在我的这篇博文里
Ubuntu20运行SegNeXt代码提取道路水体(三)——SegNeXt训练与推理自己的数据集
经过一系列配置后
iou算出来是0
经过多次尝试后
终于让我试出来了正确配置方法!
具体的配置细节请查看这篇文章
1、在mmseg/datasets下面对数据集进行初始定义
我新建了一个myroaddata.py文件
里面的内容是:
# Copyright (c) OpenMMLab. All rights reserved.
import os.path as osp
import mmcv
import numpy as np
from PIL import Image
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class MyRoadData(CustomDataset):
CLASSES = ('background','road')
PALETTE = [[0,0,0],[255, 255, 255]]
def __init__(self, **kwargs):
super(MyRoadData, self).__init__(img_suffix='_sat.tif', seg_map_suffix='_mask.png',
**kwargs)
assert osp.exists(self.img_dir)2、修改mmseg/datasets/目录下的_init_.py
把我的自定义数据集加到原_init_.py中
# Copyright (c) OpenMMLab. All rights reserved.
from .ade import ADE20KDataset
from .builder import DATASETS, PIPELINES, build_dataloader, build_dataset
from .chase_db1 import ChaseDB1Dataset
from .cityscapes import CityscapesDataset
from .coco_stuff import COCOStuffDataset
from .custom import CustomDataset
from .dark_zurich import DarkZurichDataset
from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
RepeatDataset)
from .drive import DRIVEDataset
from .hrf import HRFDataset
from .isaid import iSAIDDataset
from .isprs import ISPRSDataset
from .loveda import LoveDADataset
from .night_driving import NightDrivingDataset
from .pascal_context import PascalContextDataset, PascalContextDataset59
from .potsdam import PotsdamDataset
from .stare import STAREDataset
from .voc import PascalVOCDataset
from .myroaddata import MyRoadData
__all__ = [
'CustomDataset', 'build_dataloader', 'ConcatDataset', 'RepeatDataset',
'DATASETS', 'build_dataset', 'PIPELINES', 'CityscapesDataset',
'PascalVOCDataset', 'ADE20KDataset', 'PascalContextDataset',
'PascalContextDataset59', 'ChaseDB1Dataset', 'DRIVEDataset', 'HRFDataset',
'STAREDataset', 'DarkZurichDataset', 'NightDrivingDataset',
'COCOStuffDataset', 'LoveDADataset', 'MultiImageMixDataset',
'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset','MyRoadData'
]3、在configs/base/datasets下面对数据加载进行定义
我新建了一个myroad.py
里面的内容为
# dataset settings
dataset_type = 'MyRoadData'
data_root = 'data/MyRoadData'
img_norm_cfg = dict(
mean=[0.5947, 0.5815, 0.5625], std=[0.1173, 0.1169, 0.1157], to_rgb=True)
img_scale = (512, 512)
crop_size = (256, 256)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=img_scale,
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=8,
train=dict(
type='RepeatDataset',
times=40000,
dataset=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/training',
ann_dir='annotations/training',
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=test_pipeline))
4、在configs/下面选择你需要的模型参数进行修改
在configs/下面选择你需要的模型参数进行修改 以pspnet为例子,在configs/pspnet/下新建一个文件pspnet_r50-d8_512x1024_40k_myroaddata.py
_base_ = [
'../_base_/models/pspnet_r50-d8.py', '../_base_/datasets/myroad.py',
'../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
]
5、修改configs/base/models/下面的pspnet_r50-d8.py
# model settings
norm_cfg = dict(type='BN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='PSPHead',
in_channels=2048,
in_index=3,
channels=512,
pool_scales=(1, 2, 3, 6),
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))6、返回tools/train.py进行训练
python tools/train.py configs/pspnet/pspnet_r50-d8_512x1024_40k_myroaddata.py
就可以跑啦
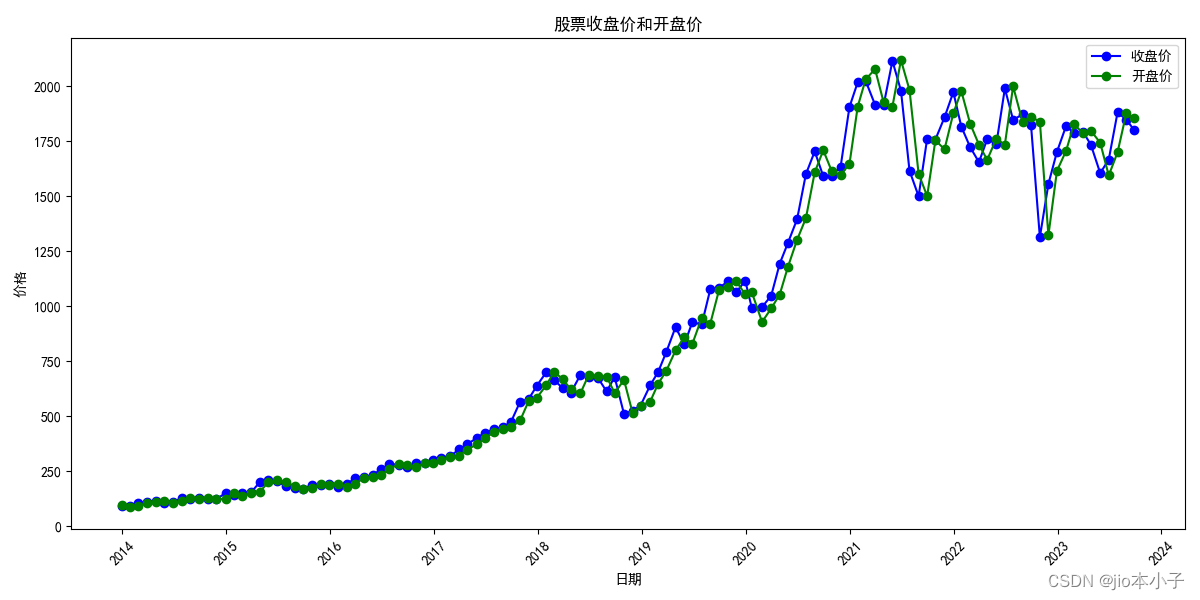
结果图:

自定义数据集格式配置
在data文件夹下新建一个MyRoadData文件夹,存放数据
再次新建俩个文件夹

annotation和images下面新建training和validation文件夹
annotation-training下放训练标签
annotation-validation放预测标签
同理
images-training放训练原图
images-validation下放预测原图
1、图片格式要求为8位深度
注意,如果是24位的图片要全部转成8位!!!!
不然会报错
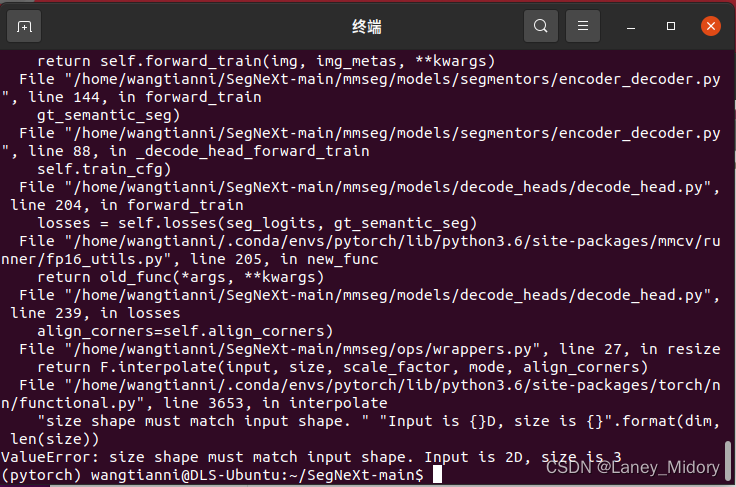
转换代码如下
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 4 16:50:20 2022
@author:Laney_Midory
csdn:Laney_Midory
"""
import cv2
import os
import glob
import shutil
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
import torch.utils.data as data
from torch.autograd import Variable as V
import pickle
from time import time
os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 指定第一块GPU可用
# config.gpu_options.per_process_gpu_memory_fraction = 0.7 # 程序最多只能占用指定gpu50%的显存,服务器上注释掉这句
Image.MAX_IMAGE_PIXELS = None
tar = "/home/wangtianni/SegNeXt-main/SegNeXt-main/data/data/MyRoadData/annotations/training/"
print('将24位深度转换为8位')
mask_names = filter(lambda x: x.find('png')!=-1, os.listdir(tar))
#trainlist = list(map(lambda x: x[:-8], imagelist))
#new_path = "C:/Users/Administrator/Desktop/white/" # 目标文件夹
for file in mask_names:
path = tar + file.strip()
if not os.path.exists(path):
continue;
img = Image.open(tar+file)#读取系统的内照片
img2 = img.convert('P')
# print(train_path+'\\'+base_name[0]+'_mask.png')
img2.save(path)
#img2.save(new_path +path2 + "_mask.png")
print("Finish deep change!")