目录
一. 前言
二. 源码解析
2.1. 成员属性
2.2. 构造方法
2.3. 添加元素
2.4. 获取元素
2.5. 是否包含key
2.6. 删除元素
三. 总结
一. 前言
TreeMap 基于红黑树实现,这为 TreeMap 保持键的有序性打下了基础。总的来说,TreeMap 的核心是红黑树,TreeMap因为是通过红黑树实现,红黑树结构天然支持排序,默认情况下通过Key值的自然顺序进行排序。
Java TreeMap实现了SortedMap接口,也就是说会按照key的大小顺序对Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。
TreeSet和TreeMap在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说TreeSet里面有一个TreeMap(适配器模式)。
二. 源码解析

TreeMap底层通过红黑树(Red-Black tree)实现,有以下两个理由:
有序性:红黑树是一种二叉查找树,父节点的 key 大于左子节点的 key ,小于右子节点的 key 。这样,就完成了 TreeMap 的有序的特性。
高性能:红黑树会进行自平衡,避免树的高度过高,导致查找性能下滑。这样,红黑树能够提供 logN 的时间复杂度。
2.1. 成员属性
// 排序器
private final Comparator<? super K> comparator;
// 红黑树根节点
private transient Entry<K,V> root;
/**
* The number of entries in the tree
* key-value 键值对数量
*/
private transient int size = 0;
/**
* The number of structural modifications to the tree.
* 修改次数
*/
private transient int modCount = 0;root 属性,红黑树的根节点。其中,Entry 是 TreeMap 的内部静态类,代码如下:
/**
* 颜色 - 红色
*/
private static final boolean RED = false;
/**
* 颜色 - 黑色
*/
private static final boolean BLACK = true;
static final class Entry<K,V> implements Map.Entry<K,V> {
/**
* key 键
*/
K key;
/**
* value 值
*/
V value;
/**
* 左子节点
*/
Entry<K,V> left;
/**
* 右子节点
*/
Entry<K,V> right;
/**
* 父节点
*/
Entry<K,V> parent;
/**
* 颜色
*/
boolean color = BLACK;
}2.2. 构造方法
public TreeMap() {
comparator = null;
}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
// 添加所有元素
putAll(m);
}TreeMap():默认构造方法,不使用自定义排序,所以此时 comparator 为空。
TreeMap(Comparator<? super K> comparator):可传入 comparator 参数,自定义 key 的排序规则。
2.3. 添加元素
public V put(K key, V value) {
// 记录当前根节点
Entry<K,V> t = root;
// <1> 如果无根节点,则直接使用 key-value 键值对,创建根节点
if (t == null) {
// <1.1> 校验 key 类型。
compare(key, key); // type (and possibly null) check
// <1.2> 创建 Entry 节点
root = new Entry<>(key, value, null);
// <1.3> 设置 key-value 键值对的数量
size = 1;
// <1.4> 增加修改次数
modCount++;
return null;
}
// <2> 遍历红黑树
int cmp; // key 比父节点小还是大
Entry<K,V> parent; // 父节点
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) { // 如果有自定义 comparator ,则使用它来比较
do {
// <2.1> 记录新的父节点
parent = t;
// <2.2> 比较 key
cmp = cpr.compare(key, t.key);
// <2.3> 比 key 小,说明要遍历左子树
if (cmp < 0)
t = t.left;
// <2.4> 比 key 大,说明要遍历右子树
else if (cmp > 0)
t = t.right;
// <2.5> 说明,相等,说明要找到的 t 就是 key 对应的节点,直接设置 value 即可。
else
return t.setValue(value);
} while (t != null); // <2.6>
} else { // 如果没有自定义 comparator ,则使用 key 自身比较器来比较
if (key == null) // 如果 key 为空,则抛出异常
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
// <2.1> 记录新的父节点
parent = t;
// <2.2> 比较 key
cmp = k.compareTo(t.key);
// <2.3> 比 key 小,说明要遍历左子树
if (cmp < 0)
t = t.left;
// <2.4> 比 key 大,说明要遍历右子树
else if (cmp > 0)
t = t.right;
// <2.5> 说明,相等,说明要找到的 t 就是 key 对应的节点,直接设置 value 即可。
else
return t.setValue(value);
} while (t != null); // <2.6>
}
// <3> 创建 key-value 的 Entry 节点
Entry<K,V> e = new Entry<>(key, value, parent);
// 设置左右子树
if (cmp < 0) // <3.1>
parent.left = e;
else // <3.2>
parent.right = e;
// <3.3> 插入后,进行自平衡
fixAfterInsertion(e);
// <3.4> 设置 key-value 键值对的数量
size++;
// <3.5> 增加修改次数
modCount++;
return null;
}因为红黑树是二叉查找树,所以我们可以使用二分查找的方式遍历红黑树。循环遍历红黑树的节点,根据不同的结果,进行处理:
1. 如果当前节点比 key 小,则遍历左子树。
2. 如果当前节点比 key 大,则遍历右子树。
3. 如果当前节点比 key 相等,则直接设置该节点的 value 即可。
4. 如果遍历到叶子节点,无法满足上述情况,则说明我们需要给 key-value 键值对,创建 Entry 节点。如果比叶子节点小,则作为左子树;如果比叶子节点大,则作为右子树。
5. 如果无根节点,则直接使用 key-value 键值对,创建根节点。
public void putAll(Map<? extends K, ? extends V> map) {
// 给size赋值
int mapSize = map.size();
// 这里首先判断映射是不是有序的
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
// 获取有序映射的比较器
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
// 这里的判断一般是false,因为c = null
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map);
}因为 TreeMap 是基于树的结构实现,所以无需考虑扩容问题。
2.4. 获取元素
public V get(Object key) {
// 获得 key 对应的 Entry 节点
Entry<K,V> p = getEntry(key);
// 返回 value 值
return (p == null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) { // 不使用 comparator 查找
// Offload comparator-based version for sake of performance
// 如果自定义了 comparator 比较器,则基于 comparator 比较来查找
if (comparator != null)
return getEntryUsingComparator(key);
// 如果 key 为空,抛出异常
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
// 遍历红黑树
Entry<K,V> p = root;
while (p != null) {
// 比较值
int cmp = k.compareTo(p.key);
// 如果 key 小于当前节点,则遍历左子树
if (cmp < 0)
p = p.left;
// 如果 key 大于当前节点,则遍历右子树
else if (cmp > 0)
p = p.right;
// 如果 key 相等,则返回该节点
else
return p;
}
// 查找不到,返回 null
return null;
}
final Entry<K,V> getEntryUsingComparator(Object key) { // 使用 comparator 查找
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
// 遍历红黑树
Entry<K,V> p = root;
while (p != null) {
// 比较值
int cmp = cpr.compare(k, p.key);
// 如果 key 小于当前节点,则遍历左子树
if (cmp < 0)
p = p.left;
// 如果 key 大于当前节点,则遍历右子树
else if (cmp > 0)
p = p.right;
// 如果 key 相等,则返回该节点
else
return p;
}
}
// 查找不到,返回 null
return null;
}如果未自定义 comparator 比较器,则调用 #getEntry(Object key) 方法,使用 key 自身的排序,进行比较二分查找。
如果有自定义 comparator 比较器,则调用 #getEntryUsingComparator(Object key) 方法,使用 comparator 的排序,进行比较二分查找。
2.5. 是否包含key
public boolean containsKey(Object key) {
return getEntry(key) != null;
}2.6. 删除元素
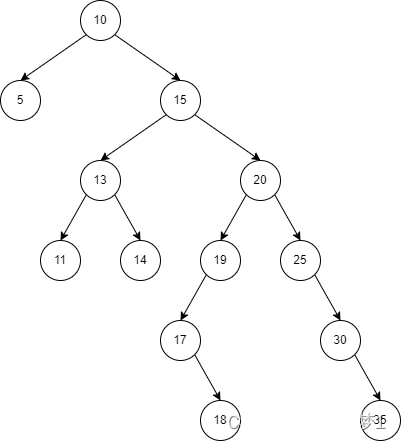
情况一,无子节点:直接删除父节点对其的指向即可。
例如说,叶子节点 5、11、14、18 。
情况二,只有左子节点:将删除节点的父节点,指向删除节点的左子节点。
例如说,节点 20 。可以通过将节点 15 的右子节点指向节点 19 。
情况三,只有右子节点:和情况二的处理方式一致。将删除节点的父节点,指向删除节点的右子节点。
例如说,节点 25。
情况四,有左子节点 + 右子节点。
这种情况,相对会比较复杂,因为无法使用子节点替换掉删除的节点。所以此时有一个巧妙的思路。我们结合删除节点 15 来举例。
1、先查找节点 15 的右子树的最小值,找到是节点 17 。
2、将节点 17 设置到节点 15 上。因为节点 17 是右子树的最小值,能够满足比节点 15 的左子树都大,右子树都小。这样,问题就可以变成删除节点 17 。
3、删除节点 17 的过程,满足情况三。将节点 19 的左子节点指向节点 18 即可。
public V remove(Object key) {
// <1> 获得 key 对应的 Entry 节点
Entry<K,V> p = getEntry(key);
// <2> 如果不存在,则返回 null ,无需删除
if (p == null)
return null;
V oldValue = p.value;
// <3> 删除节点
deleteEntry(p);
return oldValue;
}<1> 处,调用 #getEntry(Object key) 方法,获得 key 对应的 Entry 节点。
<2> 处,如果不存在,则返回 null ,无需删除。
<3> 处,调用 #deleteEntry(Entry<K,V> p) 方法,删除该节点。
private void deleteEntry(Entry<K,V> p) {
// 增加修改次数
modCount++;
// 减少 key-value 键值对数
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
// <1> 如果删除的节点 p 既有左子节点,又有右子节点,
if (p.left != null && p.right != null) {
// <1.1> 获得右子树的最小值
Entry<K,V> s = successor(p);
// <1.2> 修改 p 的 key-value 为 s 的 key-value 键值对
p.key = s.key;
p.value = s.value;
// <1.3> 设置 p 指向 s 。此时,就变成删除 s 节点了。
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
// <2> 获得替换节点
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
// <3> 有子节点的情况
if (replacement != null) {
// Link replacement to parent
// <3.1> 替换节点的父节点,指向 p 的父节点
replacement.parent = p.parent;
// <3.2.1> 如果 p 的父节点为空,则说明 p 是根节点,直接 root 设置为替换节点
if (p.parent == null)
root = replacement;
// <3.2.2> 如果 p 是父节点的左子节点,则 p 的父子节的左子节指向替换节点
else if (p == p.parent.left)
p.parent.left = replacement;
// <3.2.3> 如果 p 是父节点的右子节点,则 p 的父子节的右子节指向替换节点
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
// <3.3> 置空 p 的所有指向
p.left = p.right = p.parent = null;
// Fix replacement
// <3.4> 如果 p 的颜色是黑色,则执行自平衡
if (p.color == BLACK)
fixAfterDeletion(replacement);
// <4> 如果 p 没有父节点,说明删除的是根节点,直接置空 root 即可
} else if (p.parent == null) { // return if we are the only node.
root = null;
// <5> 如果删除的没有左子树,又没有右子树
} else { // No children. Use self as phantom replacement and unlink.
// <5.1> 如果 p 的颜色是黑色,则执行自平衡
if (p.color == BLACK)
fixAfterDeletion(p);
// <5.2> 删除 p 和其父节点的相互指向
if (p.parent != null) {
// 如果 p 是父节点的左子节点,则置空父节点的左子节点
if (p == p.parent.left)
p.parent.left = null;
// 如果 p 是父节点的右子节点,则置空父节点的右子节点
else if (p == p.parent.right)
p.parent.right = null;
// 置空 p 对父节点的指向
p.parent = null;
}
}
}<1> 处,如果删除的节点 p 既有左子节点,又有右子节点,则符合我们提到的情况四。在这里,我们需要将其转换成情况三。
<1.1> 处,调用 #successor(Entry<K,V> t) 方法,获得右子树的最小值。这里,我们先不深究 #successor(Entry<K,V> t) 方法的具体代码,知道在这里的用途即可。
<1.2> 处,修改 p 的 key-value 为 s 的 key-value 键值对。这样,我们就完成 s 对 p 的替换。
<1.3> 处,设置 p 指向 s 。此时,就变成删除 s 节点了。此时,情况四就转换成了情况三了。
<2> 处,获得替换节点。此时对于 p 来说,至多有一个子节点,要么左子节点,要么右子节点,要么没有子节点。
<3> 处,有左子节点,或者右子节点的情况:
3.1 处,替换节点的父节点,指向 p 的父节点。
3.2.1> + 3.2.2> + 3.2.3> 处,将 p 的父节点的子节点,指向替换节点。
3.3> 处, 置空 p 的所有指向。
3.4> 处,如果 p 的颜色是黑色,则调用 #fixAfterDeletion(Entry<K,V> x) 方法,执行自平衡。
<4> 处,如果 p 没有父节点,说明删除的是根节点,直接置空 root 即可。
<5> 处,既没有左子树,又没有右子树的情况:
<5.1> 处,如果 p 的颜色是黑色,则调用 #fixAfterDeletion(Entry<K,V> x) 方法,执行自平衡。
<5.2> 处,删除 p 和其父节点的相互指向。
在前面,我们漏了一个 #successor(Entry<K,V> t) 静态方法,没有详细来看。获得 t 节点的后继节点,代码如下:
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
// <1> 如果 t 为空,则返回 null
if (t == null)
return null;
// <2> 如果 t 的右子树非空,则取右子树的最小值
else if (t.right != null) {
// 先取右子树的根节点
Entry<K,V> p = t.right;
// 再取该根节点的做子树的最小值,即不断遍历左节点
while (p.left != null)
p = p.left;
// 返回
return p;
// <3> 如果 t 的右子树为空
} else {
// 先获得 t 的父节点
Entry<K,V> p = t.parent;
// 不断向上遍历父节点,直到子节点 ch 不是父节点 p 的右子节点
Entry<K,V> ch = t;
while (p != null // 还有父节点
&& ch == p.right) { // 继续遍历的条件,必须是子节点 ch 是父节点 p 的右子节点
ch = p;
p = p.parent;
}
return p;
}
}对于树来说,会存在前序遍历,中序遍历,后续遍历。对于二叉查找树来说,中序遍历恰好满足 key 顺序递增。所以,这个方法是基于中序遍历的方式,寻找传入 t 节点的后续节点,也是下一个比 t 大的节点。
<1> 处,如果 t 为空,则返回 null 。
<2> 处,如果 t 有右子树,则右子树的最小值,肯定是它的后继节点。在 #deleteEntry(Entry<K,V> p) 方法的 <1.1> 处,就走了这块代码分支逻辑。
<3> 处,如果 t 没有右子树,则需要向上遍历父节点结合 图 来理解。
简单来说,寻找第一个祖先节点 p 是其父节点的左子节点。因为是中序遍历,该节点的左子树肯定已经遍历完,在没有右子节点的情况下,需要找到其所在的“大子树”,成为左子树的情况。
例如说,节点 14 来说,需要按照 14 -> 13 -> 15 的路径,从而找到节点 15 是其后继节点。
三. 总结
TreeMap 按照 key 的顺序的 Map 实现类,底层采用红黑树来实现存储。
TreeMap 因为采用树结构,所以无需初始考虑像 HashMap 考虑容量问题,也不存在扩容问题。
TreeMap 的 key 不允许为空( null ),可能是因为红黑树是一颗二叉查找树,需要对 key 进行排序。
相比 HashMap 来说,TreeMap 不仅仅支持指定 key 的查找,也支持 key 范围的查找。当然,这也得益于 TreeMap 数据结构能够提供的有序特性。