一、前言
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
-
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
二、环境安装
环境配置链接:训练ChatGLM2-6B创作广告 | 趋动云社区 - 文档中心
GPU平台:趋动云,目前感觉还不错的GPU云资源平台
ChatGLM2-6B:GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
总结了下环境安装步骤:
-
ChatGLM2-6B代码下载
-
预训练模型chatglm2-6b下载
-
ChatGLM2-6B代码的环境安装,进入代码目录,执行pip install -r requirements.txt
三、数据集准备
这里使用趋动云提供的AdvertiseGen数据集,dev.json格式如下:
{"content": "类型#上衣*版型#宽松*颜色#宝蓝色*风格#休闲*衣样式#卫衣", "summary": "适合装点春日的三色卫衣,通过把握色彩的饱和与明暗度,使其散发出暗藏的满满活力,柠檬黄、宝蓝色和紫外光,实用多样风格穿搭。而前襟处的英文字母点缀恰当,宽松的oversize版型更显洒脱,丰富从整体到细节的质感。在搭配舒适的面料,结合休闲与时髦理念,带来亲肤体验的同时也简洁大方。"} {"content": "类型#裙*颜色#纯色*风格#潮*图案#纯色*图案#刺绣*裙款式#抽褶", "summary": "衣身采取个性化的绣花点缀,增添时尚的韵味,让你举手投足间尽显妩媚的气息。自然的褶皱裙摆,极具潮流的味道,尽情演绎你专属的摩登气息。雅致的纯色系列,更好的为你勾勒出酷帅的气质。"} {"content": "类型#裙*版型#宽松*颜色#绿色*图案#线条*裙长#连衣裙*裙领型#圆领", "summary": "这款中长款式的连衣裙,经典的圆领设计,显得利落大方不失优雅,能够在穿着时增添女性的个人气质。精致的荷叶裙摆设计,让宽松的衣着轻松贴身,修饰腰部线条更添纤细之感。选用绿色调装饰,极具摩登时尚气。"}以下是目前开源的微调数据集。
| 数据集名称 | 规模 | 描述 |
|---|---|---|
| Stanford Alpaca | 52k | 斯坦福大学开源的 Alpaca 数据集,训练了 Alpaca 这类早期基于 LLaMA 的模型 |
| Stanford Alpaca (Chinese) | 51k | 使用 ChatGPT 翻译的 Alpaca 数据集 |
| GPT-4 Generated Data | 100k+ | 基于 GPT-4 的 self-instruction 数据集 |
| BELLE 2M | 2m | 包含约 200 万条由 BELLE 项目生成的中文指令数据 |
| BELLE 1M | 1m | 包含约 100 万条由 BELLE 项目生成的中文指令数据 |
| BELLE 0.5M | 500k | 包含约 50 万条由 BELLE 项目生成的中文指令数据 |
| BELLE Dialogue 0.4M | 400k | 包含约 40 万条由 BELLE 项目生成的个性化角色对话数据,包含角色介绍 |
| BELLE School Math 0.25M | 250k | 包含约 25 万条由 BELLE 项目生成的中文数学题数据,包含解题过程 |
| BELLE Multiturn Chat 0.8M | 800k | 包含约 80 万条由 BELLE 项目生成的用户与助手的多轮对话 |
| Guanaco Dataset | 100k+ | 包含日文、简繁体中文、英文等多类数据,数据集原用于 Guanaco 模型训练 |
| Firefly 1.1M | 1.1M | 中文对话大模型 firefly(流萤)的中文数据集,包含多个 NLP 任务 |
| CodeAlpaca 20k | 20k | 英文代码生成任务数据集 |
| Alpaca CoT | 6M | 用于微调的指令数据集集合 |
| Web QA | 36k | 百度知道汇集的中文问答数据集 |
| UltraChat | 1.57M | 清华 NLP 发布的大规模多轮对话数据集 |
注:BELLE 数据集是由 ChatGPT 产生的数据集,不保证数据准确性,所有类 GPT 模型产生的 self-instruction 数据集均不能保证其准确性。
四、模型加载
看了下显存,大概12G左右,用larger有点奢侈
ChatGLM2-6B代码目录如下:
-
ptuning:可以用来微调模型的文件夹
-
web_demo.py:实现网页访问chatglm
-
cli_demo.py:在命令行中进行交互式的对话
-
api.py:实现 OpenAI 格式的流式 API 部署
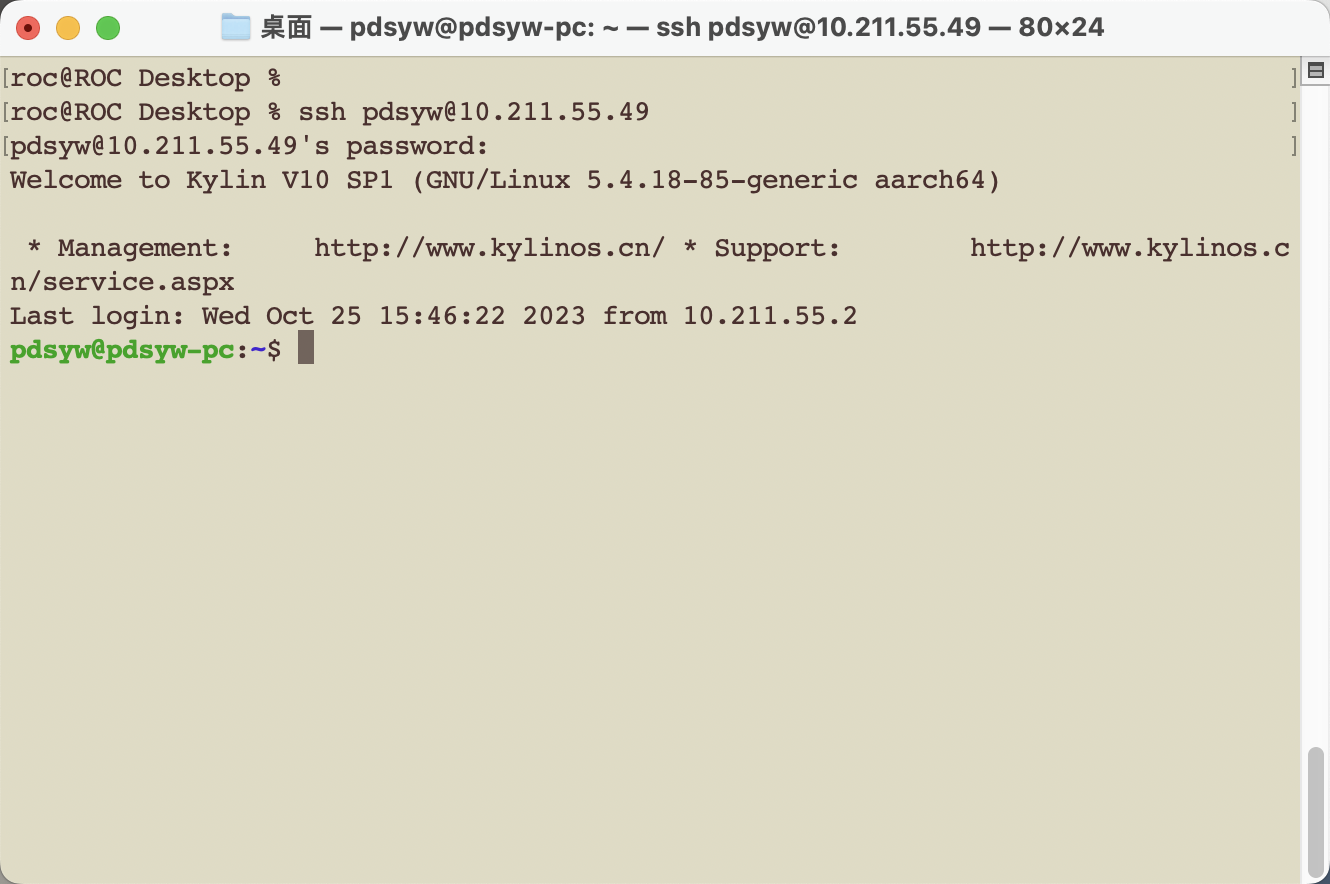
本文这里通过网页形式访问chatglm,在上述环境安装完成后,开始进入模型训练的过程,需要修改web_demo.py中的模型地址,即替换 THUDM/chatglm2-6b 为 /gemini/pretrain (模型实际挂载到环境的地址)。
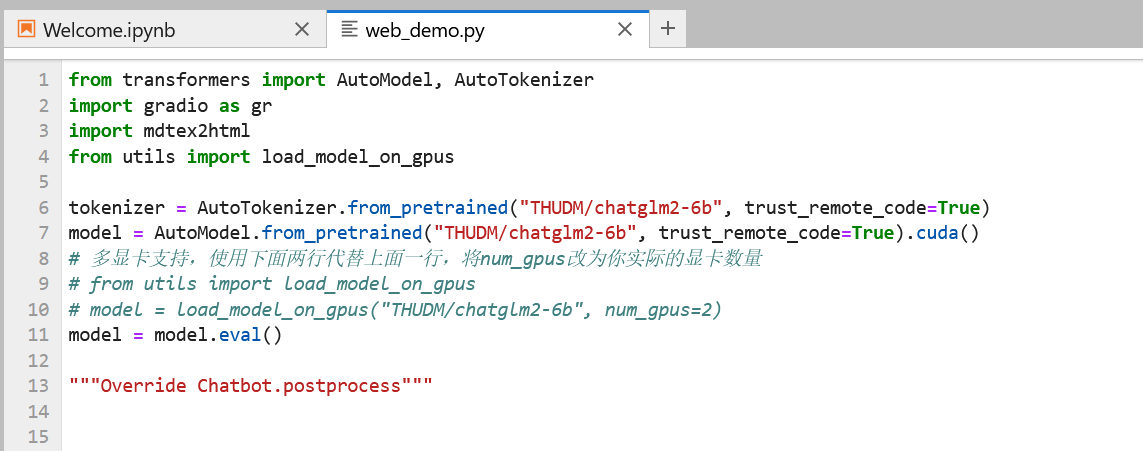
添加图片注释,不超过 140 字(可选)
因为借助趋动云平台来加载模型,想暴露在公网,需要对web_demo.py做些修改,如下:
公网访问某程序,需借助 frcp 进行内网穿透生成公网访问地址,因 frcp 需从国外源下载,可能存在下载失败的情况。此时可设置该程序本地运行,进而通过平台提供的 外部访问 地址进行访问。
-
在 web_demo.py 最后一行增加 server_name='0.0.0.0', server_port=xx 设置为本地运行该程序。形如:
demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0', server_port=77) 端口根据实际所填写的来
添加图片注释,不超过 140 字(可选)
2.等返回以下信息

添加图片注释,不超过 140 字(可选)
3.复制外部访问信息,并以 http 协议在浏览器中访问。

添加图片注释,不超过 140 字(可选)
4.网页界面如下:

添加图片注释,不超过 140 字(可选)
这些推理参数的意义:
-
temperature~:采样温度,[ 0.0,1.0 ]; 越大回答多样性越高;推荐0.95
-
top_p~: nucleus采样闽值,[ 0.0,1.0 ]; 越大回答多样性越高;推荐0.7
-
max length~:最大输出长度
temperature,top_p数值越小,随机性越小最优值对于不同任务或经过微调后可能发生变化
我的知乎:ChatGLM2-6B模型尝鲜 - 知乎