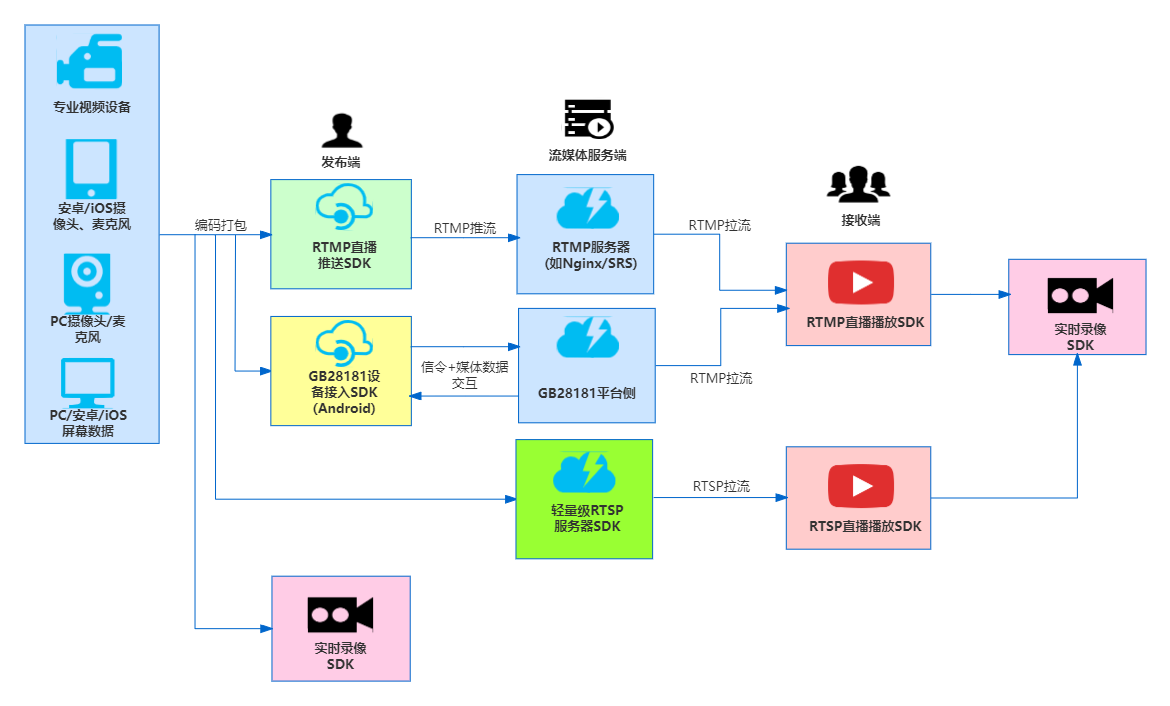
通过本文,我们将学习如何将 Unicode 编码为字节,了解系统编码的不同方法以及在 Python 中将 Unicode 转换为 ASCII。
在 Python 中将 Unicode 转换为 ASCII
Python 3 字符串的基本问题是由字符组成的; Python 中没有字符类型,但它们包含 Unicode 字符。
如果我们说 a = ‘abcd’ 并使用 len() 函数检查它的长度,那么我们得到 4 并且我们声明 s=‘שלום’ 意思是你好,这是希伯来语中的单词。 这些长度是相同的,这很好,因为两个变量都有四个字符。
>>a='abcd'
>>len(a)
4
>>s='שלום'
>>len(s)
4
事实上,幕后是不同的字节数与这里的问题无关,len() 测量的是字符数,而不是字节数,但当然,在幕后,UTF-8 Unicode 字符和 UTF-8 编码使用更多字节。
那么我们如何将字符串转换为我们需要的字节呢? 好吧,我们可以使用 s.encode(),如果我们这样做,它会返回一个字节字符串,该字符串将是我们创建希伯来语单词 שלום 所需的八个字节。
>>s.encode()
b'\xd7\xa9\xd7\x9c\xd7\x95\xd7\x9d'
>>'abcd'.encode()
b'abcd'
现在我们将获取一个 Unicode 字符串并将其转换为字节字符串,但它比这更复杂,因为我们知道这个字符串是什么,并且我们想要取回不代表 Unicode 底层字节的字节。 我们想要取回不同编码系统的底层字节。
例如,我们使用 iso-8859-8,这是您可能听说过的一种在西欧广泛使用的编码类型,它允许我们在一个字节中包含特定语言所需的所有不同字符 ,所以如果我们需要将一个字符串转换为非 Unicode 的编码。
>>s.encode('iso-8859-8')
b'\xf9\xec\xe5\xed'
让我们看看如果我们有来自不同语言的东西会发生什么,就像我们说 s='北京' 就是北京,如果我们对其进行编码,那么我们会得到一个字节字符串。
我们看到这里有六个字节,因为每个汉字都由三个字节表示; 这是我们使用 UTF-8 进行的可变长度编码。
>>s='北京'
>>s.encode()
b'\xe5\x8c\x97\xe4\xba\xac'
现在我们想使用 iso-8859-8 对 北京 进行编码,当我们执行此操作时,我们会得到 UnicodeEncodeError,这意味着编码告诉我们您想要获取这些 Unicode 字符并将它们转换为 iso-8859 的字节 -8 不允许的编码。
s.encode('iso-8859-8')

如果我们用这个连接英语单词,它也会失败,因为任何地方我们可能有错误,它都会失败,但我们可以添加一个参数来帮助忽略错误。
>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='ignore')
b'I often go to '
如果您有一大堆文本并且可以丢失 Unicode 字符,则可以使用此选项。
让我们看一下默认情况下等于 strict 的 help(s.encode),但它可以是一些不同的东西,所以如果我们使用替换值来错误,它并不真正知道如何替换,所以它 只是要使用问号。
help(s.encode)

>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='replace')
b'I often go to ??'
当我们使用 xmlcharrefreplace 时,我们会返回与这些 Unicode 字符有关的 XML 实体,因此如果您要将其粘贴到 XML 文档或 HTML 中,那么这将起作用。
>>s.encode('iso-8859-8',errors='xmlcharrefreplace')
b'I often go to 北京'
这取决于您的需求; 如果您将 Unicode 字符转换为字节,这是典型的情况,因为您将通过网络发送它们,或者您正在处理某种其他类型的编码系统。
如果您是初学者并且不想详细介绍,请使用以下命令安装名为 unidecode 的 Python 包。
它将直接将 Unicode 转换为 ASCII; 当您使用需要将 Unicode 转换为 ASCII 的应用程序时,它会很有帮助。
>>pip install unidecode
>>>from unidecode import unidecode
>>>unidecode(u'北京')
'Bei Jing'