🦄 个人主页——🎐个人主页 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 感谢点赞和关注 ,每天进步一点点!加油!🪁🍁🪁🍁🪁🍁🪁🍁
目录
🦄 个人主页——🎐个人主页 🎐✨🍁
一、DataX概览
1.1 DataX 简介
1.2 DataX框架
1.3 功能限制
1.4 Support Data Channels
二、配置样例
2.1 环境信息
2.2 SQLServer数据同步到HDFS
2.2 参数说明
一、DataX概览
1.1 DataX 简介
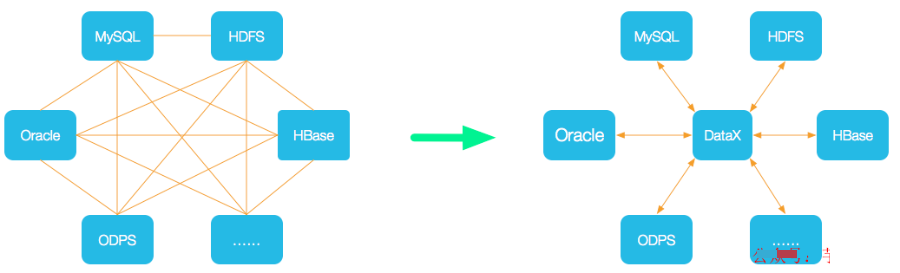
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
1.2 DataX框架
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
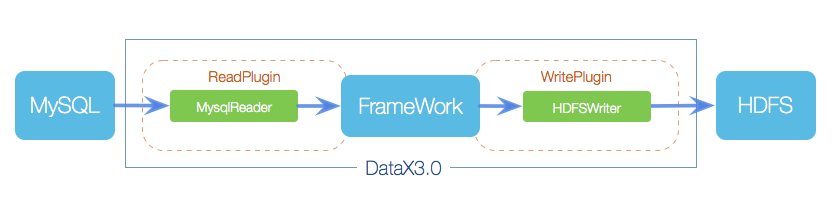
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
| 角色 | 作用 |
| Reader(采集模块) | 负责采集数据源的数据,将数据发送给 Framework。 |
| Writer(写入模块) | 负责不断向 Framework 中取数据,并将数据写入到目的端。 |
| Framework(中间商) | 负责连接 Reader 和 Writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。 |
HdfsWriter 提供向 HDFS 文件系统指定路径中写入 TEXTFILE 文件和 ORCFile 文件,文件内容可与 Hive 表关联。
1.3 功能限制
- 目前 HdfsWriter 仅支持 textfile 和 orcfile 两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表;
- 由于 HDFS 是文件系统,不存在 schema 的概念,因此不支持对部分列写入;
- 目前仅支持与以下 Hive 数据类型:
数值型:TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE
字符串类型:STRING,VARCHAR,CHAR
布尔类型:BOOLEAN
时间类型:DATE,TIMESTAMP
目前不支持:decimal、binary、arrays、maps、structs、union类型;
- 对于 Hive 分区表目前仅支持一次写入单个分区;
- 对于 textfile 需用户保证写入 hdfs 文件的分隔符与在 Hive 上创建表时的分隔符一致,从而实现写入 hdfs 数据与 Hive 表字段关联;
HdfsWriter 实现过程是:
首先根据用户指定的path,创建一个hdfs文件系统上不存在的临时目录,创建规则:path_随机; 然后将读取的文件写入这个临时目录; 全部写入后再将这个临时目录下的文件移动到用户指定目录(在创建文件时保证文件名不重复); 最后删除临时目录。 如果在中间过程发生网络中断等情况造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录。
1.4 Support Data Channels
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 图数据库 | 阿里云 GDB | √ | √ | 读 、写 |
| Neo4j | √ | 写 | ||
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | √ | 读 、写 | |
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
二、配置样例
2.1 环境信息
集群HDP版本信息如下:
2.2 SQLServer数据同步到HDFS
site_traffic_inout.json 配置文件
[winner_hdp@hdp104 yd]$ cat site_traffic_inout.json
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"username": "$IPVA_WSHOP_USER",
"password": "$IPVA_WSHOP_PASSWD",
"connection": [
{
"jdbcUrl": ["$IPVA_URL"],
"querySql": [
"SELECT StoreID,StoreName,SiteKey,SiteName from IPVA_WConfig.dbo.View_Site_Traffic_InOut;"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"StoreID" , "type":"string"},
{"name":"StoreName" , "type":"string"},
{"name":"SiteKey" , "type":"string"},
{"name":"SiteName", "type":"string"}
],
"path": "/winner/hadoop/winipva/wshop/tmp/",
"defaultFS":"hdfs://winner",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"hadoopConfig":{
"dfs.nameservices": "winner",
"dfs.ha.namenodes.winner": "nn1,nn2",
"dfs.namenode.rpc-address.winner.nn1": "hdp103:8020",
"dfs.namenode.rpc-address.winner.nn2": "hdp104:8020",
"dfs.client.failover.proxy.provider.winner": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"haveKerberos": true,
"kerberosKeytabFilePath": "/etc/security/keytabs/winner_hdp.keytab",
"kerberosPrincipal": "winner_hdp@WINNER.COM",
"fileType": "text",
"fileName": "000000",
"writeMode": "nonConflict",
}
}
}
],
"setting": {
"speed": {
"channel": "5"
},
"errorLimit": {
"record": 0
}
}
}
}
运行脚本
# !/bin/bash
#
#
# 脚本功能: sqlServer 数据同步到 HDFS
# 作 者: kangll
# 创建时间: 2022-10-27
# 修改内容: 无
# 调度周期:
# 脚本参数: 无
#
set -x
set -e
## datatime
date=`date +%Y%m%d`
## json config file path
json_src=/hadoop/datadir/windeploy/script/ETL/datax_json/
## datax path
data_py=/hadoop/software/datax/bin/datax.py
## ipva Wshop_config database connection
IPVA_USER=sa
IPVA_PASSWD='123456'
IPVA_URL="jdbc:sqlserver://192.168.2.103:1433;DatabaseName=IPVA_WConfig"
###
Site_ReID_InOut_Func() {
## 执行数据同步
python $data_py ${json_src}site_reid_inout.json -p "-DIPVA_USER=${IPVA_USER} -DIPVA_PASSWD=${IPVA_PASSWD} -DIPVA_URL=${IPVA_URL} -Ddate=${date}"
}
######################## main ###############################
main(){
Site_ReID_InOut_Func
}
#############################################################
###
main同步成功

2.3 参数说明
- defaultFS
描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000 必选:是 默认值:无
- fileType
描述:文件的类型,目前只支持用户配置为"text"或"orc"。 text表示textfile文件格式 orc表示orcfile文件格式 必选:是 默认值:无
- fileName
描述:HdfsWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。 必选:是 默认值:无
- column
描述:写入数据的字段,不支持对部分列写入。为与hive中表关联,需要指定表中所有字段名和字段类型,其中:
name指定字段名,type指定字段类型。
用户可以指定Column字段信息,配置如下:
"column":
[
{
"name": "userName","type": "string"
},
{
"name": "age","type": "long"
}
]
必选:是
默认值:无 - writeMode
描述:hdfswriter写入前数据清理处理模式: append,写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突。 nonConflict,如果目录下有fileName前缀的文件,直接报错。 必选:是 默认值:无
- fieldDelimiter
描述:hdfswriter写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据 必选:是 默认值:无
- compress
描述:hdfs文件压缩类型,默认不填写意味着没有压缩。其中: text类型文件支持压缩类型有gzip、bzip2; orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。 必选:否 默认值:无压缩
- hadoopConfig
描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"hadoopConfig":{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2",
"dfs.namenode.rpc-address.aliDfs.namenode1": "",
"dfs.namenode.rpc-address.aliDfs.namenode2": "",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
- encoding
描述:写文件的编码配置。 必选:否 默认值:utf-8,慎重修改
- haveKerberos
描述:是否有Kerberos认证,默认false 例如如果用户配置true,则配置项kerberosKeytabFilePath,kerberosPrincipal为必填。 必选:haveKerberos 为true必选 默认值:false
- kerberosKeytabFilePath
描述:Kerberos认证 keytab文件路径,绝对路径 必选:否 默认值:无
- kerberosPrincipal
描述:Kerberos认证Principal名,如xxxx/hadoopclient@xxx.xxx 必选:haveKerberos 为true必选 默认值:无
"haveKerberos": true,
"kerberosKeytabFilePath": "/etc/security/keytabs/winner_hdp.keytab",
"kerberosPrincipal": "winner_hdp@WINNER.COM",