Instant-NGP的出现,无疑给神经表达领域带来了新的生命力。可认为是NeRF诞生以来的关键里程碑了。首次让我们看到了秒级的重建、毫秒级的渲染的NeRF工作。
作为如此顶到爆的工作,Instant-NGP毫无疑问斩获SIGGRAPH 2022的最佳论文。虽然只是五篇最佳论文之一,但就目前的引用量看来,飙升到1000+引用量的Instant-NGP更像是the best of the best。夸归夸,我们研究一下Instant-NGP为何能让包括NeRF在内的四个神经表示任务都达到SOTA呢?
关键在于:多分辨率哈希编码。哈希编码是一种位置编码,在神经隐式表达任务中,由于神经网络天然对尾数不敏感,会导致表达结果的高频信息丢失,引发“过平滑”的问题。于是位置编码显得尤为重要,在NeRF中,采用频率位置编码。但频率位置编码的大问题就是不够紧凑。空间坐标本来是紧凑表示,但频率编码以后,会变得疏散。这种疏散的位置表示有两个问题:1,需要更大的神经网络去拟合;2,需要训练更多的轮数才能收敛。这两者都直接导致了NeRF训练和推理都很慢。于是,一种紧凑、通用的编码方式开始被研究者们寻找,包括参数编码和稀疏参数编码系列的编码方式,但要么就是通用性不够好,要么就是并行度不够高,总达不到理想的编码效果。而多分辨率哈希编码的诞生,解决了以上的问题。
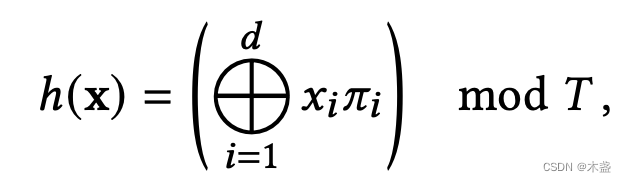
先理解这个公式:假如我输入的坐标是
x
=
(
8
,
6
,
7
)
\bold{x}=(8,6,7)
x=(8,6,7),有一组包含1的质数集
π
=
(
1
,
2654435761
,
805459861
)
\bold{\pi}=(1, 2654435761, 805459861)
π=(1,2654435761,805459861),质数集的维度与坐标维度一致即可。这里圆圈中间有个加号的符号就是“异或”计算,这是一种位运算:相同为0,不同为1。
m
o
d
mod
mod表示模除,即取余数。T表示哈希表的容量,典型值为
2
19
2^{19}
219。
这个公式的输出结果依然是一个整数,表达为一个索引值(即哈希值)。这个索引值可以直接在具体的哈希表上查找内容。将一个坐标化成一个索引值,相邻的坐标的哈希值会有明显的差异。
我们先看看哈希编码是怎么一回事儿:
import torch
def hash_computing(coords, log2_hashmap_size=19):
'''
coords: this function can process upto 7 dim coordinates
log2T: logarithm of T w.r.t 2
'''
primes = [1, 2654435761, 805459861, 3674653429, 2097192037, 1434869437, 2165219737]
xor_result = torch.zeros_like(coords)[..., 0]
for i in range(coords.shape[-1]): # 3
xor_result ^= coords[..., i] * primes[i]
return torch.tensor((1 << log2_hashmap_size) - 1).to(xor_result.device) & xor_result
if __name__ == "__main__":
x = torch.Tensor([[8, 3, 3], [8, 3, 4]]).int()
y = hash_computing(x)
print(y)
我们输入了两个相邻坐标(8,3,3)和(8,3,4),得到的哈希值分别为93092和471887。
我们看看哈希的定义:哈希算法是一种将任意长度的数据转换为固定长度值的算法。哈希算法天然就是一种紧凑表示。
未完待写…