1、sklearn模型的保存和加载API
- from sklearn.externals import joblib
- 保存:joblib.dump(rf, ‘test.pkl’)
- 加载:estimator = joblib.load(‘test.pkl’)
2、决策树的模型保存加载案例
保存:
import joblib
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_20newsgroups, load_iris
from sklearn.tree import DecisionTreeClassifier, export_graphviz
"""
用决策树对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy", )
estimator.fit(x_train, y_train)
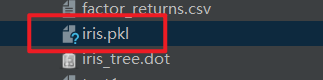
joblib.dump(estimator, 'iris.pkl')
会生成如下的文件:
加载:
model = joblib.load("iris.pkl")
print(model.predict(x_test))











![[Go版]算法通关村第十八关青铜——透析回溯的模版](https://img-blog.csdnimg.cn/a19b24e500e5437896611a6a21157ef3.png)