目录
一、下载MNIST-demo的cpp、python版本代码
二、五分钟读懂pytorch代码
三、下载MNIST数据集、训练模型
四、模型序列化、可视化分析
本文借用mnist这个相对简易深度学习任务来开始讲解libtorch如何部署模型。因此,这是一个如何编写libtorch代码的实战教程。
一、下载MNIST-demo的cpp、python版本代码
进入链接:https://github.com/pytorch 如下图:打开example
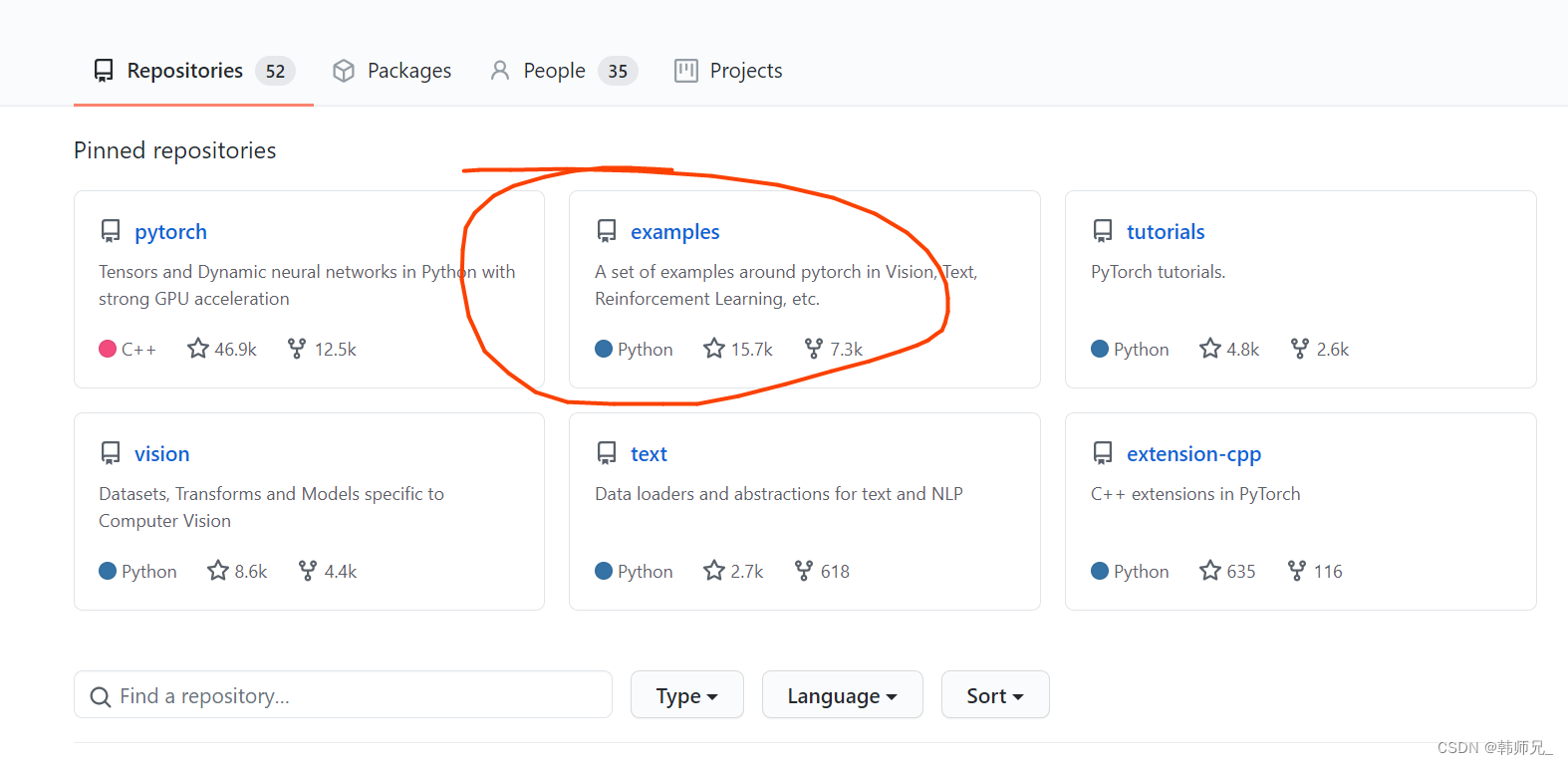
将上述example下的code下到本地,在根目录可以看到mnist的python版本:main.py;打开cpp/mnist,可以看到mnist的c++版本(libtorch实现的):mnist.cpp。以上两个代码文件下文会用到。
mnist是一个手写数字识别的demo,如下图,快速了解下原理。

二、五分钟读懂pytorch代码
读透上述python版代码。打开main.py,我们知道,输入图片大小为28*28。下面是整个MNISTpython官方代码的解读,是训练代码,需要下载数据集,已经很详细注释。如下图,执行之
后会自动下载手写数字数据,然后开始训练。(torch1.13.1)
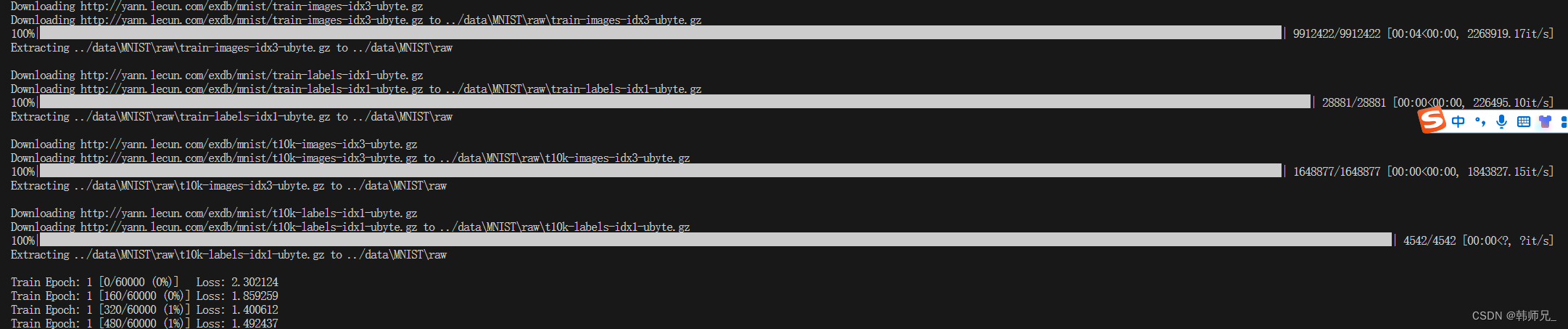
注:如果你不能自动下载数据集,请看第三章。
main.py:
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
class Net(nn.Module):
def __init__(self): # self指的是类实例对象本身(注意:不是类本身)。
# self不是关键词
# super 用于继承,https://www.runoob.com/python/python-func-super.html
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# input:28*28
x = self.conv1(x) # -> (28 - 3 + 1 = 26),26*26*32
x = F.relu(x)
# input:26*26*32
x = self.conv2(x) # -> (26 - 3 + 1 = 24),24*24*64
# input:24*24*64
x = F.relu(x)
x = F.max_pool2d(x, 2)# -> 12*12*64 = 9216
x = self.dropout1(x) #不改变维度
x = torch.flatten(x, 1) # 9216*1
# w = 128*9216
x = self.fc1(x) # -> 128*1
x = F.relu(x)
x = self.dropout2(x)
# w = 10*128
x = self.fc2(x) # -> 10*1
output = F.log_softmax(x, dim=1) # softmax归一化
return output
def train(args, model, device, train_loader, optimizer, epoch):
# 在使用pytorch构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),
# 作用是启用batch normalization和drop out。
# 测试过程中会使用model.eval(),这时神经网络会沿用batch normalization的值,并不使用drop out。
model.train()
# 可以查看下卷积核的参数尺寸
#model.conv1.weight.shape torch.Size([32, 1, 3, 3] 即:32个2D卷积核
#model.conv2.weight.shape torch.Size([64, 32, 3, 3]) 即:64个3D卷积核
for batch_idx, (data, target) in enumerate(train_loader):
# train_loader.dataset.data.shape
# Out[9]: torch.Size([60000, 28, 28])
# batch_size:64
# data:64个样本输入,torch.Size([64, 1, 28, 28])
# target: 64个label,torch.Size([64])
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# output:torch.Size([64, 10])
output = model(data)
# 类似于交叉熵
# reference: https://blog.csdn.net/qq_22210253/article/details/85229988
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# 我们打印一个卷积核参数看看
# print(model.conv2._parameters)
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=16, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=2, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True, # 锁页内存,可以加快内存到显存的速度
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
# torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起
#
transform = transforms.Compose([
transforms.ToTensor(), # (H x W x C)、[0, 255] -> (C x H x W)、[0.0, 1.0]
transforms.Normalize((0.1307,), (0.3081,)) # 数据的归一化
])
dataset1 = datasets.MNIST('data', train=True, download=False,
transform=transform)
dataset2 = datasets.MNIST('data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
# 固定步长衰减
# reference: https://zhuanlan.zhihu.com/p/93624972
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
#torch.save(model.state_dict(), "pytorch_mnist.pt")
torch.save(model, "pytorch_mnist.pth")
if __name__ == '__main__':
main()三、下载MNIST数据集、训练模型
如何下载数据集:网上一堆教程,似乎没有什么用,讲道理是pytorch底层自动取固定网站下载,并在本地新建文件夹,存在如下如data相对路径,
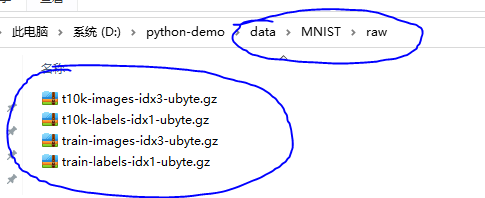
我翻看底层,下个数据,xxx还要校验MD5码,简直有X。也就是说你通过下载别人分享的压缩包,pytorch是不能加载的,我x!不过后来我找到了.pt格式的数据集,原来pytorch读取压缩包.gz格式的数据后,再将其转为.pt格式的文件,存在processed文件夹中,如下图:
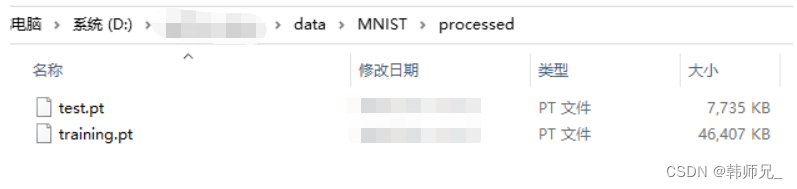
下载连接:https://github.com/MorvanZhou/PyTorch-Tutorial/tree/master/tutorial-contents-notebooks/mnist/processed
下载之后放到上述processed文件夹中就行,原始压缩包格式的数据集就不用管了,.pt格式的数据是可以拷贝共享给别人的。最终工程目录如下图:
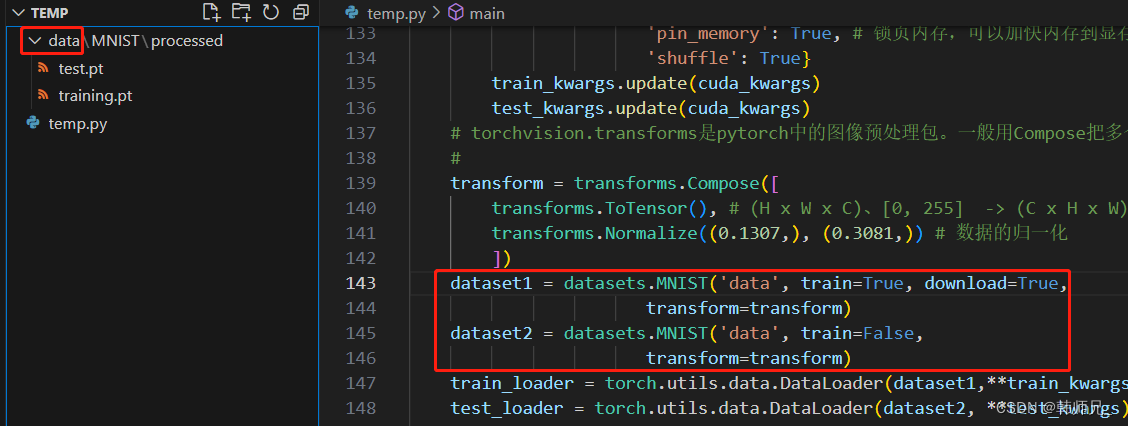
运行main.py,执行python代码训练、保存模型文件pytorch_mnist.pth,测试打印信息如下:
......
184 Train Epoch: 2 [54400/60000 (91%)] Loss: 0.003272
185 Train Epoch: 2 [55040/60000 (92%)] Loss: 0.236524
186 Train Epoch: 2 [55680/60000 (93%)] Loss: 0.087931
187 Train Epoch: 2 [56320/60000 (94%)] Loss: 0.013646
188 Train Epoch: 2 [56960/60000 (95%)] Loss: 0.027721
189 Train Epoch: 2 [57600/60000 (96%)] Loss: 0.100714
190 Train Epoch: 2 [58240/60000 (97%)] Loss: 0.155445
191 Train Epoch: 2 [58880/60000 (98%)] Loss: 0.113110
192 Train Epoch: 2 [59520/60000 (99%)] Loss: 0.039872
193
194 Test set: Average loss: 0.0398, Accuracy: 9864/10000 (99%)这里再给一个在pytorch、python-opencv环境中的模型测试代码。代码中读取上述训练保存的模型文件,然后推理图像,图像下面随便给了两个小图。
示例图:
![]()
![]()
infer.py
from main import Net
from torchvision import datasets, transforms
from PIL import Image
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('pytorch_mnist.pth') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("9.jpg", 0) # 读取要预测的灰度图片
cv2.imshow("img", img)
cv2.waitKey(100)
img = Image.fromarray(img)
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
img = trans(img)
img = img.unsqueeze(0) # 图片扩展多一维,[batch_size,通道,长,宽],此时batch_size=1
img = img.to(device)
output = model(img)
pred = output.max(1, keepdim=True)[1]
pred = torch.squeeze(pred)
print('检测结果为:%d' % (pred.cpu().numpy()))四、模型序列化、可视化分析
基于上述工作,我们已经得到.pt格式的模型文件,想要在libtorch中加载模型,还要做的工作就是模型序列化,以下是python环境中序列化代码,注:需要读入一张图,最后将.pth格式文件转为.pt格式文件。
import torch
import cv2
import torch.nn.functional as F
from main import Net
from torchvision import datasets, transforms
from PIL import Image
if __name__ == '__main__':
device = torch.device('cpu') # 使用cpu进行推理
model = torch.load('pytorch_mnist.pth') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("9.jpg", 0) # 读取要预测的灰度图片
img = Image.fromarray(img)
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
img = trans(img)
img = img.unsqueeze(0) # 图片扩展多一维,[batch_size,通道,长,宽]
img = img.to(device)
traced_net = torch.jit.trace(model, img)
traced_net.save("pytorch_mnist.pt")
print("模型序列化导出成功")生成的.pt格式文件将会部署到libtorch环境中使用,下一节详细讲解。这里最后我们利用链接:https://netron.app/的工具,将上述序列化后的模型文件(即:pytorch_mnist.pt),进行可视化,如图(这里再将上述网络定义代码贴一遍,方便对比):
class Net(nn.Module):
def __init__(self): # self指的是类实例对象本身(注意:不是类本身)。
# self不是关键词
# super 用于继承,https://www.runoob.com/python/python-func-super.html
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# input:28*28
x = self.conv1(x) # -> (28 - 3 + 1 = 26),26*26*32
x = F.relu(x)
# input:26*26*32
x = self.conv2(x) # -> (26 - 3 + 1 = 24),24*24*64
# input:24*24*64
x = F.relu(x)
x = F.max_pool2d(x, 2)# -> 12*12*64 = 9216
x = self.dropout1(x) #不改变维度
x = torch.flatten(x, 1) # 9216*1
# w = 128*9216
x = self.fc1(x) # -> 128*1
x = F.relu(x)
x = self.dropout2(x)
# w = 10*128
x = self.fc2(x) # -> 10*1
output = F.log_softmax(x, dim=1) # softmax归一化
return output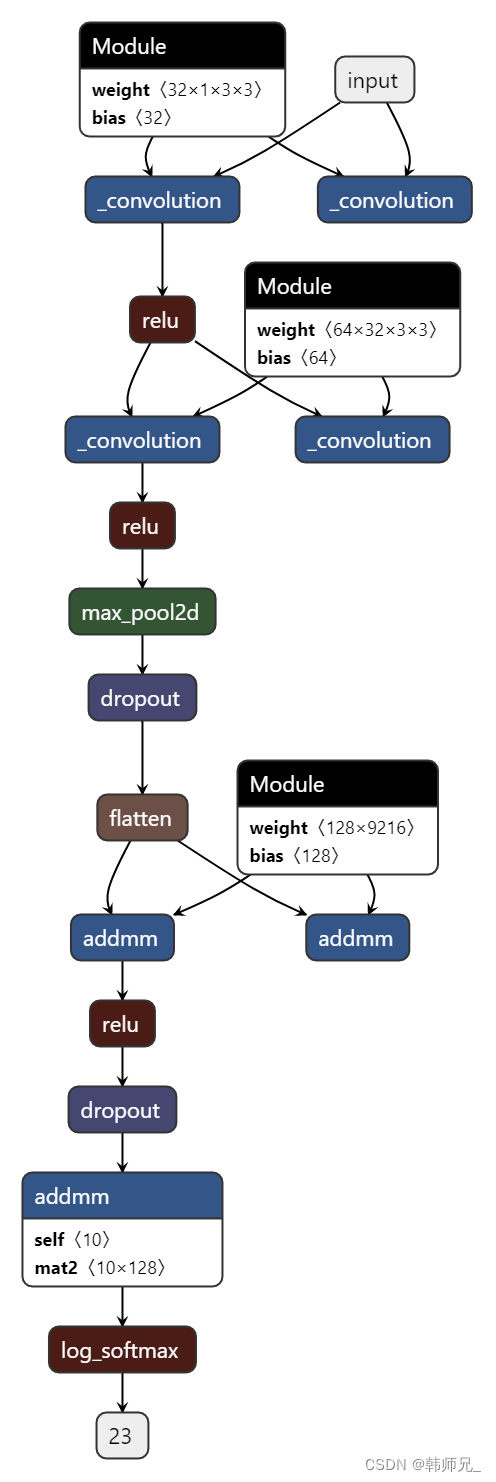


![2023年中国消防报警设备市场规模现状及行业竞争趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/c0a84172029f905adf5591eb345326be.png)