Introduction
阅读某一特定主题的一本书不会使你成为专家,阅读多本包含相似内容的书也不会。真正掌握一项技能或领域的知识需要来自多样化信息源的大量信息。
这对于自动驾驶和其他人工智能技术同样适用。
负责自动驾驶功能的深度神经网络需要经过详尽的训练,不仅要在日常行程中可能遇到的情况下,还要在希望它们永远不会遇到的异常情况下进行训练。成功的关键在于确保它们受到了正确数据的训练。
什么是正确的数据呢?那些新颖或不确定的情境,而不是反复出现相同的场景。
主动学习是一种机器学习的训练数据选择方法,它可以自动找到这种多样化的数据。它可以在人类花费大量时间筛选数据的情况下,在短时间内构建更好的数据集。
它的工作原理是利用已训练好的模型来浏览收集到的数据,标记出模型难以识别的帧。然后,这些帧由人类进行标记,然后添加到训练数据中。这提高了模型在识别恶劣条件下的物体等情况下的准确性。
(From Chat-gpt)
Orin In English:
Reading one book on a particular subject won’t make you an expert. Nor will reading multiple books containing similar material. Truly mastering a skill or area of knowledge requires lots of information coming from a diversity of sources.
The same is true for autonomous driving and other AI-powered technologies.
The deep neural networks responsible for self-driving functions require exhaustive training. Both in situations they’re likely to encounter during daily trips, as well as unusual ones they’ll hopefully never come across. The key to success is making sure they’re trained on the right data.
What’s the right data? Situations that are new or uncertain. No repeating the same scenarios over and over.
Active learning is a training data selection method for machine learning that automatically finds this diverse data. It builds better datasets in a fraction of the time it would take for humans to curate.
It works by employing a trained model to go through collected data, flagging frames it’s having trouble recognizing. These frames are then labeled by humans. Then they’re added to the training data. This increases the model’s accuracy for situations like perceiving objects in tough conditions.
For Autonomous Driving
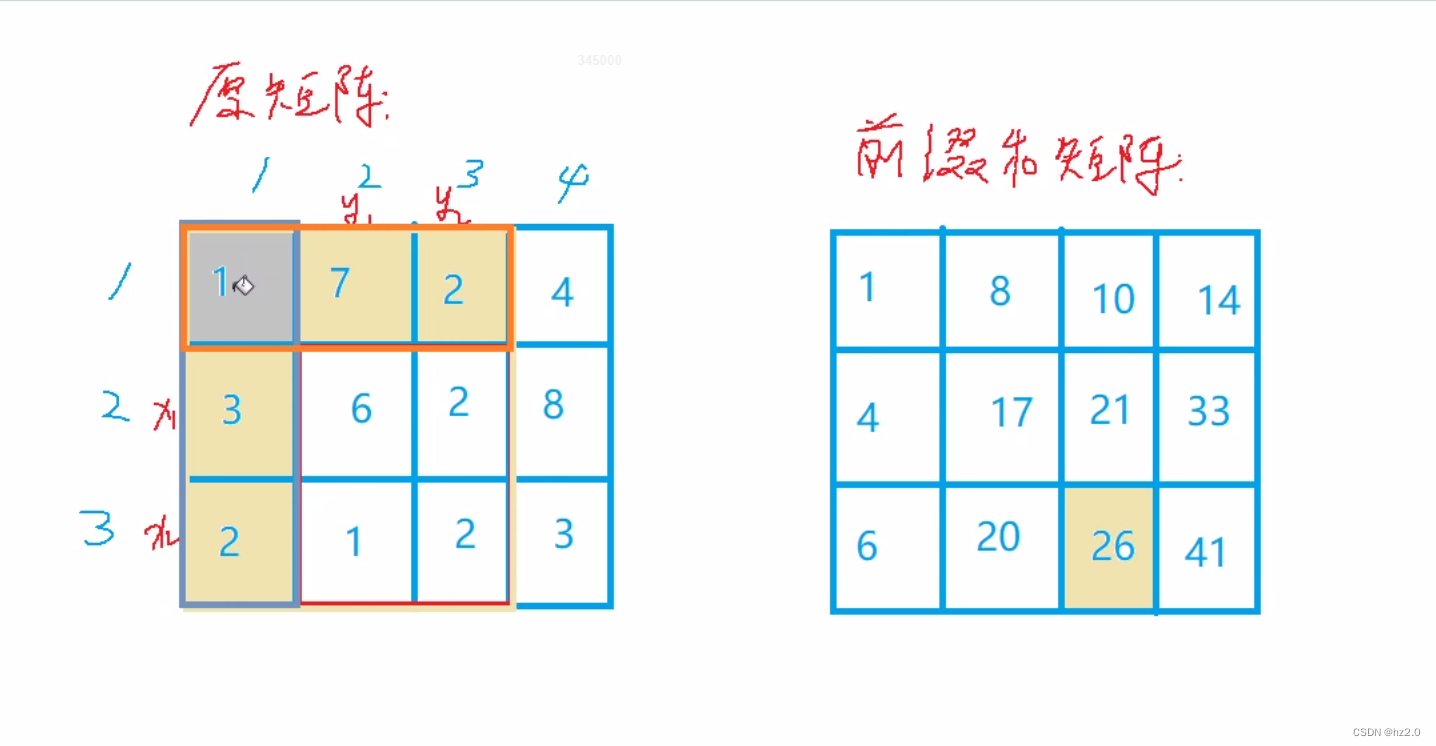
针对自动驾驶来说,成熟的量产方案需要的数据是海量的。兰德公司的研究表明,自动驾驶技术需要110 亿公里的数据才可以表现的比人类驾驶好20%。那换算一下,需要100量数采车一颗不停地跑500年,才可以拿到这些数据。
相应的,如果要将这些数据都进行标注,那么即使这100辆车每天只跑8小时的数据,也需要1百万的标注员去对这些数据进行处理。
所以这是对自动驾驶是一个巨大的挑战,而解决这个问题的一个方法就是使用active learning的范式去处理数据。
在具体介绍active learning如何作用前,可以回溯下我们常用的选择数据的方式。
1.随机采样(我们的项目初期就是这样做的):获取了大部分的常规场景,但大概率会遗漏一些corner case,所以才会导致测试过程中出现各种ISSUE。
2.基于metadata(gps,weather,time,特有采集。在进入数据迭代后, 我们的项目也是这样做的。)的采样(解决相对常见的corner case):比如交通灯来说,可以按照需求去采集黄灯;对车辆来说,可以去施工区域附近采集”大车“;对车道线来说,可以根据gps信息,均匀送标上海的大部分路段的数据等等方法。这种方法确实能解决80%甚至90%的corner case。但剩下的10%也许才是产品竞争力的体现。比如下图中不装货物的挂车、站在高跷上的人,拖车等,就不是这样的方法可以解决的。


3.基于人工的采样(项目攻关、解决特定问题时常用的方法):标注人员(如果没有自有团队,那这就需要专业的研发人员亲自下场了)根据一定的规则,在阅览一帧帧的数据后,挑选出和问题场景相同的数据。这个的成本、时间、收益就是一个不易衡量的值了。但在一些特定场景,比如需要通过E-NCAP(www.euroncap.com)时, 是可以做到事半功倍的。
active learning / passive learning Example from Nvidia
走进active learning
这里先推荐一本书:Active Learning Literature Survey 作者 Burr Settles,虽然出版年份较早(2012),但基本上是这个领域最经典的一份综述,后续很多的科技软文大部分的内容和插图都来自这篇著作,感兴趣的小伙伴,可以自行深入阅读。本篇后续的介绍也会借鉴这篇著作的内容。
[active learning literature survey.pdf]
监督学习(我们项目的训模型目前都是属于监督学习)问题中,存在标记成本较为昂贵且标记难以大量获取的问题。 针对一些特定任务,只有行业专家才能为样本做上准确标记。在此问题背景下,主动学习(Active Learning, AL)尝试通过选择性的标记较少数据而训练出表现较好的模型。
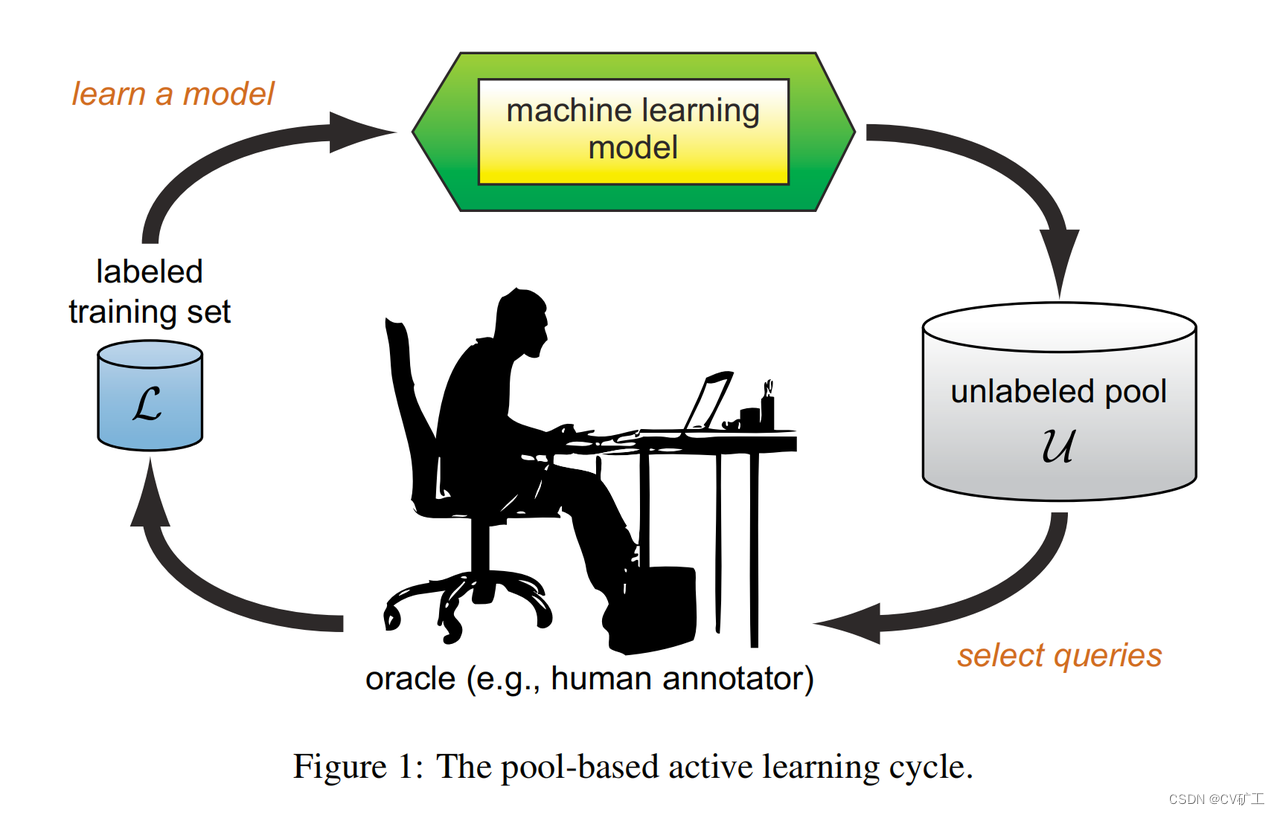
下面是从 Burr 的 Survey 中选取的例子。
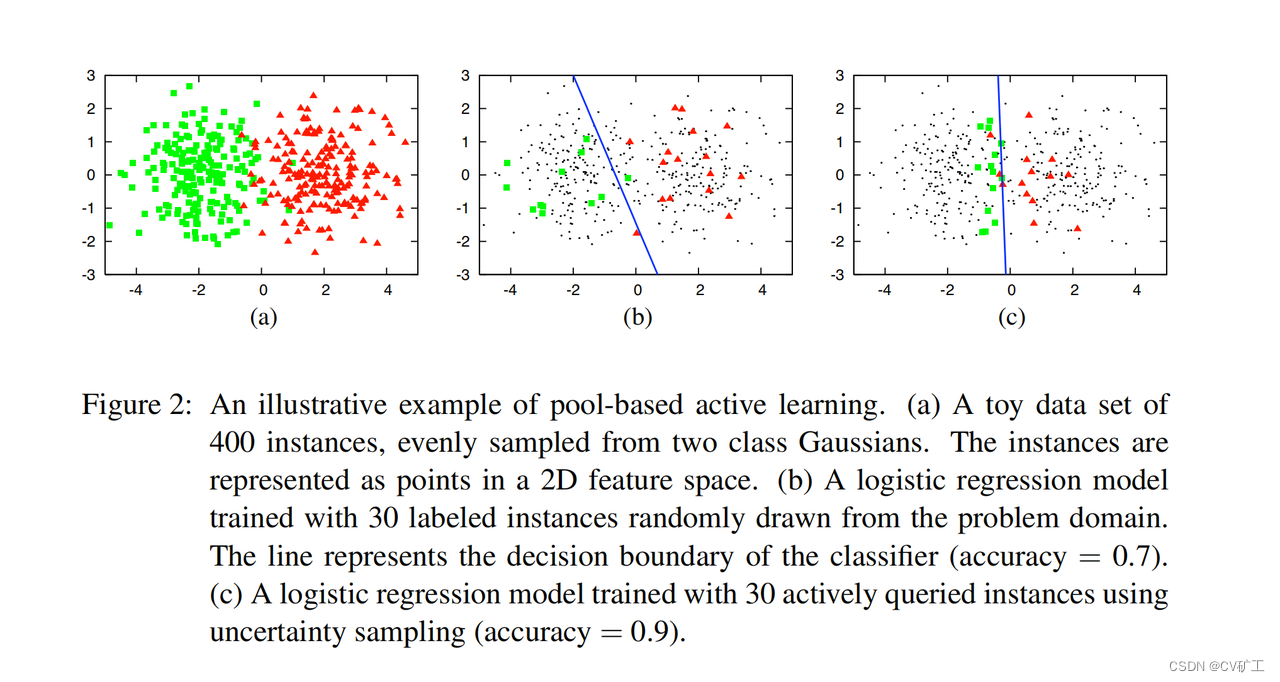
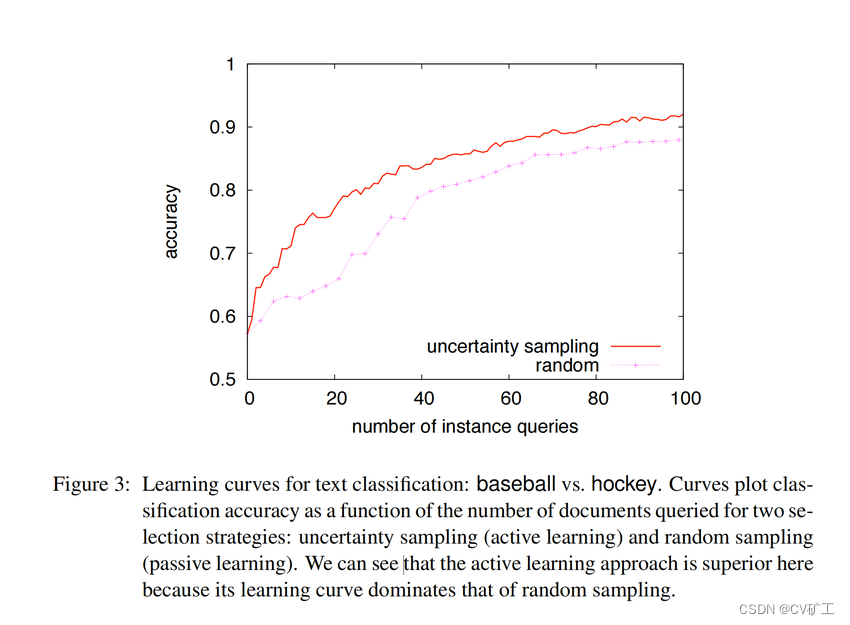
Query Strategy Frameworks
只简单介绍一些已经有成熟库的query方法,主要参考:
repo:https://github.com/modAL-python/modAL
DOC: https://modal-python.readthedocs.io/en/latest/content/overview/modAL-in-a-nutshell.html
对我们的业务来说,目的是获取可以提升我们模型效果的数据即可,整个Frame框架借用数据平台的workflow即可快速搭建。欠缺的刚好就是如何去发现needed数据的方法。而这些方法也刚好就是各种active learning方案的核心,也就是如何query,所以后续我们着重介绍下成熟的常见query方法。
当然复杂的也有很多,比如:
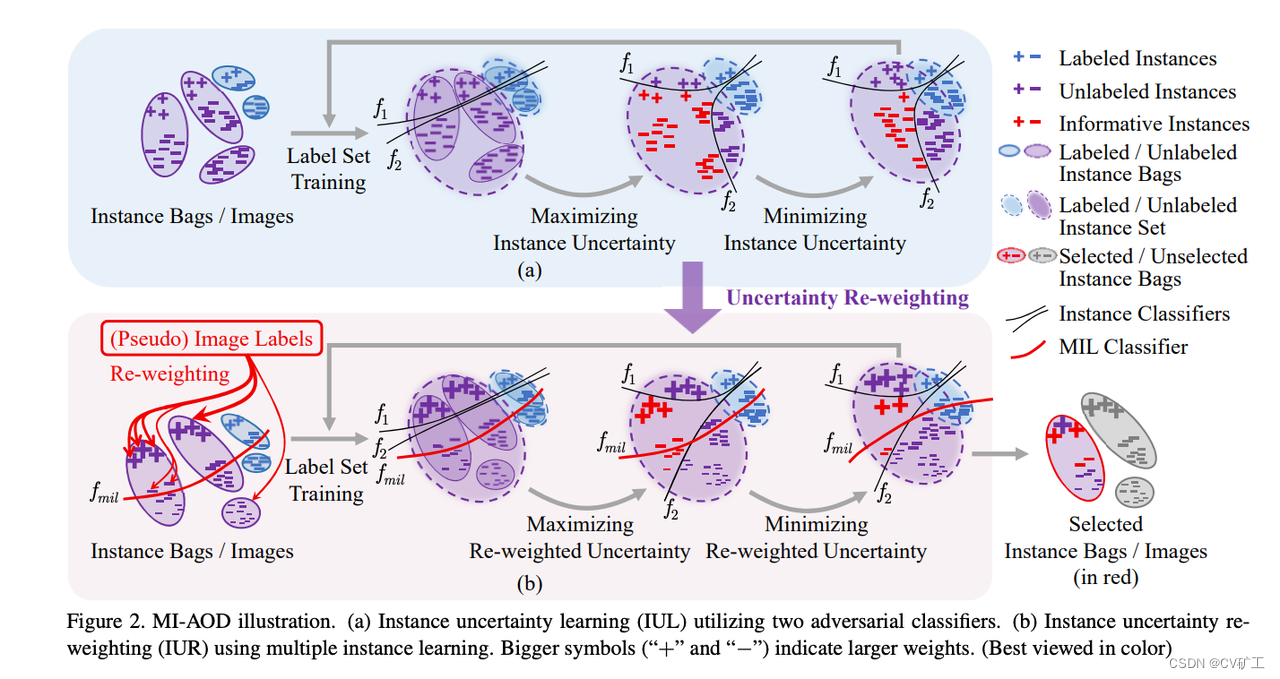
from Multiple instance active learning for object detection (CVPR202),感兴趣的同学可以自行学习。
Uncertainty sampling
When you present unlabelled examples to an active learner, it finds you the most useful example and presents it for you to be labelled. This is done by first calculating the usefulness of prediction (whatever it means) for each example and select an instance based on the usefulness. The thing is, there are several ways to measure this. They are based upon classification uncertainty, hence they are called uncertainty measures.
Classification uncertainty
对概率学感兴趣的同学,可以直接看如下公式即可:

Classification margin
同样,一个抽象公式:

Classification entropy
公式:

Disagreement sampling(Committee-based )
When you have several hypotheses about your data, selecting the next instances to label can be done by measuring the disagreement between the hypotheses. Only for classifiers。
Vote entropy

有没有发现这个和已经构建的大小模型diff是一个东西。我们将classier数量定为2,一个是离线大模型,一个是在线小模型。那么如果两个模型的vote entropy较大(也就是所说的结果diff较大),则将此数据筛选出来,用于训练。
Consensus entropy
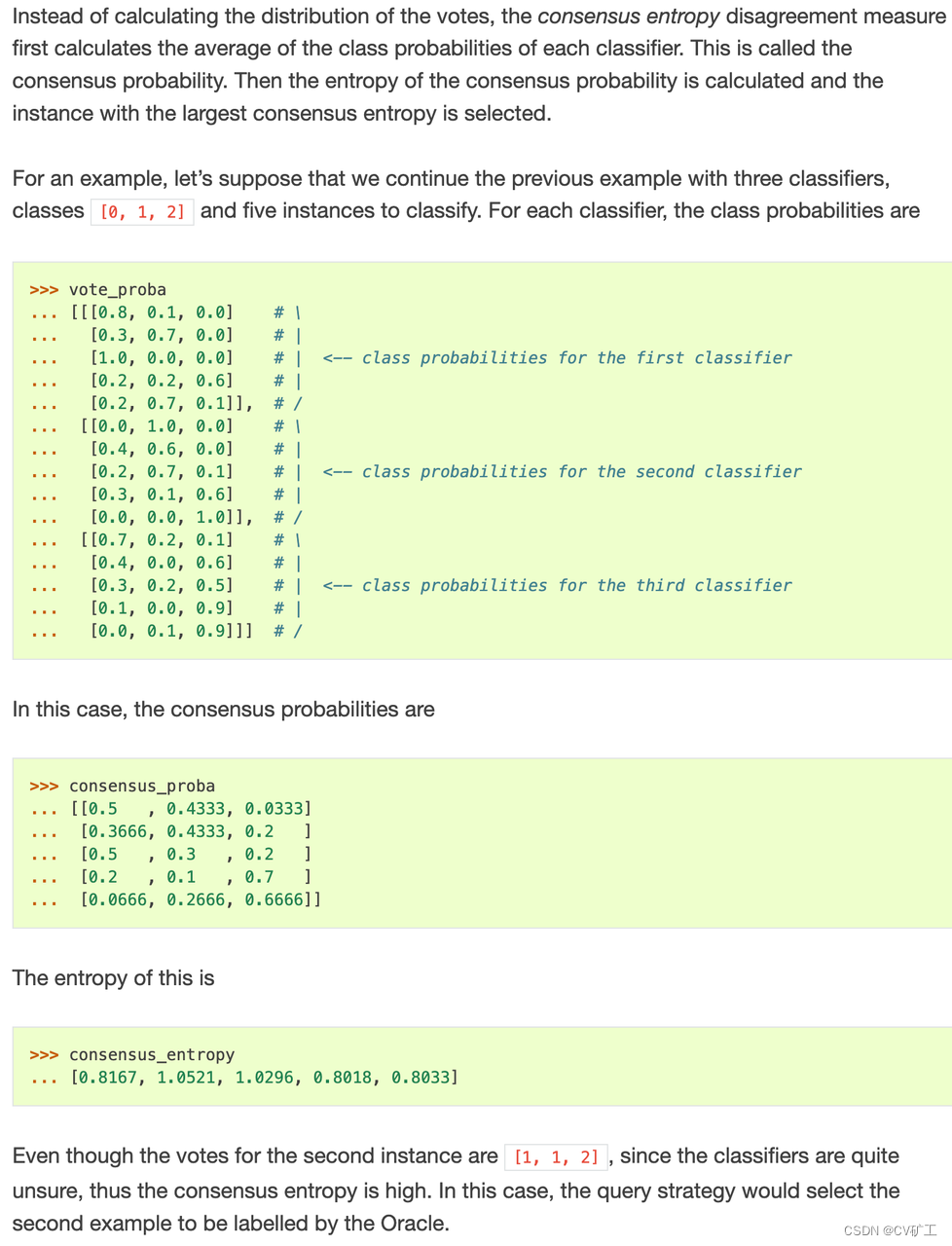
这里稍稍难懂些,解释下。我们分别求出三个分类器对5个instance的分类结果,也就是模型出的cls分类,一般经过sigmoid后,是一个概率分布。如上边的vote_proba所示。那么我也就知道每个模型对每个物体属于哪个分类的概率。那么我们对vote_proba在第二维上求mean,得到了文中所说的consensus_proba,consensus_proba[0, 0]的含义就是对第一个instance来说,它属于第一类(class)的平均概率,换个说法,三个模型认为此instance属于第一类的平均概率,也就暗合了一致性的说法。最后对每个instance的三个类别的一致性概率求一致熵。如果熵较大,那也就说明对这个instance来说,所有分类器给他的打分都很低(高),也就更不确定,那么他大概率就是容易出问题的目标了。
Max Disagreement
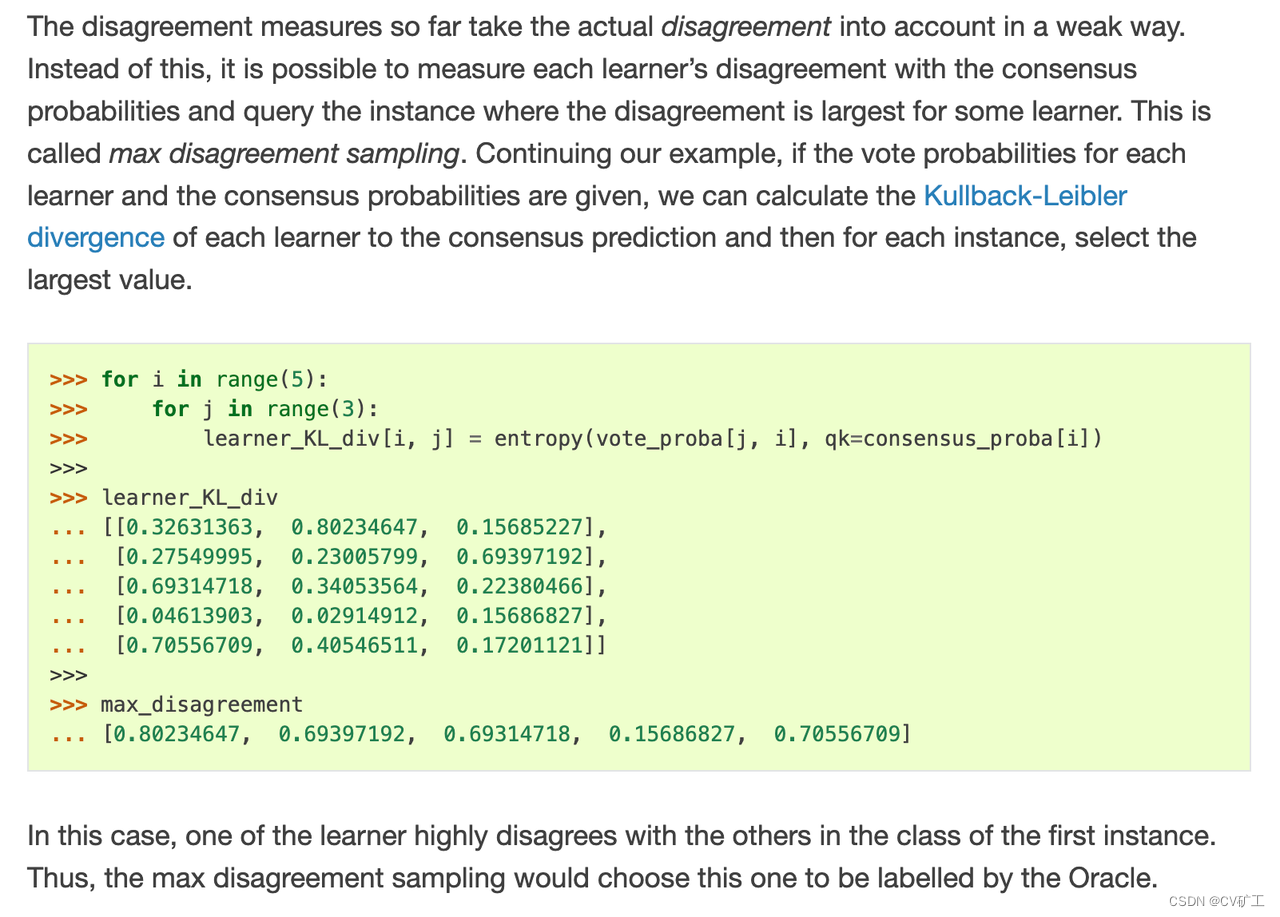
Kullback-Leibler divergence:(相对熵/KL散度)衡量两个概率之间的“距离”,因此可以用 KL 散度计算出那些偏差较大的数据样本。
现状
Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering
ACL 2021年的outstanding paper证明对VAQ(visual question answering)任务任务来说,使用目前的query方法得到的数据进行模型训练,并不能得到比random sample的数据集训练的模型好的性能。所以在目前LLM火热的情况下,active learning也就变得不温不火。论文熟肉
但是在传统的分类、物体识别领域,active learning取得的成果还是有目共睹的。
(
Ozan Sener and Silvio Savarese. 2018. Active learning for convolutional neural networks: A core-set approach. In International Conference on Learning Representations (ICLR).
Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. 2009. Multi-class active learning for image classification. In Computer Vision and Pattern Recognition (CVPR), pages 2372–2379.
)
而对于我们公司或者说项目来说,自动驾驶算法作为核心项目。所以用active learning相关方法进行数据挖掘工作,是能给最终的效果带来很大的提升,甚至减少足够的研发成本。
相关参考文献(SOTA or 曾经 SOTA)
1.A Survey on Active Deep Learning: From Model-driven to Data-driven
2.Data Classification Algorithms and Applications
3.Weather and Light Level Classification for Autonomous Driving: Dataset, Baseline and Active Learning
4.Active Finetuning: Exploiting Annotation Budget in the Pretraining-Finetuning Paradigm (CVPR 2023)
5.ActiveGLAE: A Benchmark for Deep Active Learning with Transformers
6.active learning literature survey
7.Active Learning by Feature Mixing (CVPR 2022)
8.Exploring Diversity-based Active Learning for 3D Object Detection in Autonomous Driving (IEEE)
9.Scalable Active Learning for Object Detection
相关开源REPO
1.https://github.com/aayushjr/HybridCLAUS
2.https://github.com/Luoyadan/CRB-active-3Ddet
3.https://github.com/baal-org/baal
4.https://github.com/SupeRuier/awesome-active-learning (推荐)
相关科技软文
- https://zhuanlan.zhihu.com/p/352339212
- https://zhuanlan.zhihu.com/p/391078925
- https://zhuanlan.zhihu.com/p/239756522
- https://zhuanlan.zhihu.com/p/377045943