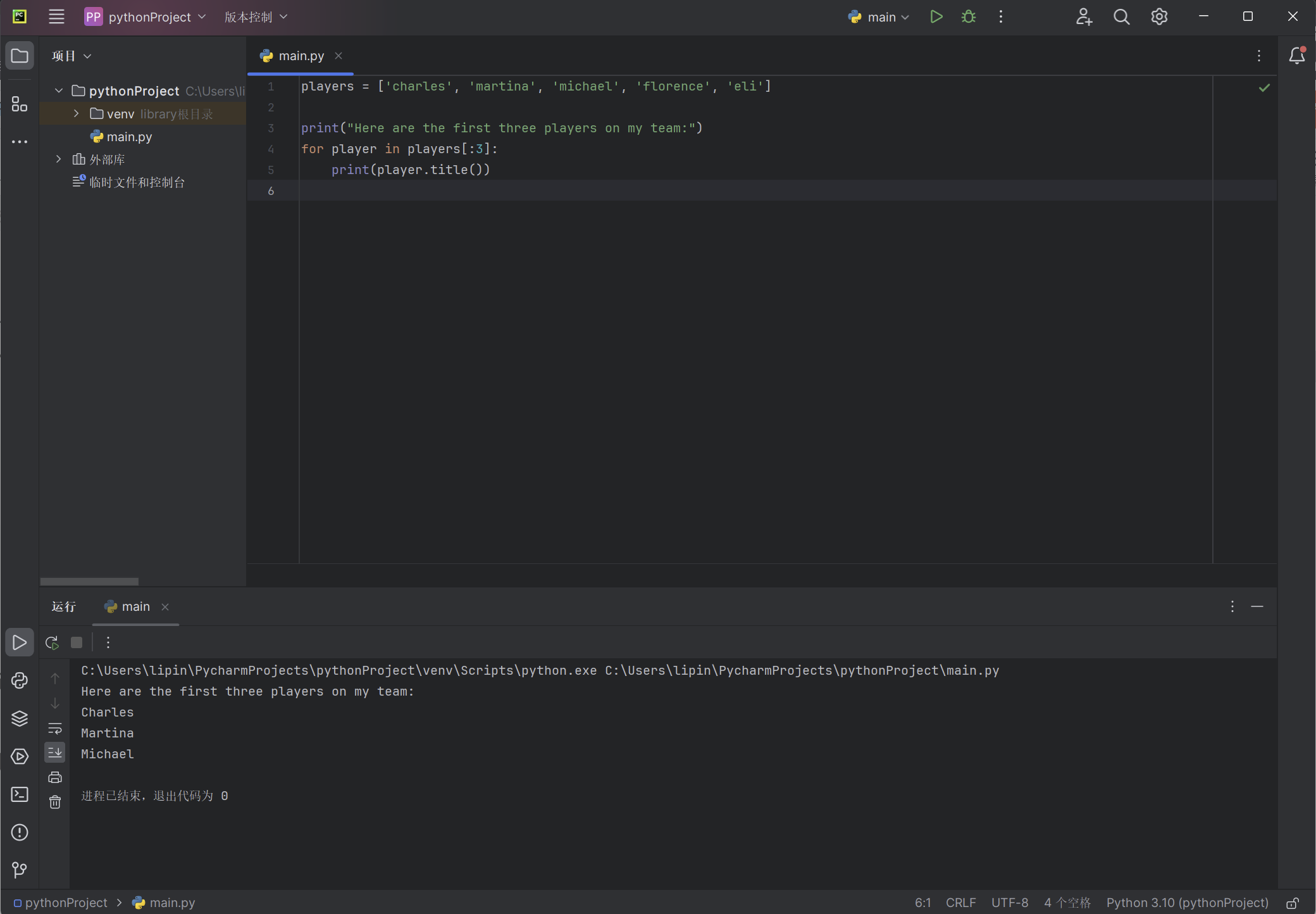
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print("Here are the first three players on my team:")
for player in players[:3]:
print(player.title())
代码没有遍历整个队员列表,而只遍历前三名队员:
在很多情况下,切片都很有用。例如,编写游戏时,你可以在玩家退出游戏时将其最终得分加入到一个列表中。然后,为获取该玩家的三个最高得分,你可以将该列表按降序排列,再创建一个只包含前三个得分的切片。处理数据时,可使用切片来进行批量处理;编写Web应用程序时,可使用切片来分页显示信息,并在每页显示数量合适的信息。
你经常需要根据既有列表创建全新的列表。下面来介绍复制列表的工作原理,以及复制列表可提供极大帮助的一种情形。
要复制列表,可创建一个包含整个列表的切片,方法是同时省略起始索引和终止索引([:] )。这让Python创建一个始于第一个元素,终止于最后一个元素的切片,即复制整个列表。
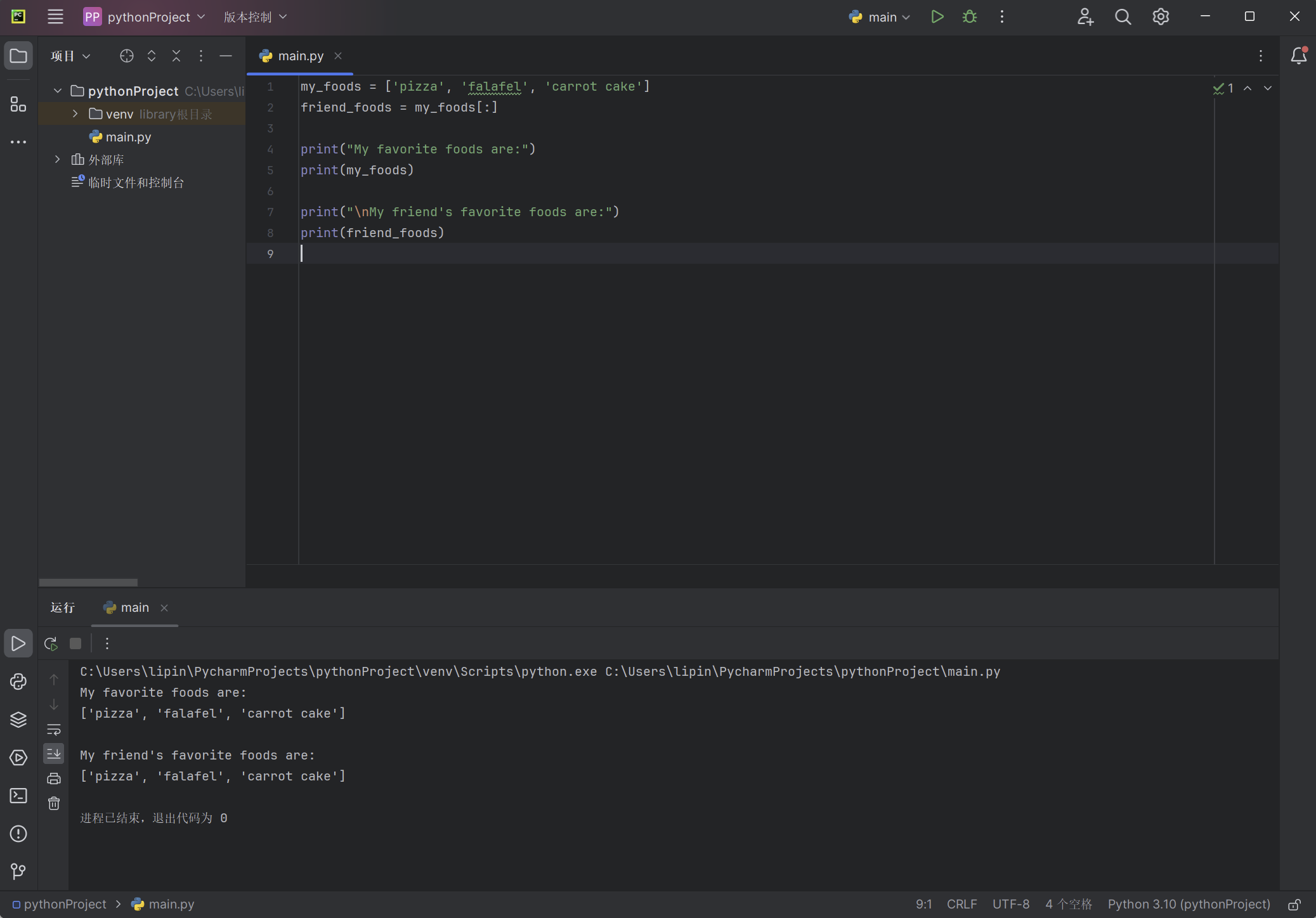
例如,假设有一个列表,其中包含你最喜欢的四种食品,而你还想创建另一个列表,在其中包含一位朋友喜欢的所有食品。不过,你喜欢的食品,这位朋友都喜欢,因此你可以通过复制来创建这个列表:
my_foods = ['pizza', 'falafel', 'carrot cake']
friend_foods = my_foods[:]
print("My favorite foods are:")
print(my_foods)
print("\nMy friend's favorite foods are:")
print(friend_foods)
我们首先创建了一个名为my_foods 的食品列表),然后创建了一个名为friend_foods 的新列表。我们在不指定任何索引的情况下从列表my_foods 中提取一个切片,从而创建了这个列表的副本,再将该副本存储到变量friend_foods 中。打印每个列表后,我们发现它们包含的食品相同:
为核实我们确实有两个列表,下面在每个列表中都添加一种食品,并核实每个列表都记录了相应人员喜欢的食品:
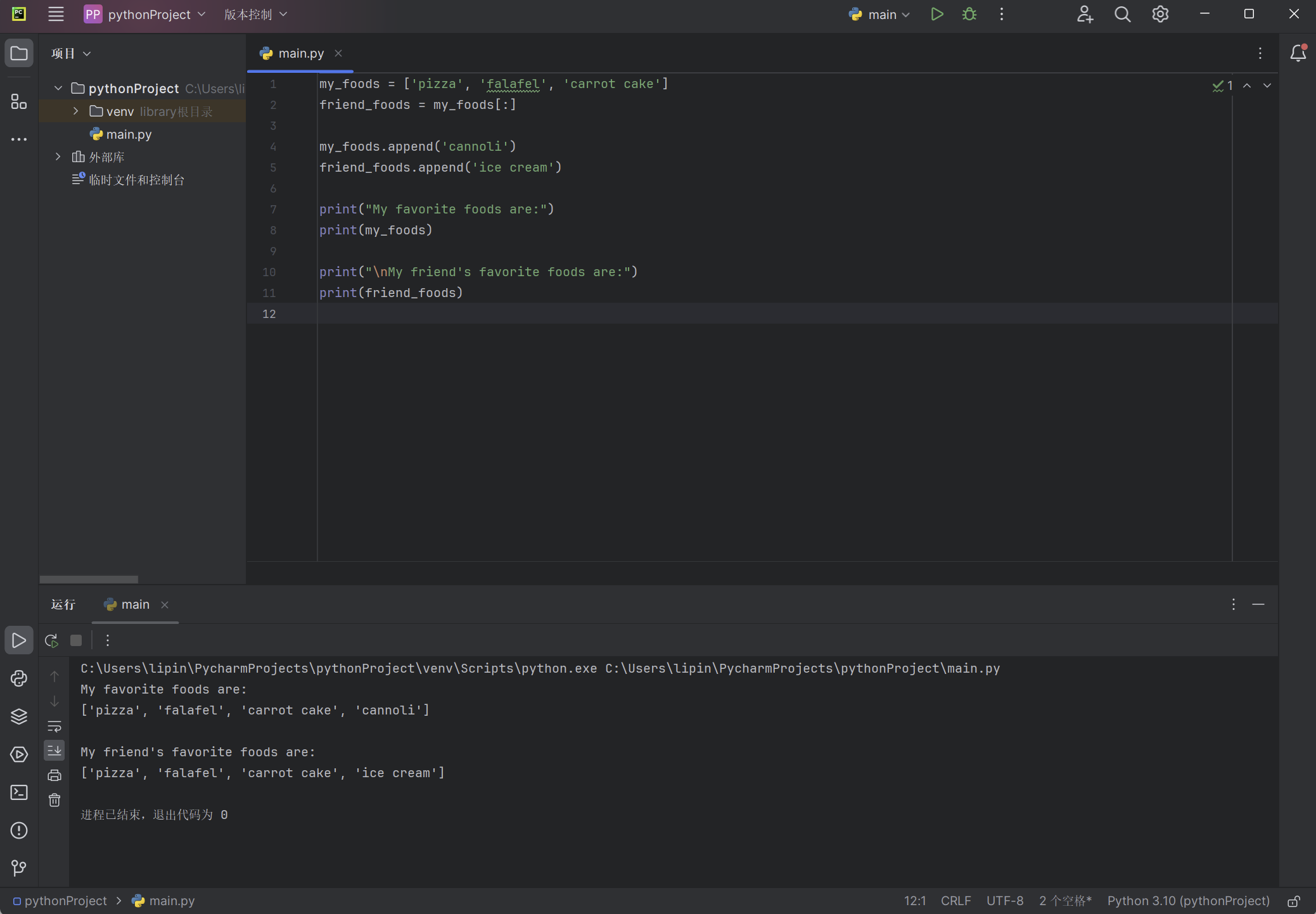
my_foods = ['pizza', 'falafel', 'carrot cake']
friend_foods = my_foods[:]
my_foods.append('cannoli')
friend_foods.append('ice cream')
print("My favorite foods are:")
print(my_foods)
print("\nMy friend's favorite foods are:")
print(friend_foods)
与前一个示例一样,我们首先将my_foods 的元素复制到新列表friend_foods 中。接下来,在每个列表中都添加一种食品:在列表my_foods 中添加’cannoli’ ,而在friend_foods 中添加’ice cream’ 。最后,打印这两个列表,核实这两种食品包含在正确的列表中:
倘若我们只是简单地将my_foods 赋给friend_foods ,就不能得到两个列表。例如,下例演示了在不使用切片的情况下复制列表的情况:
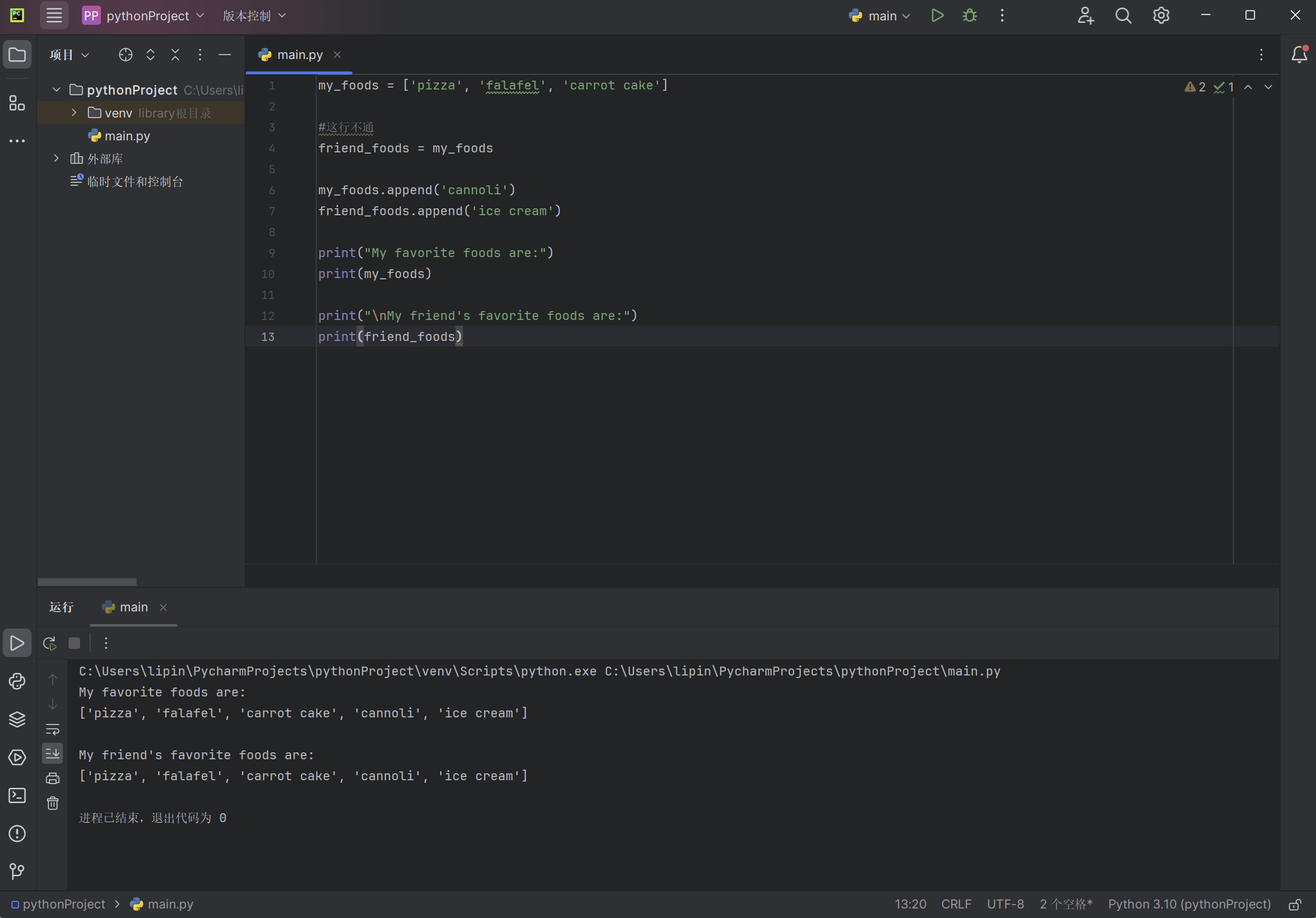
my_foods = ['pizza', 'falafel', 'carrot cake']
#这行不通
friend_foods = my_foods
my_foods.append('cannoli')
friend_foods.append('ice cream')
print("My favorite foods are:")
print(my_foods)
print("\nMy friend's favorite foods are:")
print(friend_foods)
这里将my_foods 赋给friend_foods ,而不是将my_foods 的副本存储到friend_foods 。这种语法实际上是让Python将新变量friend_foods 关联到包含在my_foods 中的列表,因此这两个变量都指向同一个列表。鉴于此,当我们将’cannoli’ 添加到my_foods 中时,它也将出现在friend_foods 中;同样,虽然’ice cream’ 好像只被加入到了friend_foods 中,但它也将出现在这两个列表中。
输出表明,两个列表是相同的,这并非我们想要的结果:
列表解析式
Python 的强大特性之一是其对 list 的解析,它提供一种紧凑的方法,可以通过对 list 中的每个元素应用一个函数,从而将一个 list 映射为另一个 list。
列表解析 将for 循环和创建新元素的代码合并成一行,并自动附加新元素。面向初学者的书籍并非都会介绍列表解析,这里之所以介绍列表解析,是因为等你开始阅读他人编写的代码时,很可能会遇到它们。
下面的示例使用列表解析创建你在前面看到的平方数列表:
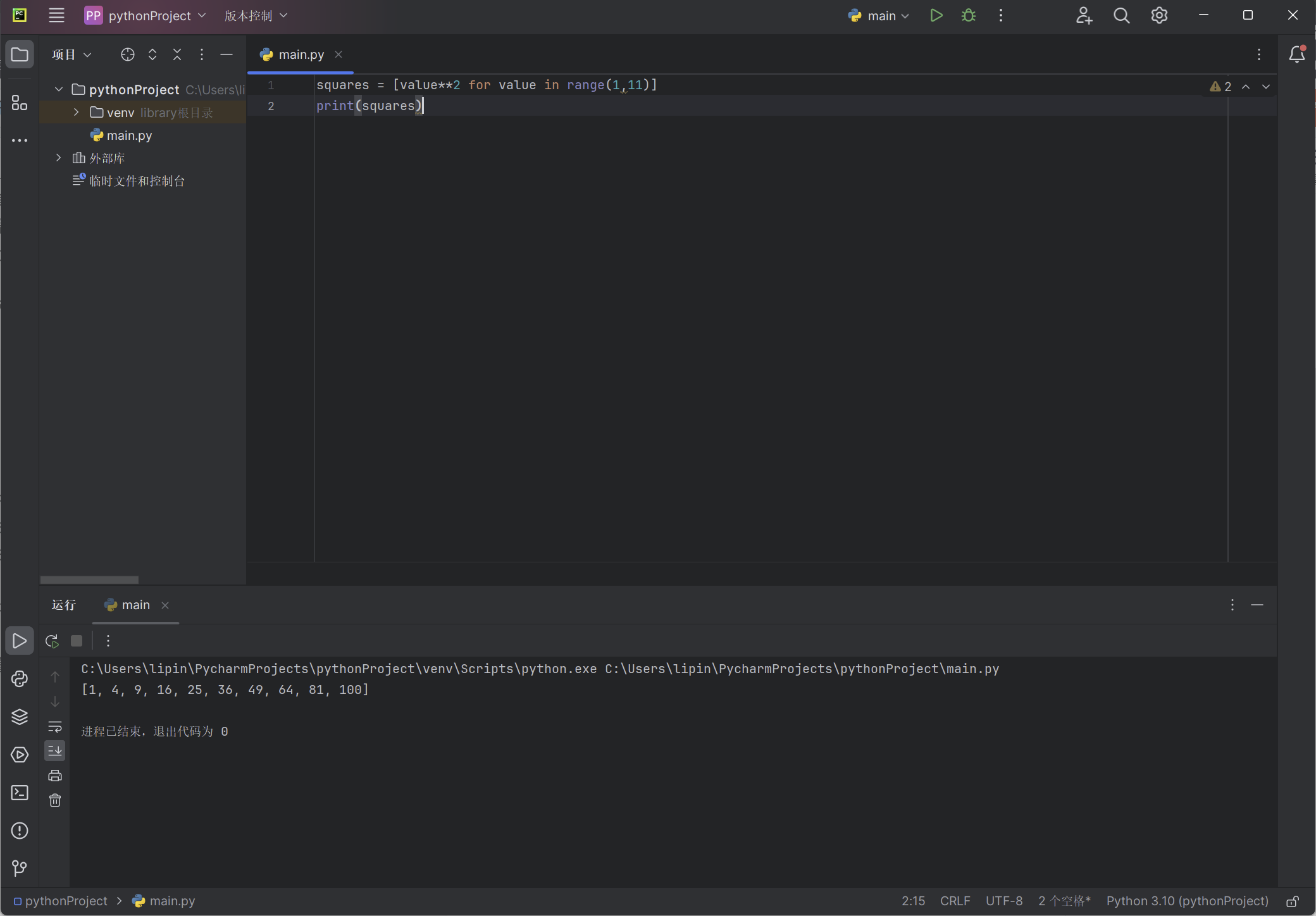
squares = [value**2 for value in range(1,11)]
print(squares)
要使用这种语法,首先指定一个描述性的列表名,如squares ;然后,指定一个左方括号,并定义一个表达式,用于生成你要存储到列表中的值。在这个示例中,表达式为value2 ,它计算平方值。接下来,编写一个for 循环,用于给表达式提供值,再加上右方括号。在这个示例中,for 循环为for value in range(1,11) ,它将值1~10提供给表达式value2 。请注意,这里的for 语句末尾没有冒号。
结果与你在前面看到的平方数列表相同:
元组拆包
元组的拆包就是将元组内部的每个元素按照位置,对应的赋值给不同变量。
可以用于:变量赋值,变量值交换,函数参数赋值,获取元组中特定位置的元素值,等。此外,Python函数return多个对象,默认就是以tuple形式返回。
我们对以下的元组进行拆包:
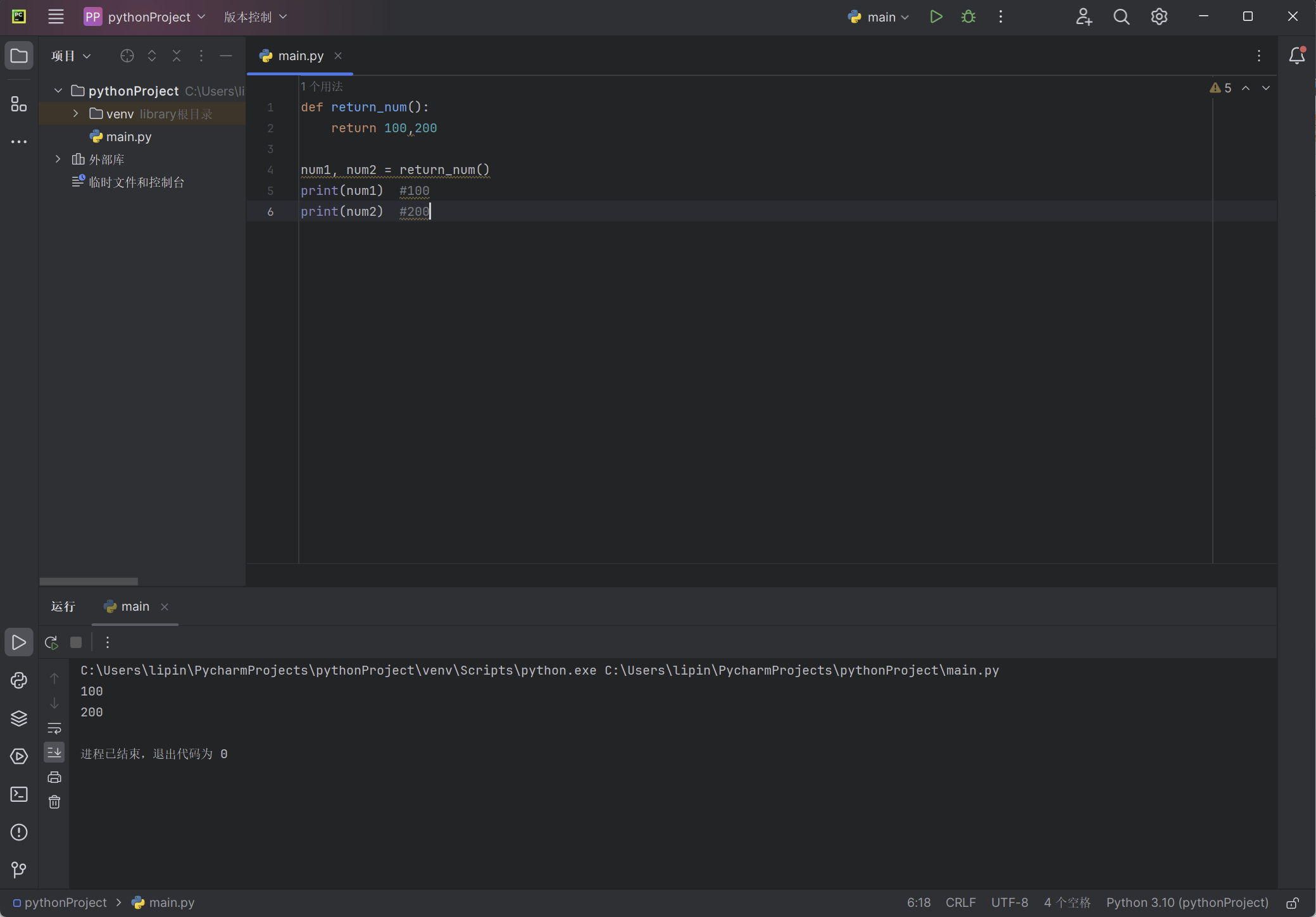
def return_num():
return 100, 200
num1, num2 = return_num()
print(num1) # 100
print(num2) # 200
以上代码的输出:
代码实列二:
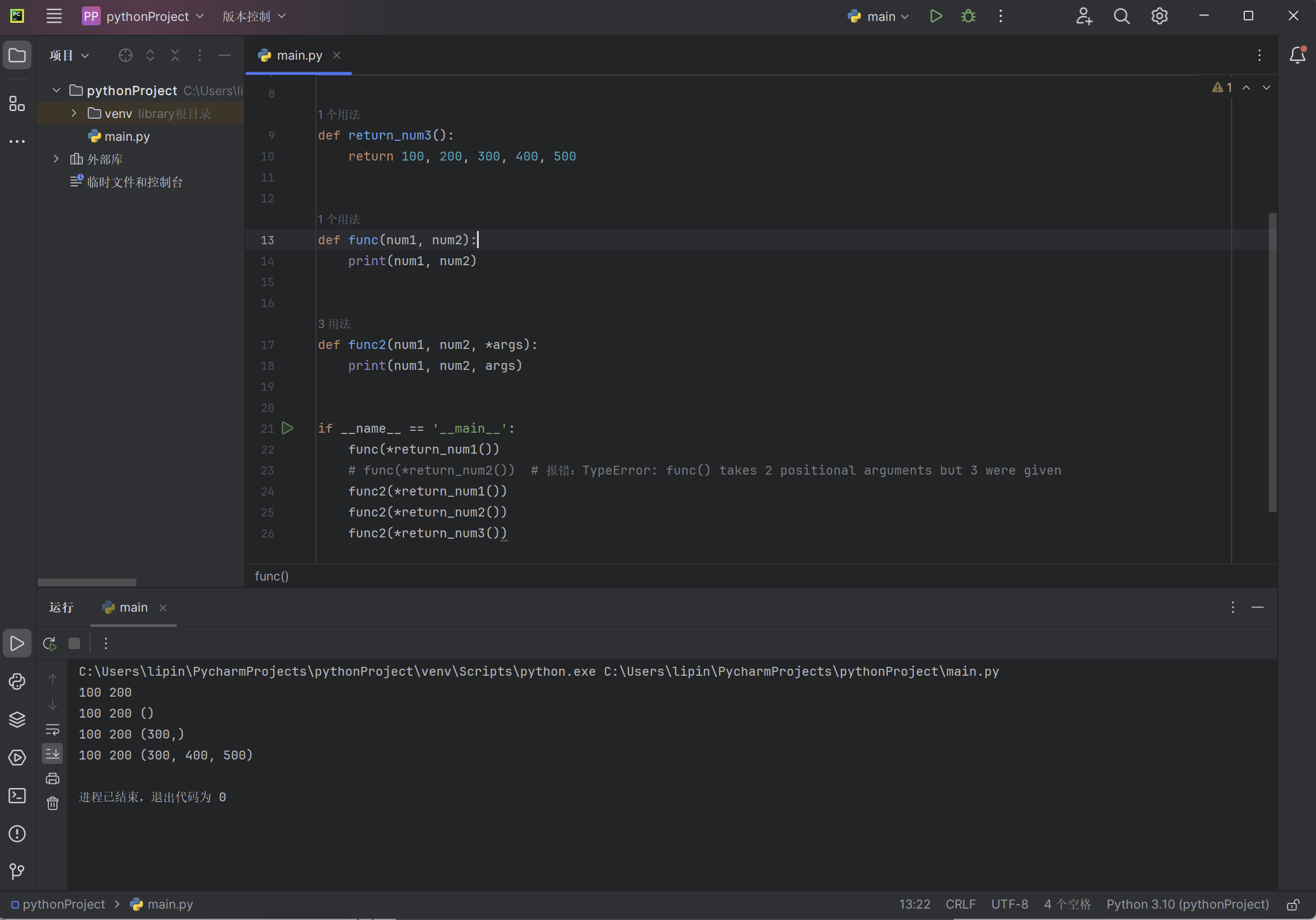
def return_num1():
return 100, 200
def return_num2():
return 100, 200, 300
def return_num3():
return 100, 200, 300, 400, 500
def func(num1, num2):
print(num1, num2)
def func2(num1, num2, *args):
print(num1, num2, args)
if __name__ == '__main__':
func(*return_num1())
# func(*return_num2()) # 报错:TypeError: func() takes 2 positional arguments but 3 were given
func2(*return_num1())
func2(*return_num2())
func2(*return_num3())
以上代码的输出:
字典拆包
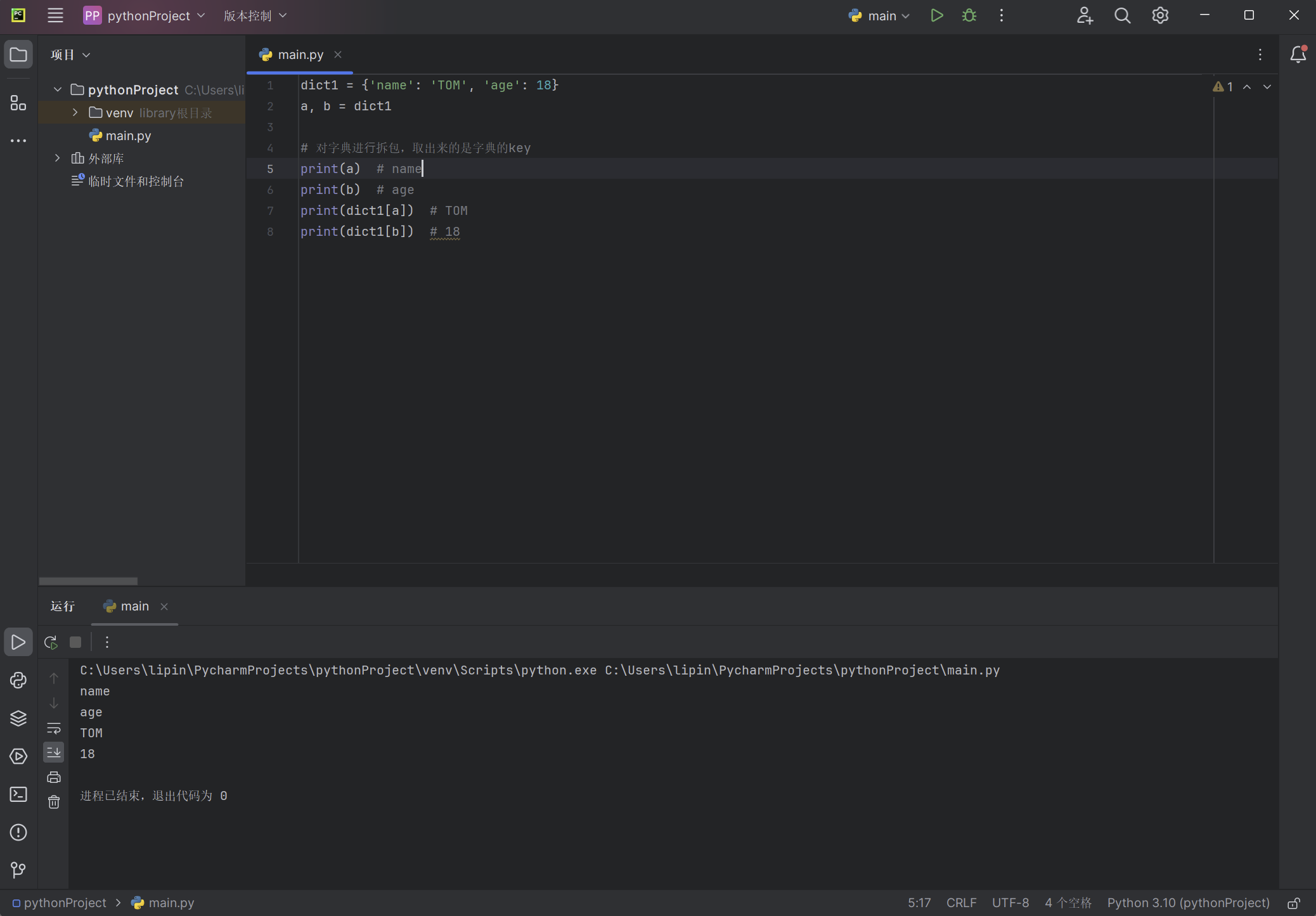
dict1 = {'name': 'TOM', 'age': 18}
a, b = dict1
# 对字典进⾏拆包,取出来的是字典的key
print(a) # name
print(b) # age
print(dict1[a]) # TOM
print(dict1[b]) # 18
以上代码的输出:
示例代码二:
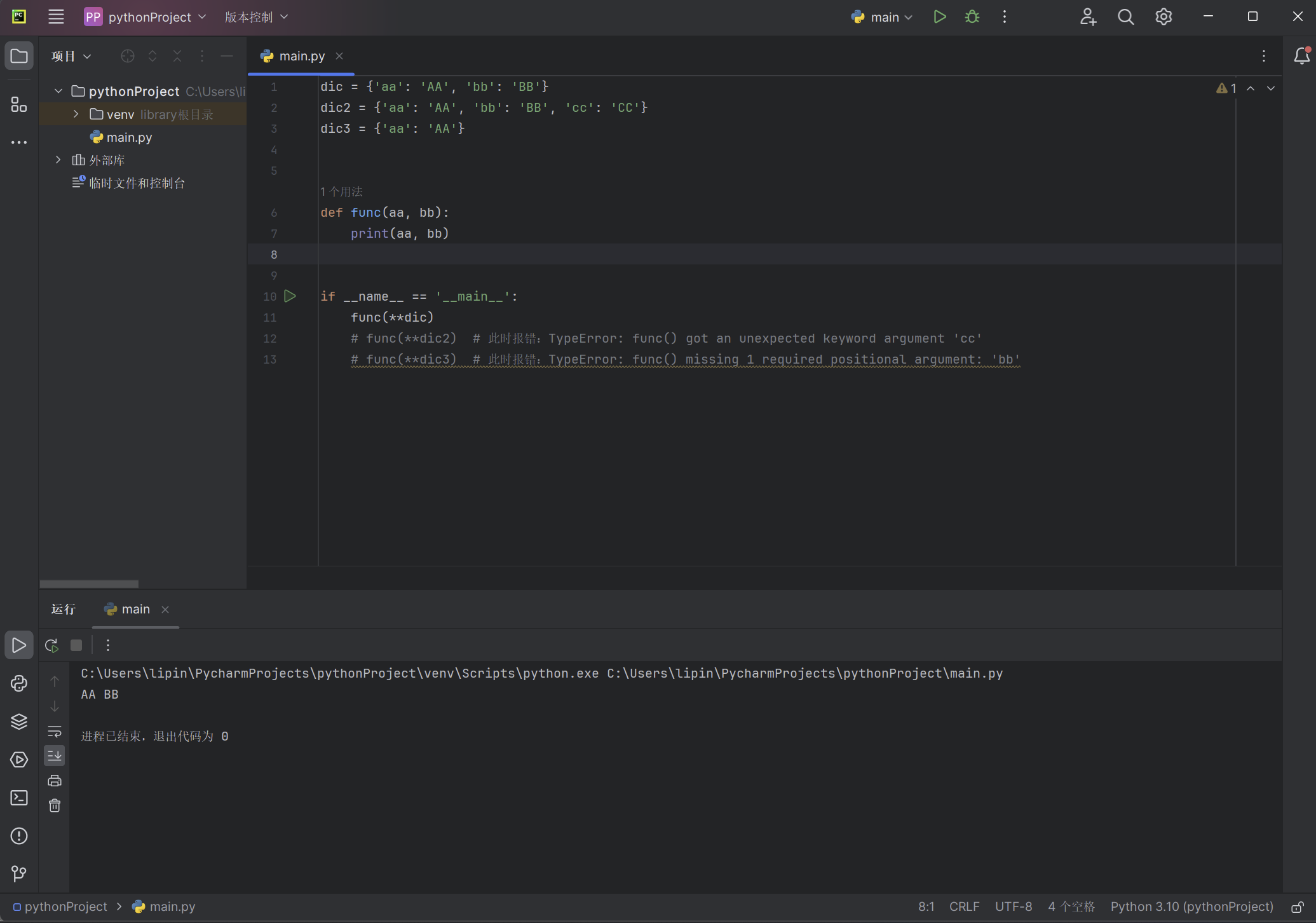
dic = {'aa': 'AA', 'bb': 'BB'}
dic2 = {'aa': 'AA', 'bb': 'BB', 'cc': 'CC'}
dic3 = {'aa': 'AA'}
def func(aa, bb):
print(aa, bb)
if __name__ == '__main__':
func(**dic)
# func(**dic2) # 此时报错:TypeError: func() got an unexpected keyword argument 'cc'
# func(**dic3) # 此时报错:TypeError: func() missing 1 required positional argument: 'bb'
以上代码的输出:
示例代码三:
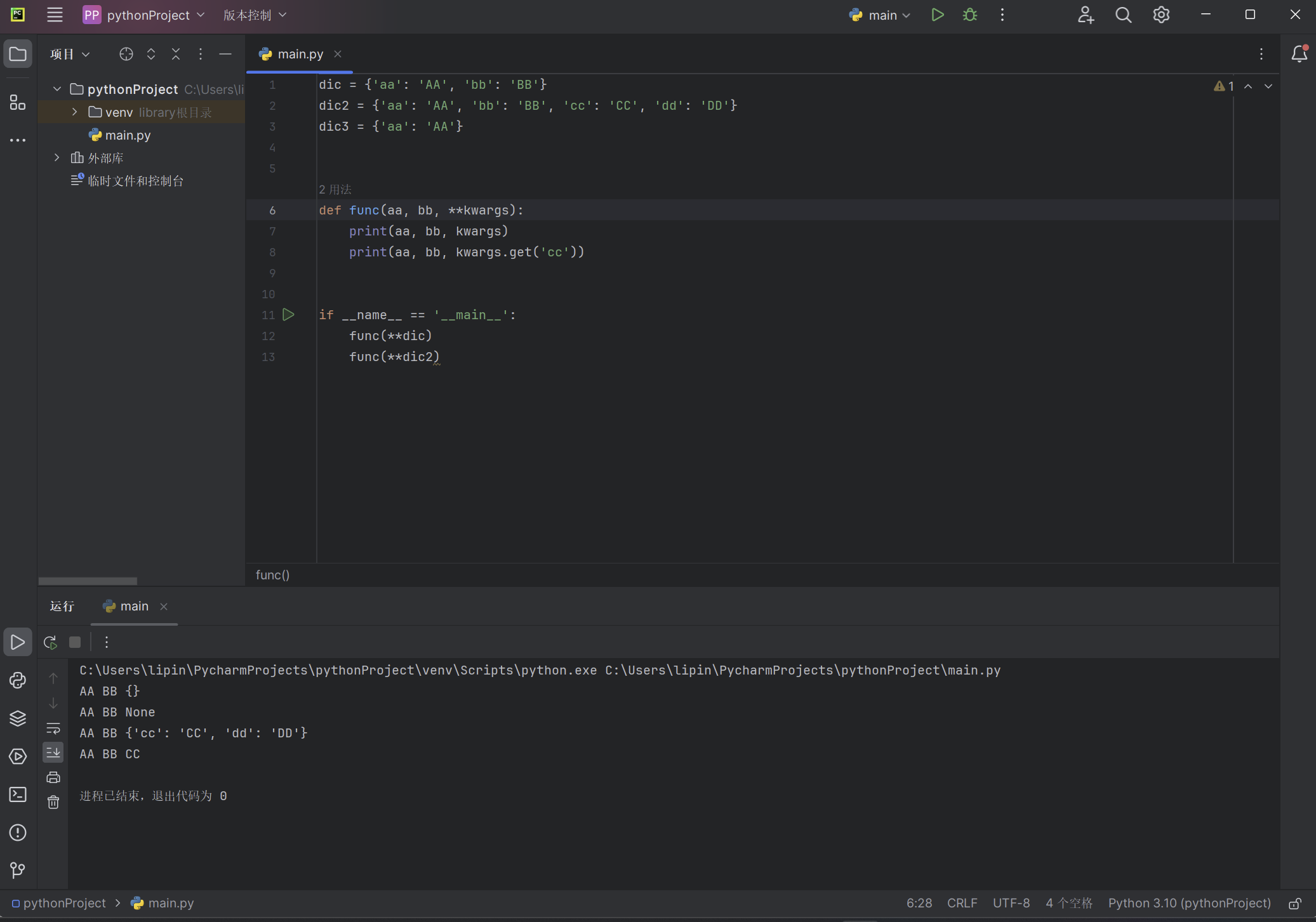
dic = {'aa': 'AA', 'bb': 'BB'}
dic2 = {'aa': 'AA', 'bb': 'BB', 'cc': 'CC', 'dd': 'DD'}
dic3 = {'aa': 'AA'}
def func(aa, bb, **kwargs):
print(aa, bb, kwargs)
print(aa, bb, kwargs.get('cc'))
if __name__ == '__main__':
func(**dic)
func(**dic2)
#func(**dic3) #报错func() missing 1 required positional argument: 'bb'
以上代码的输出: