Java 的模式匹配是一个新型的、而且还在持续快速演进的领域。类型匹配是模式匹配的一个规范。类型匹配这个特性,首先在 JDK 14 中以预览版的形式发布。在 JDK 15 中,改进的类型匹配再次以预览版的形式发布。最后,类型匹配在 JDK 16 正式发布。
那么,什么是模式匹配,什么又是类型匹配呢?这就要说到模式的组成。通常,一个模式是匹配谓词和匹配变量的组合。其中,匹配谓词用来确定模式和目标是否匹配。在模式和目标匹配的情况下,匹配变量是从匹配目标里提取出来的一个或者多个变量。
对于类型匹配来说,匹配谓词用来指定模式的数据类型,而匹配变量就是一个属于该类型的数据变量。需要注意的是,对于类型匹配来说,匹配变量只有一个。
这样的描述还是太抽象,太难理解。我们还是通过案例和代码,一点一点地来理解类型匹配吧。
阅读案例
在程序员的日常工作中,一个重要的事情,就是把相似的东西抽象出来,设计成一个通用的、可以复用的接口。
比如说,我们从正方形、长方形、圆形这些看起来差异巨大的东西出发,抽象出了形状这个接口。我们希望使用一个实例时,如果我们不能确定它是正方形还是长方形,我们至少还能确定它是一个形状。这种模模糊糊的确定性(其实也是不确定性),其实对我们编写代码有巨大的帮助,包括但是不限于简化代码逻辑,减少代码错误。
但要注意的是,每一个实例都是具体的形状。它可以是正方形的对象,可以是长方形的对象,就是不能是一个抽象的形状。也就是说,抽象的类和接口不能直接实例化。
一个方法的规范,它的输入参数可能是一个表示形状的对象,也可能是一个更一般化的对象。比如说吧,我们要设计一个方法,来判断一个形状是不是正方形。那么,就需要一个表示形状的对象,作为这个方法的输入参数。而实现这个方法的代码,仅仅知道形状这个一般化的对象是远远不够的。下面的代码,就是一个这种方法的实现代码。
static boolean isSquare(Shape shape) {
if (shape instanceof Rectangle) {
Rectangle rect = (Rectangle) shape;
return (rect.length == rect.width);
}
return (shape instanceof Square);
}
在这个 isSquare 方法的实现代码里,我们需要使用 instanceof 运算符,来判断输入参数是不是一个长方形的实例;如果判断成立,再使用类型转换运算符,把这个实例投射成长方形的实例;最后,我们开始使用这个长方形的实例,进行更多的运算。
其实,这样的操作是一个模式化的过程。如果我们把它揉碎了来看,这个模式有三个部分。
第一个部分是类型判断语句,也就是匹配谓词,使用的代码是“instanceof Rectangle”。第二个部分是类型转换语句,使用的是类型转换运算符((Rectangle) shape)。第三个部分是声明一个新的本地变量,也就是匹配变量,来承载转换后的数据,使用的是变量声明和赋值运算符(Rectangle rect =)。第二个部分和第三个部分,只有在类型判断成立的情况下,才能够执行。
使用这样的模式化操作,是一个 Java 程序员的基本功。这个模式直观而且便于理解。可是,这个模式很乏味,也很臃肿。调用了 instanceof 之后,除了类型转换之外,我们还可以做什么呢?一般情况下,在类型判断之后,我们总是紧跟着就进行类型转换。
把类型判断和类型转换切割成两个部分,增加了错误潜入的机会,平添了许多烦恼。比如说,一个活生生的程序员或者冷冰冰的机器,有可能无意地使用了错误的类型。下面例子中的两段代码,就是两个常见的类型转换错误。第一段代码误用了变量类型,第二段代码误用了判断结果。
if (shape instanceof Circle) {
Rectangle rect = (Rectangle) shape;
return (rect.length == rect.width);
}
if (!(shape instanceof Rectangle) {
Rectangle rect = (Rectangle) shape;
return (rect.length == rect.width);
}
类型判断之后,我们原本就可以开始关注更重要的后续代码逻辑了,但现在不得不停下来编写类型转化代码,或者审视类型转换代码是否恰当。这当然影响力了生产效率。
我们可以用什么方法改进这个模式,提高生产效率呢? 这个问题的答案就是类型匹配。
类型匹配
那么,类型匹配是怎么改进这个模式的呢?我们先来看看使用了类型匹配的代码的样子。下面的例子,就是使用类型匹配的一段代码。
if (shape instanceof Rectangle rect) {
return (rect.length == rect.width);
}
为了便于更直观地比较,我把传统的实现代码和使用了类型匹配的实现代码列在了下面的表格里。你可以找找其中的差异,体会下类型匹配带来的改进。

就像我们前面拆解的一样,传统的实现代码有三个部分;而使用类型匹配的代码,只有匹配谓词和本地变量两个部分,而且是在同一个语句里。为了帮助你理解这些概念,我画了下面的这张图,标记出了类型匹配的组成部分和关键概念。
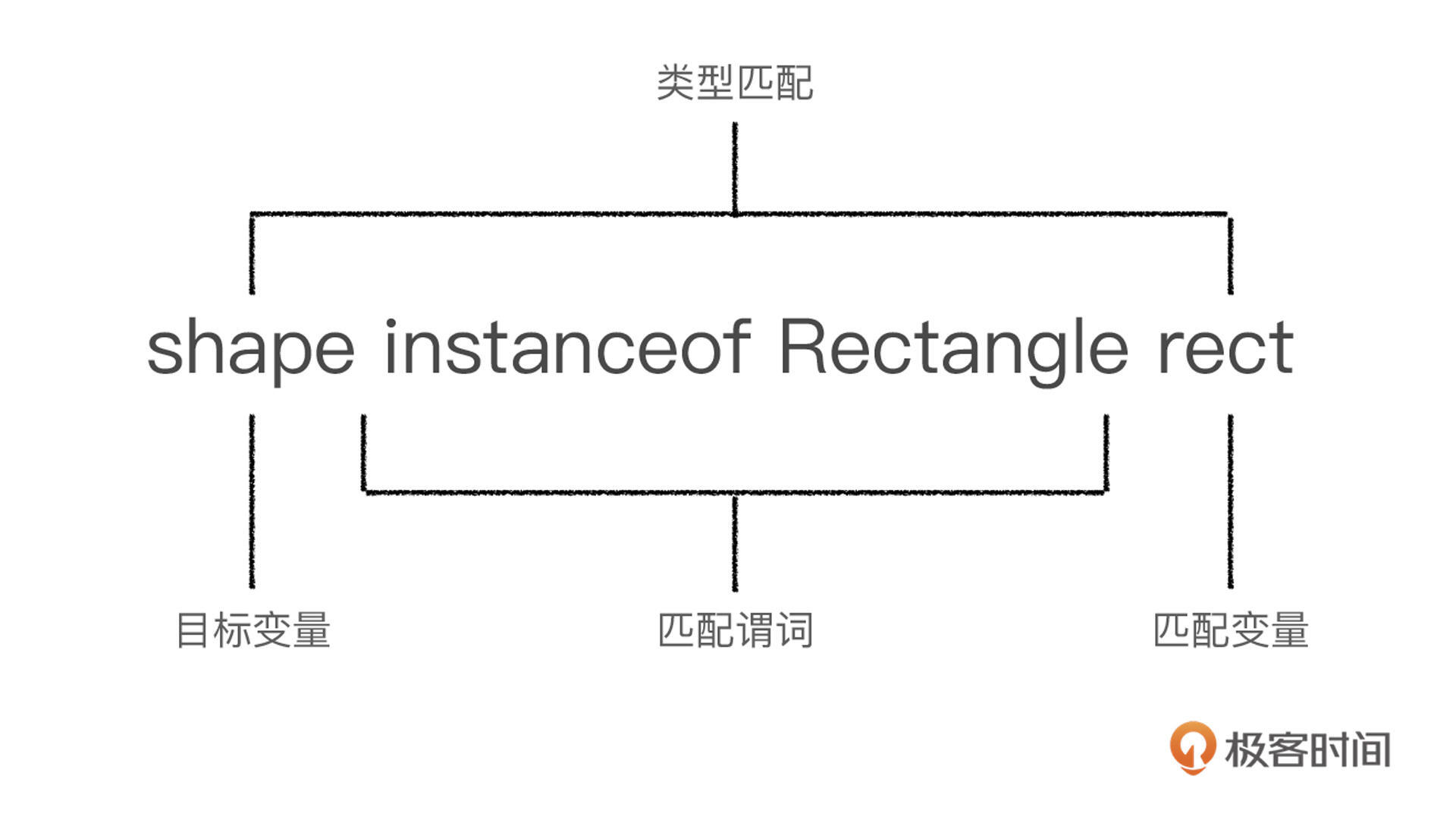
你可能已经注意到了,使用类型转换运算符的语句,没有出现在使用类型匹配的代码里。但是,这并不影响类型匹配代码所要表达的基本逻辑。
这个基本逻辑就是:如果目标变量是一个长方形的实例,那么这个目标变量就会被赋值给一个本地的长方形变量,也就是我们所说的匹配变量;相反,如果目标变量不是一个长方形的实例,那么这个匹配变量就不会被赋值。
前面,我们讨论了两个常见的类型转换错误:误用变量类型和误用判断结果。在使用类型匹配的代码里,不再需要重复使用匹配类型,也不再需要使用强制类型转换符。所以,使用类型匹配的代码,不用再担心误用变量类型的错误了。
误用判断结果的错误,是不是也被解决了呢? 似乎,我们还能写出下面的代码。在这样的代码里,如果目标变量不是一个长方形的实例,我们是不是也有可能使用匹配的变量呢?
if (!(shape instanceof Rectangle rect)) {
return (rect.length == rect.width);
}
幸运的是,类型匹配已经考虑到了这个问题,Java 编译器能够检测出上面的错误,不会允许使用没有赋值的匹配变量。这样,在代码编译期间,就有机会纠正代码的错误。比如说,我们可以尝试修改成下面的逻辑:如果目标变量不是一个长方形的实例,我们就不使用匹配变量;否则,我们就使用匹配变量。把这个逻辑映射到代码,大致是下面的样子。
if (!(shape instanceof Rectangle rect)) {
return false;
} else {
return (rect.length == rect.width);
}
在上面的代码里,使用匹配变量的条件语句 else 分支并没有声明这个匹配变量。为什么 if 语句声明的变量,可以在 else 语句里使用呢?要弄清楚这个问题,我们还要了解匹配变量的作用域。掌握匹配变量的作用域,是学会使用类型匹配的关键。
匹配变量的作用域
匹配变量的作用域,就是目标变量可以被确认匹配的范围。如果在一个范围内,无法确认目标变量是否被匹配,或者目标变量不能被匹配,都不能使用匹配变量。 如果我们从编译器的角度去理解,也就是说,在一个范围里,如果编译器能够确定匹配变量已经被赋值了,那么它就可以在这个范围内使用;如果编译器不能够确定匹配变量是否被赋值,或者确定没有被赋值,那么他就不能在这个范围内使用。
我们还是通过代码来理解这个有点抽象的概念吧。
第一段代码,我们看看最常规的使用。我们可以在确认类型匹配的条件语句之内使用匹配变量。这个条件语句之外,不是匹配变量的作用域。
public static boolean isSquareImplA(Shape shape) {
if (shape instanceof Rectangle rect) {
// rect is in scope
return rect.length() == rect.width();
}
// rect is not in scope here
return shape instanceof Square;
}
第二段代码,我们看看有点意外的使用。我们可以在确认类型不匹配的条件语句之后使用匹配变量。这个条件语句之内,不是匹配变量的作用域。
public static boolean isSquareImplB(Shape shape) {
if (!(shape instanceof Rectangle rect)) {
// rect is not in scope here
return shape instanceof Square;
}
// rect is in scope
return rect.length() == rect.width();
}
第三段代码,我们看看紧凑的方式。这一段代码的逻辑,和第一段代码一样,我们只是换成了一种更紧凑的表示方法。
在这一段代码里,我们使用逻辑与运算符表示第一段里的条件语句:类型匹配并且匹配变量满足某一个条件。这样的表示是符合匹配变量的作用域规则的。逻辑与运算符从左到右计算,只有第一个运算成立,也就是类型匹配,才能进行下一个运算。所以,我们可以在逻辑与运算的第二部分,使用匹配变量。
public static boolean isSquareImplC(Shape shape) {
return shape instanceof Square || // rect is not in scope here
(shape instanceof Rectangle rect &&
rect.length() == rect.width()); // rect is in scope here
}
第四段代码,我们看看逻辑或运算。它类似于第三段代码,只是我们把逻辑与运算符替换成了逻辑或运算符。这时候的逻辑,就变成了“类型匹配或者匹配变量满足某一个条件”。逻辑或运算符也是从左到右计算。
不过和逻辑与运算符不同的是,一般来说,只有第一个运算不成立,也就是说类型不匹配时,才能进行下一步的运算。下一步的运算,匹配变量并没有被赋值,我们不能够在这一部分使用匹配变量。所以,这一段代码并不能通过编译器的审查。
public static boolean isSquareImplD(Shape shape) {
return shape instanceof Square || // rect is not in scope here
(shape instanceof Rectangle rect ||
rect.length() == rect.width()); // rect is not in scope here
}
第五段代码,我们看看位与运算。
这段代码和第三段代码类似,只是我们把逻辑与运算符(&&)替换成了位与运算符(&)。
和第三段代码相比,这一段代码的逻辑其实并没有变化。只不过,位与运算符两侧的表达式都要参与计算。也就是说,不管位与运算符左侧的运算是否成立,位与运算符右侧的运算都要计算出来。换句话说,无论左侧的类型匹配不匹配,右侧的匹配变量都要使用。这就违反了匹配变量的作用域原则,编译器不能够确定匹配变量是否被赋值。所以,这一段代码,也不能通过编译器的审查。
public static boolean isSquareImplE(Shape shape) {
return shape instanceof Square | // rect is not in scope here
(shape instanceof Rectangle rect &
rect.length() == rect.width()); // rect is in scope here
}
第六段代码,我们把匹配变量的作用域的影响延展一下,看看它对影子变量(Shadowed Variable)的影响。
既然我们讨论变量的作用域,我们就不能不看看影子变量。假设我们定义了一个静态变量,它和匹配变量使用相同的名字。在匹配变量的作用域内,除非特殊处理,这个静态变量就被遮掩住了。这时候,这个变量名字代表的就是匹配变量;而不是静态变量。类似地,在匹配变量的作用域之外,这个变量名字代表的就是这个静态变量。
在这段代码里,我们使用类似于第一段代码的代码组织方式,来表述类型匹配部分的逻辑。另外,我在代码里标注了变量的作用域。你可以看看,这两个变量的作用域,和你想象的作用域是不是一样的?
public final class Shadow {
private static final Rectangle rect = null;
public static boolean isSquare(Shape shape) {
if (shape instanceof Rectangle rect) {
// Field rect is shadowed, local rect is in scope
System.out.println("This should be the local rect: " + rect);
return rect.length() == rect.width();
}
// Field rect is in scope, local rect is not in scope here
System.out.println("This should be the field rect: " + rect);
return shape instanceof Shape.Square;
}
}
第七段代码,我们还是来看一看影子变量。只不过,这一次,我们使用类似于第二段代码的代码组织方式,来表述类型匹配部分的逻辑。我在代码里标出的这两个变量的作用域,和你想象的作用域是一样的吗?
public final class Shadow {
private static final Rectangle rect = null;
public static boolean isSquare(Shape shape) {
if (!(shape instanceof Rectangle rect)) {
// Field rect is in scope, local rect is not in scope here
System.out.println("This should be the field rect: " + rect);
return shape instanceof Shape.Square;
}
// Field rect is shadowed, local rect is in scope
System.out.println("This should be the local rect: " + rect);
return rect.length() == rect.width();
}
}
如果回头看看这七段代码,你会倾向于哪一种编码的风格?我们把这些代码放在一起,分析一下它们的特点。
第四段和第五段代码,不能通过编译器的审查,所以我们不能使用这两种编码方式。
第二段和第七段代码,匹配变量的作用域,远离了类型匹配语句。这种距离上的疏远,无论在视觉上还是心理上,都不是很舒适的选择。不舒适,就给错误留下了空间,不容易编码,也不容易排错。这种代码逻辑和语法上都没有问题,但是不太容易阅读。
第一段和第六段代码,匹配变量的作用域,紧跟着类型匹配语句。这是我们感觉舒适的代码布局,也是最安全的代码布局,不容易出错,也容易阅读。
第三段代码,它的匹配变量的作用域也是紧跟着类型匹配语句。只不过,这种代码的编排方式不太容易阅读,阅读者需要认真拆解每一个条件,才能确认逻辑是正确的。相对于第一段和第六段代码,第三段代码的组织方式,是一个次优的选择。