MySQL的优化利器:索引条件下推,千万数据下性能提升273%🚀
前言
上个阶段,我们聊过MySQL中字段类型的选择,感叹不同类型在千万数据下的性能差异
时间类型:MySQL字段的时间类型该如何选择?千万数据下性能提升10%~30%🚀
字符类型:MySQL字段的字符类型该如何选择?千万数据下varchar和char性能竟然相差30%🚀
新的阶段我们来聊聊MySQL中索引的优化措施,本篇文章主要聊聊MySQL中的索引条件下推
同学们可以带着这些问题来看本篇文章:
- MySQL中多查询条件的语句是如何执行的?server层与存储引擎层如何交互?
- 聚簇索引和二级索引存储内容的区别?
- 什么是回表?回表有哪些开销?如何避免回表?
- 什么是索引条件下推?
- 什么时候可以用上索引条件下推?
- 索引条件下推能解决什么问题?
- 千万数据量下索引条件下推能提升多少性能?
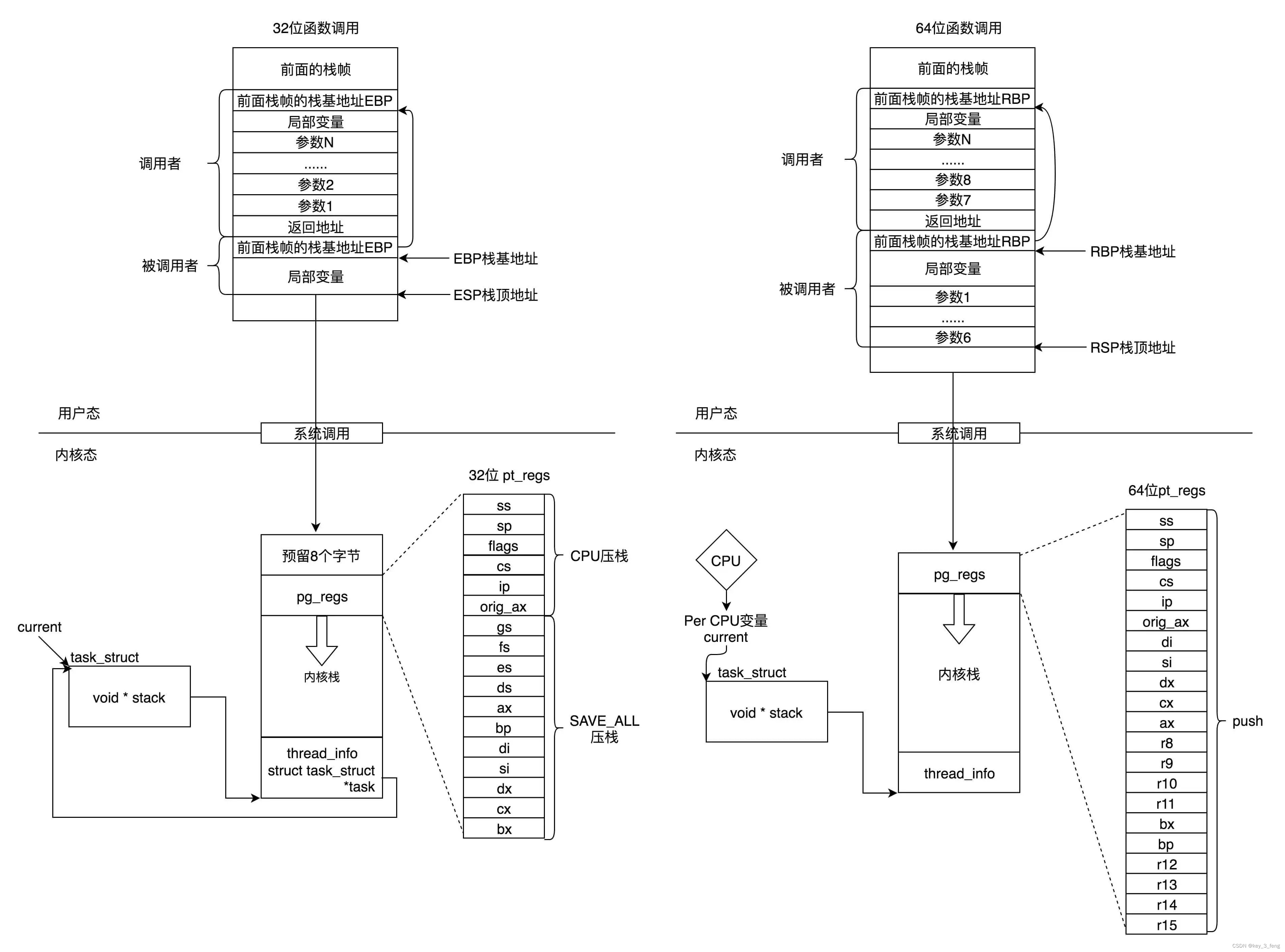
server层与存储引擎层
MySQL服务端可以分为server层与存储引擎层,存储引擎层主要存储记录,可以用不同的存储引擎实现(innodb,myisam)
server层有不同的组件处理不同的功能,比如:接收客户端请求(连接器)、检查SQL语法(分析器)、判断缓存命中(查询缓存8.0移除)、优化SQL和选择索引生成执行计划(优化器)、调用存储引擎获取记录(执行器)

server层与存储引擎层的交互
以学生表为例
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`age` smallint(6) DEFAULT NULL COMMENT '年龄',
`student_name` varchar(20) DEFAULT NULL COMMENT '名称',
`info` varchar(30) DEFAULT NULL COMMENT '信息',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`student_name`)
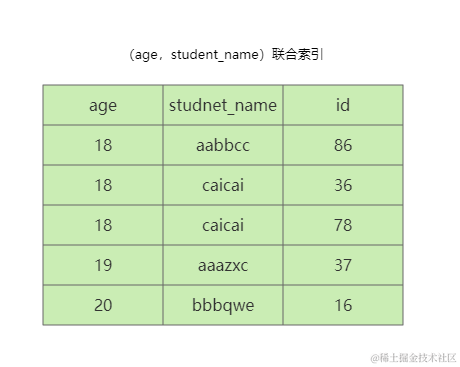
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;聚簇(主键)索引以主键id有序存储整个记录的值
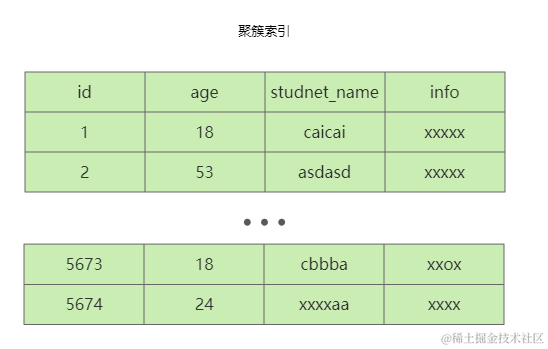
二级索引只存储规定的索引列和主键,并且以索引列、主键值的先后顺序有序
二级索引为(age,student_name)联合索引时整体上age有序,当age相等时,student_name有序,当student_name相等时,主键有序
当发生多条件查询时(where 有多个条件),执行器从存储引擎层获取完数据还需要在server层过滤其他查询条件
比如select * from student where age = 18 and student_name like 'c%'; (查询学生表中年龄为18,名称为c开头的学生)
存在(age,student_name)的联合索引,优化器会认为联合索引是最优的,于是生成使用(age,student_name)联合索引的执行计划,执行器根据执行计划调用存储引擎层
在存储引擎层会根据age = 18进行匹配,当满足此条件时,先回表查询聚簇索引
什么是回表?
二级索引只存储需要的列和主键,聚簇(主键)索引存储所有数据
由于我们使用的索引没有存储查询列表需要的列,于是需要去聚簇(主键)索引中再次查询获取其他列的值
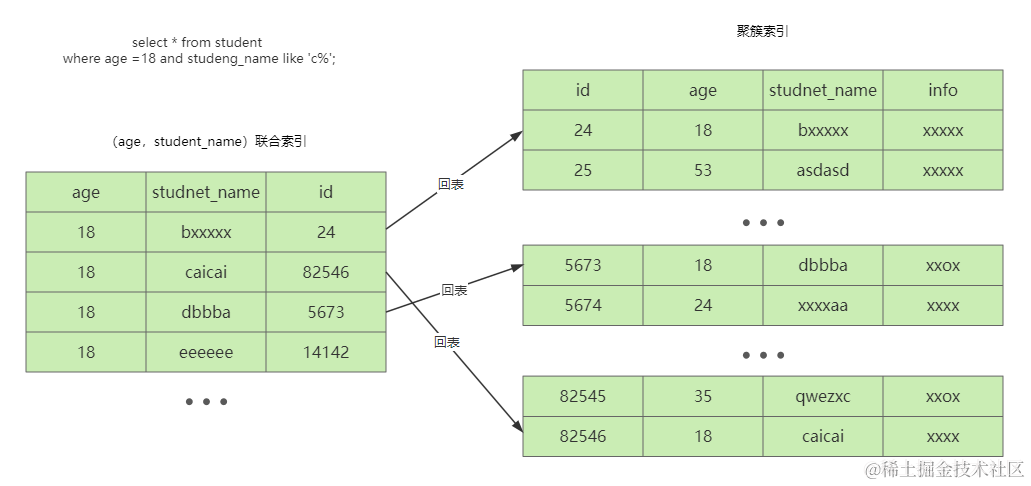
在这个过程中主键值可能是乱序的,因此回表查询聚簇索引时,会出现随机IO(开销大)
server层与存储引擎层交互的单位是记录
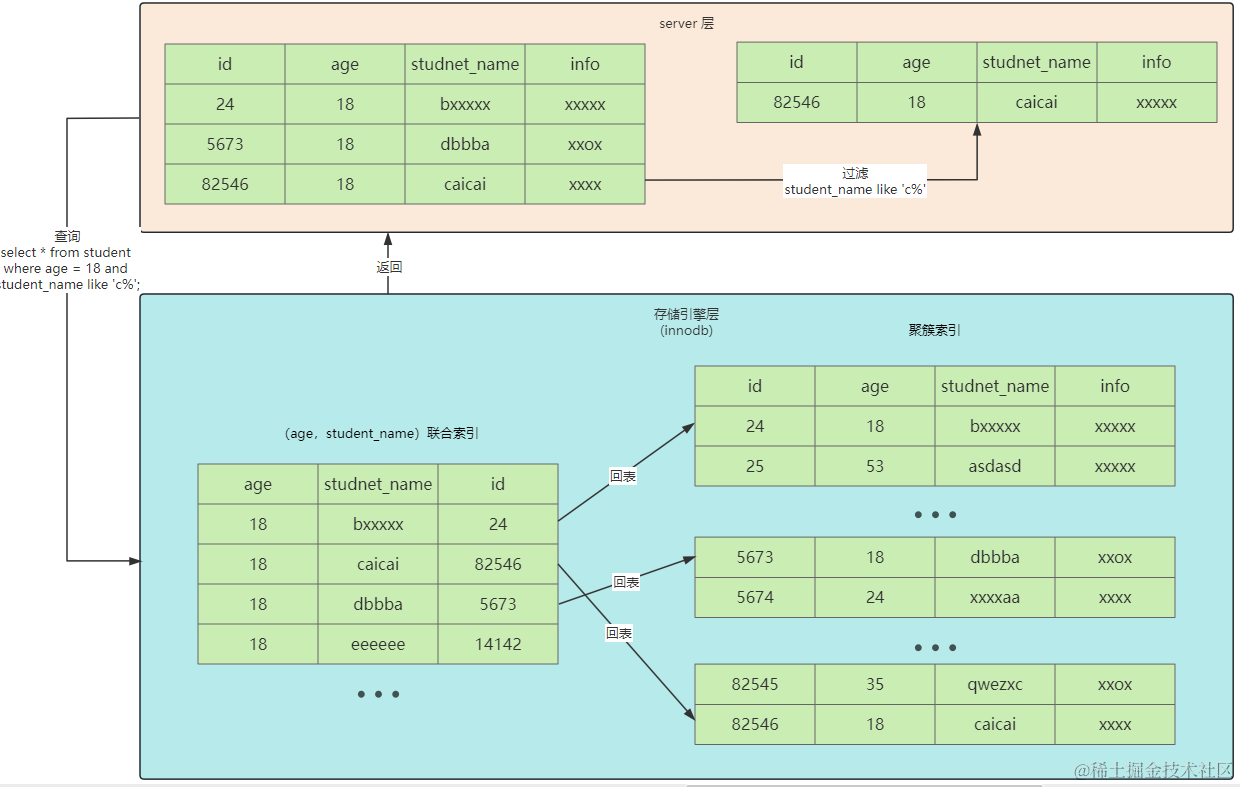
- server层优化器根据索引生成执行计划,执行器调用存储引擎层
- 存储引擎层在联合索引中寻找满足
age=18的记录 - 每次找到记录回表查询聚簇索引获取其他列的值
- 然后返回给server层进行where过滤
- 2-4实际是一个循环,直到找到第一条不满足条件的记录
在这个流程中会发现一个问题:student_name like 'c%'可以在存储引擎层的联合索引中就判断,并不需要回表查询聚簇索引后返回server层判断
索引条件下推 Index Condition Push
索引条件下推英文名:Index Condition Push
将判断where条件从server层下推到存储引擎层,也就是说存储引擎层也会判断查询其他条件
比如age=18 and student_name like 'c%',在回表前还需要判断student_name是否满足
图中第一条和第三条记录不满足student_name like 'c%'因此不回表直接跳过

索引条件下推ICP 防止明明可以在存储引擎层判断,但还回表查询后拿到server层判断,减少回表次数
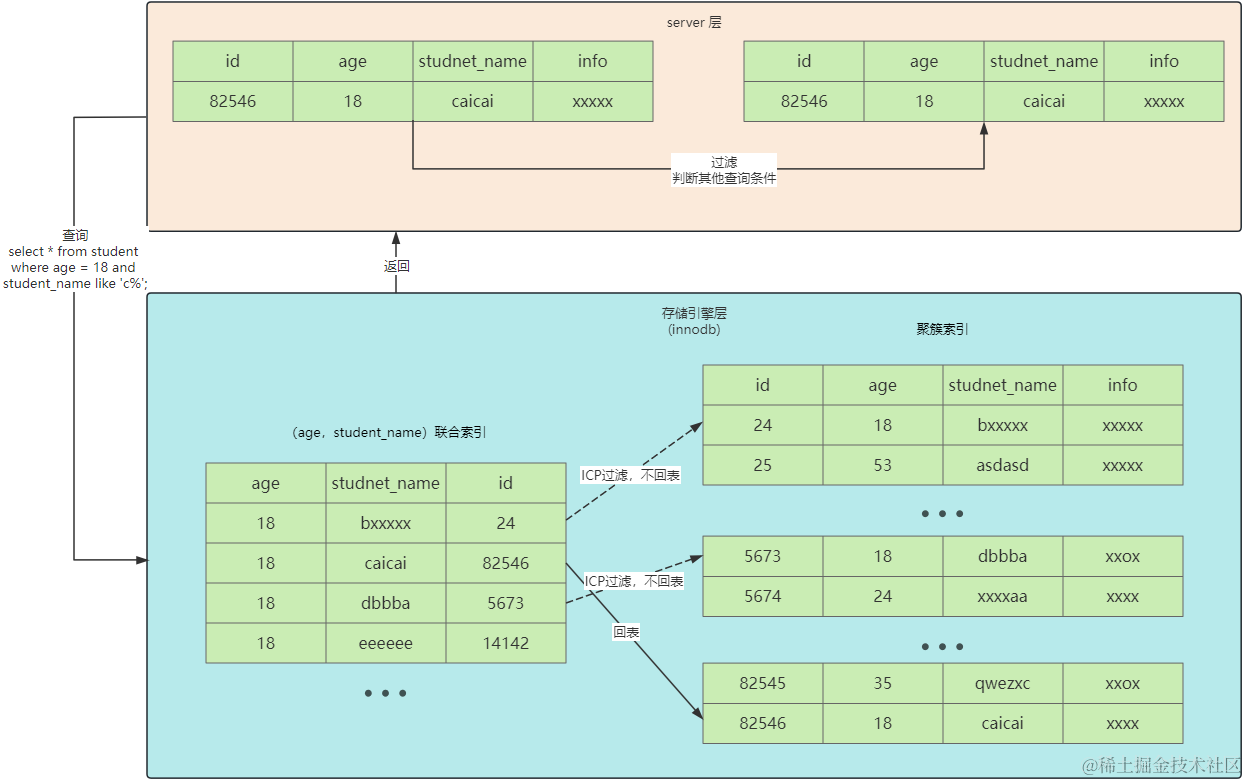
加入ICP后的执行步骤:
- server层优化器根据索引生成执行计划,执行器调用存储引擎层
- 存储引擎层在索引上查找满足
age=18的记录 - 找到满足条件的记录后,根据索引上现有列判断其他查询条件,不满足则跳过该记录
- 满足则回表查询聚簇索引其他列的值
- 获取需要查询的值后,返回server层进行where过滤
- 2-5步骤为循环执行,直到找到第一条不满足条件的记录
测试
开启函数创建
#开启函数创建
set global log_bin_trust_function_creators=1;
#ON表示已开启
show variables like 'log_bin_trust%';定义随机生成字符串函数
#分割符从;改为$$
delimiter $$
#函数名ran_string 需要一个参数int类型 返回类型varchar(255)
create function ran_string(n int) returns varchar(255)
begin
#声明变量chars_str默认'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
#声明变量return_str默认''
declare return_str varchar(255) default '';
#声明变量i默认0
declare i int default 0;
#循环条件 i<n
while i < n do
set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$定义范围生成整形函数
#生成范围生成整形的函数
delimiter $$
create function range_nums(min_num int(10),max_num int(10)) returns int(5)
begin
declare i int default 0;
set i = FLOOR(RAND() * (max_num - min_num + 1)) + min_num;
return i;
end $$定义插入函数
#插入 从参数start开始 插入max_num条数据
delimiter $$
create procedure insert_students_tests(in start int(10),in max_num int(10))
begin
declare i int default start;
set autocommit = 0;
repeat
set i = i+1;
#SQL 语句
insert into student(student_name,age,info)
values (ran_string(10),range_nums(0,100),ran_string(20));
until i=max_num
end repeat;
commit;
end $$执行
#执行插入函数
delimiter ;
call insert_students_tests(0,19000000);我测试的数据量是1900百万
记得建立索引
alter table student add index idx_age_name(age,student_name);索引条件下推默认情况是开启的,SQL_NO_CACHE是不使用缓存(MySQL5.7 版本还有缓存)
select SQL_NO_CACHE * from student where age = 18 and student_name like 'c%'
> OK
> 时间: 1.339s那如何判断是否使用到索引条件下推呢?
我们使用explain查看执行计划,当附加信息中存在Using index condition说明使用索引条件下推

那如何关闭索引条件下推呢?
这里我们使用会话级别的关闭
SET optimizer_switch = 'index_condition_pushdown=off';关闭后,再查看执行计划发现附加信息中不再有Using index condition

select SQL_NO_CACHE * from student where age = 18 and student_name like 'c%'
> OK
> 时间: 5.039s(5.039 - 1.339) / 1.339 = 276% ,使用索引条件下推提升的性能竟为 276%
经过前面的分析,索引条件下推是通过减少回表的次数从而优化性能,因此这里提升的性能实际上节省不必要的回表开销
在查询大数据量情况下,回表不仅要多查聚簇索引,还可能导致随机IO(增加与磁盘的交互)
虽然可以通过索引条件下推优化减少回表次数,但还是会有符合条件的记录需要回表
那有没有什么办法可以尽量避免回表或让回表的开销变小呢?
如果在二级索引上就已经得到需要查询的列(比如查询age,student_name,id),那么就不用回表
那如果还是要去聚簇索引查询其他列,该如何降低回表的开销呢?
这个问题留着下一章讨论,如果你想到什么方案也可以在评论区交流喔~
总结
MySQL服务端分为server层与存储引擎层,存储引擎层可以通过不同的实现(innodb,myisam)存储记录
server层拥有分工明确的不同组件:连接器(管理请求连接)、分析器(处理SQL语法、词性分析)、优化器(优化SQL,根据不同索引生成执行计划)、执行器(根据执行计划调用存储引擎获取记录)
server层与存储引擎层以记录为单位进行交互,server层执行器根据执行计划调用存储引擎层获取记录
二级索引存储索引列和主键的值,并以索引列、主键进行排序,有多个索引列时,前一个索引列相等时当前索引列才有序;聚簇索引存储整条记录的值,并以主键有序
当使用二级索引并且二级索引上的列不满足查询条件时,需要回表查询聚簇索引获取其他列的值;回表查询聚簇索引时主键值无序可能导致随机IO
索引条件下推在多查询条件的情况下,在存储引擎层多判断一次where其他查询条件,利用二级索引上的其他列判断记录是否满足其他查询条件,如果不满足则不用回表,减少回表次数
查询数据量大的情况下,回表的开销非常大,只有当二级索引存在的列满足查询需要的列时才不会回表,回表产生的随机IO要通过其他手段优化
最后(不要白嫖,一键三连求求拉~)
本篇文章被收入专栏 由点到线,由线到面,构建MySQL知识体系,感兴趣的同学可以持续关注喔
本篇文章笔记以及案例被收入 gitee-StudyJava、 github-StudyJava 感兴趣的同学可以stat下持续关注喔~
有什么问题可以在评论区交流,如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
关注菜菜,分享更多干货,公众号:菜菜的后端私房菜
本文由博客一文多发平台 OpenWrite 发布!