文章以 敏感数据安全性存储 为背景,讲述 ShardingSphere 完成数据加密上线,以及后续的业务系统加密改造的过程。
以下如无特殊说明,ShardingSphere-JDBC Starter 版本为 4.1.1。
业务背景
事情的起因是集团对于敏感数据安全的重视,需要数据库中存在的 敏感数据进行加密改造,最终效果要达到 数据库中不存在敏感明文数据。
不同公司业务差异性,敏感数据的定义不尽相同。不过,基础字段的加密规则大致是相通的。
- 强制加密:手机号、证件号、邮箱、密码、人脸识别、指纹等。
- 建议加密:用户姓名、住址、坐标、银行卡等。
技术方案选型
如果要让各业务方快速推进数据加密,需要保证效率、通用以及不出错的前提下完成。
进行技术选型阶段时,面临一个问题:选择自己造轮子还是使用比较成熟的开源组件。
1. ShardingSphere
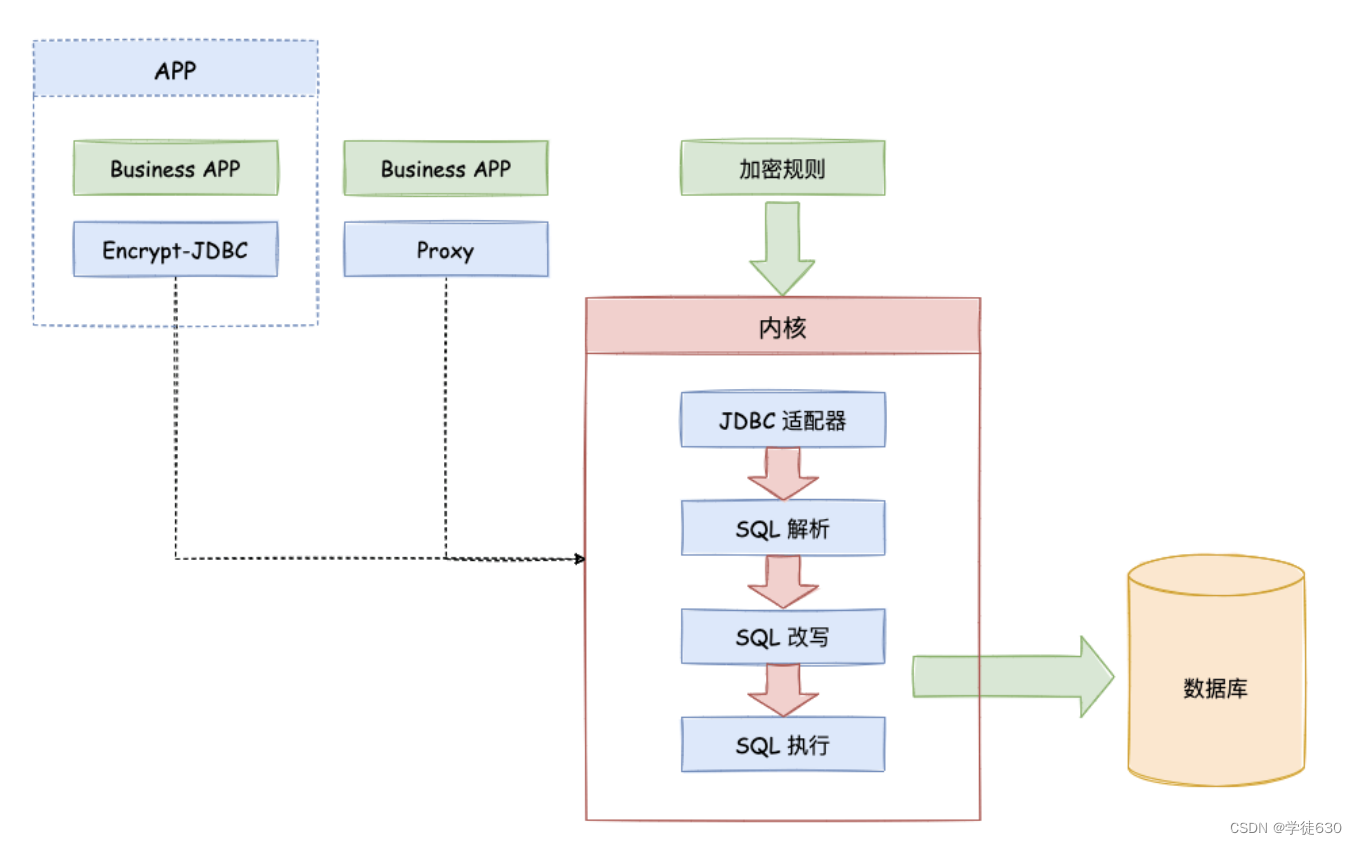
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。
其中的 JDBC 组件支持数据分片、分布式事务、读写分离、数据加密等,可以通过配置指定需要使用的功能。
1.1加密原理
ShardingSphere 通过重写 JDBC 组件对用户输入的 SQL 进行解析,并根据提供的加密规则对 SQL 进行重写,将原文数据(可选)及密文数据存储到数据库表。
在用户查询数据时,根据自定义配置选择按照明文数据查询或者密文数据查询,但是最终都会将原始数据返回给用户。
在此查询过程中,框架屏蔽了数据的加密处理,使用户无感 SQL 解析、数据加密、数据解密等处理过程。
1.2 加密规则
ShardingSphere 对于数据加密的配置分为四部分,数据源配置,加密算法配置,加密表配置以及查询属性配置,其详情如下图所示:
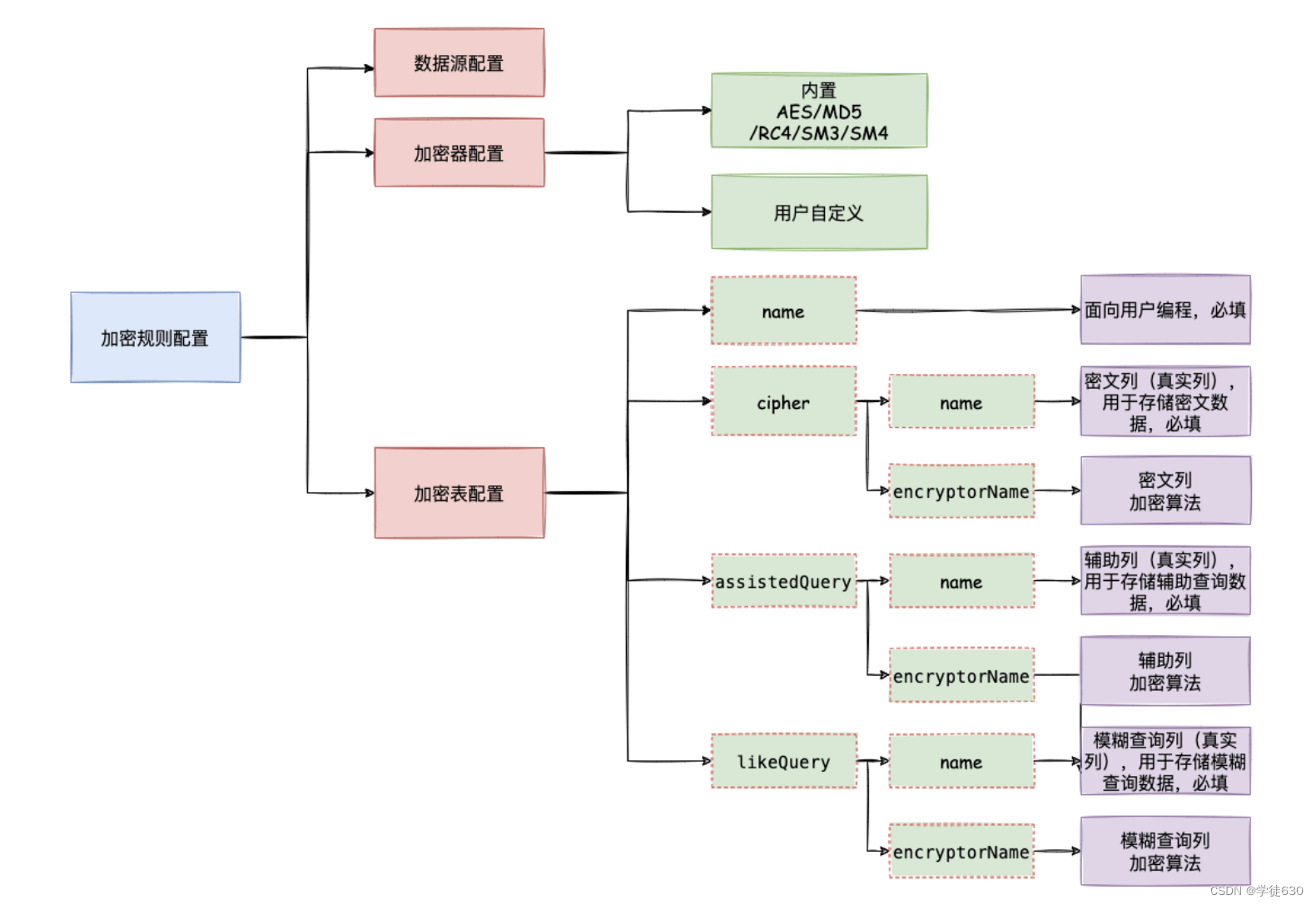
数据源配置:
没有使用加密前,项目中数据源比如说 druid 或者 hikari,是直接通过 Spring 加载到 IOC 容器中;使用了数据加密之后,会由 ShardingSphere 将配置的数据源包装一层再交给 Spring 管理。
加密器配置:
指的是 需要加密的字段通过什么加密方式进行加密。ShardingSphere 中内置了 AES 和 MD5 两种加密算法,另外也可以通过提供的 SPI 机制加载自定义加密器。
脱敏表配置:
脱敏表配置实现了用户无感知加密功能,重点包含三个属性,plainColumn(明文列)、cipherColumn(密文列)、logicColumn(逻辑列)。
- plainColumn:比如说有一张用户表,里面有个存储原始密码列 pwd_plain。
- cipherColumn:用户表里新增原始数据加密后密文列 pwd_cipher。
- logicColumn:逻辑列是面向开发者在程序中编写 SQL 的列,和明文以及密文列保持一种映射关系,可以屏蔽底层对明文或者密文数据的加密处理。
如何理解logicColumn?
我们可以从加密模块存在的意义来理解。加密模块最终目的是希望屏蔽底层对数据的加密处理,也就是说我们不希望用户知道数据是如何被加解密的、如何将密文数据存储到 cipherColumn,将辅助查询数据存储到 assistedQueryColumn。 换句话说,我们不希望用户知道 cipherColumn 和 assistedQueryColumn 的存在和使用。 所以,我们需要给用户提供一个概念意义上的列,这个列可以脱离底层数据库的真实列,它可以是数据库表里的一个真实列,也可以不是,从而使得用户可以随意改变底层数据库的 cipherColumn 和 assistedQueryColumn 的列名。 只要用户的 SQL 面向这个逻辑列进行编写,并在加密规则里给出 logicColumn、cipherColumn、assistedQueryColumn 之间正确的映射关系即可。
为什么要这么做呢?答案在文章后面,即为了让已上线的业务能无缝、透明、安全地进行数据加密迁移。
查询属性配置:
数据库中同时存储了明文列以及密文列时,该属性决定了是查询明文列的数据直接返回,还是查询密文列再通过 ShardingSphere 解密后返回。
1.3 举例说明
(1)新上线业务
举例说明,假如数据库里有一张表叫做 t_user,这张表里实际有两个字段 pwd_cipher,用于存放密文数据、pwd_assisted_query,用于存放辅助查询数据,同时定义 logicColumn 为 pwd。 那么,用户在编写 SQL 时应该面向 logicColumn 进行编写,即 INSERT INTO t_user SET pwd = '123'。 Apache ShardingSphere 接收到该 SQL,通过用户提供的加密配置,发现 pwd 是 logicColumn,于是便对逻辑列及其对应的明文数据进行加密处理。 Apache ShardingSphere 将面向用户的逻辑列与面向底层数据库的密文列进行了列名以及数据的加密映射转换。 如下图所示:

即依据用户提供的加密规则,将用户 SQL 与底层数据表结构割裂开来,使得用户的 SQL 编写不再依赖于真实的数据库表结构。 而用户与底层数据库之间的衔接、映射、转换交由 Apache ShardingSphere 进行处理。
下方图片展示了使用加密模块进行增删改查时,其中的处理流程和转换逻辑,如下图所示。

总结起来,ShardingSphere 相当于一个转换层,对用户的 SQL 进行解析,遇到需要加密的字段,根据加密规则进行重写 SQL,最终提交重写后的 SQL 到数据库执行。
(2)历史业务改造
- 业务场景分析
由于业务已经在线上运行,数据库里必然存有明文历史数据。现在的问题是如何让历史数据得以加密清洗、如何让增量数据得以加密处理、如何让业务在新旧两套数据系统之间进行无缝、透明化迁移。
- 解决方案说明
在提供解决方案之前,我们先来头脑风暴一下。首先,既然是旧业务需要进行加密改造,那一定存储了非常重要且敏感的信息。这些信息含金量高且业务相对基础重要。不应该采用停止业务禁止新数据写入,再找个加密算法把历史数据全部加密清洗,再把之前重构的代码部署上线,使其能把存量和增量数据进行在线加密解密。
那么另一种相对安全的做法是:重新搭建一套和生产环境一模一样的预发环境,然后通过相关迁移洗数工具把生产环境的存量原文数据加密后存储到预发环境,而新增数据则通过例如 MySQL 主从复制及业务方自行开发的工具加密后存储到预发环境的数据库里,再把重构后可以进行加解密的代码部署到预发环境。这样生产环境是一套以明文为核心的查询修改的环境;预发环境是一套以密文为核心加解密查询修改的环境。在对比一段时间无误后,可以夜间操作将生产流量切到预发环境中。此方案相对安全可靠,只是时间、人力、资金、成本较高,主要包括:预发环境搭建、生产代码整改、相关辅助工具开发等。
业务开发人员最希望的做法是:减少资金费用的承担、最好不要修改业务代码、能够安全平滑迁移系统。于是,ShardingSphere 的加密功能模块便应运而生,可分为三步进行:
1. 系统迁移前 假设系统需要对 t_user 的 pwd 字段进行加密处理,业务方使用 ShardingSphere 来代替标准化的 JDBC 接口,此举基本不需要额外改造(ShardingSphere 还提供了 Spring Boot Starter、Spring 命名空间、YAML 等接入方式,满足不同业务方需求)。另外,提供一套如下所示的加密配置规则。
-!ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_user:
columns:
pwd:
plainColumn: pwd
cipherColumn: pwd_cipher
encryptorName: aes_encryptor
assistedQueryColumn: pwd_assisted_query
assistedQueryEncryptorName: pwd_assisted_query_cipher
queryWithCipherColumn: false依据上述加密规则可知,首先需要在数据库表 t_user 里新增一个字段叫做 pwd_cipher,即 cipherColumn,用于存放密文数据,同时我们把 plainColumn 设置为 pwd,用于存放明文数据,而把 logicColumn 也设置为 pwd。 由于之前的代码 SQL 就是使用 pwd 进行编写,即面向逻辑列进行 SQL 编写,所以业务代码无需改动。通过 ShardingSphere,针对新增的数据,会把明文写到 pwd 列,并同时把明文进行加密存储到 pwd_cipher 列。 此时,由于 queryWithCipherColumn 设置为 false,对业务应用来说,依旧使用 pwd 这一明文列进行查询存储,却在底层数据库表 pwd_cipher 上额外存储了新增数据的密文数据,其处理流程如下图所示。
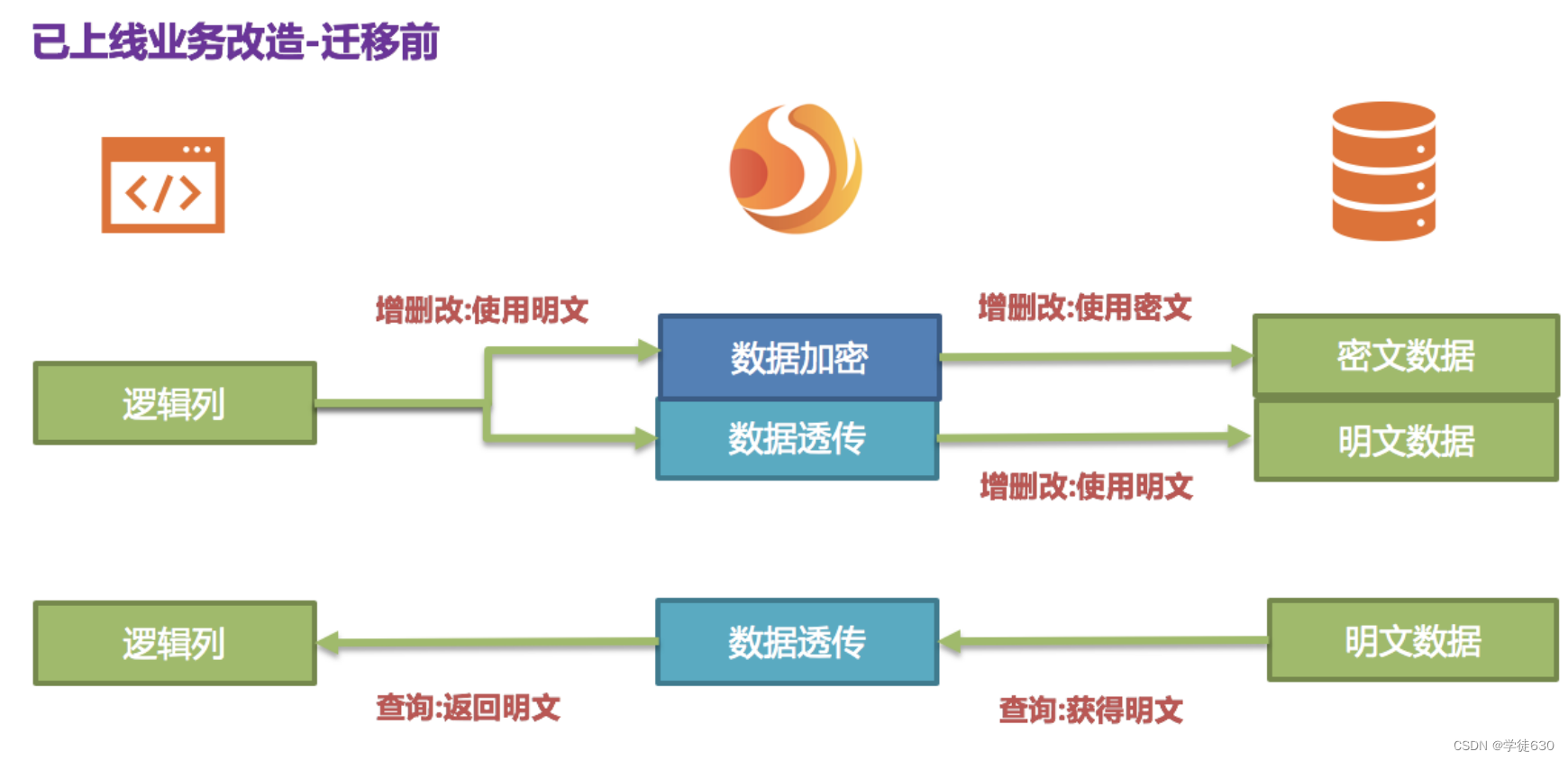
新增数据在插入时,就通过 ShardingSphere 加密为密文数据,并被存储到了 cipherColumn。而现在就需要处理历史明文存量数据。由于 ShardingSphere 目前并未提供相关迁移洗数工具,此时需要业务方自行将 pwd 中的明文数据进行加密处理存储到 pwd_cipher。
2. 系统迁移中 新增的数据已被 ShardingSphere 将密文存储到密文列,明文存储到明文列;历史数据被业务方自行加密清洗后,将密文也存储到密文列。也就是说现在的数据库里既存放着明文也存放着密文,只是由于配置项中的 queryWithCipherColumn = false,所以密文一直没有被使用过。 现在我们为了让系统能切到密文数据进行查询,需要将加密配置中的 queryWithCipherColumn 设置为 true。 在重启系统后,系统业务一切正常,但是 ShardingSphere 已经开始从数据库里取出密文列的数据,解密后返回给用户; 而对于用户的增删改需求,则依旧会把原文数据存储到明文列,加密后密文数据存储到密文列。
虽然现在业务系统通过将密文列的数据取出,解密后返回,但是,在存储的时候仍旧会存一份原文数据到明文列,这是为什么呢?答案是:为了能够进行系统回滚。因为只要密文和明文永远同时存在,我们就可以通过开关项配置自由将业务查询切换到 cipherColumn 或 plainColumn。也就是说,如果将系统切到密文列进行查询时,发现系统报错,需要回滚,那么只需将 queryWithCipherColumn = false,ShardingSphere 将会还原,即又重新开始使用 plainColumn 进行查询。处理流程如下图所示:
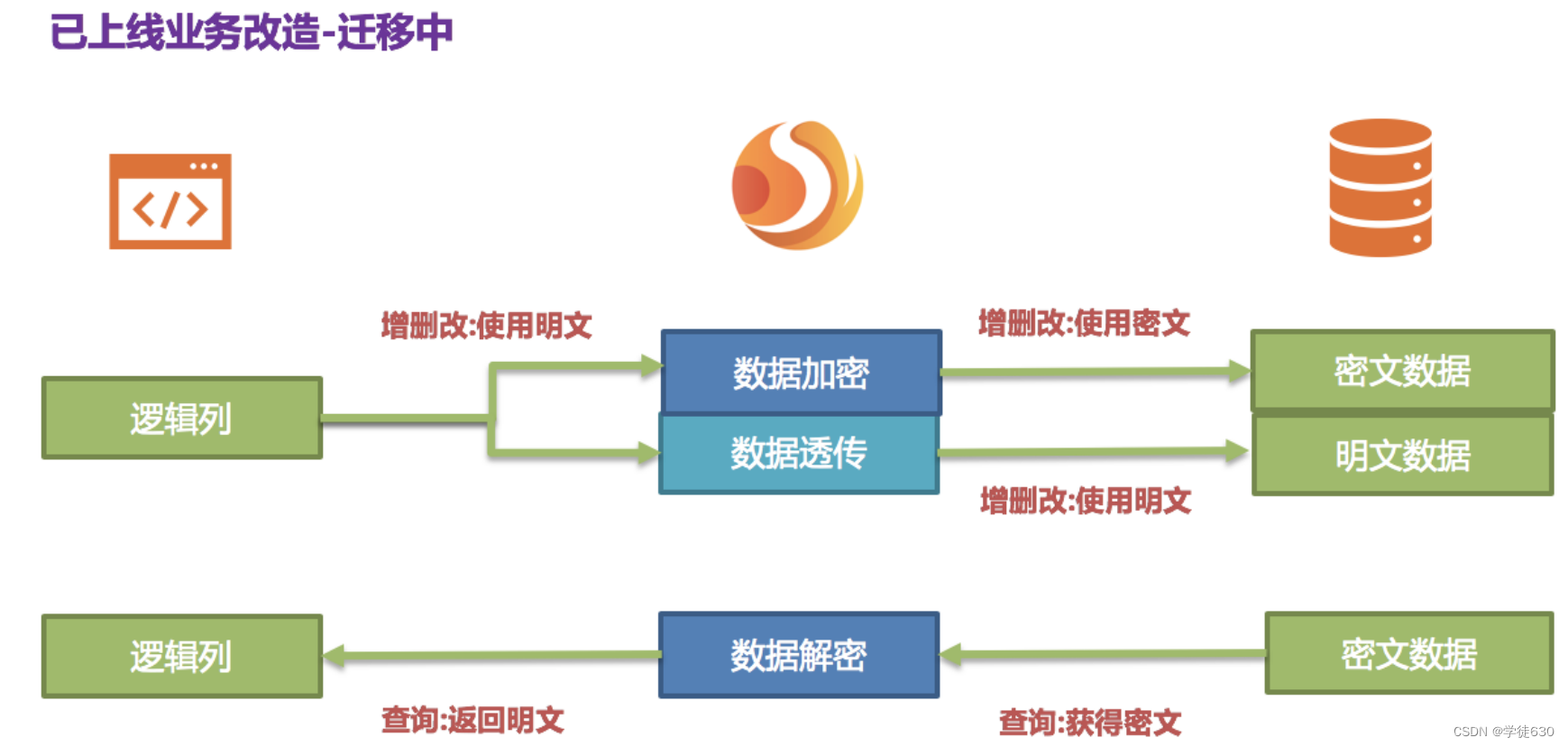
3. 系统迁移后 由于安全审计部门要求,业务系统一般不可能让数据库的明文列和密文列永久同步保留,我们需要在系统稳定后将明文列数据删除。即我们需要在系统迁移后将 plainColumn,即 pwd 进行删除。那问题来了,现在业务代码都是面向 pwd 进行编写 SQL 的,把底层数据表中的存放明文的 pwd 删除了, 换用 pwd_cipher 进行解密得到原文数据,那岂不是意味着业务方需要整改所有 SQL,从而不使用即将要被删除的 pwd 列?还记得 ShardingSphere 的核心意义所在吗?即依据用户提供的加密规则,将用户 SQL 与底层数据库表结构割裂开来,使得用户的 SQL 编写不再依赖于真实的数据库表结构。用户与底层数据库之间的衔接、映射、转换交由 ShardingSphere 进行处理。
因为有 logicColumn 存在,用户的编写 SQL 都面向这个虚拟列,ShardingSphere 就可以把这个逻辑列和底层数据表中的密文列进行映射转换。于是迁移后的加密配置即为:
-!ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_user:
columns:
pwd: # pwd 与 pwd_cipher 的转换映射
cipherColumn: pwd_cipher
encryptorName: aes_encryptor
assistedQueryColumn: pwd_assisted_query
assistedQueryEncryptorName: pwd_assisted_query_cipher
queryWithCipherColumn: true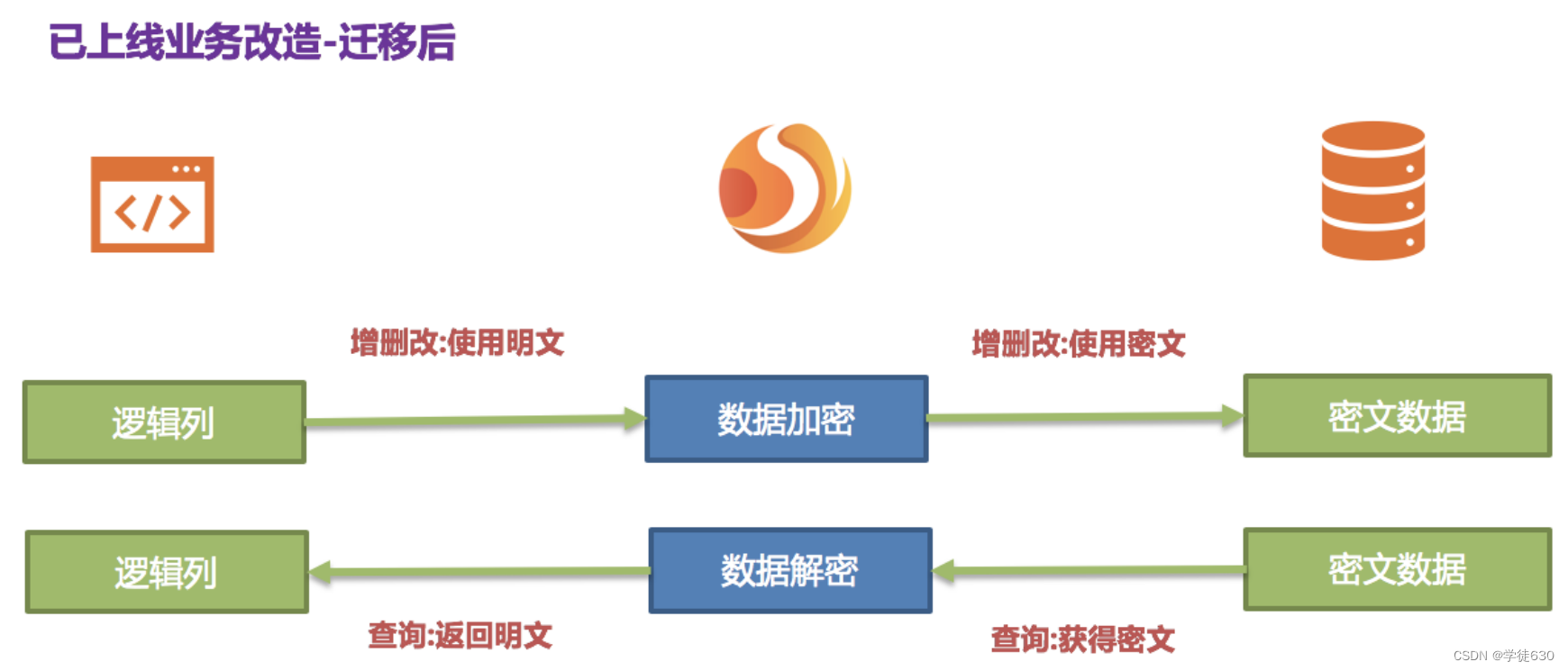
4. 系统迁移完成
安全审计部门再要求,业务系统需要定期或某些紧急安全事件触发修改密钥,我们需要再次进行迁移洗数,即使用旧密钥解密后再使用新密钥加密。既要又要还要的问题来了,明文列数据已删除,数据库表中数据量千万级,迁移洗数需要一定时间,迁移洗数过程中密文列在变化,系统还需正确提供服务。怎么办?答案是:辅助查询列。因为辅助查询列一般使用不可逆的 MD5 和 SM3 等算法,基于辅助列进行查询,即使在迁移洗数过程中,系统也是可以提供正确服务。
至此,已在线业务加密整改解决方案全部叙述完毕。ShardingSphere 提供了 Java、YAML、Spring Boot Starter、Spring 命名空间多种方式供用户选择接入,力求满足业务不同的接入需求。
2. 自定义开发
如果选择自己造轮子,实现逻辑与 ShardingSphere 的流程基本一致,解析用户的行为并进行修改,实现方式并不固定。
优点:
- 代码实现起来较为简洁,减少了开源组件的大量依赖。
- 不存在 SQL 兼容问题,仅是修改 SQL 中需要加解密的字段,不涉及 SQL 解析器的开发。
- 性能良好,相对于开源组件的大量封装以及 SQL 解析,拦截器只有加密算法的必要开销。
缺点:
- 对业务侵入性高,在加密功能上线切换阶段,需要频繁修改 SQL 语句(取决实现方式)。
- 从开始进行数据加密,最终数据库全部加密,需要一个 很长的开发和测试周期。
- 如果业务有耦合关联,数据库加密可能会出现:上线一起上,有问题一起回滚的情况。
技术水准和开发时间满足的情况下,也有不少公司选择了自己开发数据加密组件。
考虑到业务侵入、耦合和开发周期这几点因素,决定放弃自己造轮子,选择使用 ShardingSphere 作为数据加密安全框架。
使用限制
- 需自行处理数据库中原始的存量数据;
- 模糊查询支持 %、_,暂不支持 escape;
- 加密字段无法支持查询不区分大小写功能;
- 加密字段无法支持比较操作,如:大于、小于、ORDER BY、BETWEEN 等;
- 加密字段无法支持计算操作,如:AVG、SUM 以及计算表达式;
- 当投影子查询中包含加密字段时,必须使用别名。
- 不支持子查询中包含加密字段,并且外层投影使用星号的 SQL。
- 加密规则中配置的加密列、辅助查询列、LIKE 查询列等需要和数据库中的列保持大小写一致。
问题解决方案
推行业务方数据加密时,发现了一些不太友好的兼容问题,在这里分享下解决方案。
1. SQL 解析器预热
项目启动后,使用 ShardingSphere 加密数据源执行 SQL,发现前两条执行的时间差异比较大。
通过源码得知,第一次解析 SQL 时会使用工厂类创建单例对象,第二次解析时不用创建新对象。
所以可以在项目初始化时实例化相关对象,减少第一次预热时间,节省大概 500 ms 时间。

2. 关键字不识别
ShardingSphere 对于某些关键字不会识别,而且不兼容的关键字并非单个数据库的。如果执行 SQL 包含的话,会抛出错误。
mismatched input 'xxx' expecting {'!', '~', '+', '-', '.', '(', '{', '?', '@', TRUNCATE, POSITION...
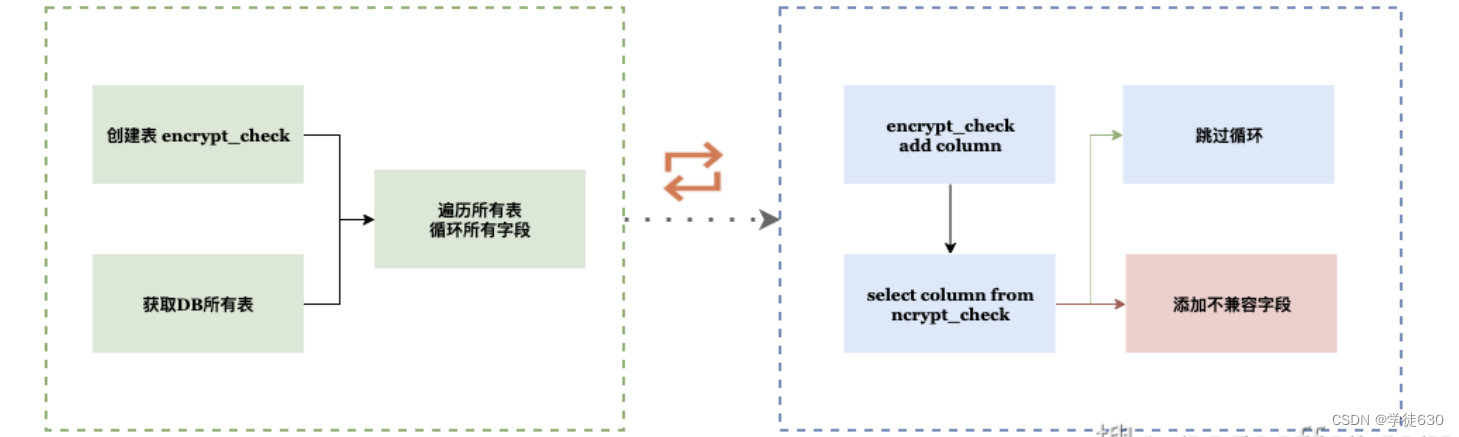
因为不明确不支持的字段属于哪个数据库,不能按照单个数据库的关键字扫描。所以在开发的时候用了一种笨方法,解决方案如下:
- DB 中创建 encrypt_check 临时表,字段仅一个主键即可;
- 查询 DB 下所有表,循环遍历表的所有字段,执行 3、4、5 流程;
- 将字段插入 encrypt_check 临时表,执行 select 字段 from encrypt_check;
- 不报错证明兼容,删除 check 表该字段继续循环;
- 报错的话添加到不兼容集合,并删除 check 表该字段继续循环;
- 所有表字段循环完成后,返回不兼容集合 Map<表名, List<字段>>。
如果扫描 DB 发现有关键字,SQL 语句中使用 `` 修饰,Mybatis-Plus 应用可以在实体对象上添加 @TableField 注解解决。扫描程序流程图如下所示:
3. 不兼容项
ShardingSphere 的 SQL 解析内核并不是针对包含加密字段的 SQL,作用域是整个项目。
所以项目中如果出现下述的 SQL,需要进行改写。官网上明确说明的比较和计算类操作不再重复举例。
示例一
问题描述:不支持查询列中包含子查询,子查询无法查询到值。
解决方案:将子查询在 SQL 中优化或者代码中查询并替换值。
select t.id, (select ue.email from user_email ue where ue.id = t.id) as email from t_user t示例二
问题描述:不支持返回列中使用 * 号搭配子查询,查询有记录返回,但是记录无法进行映射,返回到应用里记录全部为 null。
解决方案:* 号替换为具体字段。
select t.* from (select id, pwd from t_user) t示例三
问题描述:DISTINCT 无法搭配 FROM 子查询,报错:Can not find owner from table。
解决方案:FROM 后子查询替换或者将 DISTINCT 替换为 GROUP BY。
select distinct t.id
from
(select id from t_user where del_flag = 0) t
inner join user_enail ue
on ue.id = t.id示例四
问题描述:UNION 或 UNION ALL 上下 SQL 结果集不能包含括号。
解决方案:删除 SQL 结果集的括号。
( select * from t_user )
union
( select * from t_user )示例五
问题描述:Mybatis <forech> 形式拼接字符串批量提交或修改操作,ShardingSphere 无法为密文列赋值。
解决方案:修改为 Mybatis-Plus 批量提交的形式或者切换 Mybatis 批处理执行器。
示例六
问题描述:Mybatis-Plus( 3.4.2 版本)包含 binary 关键字执行分页 SQL 报错: java.lang.xxx cannot be cast to java.lang.xxx;
ShardingSphere 在进行 SQL 解析环节会为分页 SQL 找到 offset 和 limit,而 Mybatis-Plus 在 current 为 1 时,默认不拼接 offset,导致 ShardingSphere 解析出错。
解决方案:重写分页插件 MySqlDialect,current 为 1 也执行 offset 拼接操作。
select * from t_user where binary user_name = ? LIMIT ?不支持 SQL 总结
上面大部分问题同出一辙,ShardingSphere 不能很好兼容子查询结果集,其余 SQL 暂时没有发现问题;所以在项目引入加密时,着重注意带子查询的语句。
如果大家在使用过程中如果遇到不同的兼容性问题,欢迎补充。
加密算法解析
Apache ShardingSphere 提供了加密算法用于数据加密,即 EncryptAlgorithm。
一方面,Apache ShardingSphere 为用户提供了内置的加解密实现类,用户只需进行配置即可使用; 另一方面,为了满足用户不同场景的需求,我们还开放了相关加解密接口,用户可依据这两种类型的接口提供具体实现类。 再进行简单配置,即可让 Apache ShardingSphere 调用用户自定义的加解密方案进行数据加密。
EncryptAlgorithm
该解决方案通过提供 encrypt(),decrypt() 两种方法对需要加密的数据进行加解密。 在用户进行 INSERT,DELETE,UPDATE 时,ShardingSphere会按照用户配置,对SQL进行解析、改写、路由,并调用 encrypt() 将数据加密后存储到数据库, 而在 SELECT 时,则调用 decrypt() 方法将从数据库中取出的加密数据进行逆向解密,最终将原始数据返回给用户。
当前,Apache ShardingSphere 针对这种类型的加密解决方案提供了三种具体实现类,分别是 MD5(不可逆),AES(可逆),RC4(可逆),用户只需配置即可使用这三种内置的方案。
总结回顾
选择 ShardingSphere 作为数据加密方案后,在一定程度上提高了业务系统接入加密的效率,节省了人员投入的成本,快节奏且稳定的完成了敏感数据改造的落地。
这里总结下方案落地的心得:
- 无论上线任何中间件产品,先去网上 搜索不兼容项和缺点。如果是 GitHub 开源项目,多看看 Issue,会有很大的帮助。
- 上线前要做好 充分且全面的测试,最好能考虑到性能、JVM、兼容性等方面。
- 不同业务线项目的上线难度是不一样的,负责推广的技术需要在开发、测试阶段将可能出现的问题发现及解决。
- 要有全局意识,难点往往体现在细枝末节的地方。拿 ShardingSphere 推广业务方使用来说,负责的项目涉及到 DataX、Canal、ES 适配,考虑不到就会出现问题。
项目实战
我们以用户表举例,用户表中存在证件号、手机号、邮箱以及地址等敏感字段,需要在数据库中进行加密存储。
代码实战查看 /services/user-service。
1. 引入 ShardingSphere
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version>
</dependency>2. 新增加密配置
application.yaml 配置文件修改配置,将数据库驱动变更为 ShardingSphere Driver。
spring:
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:shardingsphere-config.yaml并配置 shardingsphere-config.yaml 相关配置。为了方便大家理解,我把分库分表的相关配置删除了,仅保留了加密相关的配置。
# 配置数据源,底层被 ShardingSphere 进行了代理
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/12306_user_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
# 数据加密存储规则
- !ENCRYPT
# 需要加密的表集合
tables:
# 用户表
t_user:
# 用户表中哪些字段需要进行加密
columns:
# 身份证字段,逻辑字段,不一定是在数据库中真实存在
id_card:
# 身份证字段存储的密文字段,这个是数据库中真实存在的字段
cipherColumn: id_card
# 身份证字段加密算法
encryptorName: common_encryptor
phone:
cipherColumn: phone
encryptorName: common_encryptor
mail:
cipherColumn: mail
encryptorName: common_encryptor
address:
cipherColumn: address
encryptorName: common_encryptor
# 是否按照密文字段查询
queryWithCipherColumn: true
# 加密算法
encryptors:
# 自定义加密算法名称
common_encryptor:
# 加密算法类型
type: AES
props:
# AES 加密密钥
aes-key-value: d6oadClrrb9A3GWo
props:
sql-show: true3. 效果展示
咱们新插入一条用户信息,在应用程序里还是明文,经过 ShardingSphere 代理后,存储数据库时,就已经是密文的了。
原始 SQL:
insert into t_user (id_card, phone, mail, address) values ('34020xx023081xx338', '1x60111xx983', 'mading@axxche.org', 'xx东城x');修改后的 SQL:
insert into t_user (id_card, phone, mail, address) values ('YUvr+8Xf17VCgGonU2WXqmKuhB5FMazUEbh3y+h0B38=', 'MZObk+5TeYPLHtP2A6+aiw==', 'vX/5iWTyfAvMJMt+ioipj9vd6cnZ4rz4qKBAXQ9C9oU=', 'vX/5iWTyfAvMJMt+ioipj9vd6cnZ4rz4qKBAXQ9C9oU=');可能有小伙伴比较疑问,存储到数据库是密文,那查询时展示不就有问题了吗?ShardingSphere 在执行查询语句时,如果涉及到相关加密表,会自动将加密数据转换为明文数据,也就是会把 YUvr+8Xf17VCgGonU2WXqmKuhB5FMazUEbh3y+h0B38= 转换为 34020xx023081xx338。
这样就能形成一个加密敏感信息落库闭环。







![[Python进阶] 消息框、弹窗:pywin32](https://img-blog.csdnimg.cn/1987913475b4427a94b4a3beb63efaa6.png)