目录
一.DQL的定义
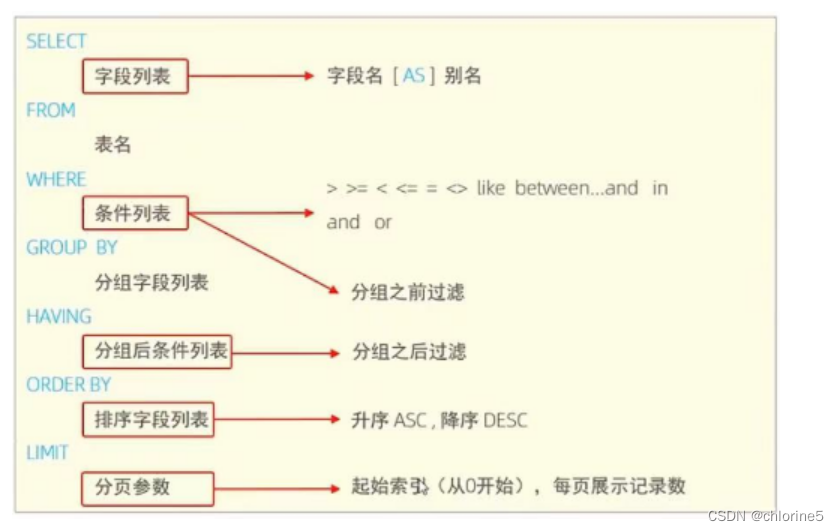
二.DQL—语法
三.DQL—基础查询(SELECT.. FROM)
👉查询多个字段
👉设置别名
👉去除重复记录
@准备工作(建表,添加数据)
&DQL----基本查询的案例
五.DQL—条件查询(WHERE)
5.1 语法:
5.2.条件
&DQL-----条件查询的十一个案例
六.DQL——聚合函数
6.1 介绍
6.2.常见聚合函数
6.3.语法
&DQL-----聚合函数的五个案例
七.DQL——分组查询(GROUP BY)
7.1 语法
&DQL------分组查询的三个案例
八.SQL——排序查询(ORDER BY)
8.1.语法
8.2.排序方式
&DQL----排序查询三个案例分析
九.SQL——分页查询(LIMIT)
9.1.语法
&DQL------分页查询的三个案例
十.综合案例
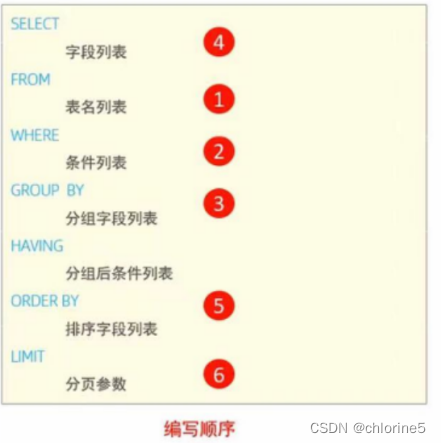
十一.DQL——编写顺序
&案例---编写顺序
十二.DQL——总结
一.DQL的定义
DQL(Data Query Language):数据查询语言,用来查询数据库中表的记录。
- 查询关键字:SELECT
前俩篇SQL语言中我们学到了DML,DDL,我们按我们学过的知识想一下,
对数据的增删查改的效率高,还是查询的效率高?
- ——那必定是查询的效率高
二.DQL—语法

-----//基础查询
【SELECT
字段列表
FROM
表名列表】
-----//条件查询
WHERE
条件列表
------//聚合函数
count,max,min,avg,sum;
------//分组查询
GROUP BY
分组字段列表
HAVING
分组后条件列表
-------//排序查询
ORDER BY
排序字段列表
------//分页查询
LIMIT
分页参数
三.DQL—基础查询(SELECT.. FROM)
👉查询多个字段
SELECT 字段1,字段2,字段3.... FROM 表名;
SELECT * FROM 表名;//查询返回所有字段用*号👉设置别名
SELECT 字段1 [AS 别名1], 字段2 [AS 别名2].....FROM 表名;
--其中的AS是可以省略的👉去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;@准备工作(建表,添加数据)
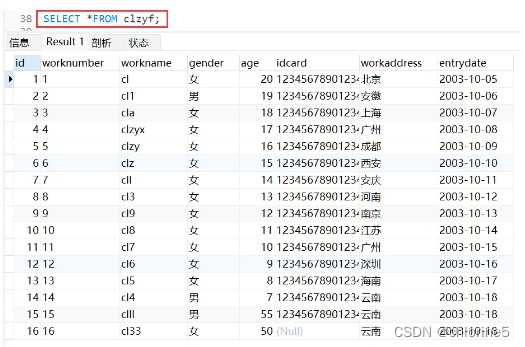
- 首先我们需要对数据进行数据准备,为了更好的完成接下来的数据查询。
---查询数据--------- ---数据准备 use cl; SELECT DATABASE(); CREATE table clzyf( id int COMMENT'编号', worknumber varchar(10) COMMENT'员工工号', workname VARCHAR(10) COMMENT'员工姓名', gender char(1) COMMENT'员工性别', age TINYINT UNSIGNED COMMENT'员工年龄', idcard char(18) COMMENT'员工身份证号', workaddress VARCHAR(50) COMMENT'工作地址'; entrydate date COMMENT'入职时间' )COMMENT'员工表';
- 将下列16个成员都添加到表中
INSERT INTO clzyf(id,worknumber,workname,gender,age,idcard,workaddress,entrydate) VALUES (1,'1','cl','女',20,'123456789012345678','北京','2003-10-05'), (2,'2','cl1','男',19,'123456789012345671','安徽','2003-10-06'), (3,'3','cla','女',18,'123456789012345689','上海','2003-10-07'), (4,'4','clzyx','女',17,'123456789012345602','广州','2003-10-08'), (5,'5','clzy','女',16,'123456789012345603','成都','2003-10-09'), (6,'6','clz','女',15,'123456789012345604','西安','2003-10-10'), (7,'7','cll','女',14,'123456789012345605','安庆','2003-10-11'), (8,'8','cl3','女',13,'123456789012345606','河南','2003-10-12'), (9,'9','cl9','女',12,'123456789012345607','南京','2003-10-13'), (10,'10','cl8','女',11,'123456789012345608','江苏','2003-10-14'), (11,'11','cl7','女',10,'123456789012345609','广州','2003-10-15'), (12,'12','cl6','女',09,'123456789012345680','深圳','2003-10-16'), (13,'13','cl5','女',08,'123456789012345697','海南','2003-10-17'), (14,'14','cl4','男',07,'123456789012345699','云南','2003-10-18'), (15,'15','clll','男',55,'123456789012345676','云南','2003-10-18'), (16,'16','cl33','女',50,null,'云南','2003-10-18');
表明16行运行成功,我们接下来看看这个表的所有数据的形成。
- SELECT * FROM 表名——查看表数据
好的,准备工作已经完成。我们接下来就进行基本查询的语法。
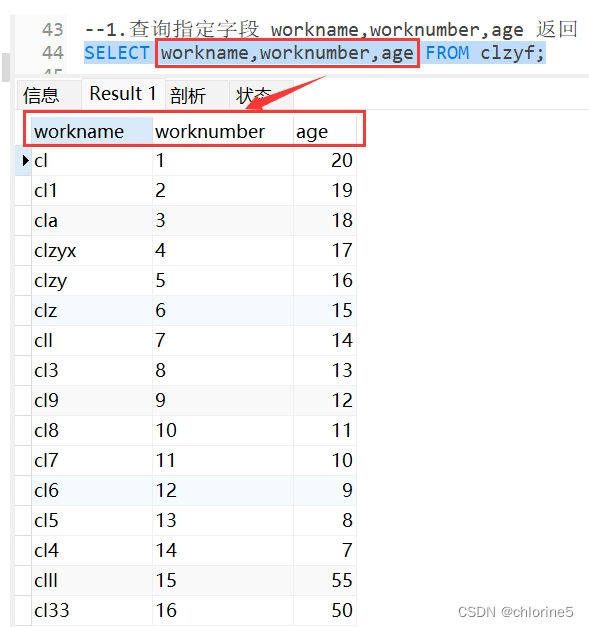
&DQL----基本查询的案例

- 1.查询指定字段 workname,worknumber,age 返回
SELECT 字段1,字段2,字段3.... FROM 表名;
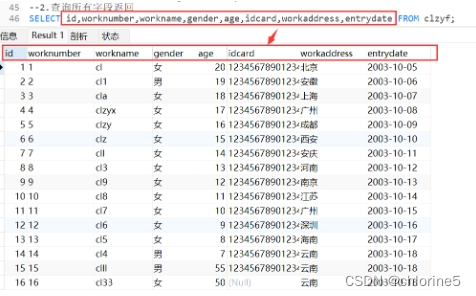
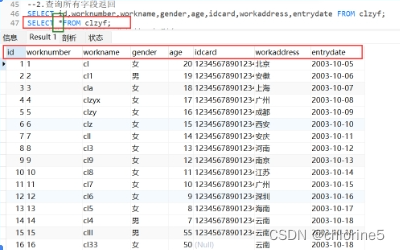
- 2.查询所有字段返回
SELECT * FROM 表名;//查询返回所有字段用*号
还有一种比较简单的写法的,直接将所有字段总称为*
但是不建议这样写,在实际开发中不建议写*,原因有俩个,第一个不直观,第二个会影响效率。在开发中都有规范,不要怕麻烦,尽量都写出来。
- 3.查询所有员工的工作地址,起别名
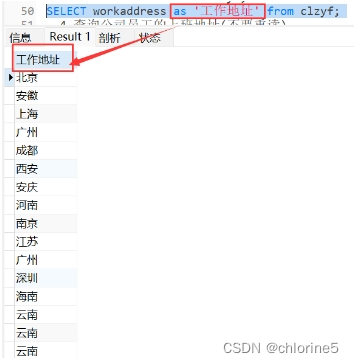
但是这里的workaddress书写有点长,我想给这个工作地址起个别名。就用到下面的语法了。
SELECT 字段1,字段2,字段3.... as '别名' FROM 表名;
as是可以省略的
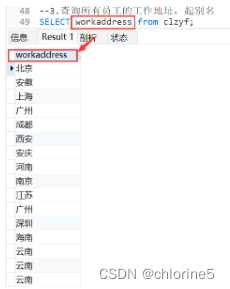

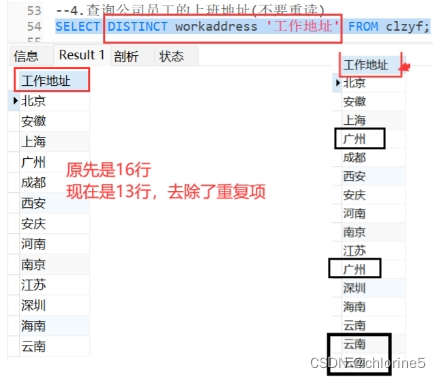
- 4.查询公司员工的上班地址(不要重读)
SELECT DISTINCT 字段列表 FROM 表名;
五.DQL—条件查询(WHERE)
5.1 语法:
SELECT 字段列表 FROM 表名 WHERE 条件列表;5.2.条件
&DQL-----条件查询的十一个案例
为了更方便,我虽然说用*不好,但是为了方便演示,我直接用*来表示所有字段
---条件查询
---1.查询年龄等于18的员工
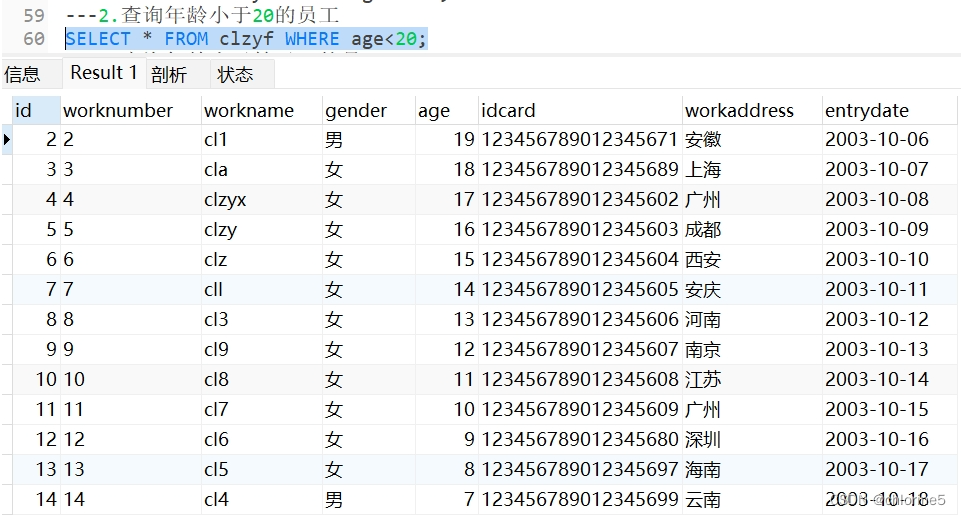
---2.查询年龄小于20的员工
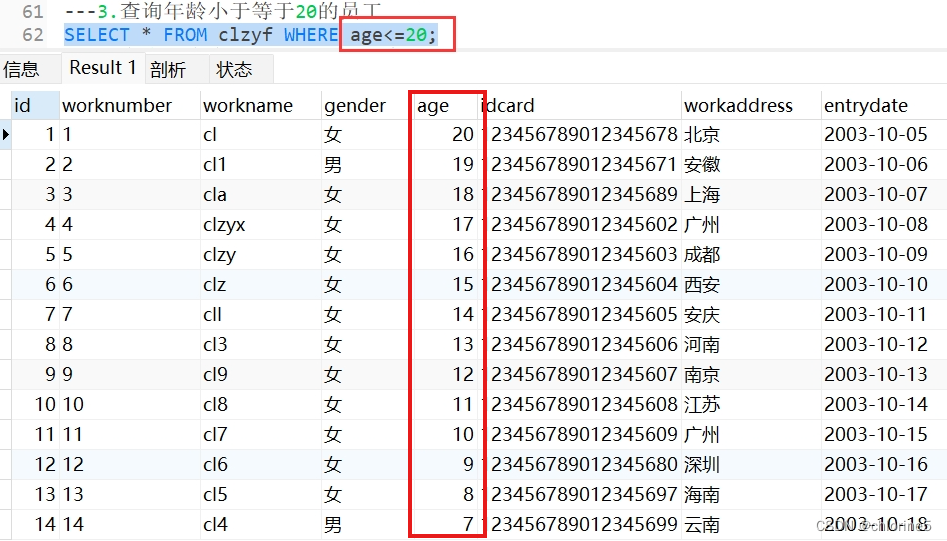
---3.查询年龄小于等于20的员工
---4.查询没有身份证号的员工信息
---5.查询有身份证号的员工信息
---6.查询年龄不等于18的员工信息
---7.查询年龄在15岁(包含)到20岁(包含)之间的员工信息
---8.查询性别为 女 且年龄小于25岁的员工信息
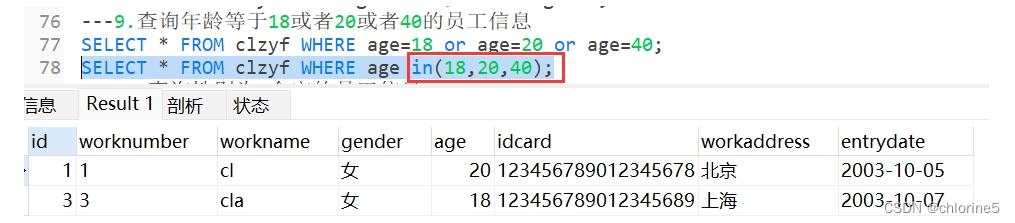
---9.查询年龄等于18或者20或者40的员工信息
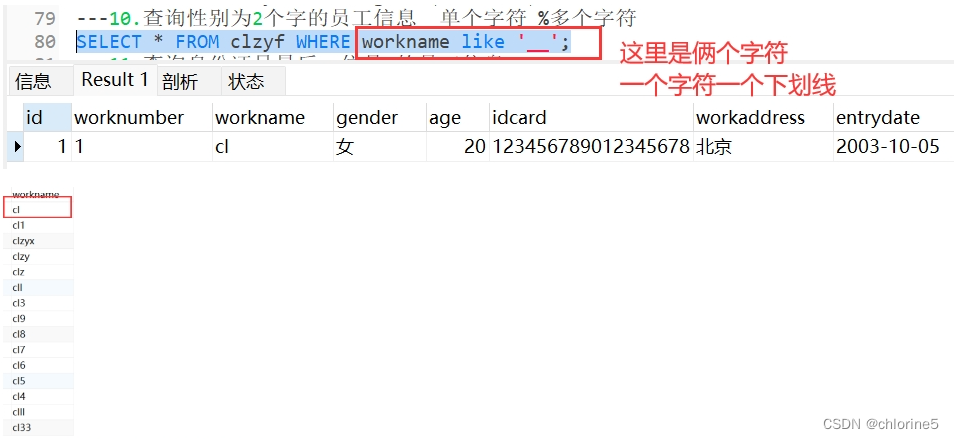
---10.查询性名为2个字的员工信息
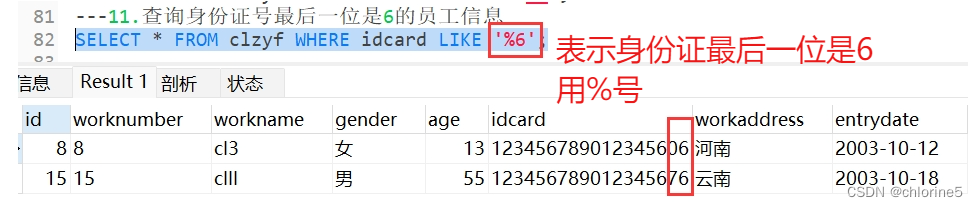
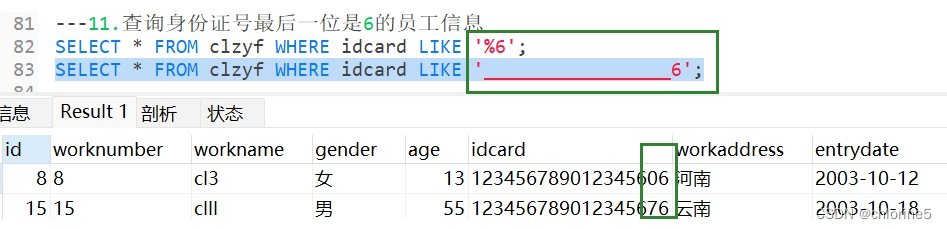
---11.查询身份证号最后一位是6的员工信息
- 1.查询年龄等于18的员工

- 2.查询年龄小于20的员工
- 3.查询年龄小于等于20的员工
- 4.查询没有身份证号的员工信息


- 5.查询有身份证号的员工信息
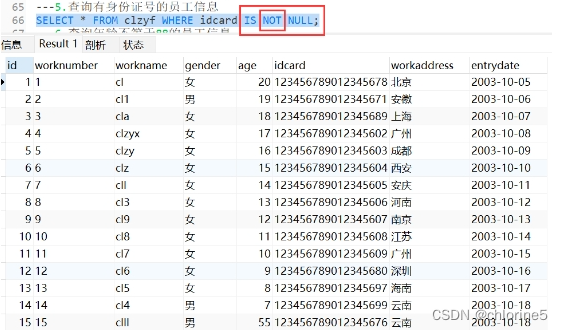
6.查询年龄不等于18的员工信息
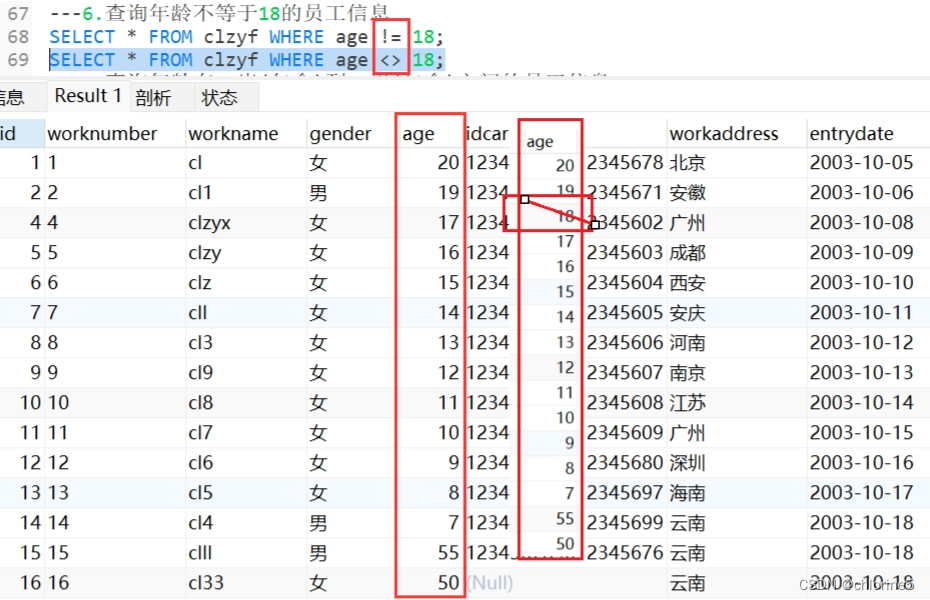
- 7.查询年龄在15岁(包含)到20岁(包含)之间的员工信息
都必须满足用 and或者 && 或者 between..and..,大多数都是用and更好
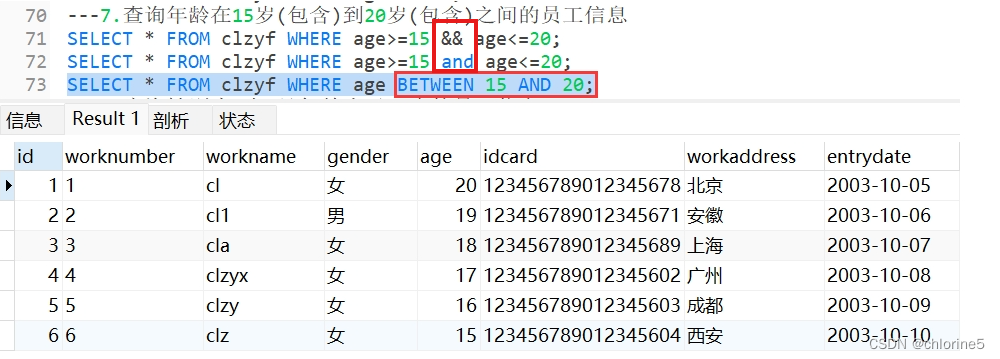
- 8.查询性别为 女 且年龄小于25岁的员工信息(且用and)
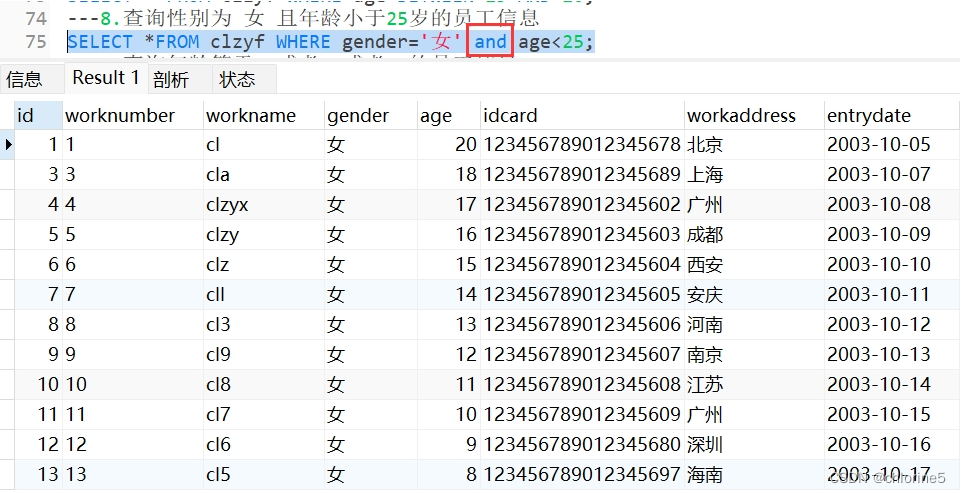
- 9.查询年龄等于18或者20或者40的员工信息
在SQL语言中这样一直or下去是很麻烦的,我们有更简便的语句

- 10.查询姓名为2个字符的员工信息
- _单个字符(有几个字符就几个下划线)
- %任意个字符
- 11.查询身份证号最后一位是6的员工信息
_单个字符(有几个字符就几个下划线) %任意个字符
%x表示前面多少位字符是什么都不管,最后一个字符是x
%6表示前面多少位字符是什么没关系,最后一个字符是6.
那么大家来思考一个问题,如何用_下划线来实现对查询身份证最后一位6的员工信息
身份证号是18位,我们需要满足最后一个是6,所以需要用17个下划线就可以完成
我的建议还是用%号,因为如果100位数,需要查询最后一个数是6.我们要打99个下划线吗?
不太现实,为了更方便,用%100即可.
六.DQL——聚合函数
一般解答聚合函数,都会同分组查询进行操作。
首先我们对聚合函数进行讲解,然后对分组查询进行讲解
6.1 介绍
将一列数据作为一个整体,进行纵向计算。
6.2.常见聚合函数
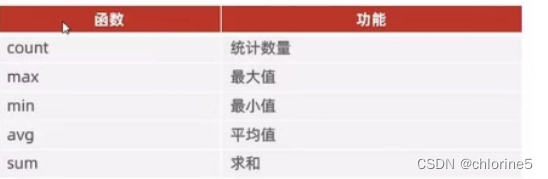
这些函数都是作用于表的某一列数据.
6.3.语法
SELECT 聚合函数(字段列表) FROM 表名;&DQL-----聚合函数的五个案例
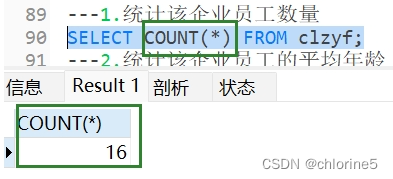
---1.统计该企业员工数量
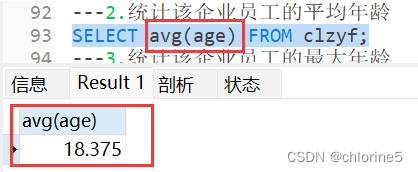
---2.统计该企业员工的平均年龄
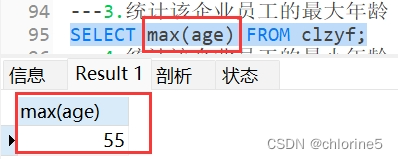
---3.统计该企业员工的最大年龄
---4.统计该企业员工的最小年龄
---5.统计该企业员工云南地区的年龄之和
- ---1.统计该企业员工数量
- ---2.统计该企业员工的平均年龄
- ---3.统计该企业员工的最大年龄
---4.统计该企业员工的最小年龄
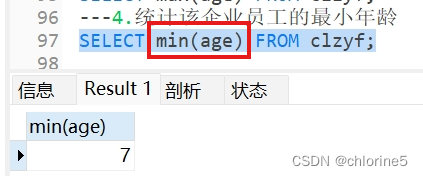
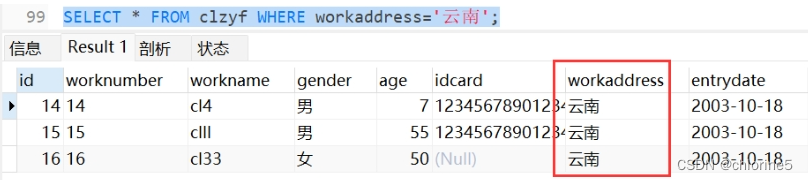
---5.统计该企业员工云南地区的年龄之和
5.1.首先我们先从表中找到地区在云南的有几个
5.2.然后求和年龄大小之和。

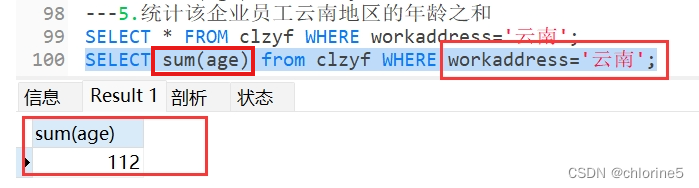
注意:所有的Null值不参与所有聚合函数运算。
七.DQL——分组查询(GROUP BY)
7.1 语法
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件];where与having的区别:
- 执行时机不同:where是分组之前进行过滤,如果不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
&DQL------分组查询的三个案例
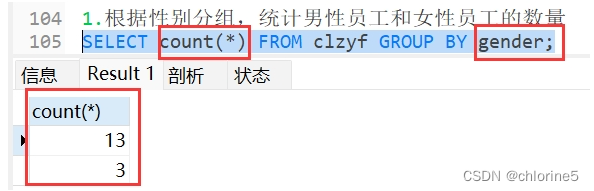
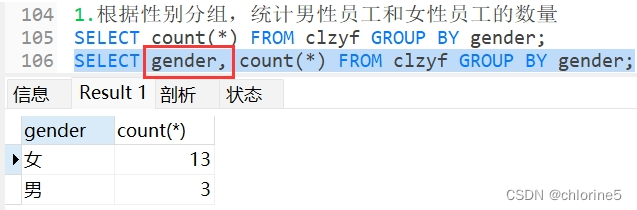
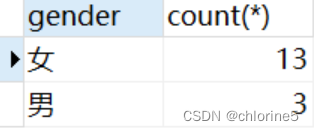
1.根据性别分组,统计男性员工和女性员工的数量
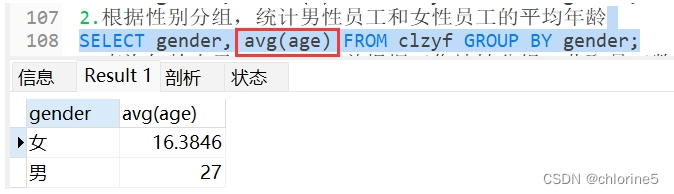
2.根据性别分组,统计男性员工和女性员工的平均年龄
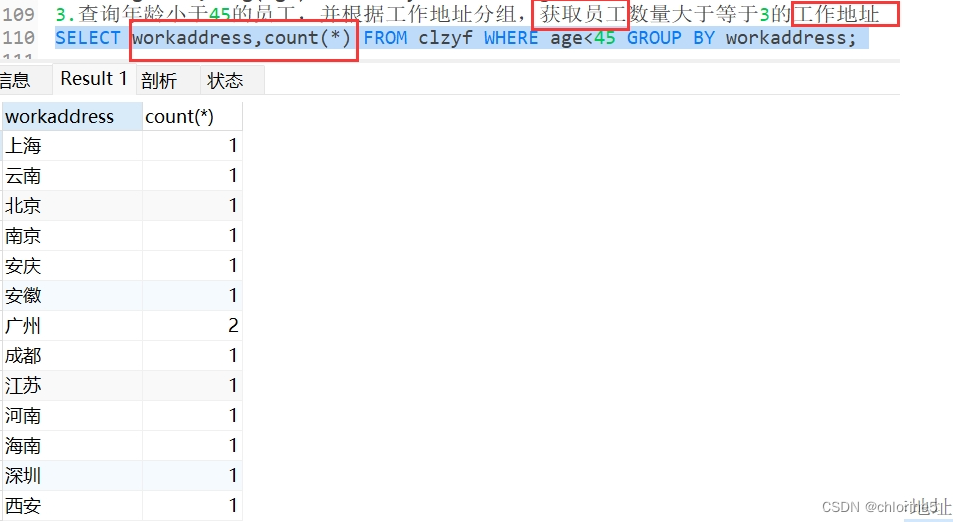
3.查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
- -----1.根据性别分组,统计男性员工和女性员工的数量
这里只是展示女性员工和男性员工的总人数,但是我们想知道哪一个是女生哪一个是男生的数量
- -----2.根据性别分组,统计男性员工和女性员工的平均年龄
- ---3.查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
我们现在进行四步走攻略
- 第一步:查询年龄小于45的员工
- 第二步:根据工作地址分组
- 第三步:获取员工数量的工作地址
- 第四步:获取员工数量大于等于3的工作地址(having)
这里显示的是工作地址分组后,获取员工数量大于等于3的工作地址,所以用having来表分组后的条件。



可以给count(*)取别名address_count
只不过中间 少了个as

注意:
执行顺序:where(分组聚合之前)>聚合函数>having(分组聚合之后);
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
加gender字段只是为了使更清楚,不然不知道哪个是女生的总数量,哪个是男生的总数量,
但是发挥主要作用的是count(*)-聚合函数和GROUP BY分组函数


八.SQL——排序查询(ORDER BY)
8.1.语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2;8.2.排序方式
- ASC:升序(默认值)
- DESC:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
&DQL----排序查询三个案例分析
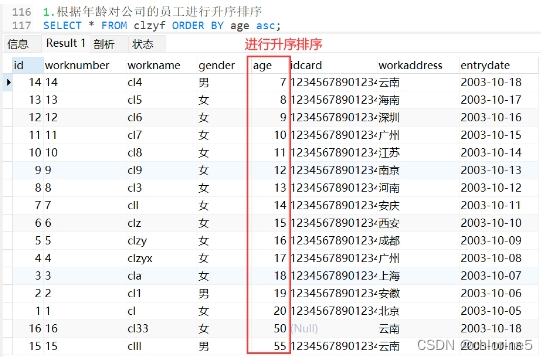
1.根据年龄对公司的员工进行升序排序
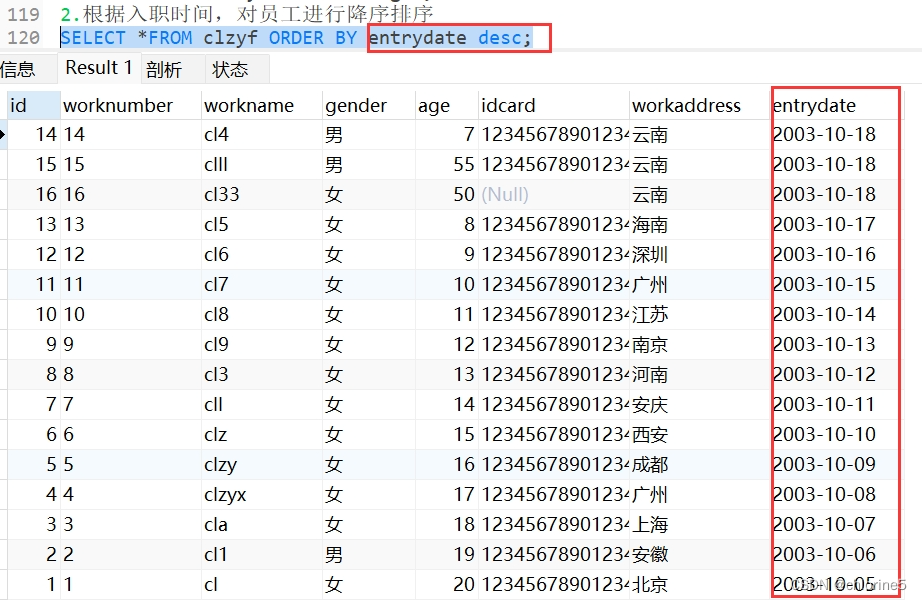
2.根据入职时间,对员工进行降序排序
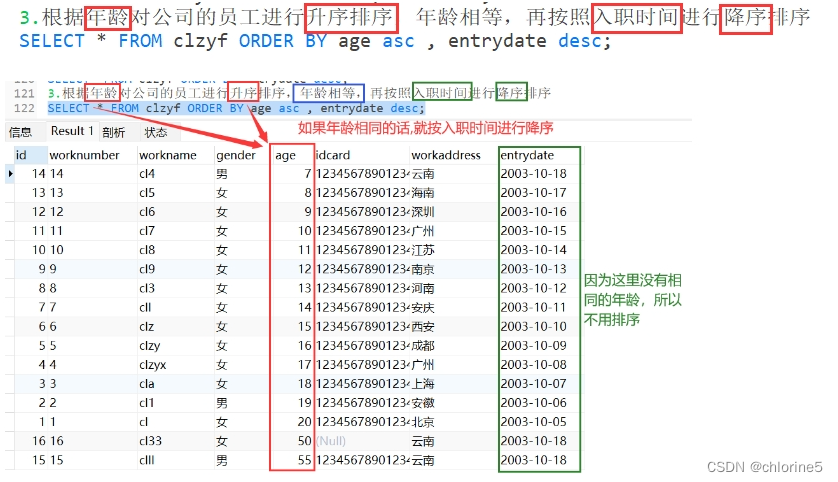
3.根据年龄对公司的员工进行升序排序,年龄相等,再按照入职时间进行降序排序
- ----1.根据年龄对公司的员工进行升序排序
我们前面说了,src是默认值,可以省略src,默认是升序。
- ----2.根据入职时间,对员工进行降序排序
- ----3.根据年龄对公司的员工进行升序排序,年龄相等,再按照入职时间进行降序排序
- 第一步:年龄升序排序
- 第二步:如果年龄相同,入职时间降序(年龄升序,入职时间降序(之间用逗号连接))
注意:多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。

九.SQL——分页查询(LIMIT)
![]()
分页在未来做的是传统的管理系统,还是做互联网,都会遇到分页查询
9.1.语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询记录数;注意:
- 起始索引是从0开始,起始索引=(查询页码-1)*每页显示记录数;
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中式LIMIT
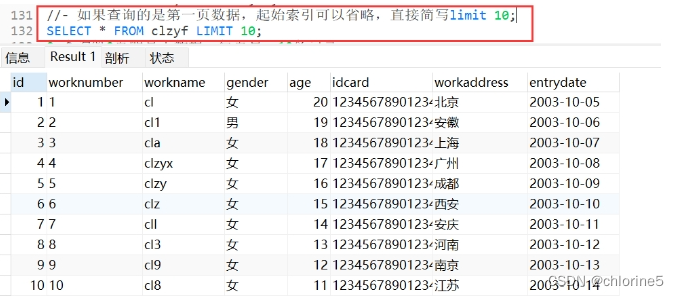
- 如果查询的是第一页数据,起始索引可以省略,直接简写limit 10;
&DQL------分页查询的三个案例
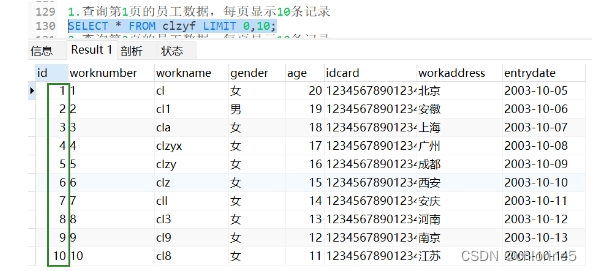
1.查询第1页的员工数据,每页显示10条记录
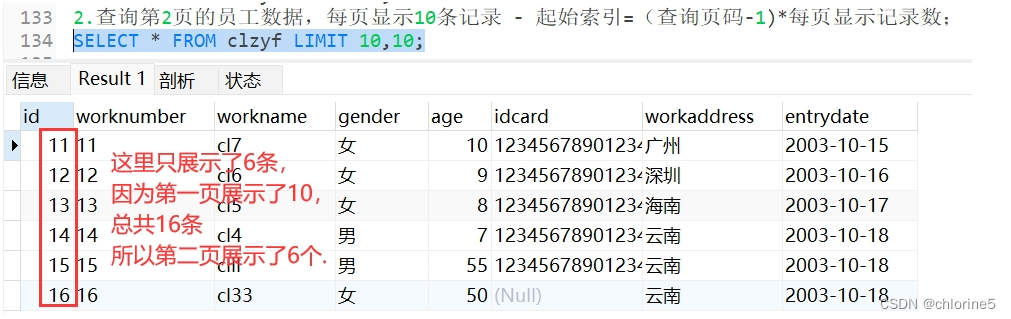
2.查询第2页的员工数据,每页显示10条记录
- ---1.查询第1页的员工数据,每页显示10条记录
LIMIT 起始索引,查询记录数;
- 第一个数值是起始索引【起始索引=(查询页码-1)*每页显示记录数】如果是第一页,那么起始索引就是0
- 第二个数值就是每页的显示的几条记录,本题是10。
查询的第一页的数据,起始索引是可以省略的,所以可以直接省略0
- ---2.查询第2页的员工数据,每页显示10条记录
十.综合案例
- ----1.查询年龄为20,21,22,23岁的女性员工信息
SELECT * FROM clzyf WHERE 字段名 in(值1,值2,...);

- ---2.查询性别为男,并且年龄在20—40岁(含) 以内的姓名为三个字的员工

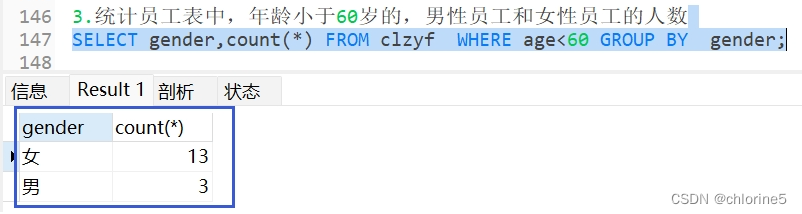
- ---3.统计员工表中,年龄小于60岁的,男性员工和女性员工的人数
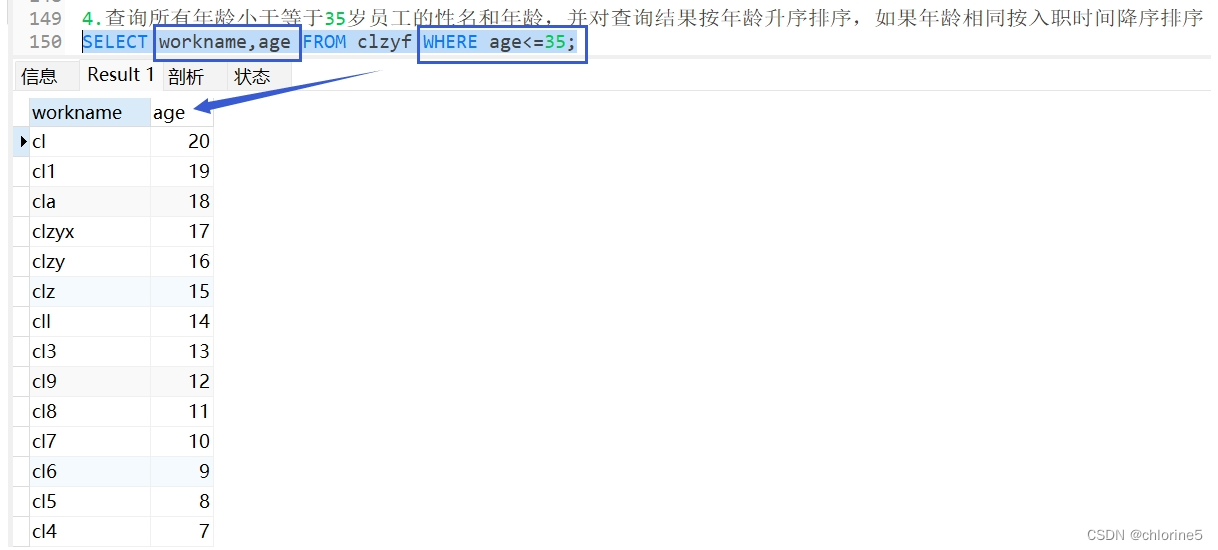
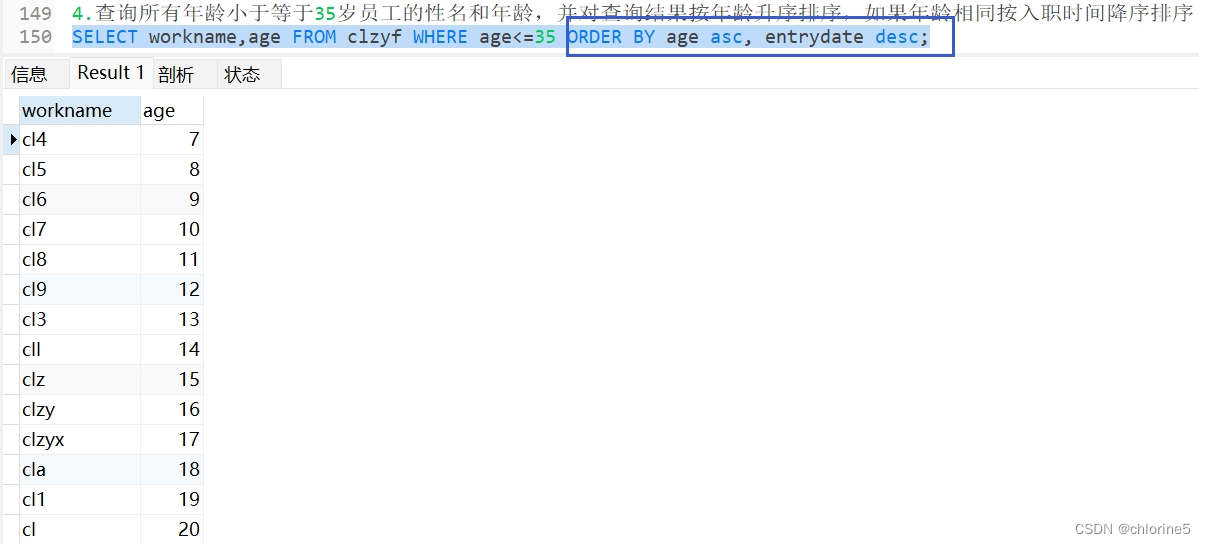
- --4.查询所有年龄小于等于35岁员工的性名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序
进行俩步走过程
第一步:查询所有年龄小于等于35员工的姓名和年龄
第二步:进行排序,对年龄升序排序,如果年龄相同,就对入职时间降序,用逗号隔开就好。(首先年龄升序排序,然后用逗号,最后入职时间降序)
- ----5.查询性别为男,且年龄在20-40岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序
第一步:性别为男,年龄在20-40岁(含)以内的
第二步:1.首先对年龄升序排序,年龄相同按入职时间升序排序
2.然后取第一页中的前5个员工信息即可(就是在第一页中,显示5个记录)


我们上面说的是编写顺序,并不是执行顺序,按照由上而下的关键词顺序往后写


第一步是SELECT* FROM 第二个是WHERE ,第三个是ORDER BY ,第四个是LIMIT.
十一.编写顺序

我们就从案例中理解这个编写顺序的问题吧。
&案例---编写顺序
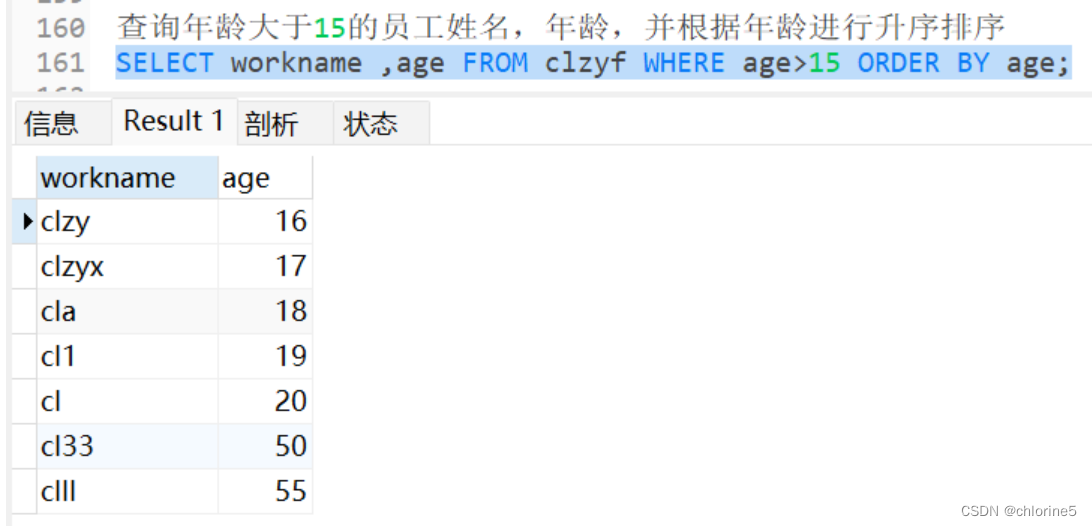
1.----查询年龄大于15的员工姓名,年龄,并根据年龄进行升序排序
我们只是看到段SQL语言是执行成功的,并不知道其中的编写顺序。那该如何验证其中的编写顺序呢?
——这就需要我们对其起别名了。(AS)
我们根据编写顺序
首先第一步执行的是FROM ,给clzyf取别名e,
然后第二步执行WHERE,用e.age即可
运行成功,说明先执行FROM,再执行WHERE。
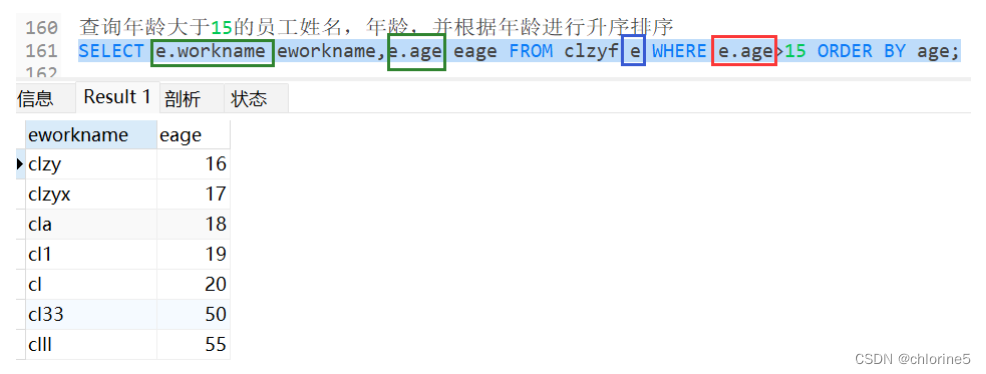
然后第三步执行SELEXT
我们将SELECT后面的workname和age分别取别名e.workname,e.age.
——一样是运行成功,因为FROM是第一步执行的,然后通过别名e找到WHERE,然后第三步就是SELECT中进行。


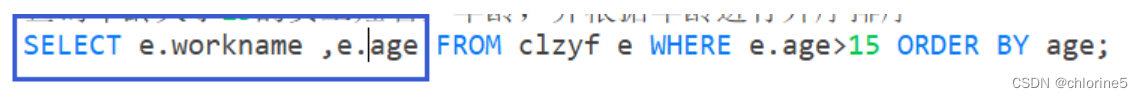
好
那我们对WHERE中的e.age改成eage,那么我们的SQL语言能运行成功嘛?
第一步FROM,别名是e,然后第二个WHERE是需要通过e来声明的别名,但是WHERE是eage,所以第三个SELECT是无法进行的。
这就证明了SELECT就在WHERE之后,WHERE是在FROM之后的。
我们必须符合下面的代码进行~(因为其中包含着编写顺序的)
——所以DQL语言查询语言,其中存在着编写顺序。

十二.DQL——总结
休息时间才能体现人类的价值。