忘记过去,超越自己
- ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️
- ❤️ 本篇创建记录 2023-10-27 ❤️
- ❤️ 本篇更新记录 2023-10-27 ❤️
- 🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝
- 🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请留言轰炸哦!及时修正!感谢支持!
- 🔥 Arduino ESP8266教程累计帮助过超过1W+同学入门学习硬件网络编程,入选过选修课程,刊登过无线电杂志 🔥零基础从入门到熟悉Arduino平台下开发ESP8266,同时会涉及网络编程知识。专栏文章累计超过60篇,分为基础篇、网络篇、应用篇、高级篇,涵盖ESP8266大部分开发技巧。
快速导航
单片机菜鸟的博客快速索引(快速找到你要的)
如果觉得有用,麻烦点赞收藏,您的支持是博主创作的动力。
文章目录
- 1. 前言
- 2. Python脚本
1. 前言
博主在制作tft 自定义字库时,有个特别需求就是:
无脑复制了一堆中文汉字,然后需要挑选出不重复的汉字,然后再转成UniCode
所以,首先要解决的就是
挑选出不重复的汉字
直接在网上找到了一个Py脚本,特此分享记录一下。
2. Python脚本
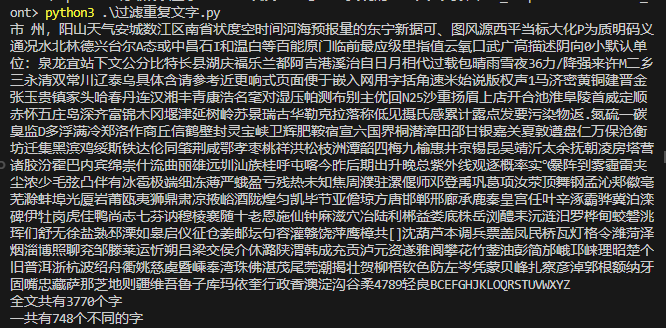
在这里插入图片描述
import re
# 打开文件
fr = open('./脚本使用.txt', 'r', encoding='UTF-8')
# 读取文件所有行
content = fr.readlines()
fr.close()
contentLines = ''
characers = []
stat = {}
# 依次迭代所有行
for line in content:
# 去除空格
line = line.strip()
if len(line) == 0:
continue
contentLines = contentLines + line
# print(line)
# 统计每一字出现的个数
for x in range(0, len(line)):
# 如果字符第一次出现 加入到字符数组中
if not line[x] in characers:
characers.append(line[x])
# 如果是字符第一次出现 加入到字典中
if line[x] not in stat:
stat[line[x]] = 1
# 出现次数加一
stat[line[x]] += 1
# 对字典进行倒数排序 从高到低 其中e表示dict.items()中的一个元素,
# e[1]则表示按 值排序如果把e[1]改成e[0],那么则是按键排序,
# reverse=False可以省略,默认为升序排列
stat = sorted(stat.items(), key=lambda e: e[1], reverse=True)
# 打印stat 每个字和其出现的次数 stat经过排序后变成二元组
# print(stat)
# for i in range(len(stat)):
# print(stat[i][0],stat[i][1])
str_data = ''
for i in stat:
str_data += i[0]
print(str_data)
print('全文共有%d个字' % len(contentLines))
print('一共有%d个不同的字' % len(characers))
with open('data.txt', 'w', encoding='utf-8') as f2: # 写入文件
# 写个头文件
f2.write(str_data)
直接执行这个脚本。

![[量化投资-学习笔记002]Python+TDengine从零开始搭建量化分析平台-MA均线的多种实现方式](https://img-blog.csdnimg.cn/c59daef6814d4bbdb578b15835a88c23.png#pic_center)