更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
文章介绍了 Bucket 优化技术及其在实际业务中的应用,包括 Spark Bucket 的基本原理,重点阐述了火山引擎湖仓一体分析服务 LAS(下文以 LAS 指代)Spark 对 Bucket 优化的功能增强, 实现了 Bucket 易用性的巨大提升,优化的覆盖范围得以扩大,且在字节内部已有成功应用案例。文中提及的能力增强在 LAS 上均可直接使用,欢迎大家到火山引擎官网进行体验和选购(点击前往),文末更有专属彩蛋,新人优惠购福利,等着你来解锁!
本篇文章提纲如下:
- Bucket 优化技术简介
- LAS bucket 增强
- Bucket 优化在字节内部的应用
- 总结
Bucket 优化技术简介
Bucket 优化是通过将数据进行分桶、排序来优化查询速度的一种技术。
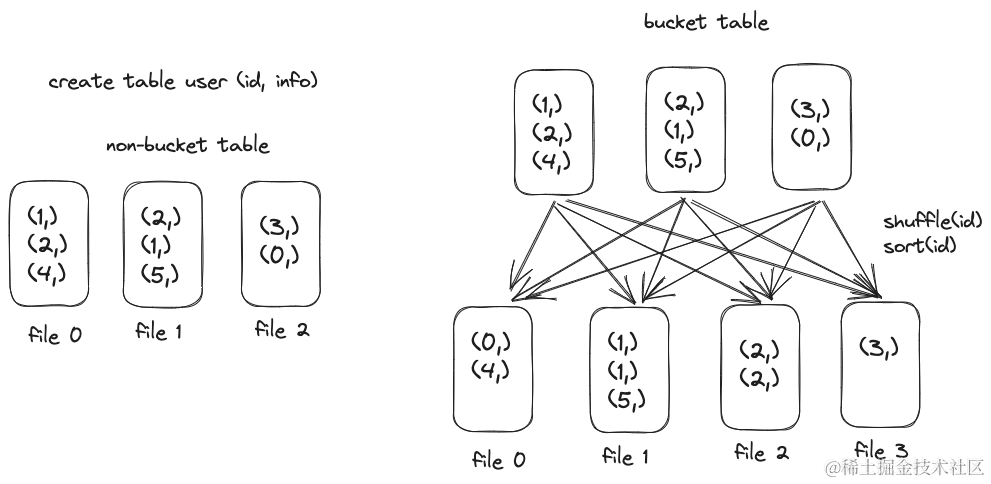
分桶是组织数据的一种方式,需要指定分桶字段、分桶数量;它对分桶字段的值进行哈希并取余,将余数相同的数据存在同一个分桶中。Bucket 表通过指定分桶字段、分桶数量、排序列,将写入的数据利用 Shuffle 分桶、桶内排序后再写入文件中。
Bucket 表创建语法如下,clustered by (id) 指定分桶列,sorted by (id)指定排序列,into 4 buckets ****指定分桶数量。
create table user(id Int, info String) clustered by (id) sorted by (id) into 4 buckets;
读、写 Bucket 表与非 Bucket 表的 SQL 语法一样,无需用户修改。
insert overwrite table user select id, info from ... where ...
前述 SQL 写出 bucket 表的执行计划如下,如果原本作业输出数据的分布不满足 Bucket 分桶要求的话,会引入一次额外的 Shuffle、Sort 开销。
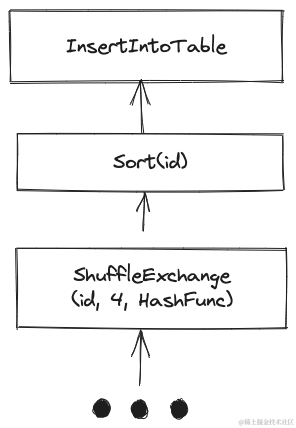
产出非 Bucket 表和 Bucket 表的示意图对比如下。
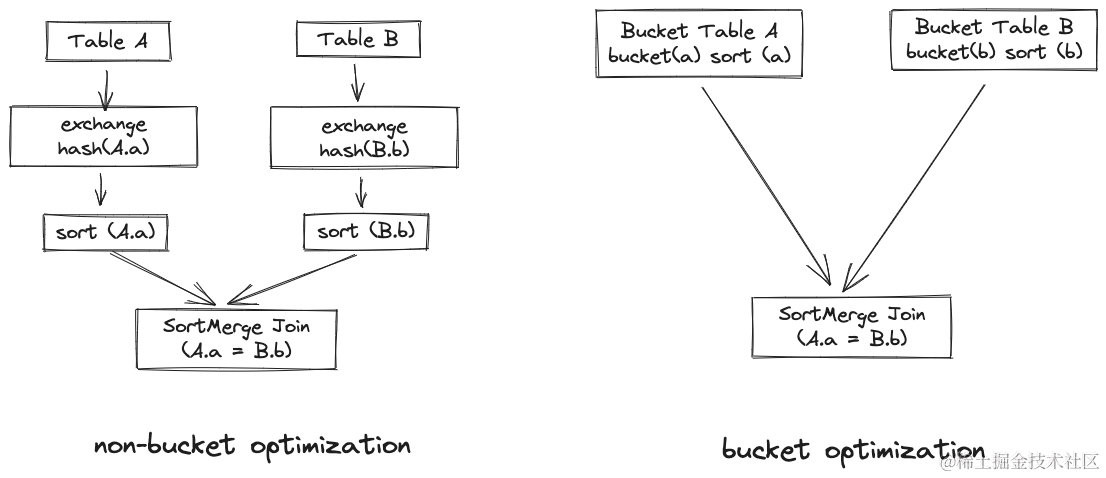
下游任务按照分桶列来 Join、Group By 或 Window 时可以省去一次 Shuffle 、Sort 的开销。下图分别展示了有、无 Bucket 优化时的 SortMerge Join 的执行计划;在有 Bucket 优化时,能够省掉 A、B 两表的 Shuffle 和 Sort。
LAS bucket 增强
结合实际业务场景,LAS Spark 团队进一步增强了 Spark 的 Bucket 优化:
- 兼容 Hive Bucket 优化,支持跨引擎读取
- 读、写 Bucket 表时,支持更多场景下的 Shuffle 消除
- 兼容历史非 Bucket 分区
- 支持分区级别设置分桶数
兼容 Hive Bucket 优化
数仓中的表可能会被多个计算引擎读取,目前字节内部同时支持 SparkSQL、Presto 两大 OLAP 引擎。为了让不同的计算引擎都能利用表的 Bucket 信息优化查询,需要对齐各个引擎的 Bucket 实现。下图展示了 Hive/Presto 写 Bucket 表与原生 Spark 写 Bucket 表对比。
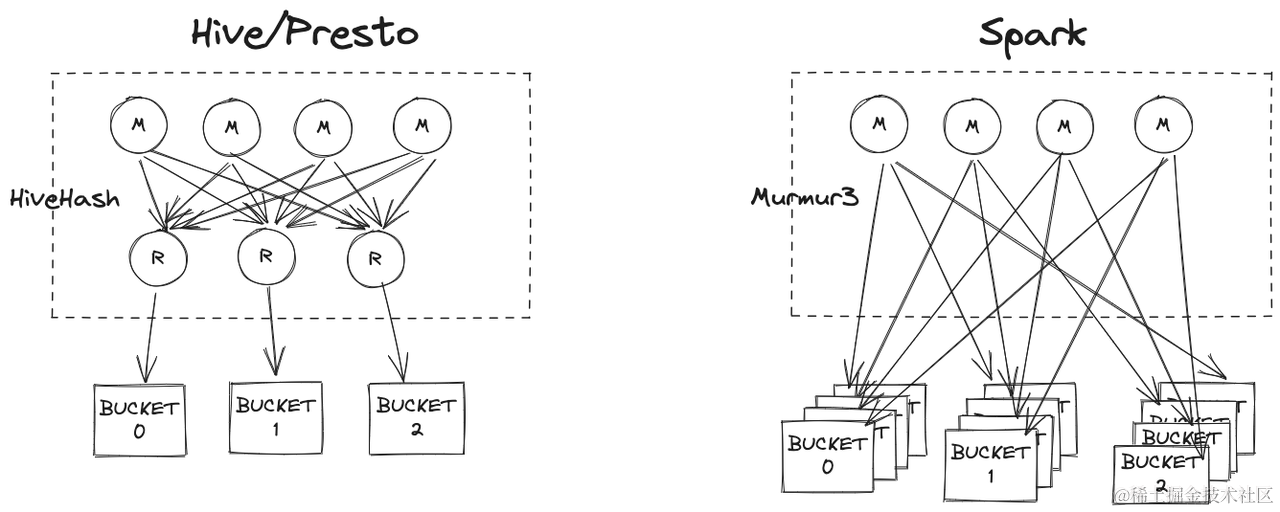
通过上图可以发现,Hive 在写 Bucket 表之前会将相同分桶的数据通过 reduce 操作写到一个文件中,而 Spark 原生 Bucket 优化并没有这一步,因此存在如下问题:
问题1 —— 过多小文件:Spark 写出 Bucket 表的原生实现是,在 mapper 端将数据写到文件当中,而每个 map task 中可能包含多个分桶的数据,最坏情况下会产生 MB 个文件,M 是 map task 数目,B 是分桶数。按照这个逻辑,每个分桶内的数据都被分成了 M 份,因此可能大部分都是小文件。当任务并发度为 1000、分桶数目为128 时,最坏情况下会产生 MB = 128000 个文件,如此多的文件数目会大大增加 HDFS NameNode 的压力,增加 HDFS 读取的延时。
问题2 —— 无法保证单个分桶内数据有序性:Spark 原生的 Bucket 表中,每个分桶下有多个文件,无法保证桶内数据有序,因此,在做 SortMerge Join 前仍然需要排序。
由于 Presto 支持兼容 Hive Bucket 优化、Spark 原生的 Bucket 优化存在前述两个问题,LAS Spark 团队最终选择让 Spark 兼容 Hive Bucket 优化。实现步骤如下
- 动态增加一次以分桶列为 reduce Key 并且并行度与分桶数目相同的 Shuffle,在数据写出前排序,保证同一个分桶内的数据只写一个文件、且桶内数据有序。
- 为 Spark 支持 HiveHash 的哈希函数,使其既能写出与 Hive 兼容的 Bucket 表,也能读取 Hive Bucket 表、并利用分桶信息消除 Shuffle。
支持更多场景下的 Shuffle 消除
Spark 要求只有分桶数目相同的 Bucket 表才能消除 ShuffledJoin 之前的 Shuffle。对于两张大小相差很大的表,比如几百 GB 的维度表与几十 TB (单分区)的事实表,它们的分桶个数往往不同,并且个数相差很多,默认无法消除 Join 前的 Shuffle。为了尽可能多地减少 Shuffle 带来的开销,LAS Spark 通过两种方式支持了消除分桶数成倍数关系的 Bucket 表在 Join 前的 Shuffle。
第一种方式,Task 个数与小表分桶个数相同。如下图所示,表 A 包含 3 个分桶,表 B 包含 6 个分桶。此时表 B 的 bucket 0 与 bucket 3 的数据合集应该与表 A 的 bucket 0 进行 Join。这种情况下,可以启动 3 个 Task。在 Task 0 中 Join 表 A 的 bucket 0 与表 B 的 bucket 0 + bucket 3 。在这里,需要对表 B 的 bucket 0 与 bucket 3 的数据再做一次 merge sort 从而保证合集有序。
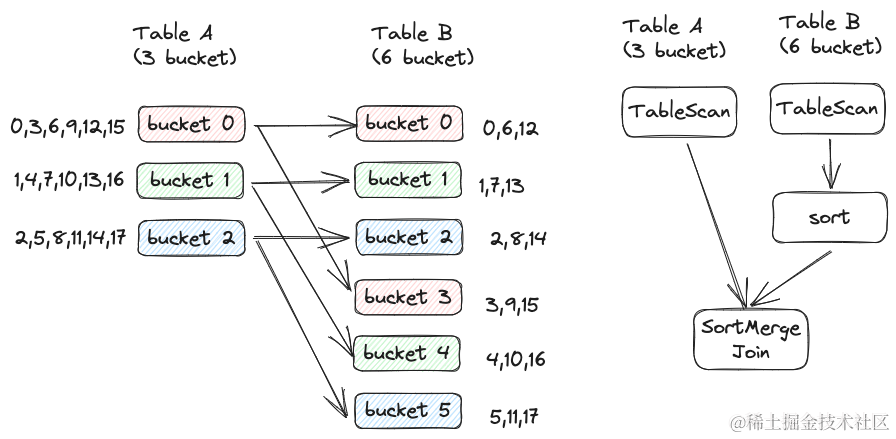
如果表 A 与表 B 的分桶个数相差不大,可以使用上述方式。如果表 B 的分桶个数是表 A 分桶个数的 10 倍,那上述方式虽然避免了 Shuffle,但可能因为并行度不够反而比包含 Shuffle 的 SortMerge Join 速度慢。此时可以使用另外一种方式,即 Task 个数与大表 Bucket 个数相等,如下图所示:
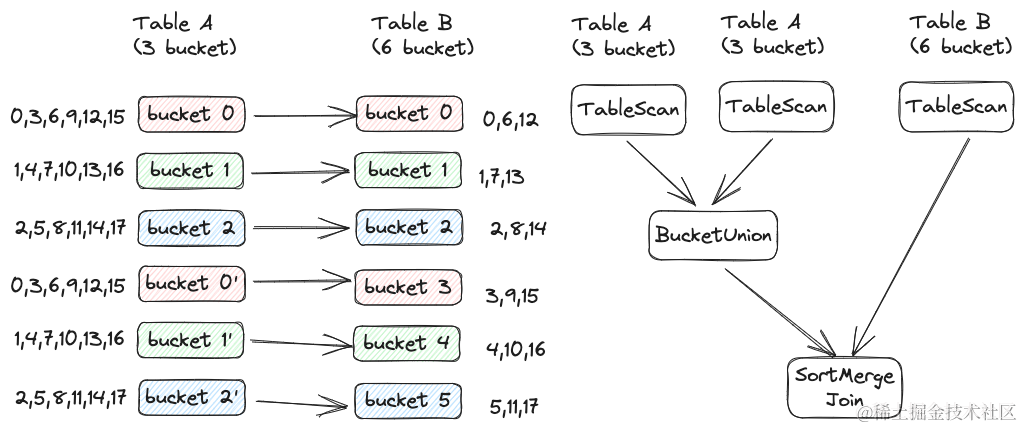
在该方案下,可将表 A 的 3 个分桶读多次。在上图中,直接将表 A 与表 A 进行 BucketUnion (新的算子,与 Union 类似,但保留了 Bucket 特性),结果相当于将表 A 设置成 6 个分桶,与表 B 的分桶个数相同。
对于一张常用表,可能会与另外一张表按 User 字段做 Join,也可能会与另外一张表按 User 和 App 字段做 Join,与其它表按 User 与 Item 字段进行 Join。而 Spark 原生的 Bucket 优化要求 Join Key Set 与表的分桶列完全相同才能消除 ShuffledJoin 之前的 Shuffle。在该场景中,不同 Join 的 Key Set 不同,因此无法同时使用 Bucket 优化。这极大的限制了 Bucket 优化的适用场景。
针对此问题,LAS Spark 团队支持了超集场景下的 Bucket 优化。只要 Join Key Set 包含了分桶列,即可进行消除 Shuffled Join 之前的 Shuffle。
如下图所示,表 X 与表 Y,都按字段 A 分桶。而查询需要对表 X 与表 Y 进行 Join,且 Join Key Set 为 A 与 B。此时,由于 A 相等的数据,在两表中的 Bucket ID 相同,那 A 与 B 各自相等的数据在两表中的 Bucket ID 肯定也相同,所以数据分布是满足 Join 要求的,不需要 Shuffle。同时,Bucket 优化还需要保证两表按 Join Key Set 即 A 和 B 排序,此时只需要对表 X 与表 Y 进行分区内排序即可。由于两边已经按字段 A 排序了,此时再按 A 与 B 排序,代价相对较低。
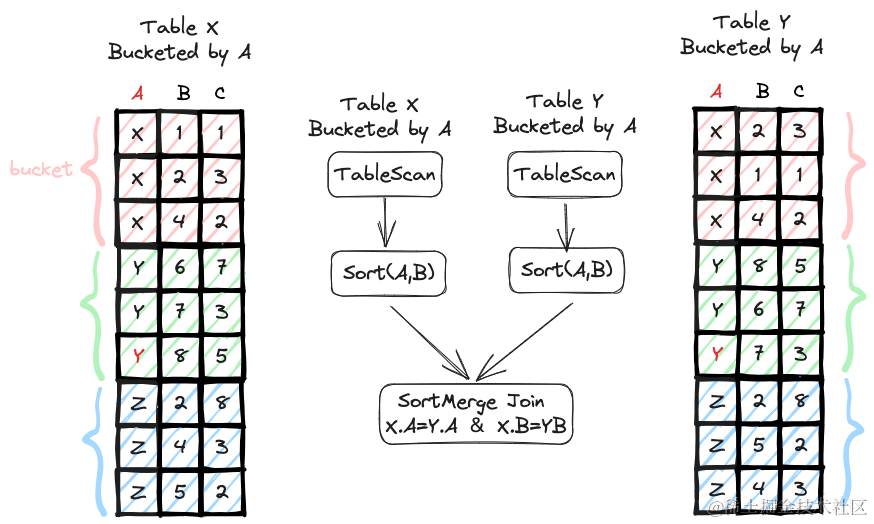
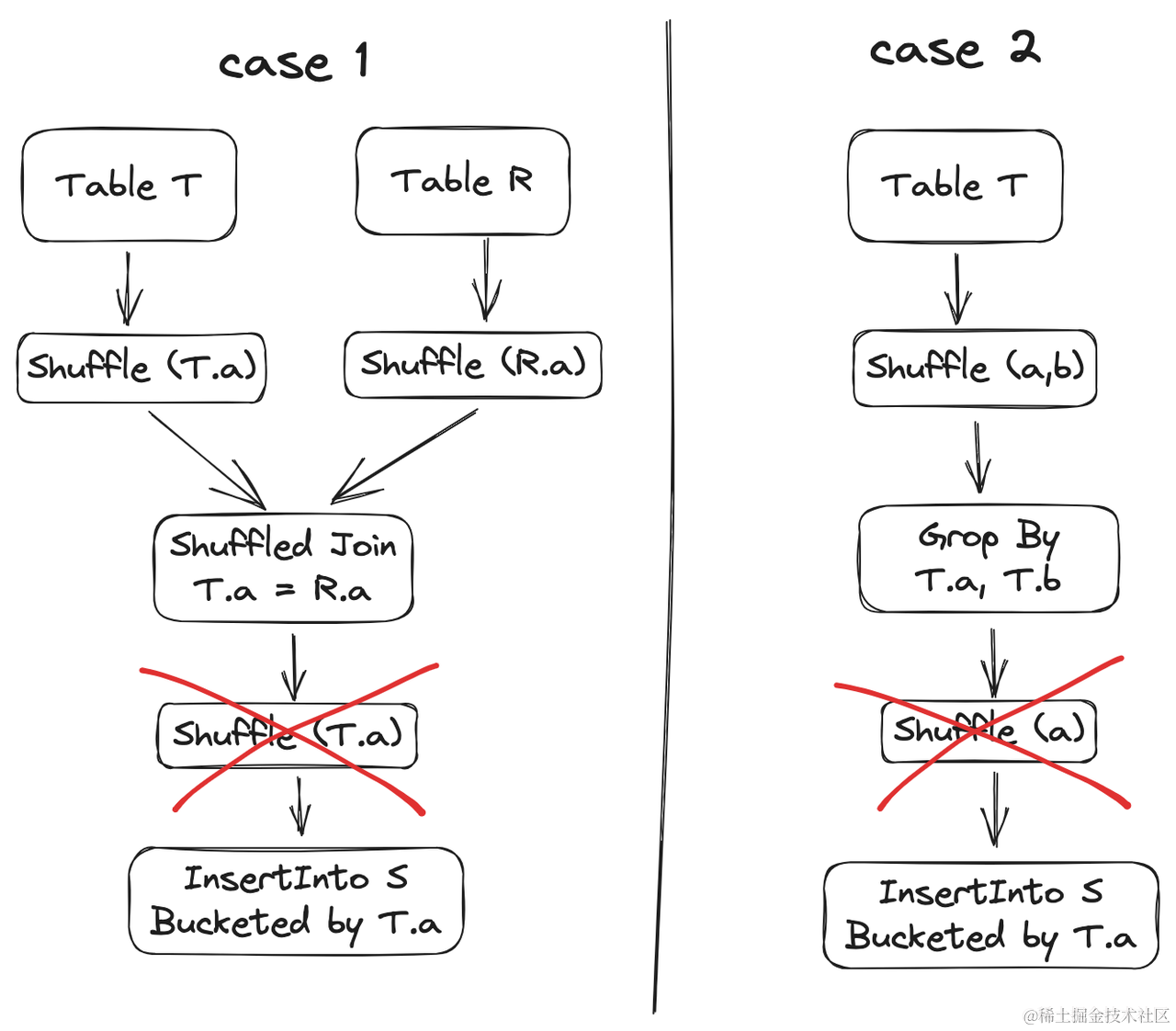
兼容 Hive Bucket 优化后,写入 Bucket 表前需要多一次 Shuffle。但是如果写出的数据分布满足分桶要求,则无需额外 Shuffle。LAS Spark 识别了两类这样的场景
- Case 1:当写入 Bucket 表的前一个算子为 Group By/Window/Inner Join/Left Join/Right Join 时,支持消除 Shuffle;在部分场景下,写入 Bucket 表的前一个算子为 Full Out Join 时也支持消除 Shuffle。前述说的 Join 都是指 Shuffled Join。
- Case 2:当且仅当写入 Bucket 表的前一个算子是 Group By时,支持写入超集 Shuffle 消除。
兼容历史非 Bucket 分区
在推进 Bucket 优化覆盖更多任务过程中,用户希望存量表也能通过改造利用到 Bucket 优化。如果直接向表的元信息中写入 Bucket 信息,在查询历史分区数据时会因为它们并未按 Bucket 表要求分布而报错。而存量表中历史数据量级比较大,按照 Bucket 分布重新生成一遍的开销过大,难以推进落地。为了解决以上问题,LAS Spark 团队扩展 了 SparkSQL 的语法,允许通过 DDL 修改表的属性,让表从某一刻开始支持变成 Bucket 表。
alter table tbl clustered by (a) sorted by (a) into 8 buckets;
前述 ddl 执行时会在表的元信息中记录 ddl 执行的日期、bucket 信息。后续写入数据时,会将数据进行 Shuffle 以符合 Bucket 分布;在进行 ShuffledJoin 时,先检查所查询的数据是否只包含 ddl 执行日期之后的分区。如果是,则当成 Bucket 表处理,支持 Bucket 优化;否则当成普通的表。
支持分区级别设置分桶数
由于数据量随业务增长而变多,这会造成单 Task 需要处理的数据量过大。因此,LAS Spark 支持了按分区级别来设置分桶数目,对于业务数据量大的分区,可以将分桶数目设置地更大,在减少 Shuffle 开销的同时提高并发度。
假设有一个被同一部门多条业务线使用的 Bucket 表,表级别定义分桶数目为 1024。
create table department (
user_id int ,
user_info string
) partitioned by ( date string, business string)
clustered by(user_id) sorted by(user_id) into 1024 buckets;
其中 business = ’ hot ’ 分区存储热门业务的数据,数据量大约是其他业务的 2 倍 。 LAS Spark 通过扩展 SparkSQL 的语法,支持为该分区设置更大的分桶数目,如下:
ALTER TABLE department PARTITION(business='hot') SET NUM_BUCKETS = 2048;
数据写入:在将数据写出到表中时,如果当前分区有分区级别的分桶数目信息,按照分区级别的分桶数写入数据;否则,按照表级别的分桶数目写出数据。
数据读取:
- 读取单个分区的情况比较好理解,读取时优先选择分区级别的分桶信息,如果没有的话再选择表级别分桶信息。
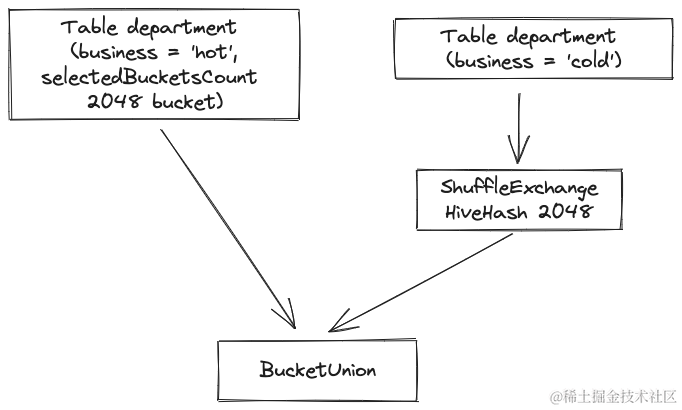
- 读取多个分区时,如果所有分区的分桶数一样,当成普通 Bucket 表;否则,最大分桶数目的分区会保留分桶信息,其余分区的数据会当成普通分区来读取。以下图为例,同时读取 department 表的 hot、cold 两个分区,前者是 2048 个分桶,后者是 1024 个分桶,读取分区时会保留 hot 分区的分桶信息、对 cold 分区数据进行 Shuffle,然后对两部分数据进行 BucketUnion (保留 Bucket 信息的 Union 算子),让 department 表看起来是分桶数为 2048 的 Bucket 表,后续能利用到 Bucket 优化。
Bucket 优化在字节内部的应用
业务背景
数据生产链路的稳定性尤为重要,一旦链路中的任务失败或延迟产出都会给业务带来诸多问题。以视频数据为例,视频数据的生产链路如果无法保障稳定性则会带来如下风险:
- SLA 破线风险高:数据量级大、消耗资源多、单次执行时间较长,一旦失败重跑很容易造成 SLA 破线;
- 运维成本高:容易造成夜间报警起夜,同时任务就绪时间严重延迟时,还需人工介入调度下游,以免队列阻塞。整个过程需消耗较多人力。
在字节内部的某条链路任务上,耗时长、风险高的过程主要是 Shuffle 环节。目前,任务的 Shuffle 数据量较大,因此命中各种问题节点的概率增大,经常遇到坏节点、慢节点等问题,导致 Shuffle失败。同时也易将 Shuffle Service 的节点打满,进而导致 Task 出现 Fetch Fail 情况重试,当重试超过 3 次时,整个 Spark Application 会被 Kill 掉。
Bucket 改造
通过对链路任务的逻辑分析,结合 Bucket 特性,对全链路应用了 Bucket 优化。这里的全链路是指,从 ODS 层一直到 DM 层。链路中只要能利用到 Bucket 特性,则均进行了改造;共将链路中超过半数的表改造成 Bucket 表。改造时,通过如下方法利用尽可能多的 Bucket 优化:
- 通过对链路中任务的分析,发现大部分 Join、Group By 操作的 key 中都共同包含了作品 ID,因此选择作品 ID 作为分桶列,使得 Join/Group By/Window 引入的 Shuffle 的 Key 是分桶列的超集,从而消除这些 Shuffle。
- 保证链路中上下游之间的分桶个数成倍数关系,从而消除所有可能的 Shuffle。具体来说,要求设置的分桶数目必须为 2 的次幂,这样就保证了不同 Bucket 表的分桶数目成倍数关系。
改造收益
经过全链路 Bucket 改造后,全链路层面收益如下 :
- 减少大任务 Shuffle : 消除了大表 Shuffle 问题,减少大量 Shuffle 数据。
- 链路运行稳定性提升:夜间生产链路无 Shuffle 失败问题。
单个任务层面的收益如下:
- 长尾 任务减轻: 单 Task 时间可平均缩短 20%。
- 资源节约: CPU 和内存资源可节约 10%-20%。
- 运行时长: 任务运行时长无额外增加,其中部分任务因长尾任务减轻,时长可缩短20%。
总结
在消除 Exchange、优化 Shuffle 量级上,Bucket 优化是一个很有效的技术手段,但是原生的 Spark Bucket 不支持存量表迁移、无法在数据量增长后扩容 Bucket 数量、优化覆盖场景也比较有限,针对以上场景 LAS Spark 团队做了一系列的改进,使得 Bucket 的易用性得到了很大的提升、并扩大了优化的覆盖范围,以上能力的增强在 LAS 上均可直接使用,欢迎大家积极试用并提出宝贵的意见和建议。
湖仓一体分析服务 LAS(Lakehouse Analytics Service)是面向湖仓一体架构的 Serverless 数据处理分析服务,提供字节跳动最佳实践的一站式 EB 级海量数据存储计算和交互分析能力,兼容 Spark、Presto 生态,帮助企业轻松构建智能实时湖仓。新人优惠来袭!赠送给所有新人用户的专属福利来啦, LAS 数据中台新人特惠 1 元秒杀活动最新上线!更有超多叠加优惠等你来抢! 感谢大家一直以来对我们的支持与厚爱,我们会一如既往地为您带来更好的内容。 (点击链接,可顺滑体验)
链接:zjsms.com/jVCr5bp/







![[H5动画制作基础]随机四位数值](https://img-blog.csdnimg.cn/a35d60ac469042dc9e204388b9758d93.png)