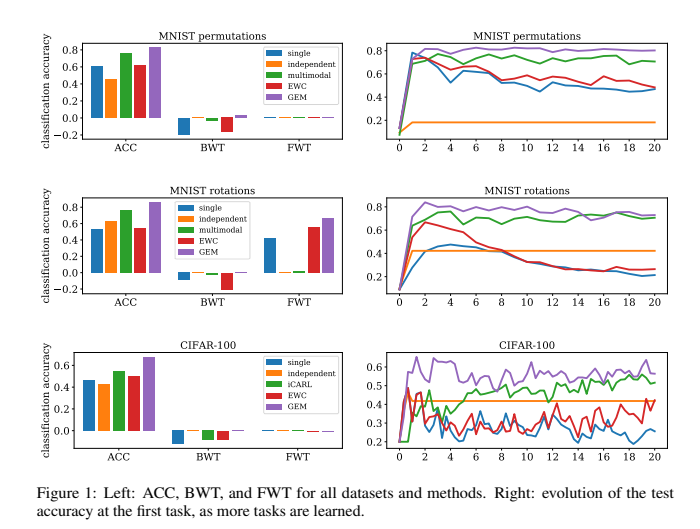
在这篇中,我们介绍了链接预测的重要任务,以及如何提取链接级特征来更好地解决这类问题。这在我们需要预测缺失的边或预测将来会出现的边的情况下很有用。我们将讨论的链路级功能包括基于距离的功能,以及本地和全局邻域重叠。
文章目录
- 1. 边层级任务
- 2. 链路预测任务两种方式
- 3. 通过邻近进行链路预测
- 4. 边层级特征
- 4.1 基于距离的特征(Distance-based feature)
- 4.2 局部邻域重叠(Local neighborhood overlap)
- 4.3 全局邻域重叠(Global neighborhood overlap)
- 5. 总结
1. 边层级任务

任务是:基于已有的图结构,预测新的边。
这意味着在测试时,我们必须计算所有尚未链接的节点对,对它们进行排序,然后,宣布我们的算法预测的最前面的k个注释对,是网络中将要发生的链接。
而现在的关键,是对每一对节点(边)设计特征。
正如上一篇中说到的节点层级的任务,是给节点设计特征,那我们能否直接拼接两个节点的特征作为这一对节点的特征呢?
答案是不能的,因为这样会丢失很多重要信息。
2. 链路预测任务两种方式

3. 通过邻近进行链路预测

4. 边层级特征

总体来说,边层级特征可以分为三种方式:
- 基于距离的特征(Distance-based feature)
- 局部邻域重叠(Local neighborhood overlap)
- 全局邻域重叠(Global neighborhood overlap)
4.1 基于距离的特征(Distance-based feature)

这种想法很简单,就是比如B、H之间的距离为2,那么就将BH这条边(预测边)的特征值设为2。
但也有很大问题,就是这种方法没有考虑邻域重叠的程度。
4.2 局部邻域重叠(Local neighborhood overlap)

4.3 全局邻域重叠(Global neighborhood overlap)


利用图邻接矩阵的幂计算两个节点之间的路径数。



以上是简单证明,学过数据结构的应该知道这个结论。

5. 总结