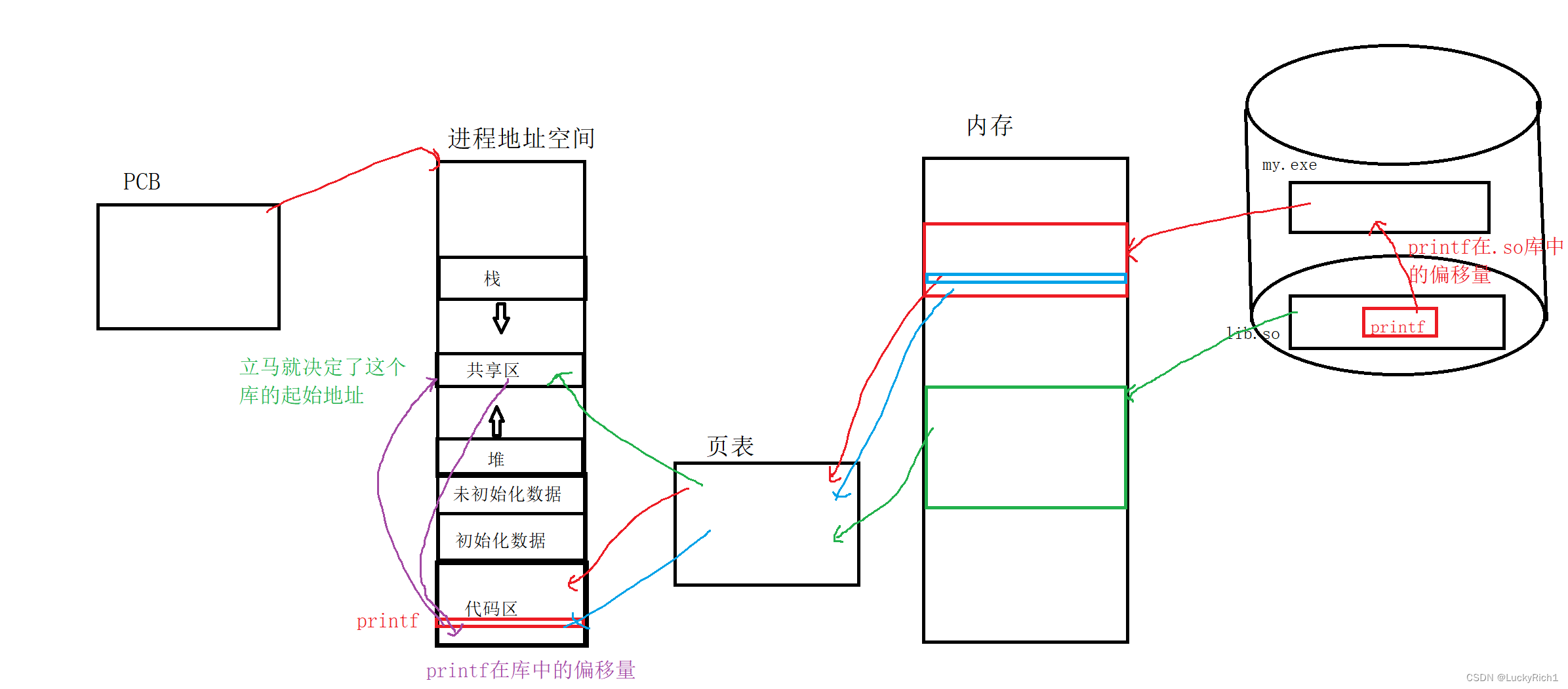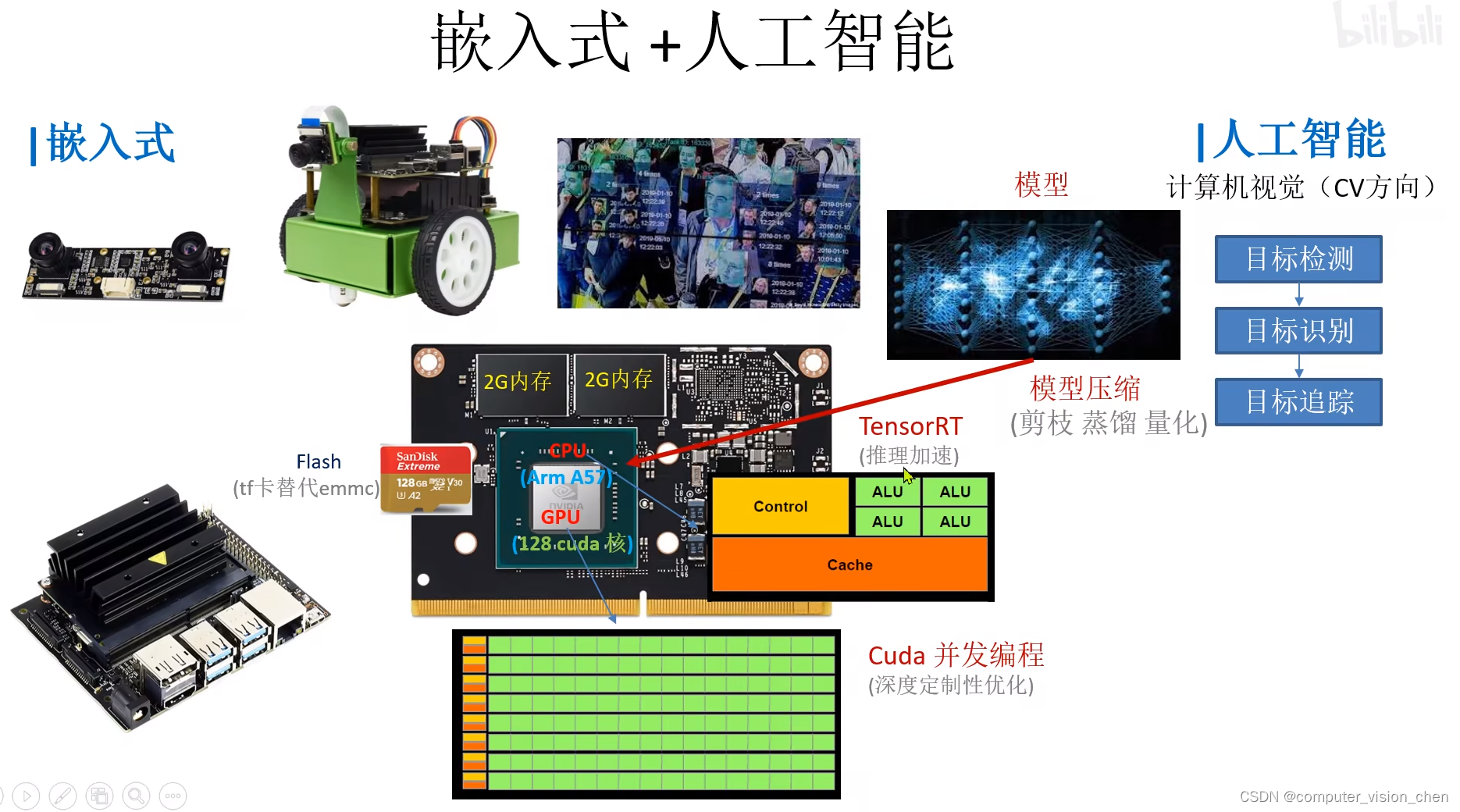
CPU是Arm A57的
GPU是128cuda核
一.小车跟踪的需求和设计方法
比如有一个小车跟踪的项目。
需求是:小车识别出罪犯,然后去跟踪他。
方法:摄像头采集到人之后传入到开发板,内部做一下识别,然后控制小车去跟随。
在人工智能算法上:
先目标检测,找到人脸
然后目标识别,把人脸与库中人脸比对
然后目标追踪,运动轨迹预测。防止重新检测和识别。
二.嵌入式设备上的运算流程
模型存在 Flash卡(类似硬盘,永久存储)上面。
运行的时候把数据搬到内存里面,速度比flash快很多。现在的手机都是 Flash + 内存。
AI模型师放到Flash硬盘里的,然后加载到内存,内存再加载到GPU。
三.算法的部署流程
3.1 剪枝、蒸馏、量化
要把模型在板子上快速运行。
先把模型压缩,减少运算量。
表现为:剪枝、蒸馏、量化
剪枝:去掉权重很低的神经元。
蒸馏:找个比较大的模型去训练,蒸馏出比较关键的分布,再用小模型基于这个分布训练。
量化:对模型运算的时候,很多都是浮点数,有的场合不需要这么这么长的精度。
3.2 TensorRT 推理加速
英伟达提出的,其它公司可能有自己的工具。
推理加速可以提升到10-100秒。
3.3 cuda并发编程
基于硬件层的优化
如果对上面的速度还不满意,可以使用cuda并发编程。
网上有岗位叫GPU工程师。
怎么使GPU效率最高,读进来的时候有延迟,类似于调度算法,你看看怎么分配,使他们的时间衔接最好。个性化定制。
CPU负责任务调度,数据都是存在flash上面的。
CPU构造:
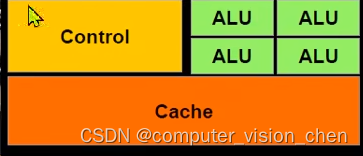
运算的时候CPU将内存中的数据搬到cache中,cache的速度比内存块。再通过控制器把cache的数据放到ALU运算单元中去,cpu的运算单元比较少。
GPU构造
128 cuda核的GPU就是有128个ALU运算单元
8行16列=128。
每一行是一组,每组都有控制单元和Cache。这八组可以并行计算。

CPU是牛人,可以处理复杂逻辑。
GPU是人多力量大,适合逻辑简单,工作内容很多的工作。
四.补充知识
4.1 NVIDIA Jetson Nano开发板
NVIDIA Jetson Nano开发板:
NVIDIA Jetson Nano是一款基于ARM架构的高性能开发板,
它具有强大的计算能力、多种外设接口和易于使用的编程环境,
适用于各种人工智能和嵌入式系统开发。
4.2 ARM处理器架构
Advanced RISC Machine,广泛应用于嵌入式机器的处理器设计。
ARM处理器具有高性能MPU和多种并行控制单元和通信接口,
构成支持多种应用的强大架构,广泛应用于消费性电子产品、电脑外设、
甚至导弹的弹载计算机等军用设施。
参考链接
https://www.bilibili.com/video/BV19m4y1978f/?spm_id_from=333.999.top_right_bar_window_history.content.click&vd_source=ebc47f36e62b223817b8e0edff181613