Haskell 语言的设计者之一 Paul Hudak 曾说过一句略带夸张的话(overstatement):
编程中最重要的三件事是: 抽象, 抽象, 抽象.
“abstraction, abstraction, abstraction” are the three most important things in programming.
如果你去问一些资深开发者, 程序员最重要的的能力之一有哪些? 那么"抽象的能力"是绝对能排得上号的.
抽象的反面
那么什么是抽象呢? 抽象这个概念本身就是抽象的. 有时候, 如果不能很好地从正面把握它的含义, 不妨先从反面去考虑.
比如, 抽象的反义词是什么呢? 抽象的反面可以是具象, 也就是"具体的";另外, “抽象的"也可以对应"形象的”, 这些都可以算是它的反面.
跳出到编程之外
先不谈编程, 让我们把视野放得更开, 去看看一些现实中的例子.
一个数字的例子
让我们看一个图:

这幅图中左边描述的古巴比伦楔形数字(Babylonian cuneiform numerals), 右边上面是罗马数字(Roman numerals), 下边就不用说, 我们自家的数字.
发现什么规律没有呢? 显然, 楔形数字 1-5 都是"形象的", 罗马和中国的数字前面三也是"形象的", 无非是一个是竖着来, 一个是横着来, 但到了 4,5 慢慢就变"抽象"了.
事实上, 汉字数字"四"还有一个异体字"亖", 也即下图所示, 也还挺"形象"的:

另一方面, 阿拉伯数字基本都很"抽象", 1,2,3,4,5, 彼此间并没有太多相似之处.
我们中国人常说"事不过三", 为什么许多数字系统从 4,5 开始就慢慢转向抽象了呢?
形象的好处及其代价
我估计大家都可能听说一个<<从三到万>>的故事:
汝有田舍翁, 家资殷盛, 而累世不识"之"“乎”. 一岁, 聘楚士训其子. 楚士始训之搦管临朱. 书一画训曰: 一字;书二画, 训曰: 二字;书三画, 训曰: 三字. 其子辄欣欣然, 掷笔归告其父, 曰: 儿得矣, 儿得矣;可无烦先生, 重费馆谷也, 请谢去. 其父喜, 从之, 具币谢遗楚士.
逾时, 其父拟征召姻友万氏者饮, 令子晨起治状, 久之不成. 父趣之, 其子恚曰: "天下姓氏夥矣, 奈何姓万!自晨起至今, 才完五百画也. "
呜呼!世之学者偶一解, 辄自矜有得, 殆类是也.
大意就是一个有钱的老头请一教书先生教儿子写字, 先生先教他的儿子执笔描红. 写一画, 教他说: "这是一字. "写二画, 教他说: "这是二字. "写三画, 教他说: "这是三字. “然后这个儿子就把笔一扔, 说这些太简单, 我学会了. 直到有一天, 他父亲让他给一个"万先生"写一个请帖, 结果他从清早写了半天, 也只完成"五百画”…
以上当然只是一个笑话, 不过从中我们也不难体会到, 形象虽然易于理解, 但一直这么形象下去, 弊端也是很明显的.
我们再看一个汉字"马"字的演变:

也不难发现, 马一开始也是很形象的, 有鬃毛, 有四条腿乃至有尾巴, 细节非常丰富, 但到了后来这些细节就基本消失了. 毕竟, 如果你经常要写这么一个字, 而写这么个字简直跟画画差不多, 那肯定是非常累的一件事.
考虑到反复用时的方便, 形象化带来的麻烦已经超过带来的好处. 代价超过了好处, 经济学就要发挥它的威力了, 我们需要新的平衡.
基本上, 语言文字走的都是越来越抽象化的道路, 那些字母化的语言文字就跟不用说了.
回到数字的例子, 如果一直按照罗马数字开头的那种的方式构造, 那么数字 9 就会变成这样:
IIIIIIIII
猛一看上去, 还不好看出它到底是几竖. 而如果是 13 呢? 那就变成了这样:
IIIIIIIIIIIII
如果更大, 那就没救了, 甚至说, 它反而不形象了.
类似的一个例子可以参考之前的"复杂性管理与重复性管理".
一个文字的例子
说完了数字的例子, 再来看一个文字的例子.
如果有这么一段话:
"公司的营业额这个季度比上个季度增长 12%, 这个季度比去年这个季度增长 23%;公司的利润这个季度比上个季度增长 16%, 这个季度比去年这个季度增长 34%. "
显然, 这段话挺啰嗦的, 如果有更多的指标要描述, 则还会更啰嗦.
现在假如我们抽象出两个概念, 令:
环比=这个季度比上个季度
同比=这个季度比去年这个季度
那么我们可以把上述的话简化为:
"公司的营业额环比增长 12%, 同比增长 23%;公司的利润环比增长 16%, 同比增长 34%. "
是不是简洁了很多呢?
注: 严格地讲, 同比是指和上一周期的同时段相比;
环比是指和同一周期的上一个时段相比. 这里的时段可以是季度, 也可以是月;
周期类似, 一般是年, 但也可以是比年更大的(或更小).
尽管在这里, 环比和同比也还在不断重复, 但却是以一种较小代价在重复.
显然这种重复是没法避免的, 因为它是客观需求所决定的, 有多少个指标要描述, 我们就要重复多少遍.
直观地讲: 不断用更短的东西去取代更长的东西. 从"重复 9 或 11 个字"到只"重复 2 个字", 还是有进步的.
所以, 我们说要管理重复性, 当重复不可避免时, 关注的关键是怎样以较小代价去重复, 这就需要抽象, 把细节压制. 尽管对于刚接触这些抽象概念的人来说, 这种抽象性使他们一开始不容易明白, 但一旦熟悉了它们的具体含义, 以后就可以持续运用这些抽象概念并得到许多好处.
编程的例子
好了, 以上说了不少具体的事例, 如果你一开始对"抽象"这个概念还是迷迷糊糊的话, 现在应该有了一点感觉.
为什么举这么多例子呢? 本质上讲, 抽象就是从一个个具体的事例中"上升"或者说"升华"得到的, 我们的认知过程是从具体到抽象的.
我并不希望给"抽象"下一个抽象的定义给你, 我更希望你能通过这样一个个具体事例去感受什么是"抽象".
说完了编程外的, 现在让我们回到编程的例子上来.
一个具体的程序
假设要写一个排序的程序, 具体要求是这样的:
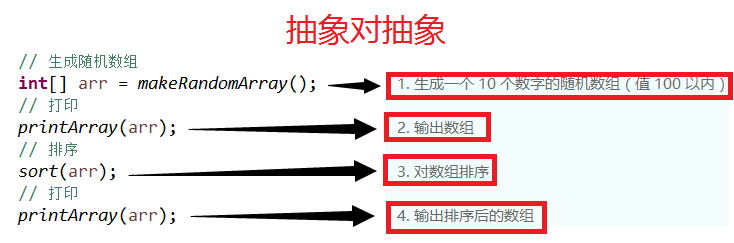
生成一个 10 个数字的随机数组(值 100 以内)
输出数组
对数组排序
输出排序后的数组
然后, 一个初学者他写的代码很可能是这样的:
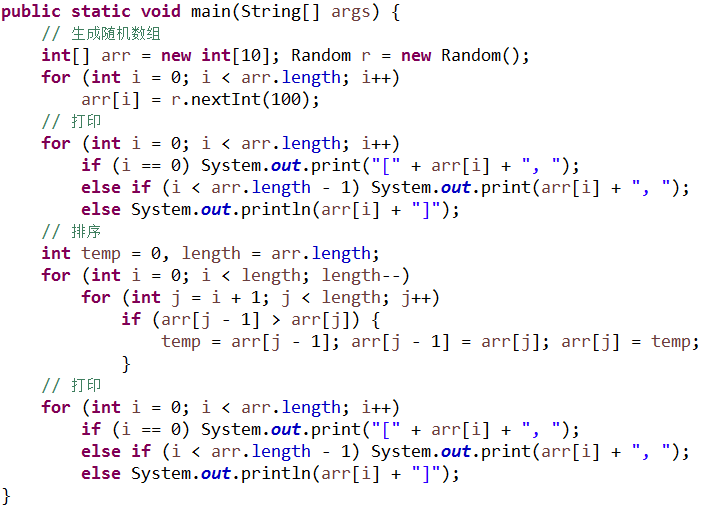
注: 为紧凑起见, 省略了一些必要的换行及大括号.
那么, 这段代码有什么问题呢? 我们接下来一一分析一下.
如何建立抽象?
首先, 能很明显的观察到一个重复, 那就是"打印"部分, 这里实际缺乏一个名为 printArray 的抽象, 我们可以用静态方法来构建这么一个抽象,
注: 在 Eclipse 中, 可以这样操作:
- 选中"打印"部分的代码(上面或下面的均可)
- 选择"菜单—Refactor—Extract method…"
- 在弹出框中的"method name"一栏中输入"printArray"
- 点击 OK 即可完成这个重构
Eclispe 会为你找出两处重复的地方, 并一并替换它们, 在点击 OK 前, 也可以点击 Preview 先预览重构后的效果, IDEA 中也可以做类似操作, 具体细节此处从略.
结果如下:

我们建立了一个叫 printArray 的方法抽象, 接受一个数组作为参数, 然后在 main 方法中调用即可, 这样就减少了重复. 这就是用方法来构建抽象, 相信你也不会太陌生.
那么, 还能更进一步改进吗? 假如你有个同事听说你写了个排序的程序, 然后他手头有个数组也想排个序, 于是他想借用一些你的方法, 但你会很尴尬地发现你没有这样一个方法可以给到他.
虽然在你的代码中, 确实有一部分做了排序的工作, 可是你却没有明确地把这些代码提取出来, 它们和那些生成随机数, 打印的代码混在了一起, 以至于你的同事根本没有办法复用, 于是他很可能直接就把你的代码拷贝过去了, 也因此重复就产生了.
所以, 问题出在你的代码中没有抽象出一个叫"排序"的东西, 还是按照前面类似的重构步骤, 我们构建出一个叫 sort 的抽象:
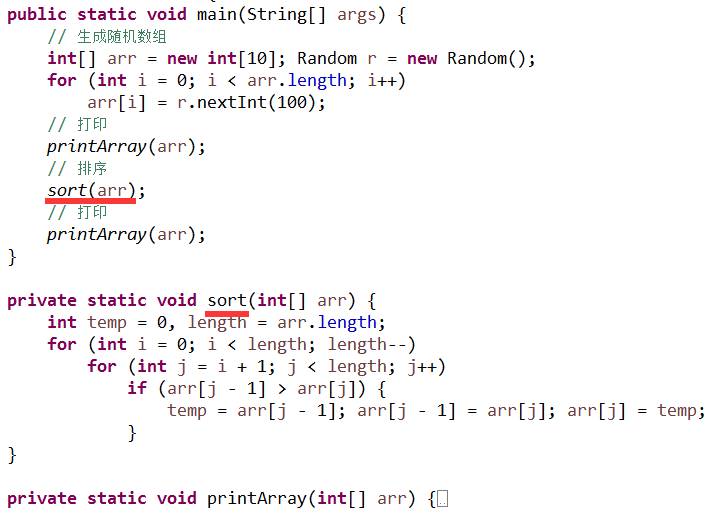
缺省情况下, 重构出来的方法是 private, 这时你只要把它改成 public 的即可, 你的同事就可以复用它了, 这样他就可以避免拷贝你的代码或者重复去写另一个排序的代码, 所谓的"重复造轮子", 你们的系统中也因此避免了重复.
那么, 事情到了这里, 是否就结束了呢? 如果我们现在观察 main 方法,

我们有三个抽象的步骤, 但最前面还剩下一堆具体的代码, 显得跟下面的代码很不匹配.
假如这时又有一个同事说, 听说你写了一份生成随机数组的程序, 我也正好想要一份随机数组来做点事情, 我能用下你的方法吗?
然后你还是很尴尬…最后重复又产生了…
事实上这里还是缺乏一个抽象, 让我们再进一步, 构建一个叫 makeRandomArray 的抽象, 最终的效果如下:
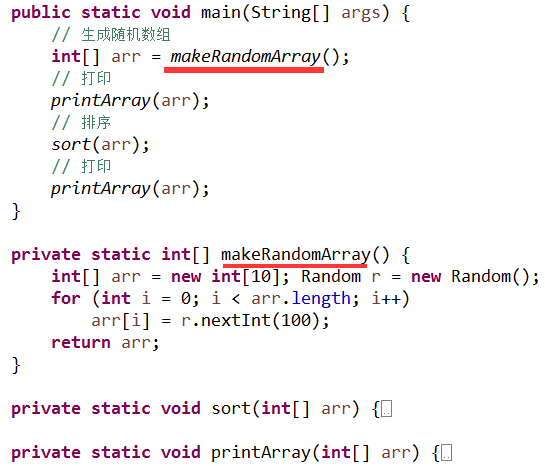
如果现在我们回顾对比一下最初的需求以及我们最初的实现, 会发现需求的描述是抽象的, 比如并没有仔细描述应该如何去排序等, 但最初的实现却是非常具体的:

如果把几行注释去掉, 甚至代码间彼此的边界也不清晰!而经过一番重构之后, 抽象的 4 条需求描述在我们的代码中有了非常明确的对应:
现在我们的 main 方法非常简洁, 逻辑也非常清晰, 甚至可以不需要注释.
过多的注释有时反而是一种代码的"坏味道"(bad smell), 说明你的代码的自解析性不强, 通常即是由缺乏抽象及良好命名所导致.
应该说, 能够做到这一步抽象的初学者是很少的.
甚至说有很多有多年经验的开发者也未必有这个意识, 他们可能会注意到 printArray 的重复, 也会抽象出一个 sort 方法, 但是否会为构建一个随机数组也做出一个抽象从而使其与整个需求步骤形成一个良好的匹配呢?
很多的教科书中的代码往往也是上来就是一堆的具体实现, 很少告诉读者其实在某些地方是可以适当引入一些抽象的.
有时我们甚至可以在 main 方法中就着需求直接先写出四个方法抽象, 再生成这些方法的空的骨架, 在这过程中我们只需关注输入输出, 然后再逐步填充方法的细节.
这也就是所谓的"top down"自顶向下式的编程, 关于这些, 可以参考之前的 小程序与大道理系列.
更进一步的抽象
对于 makeRandomArray 我们甚至还可以继续地抽象. 假如有同事说他想通过求一个随机数组的平均值来考察下生成的随机数的随机性, 然后他希望生成的数组能更大一点, 比如 30 个.
而我们现在的方法是写死了 10 个的, 那么他可能又被迫拷贝一份你的代码, 然后仅仅把其中的 10 改成 30, 这样显然又增加了很多的重复.
显然, 无论是 10 还是 30, 它们都是"具体的"值, 它们不够抽象, 这时我们可以把它参数化, 通过引入一个抽象的参数来取代这些具体的值,
这点也可以通过 Eclipse 中的重构实现:
- 先选中方法中那个具体的参数值 10
- 选择"菜单—Refactor—Introduce Parameter…"
- 在弹出框中输入参数名"size"
- 点击 OK
结果是这样:
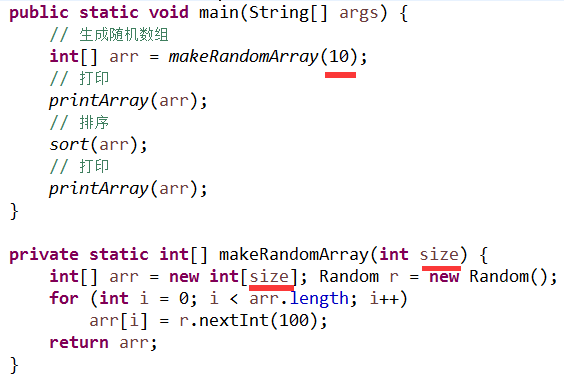
这样你的代码又可以被别人所复用了, 他只要传一个不同的参数值即可, 系统也因此减少了重复.
现在假如又有一位同事说, 他想实现一个在前一千名的观众中随机抽取 20 位中奖者的程序, 那么现在的 makeRandomArray 方法能否满足呢?
显然, 生成 20 个随机数是没有问题的, 因为现在数组大小是抽象的, 参数化了的. 但一千名观众就有问题了, 因为的我们的代码中还有一个"具体的"值, 就是那个 100, 它阻碍了我们, 使得只能生成 100 以内的随机数.
某种意义上, 任何一个具体的东西都是一种限制, 使一段程序的通用性降低.
就好比说从"中国男人"到"男人"到"人", 它的抽象程度是不断提高的, 普适性是越来越强的.
“中国”, "男"这些都是具体的修饰, 也是一种限制.
如果我们想让程序具有较好的普适性, 就必须要将那些具体的东西干掉, 越抽象, 普适性就越好. 那么同样的, 我们可以将这个 100 用一个抽象的参数代替:
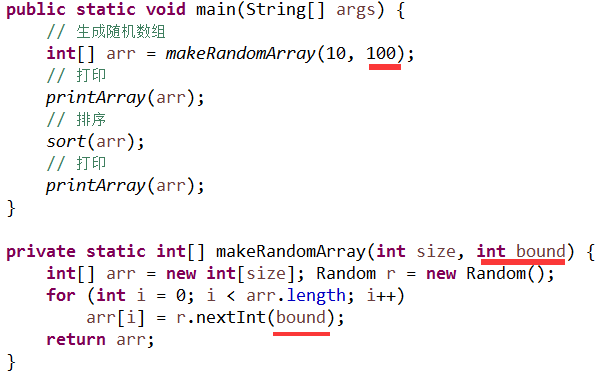
那么你的同事也不用"重复发明轮子"(reinvent the wheel), 他只要发出这样一个不同实参的调用即可:
makeRandomArray(20, 1000)
如此, 你的系统又避免了重复. 一个变量, 一个参数它们都可以成为一种抽象.
关于参数化这个话题, 也可以参考之前的"重复性管理–从 泛值到泛型 以及 泛函 系列.
关于这个具体的例子, 就先谈论到这里. 由于篇幅关系, 一些更深入的探讨及更多的例子我们留待下篇再说.