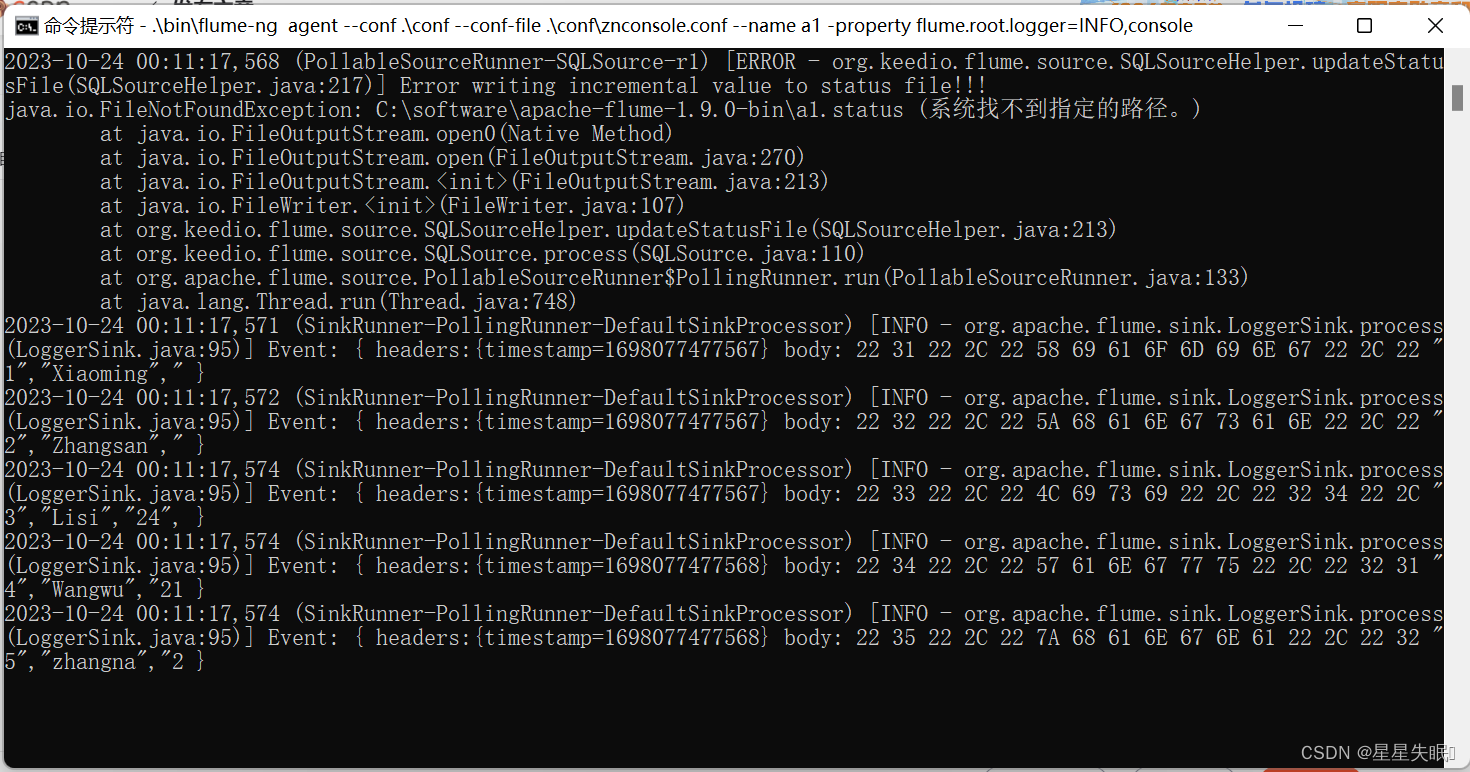
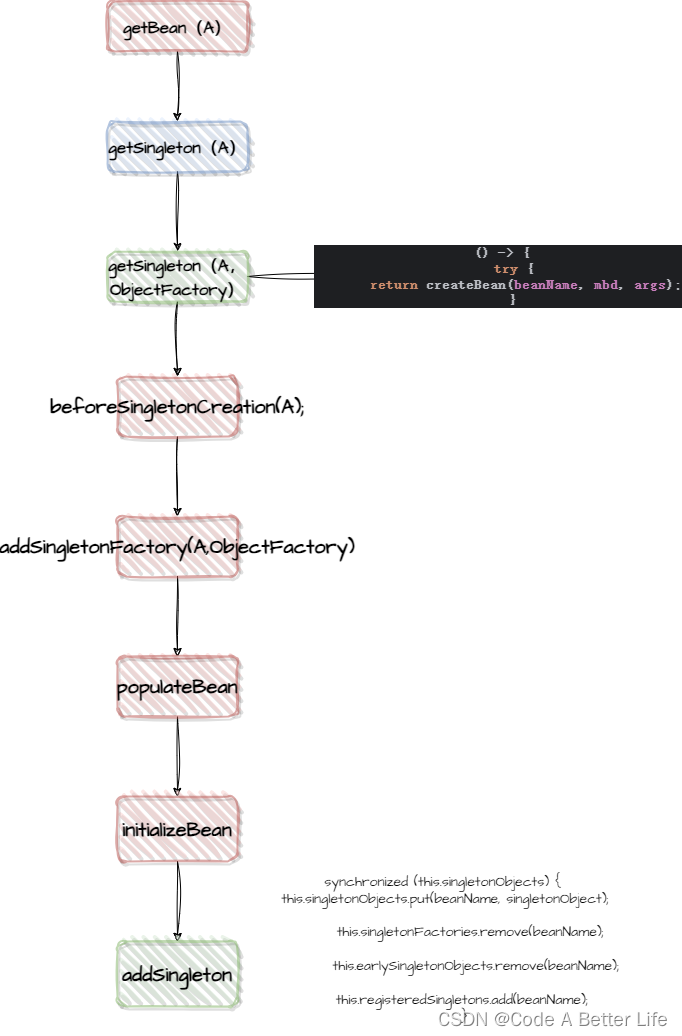
SocketBase类库主要是方便创建Socket客户端和Socket服务端的基础实现。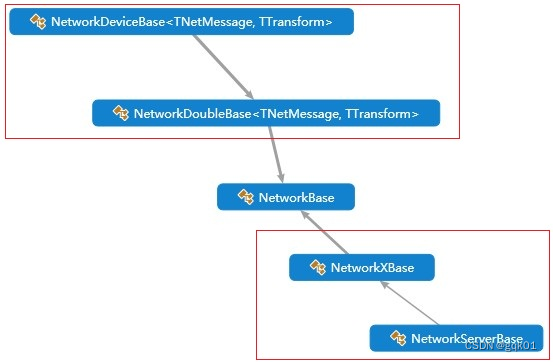
抽象基类:主要实现创建Socket
public abstract class NetworkBase{}通用基类:指定了消息的解析规则,指定了数据转换的规则 的基本实现
/// <summary>
/// 支持长连接,短连接两个模式的通用客户端基类
/// </summary>
/// <typeparam name="TNetMessage">指定了消息的解析规则</typeparam>
/// <typeparam name="TTransform">指定了数据转换的规则</typeparam>
public class NetworkDoubleBase<TNetMessage, TTransform> : NetworkBase
where TNetMessage : INetMessage, new()
where TTransform : IByteTransform, new()
{}
设备读写基类:
/// 设备类的基类,提供了基础的字节读写方法
public class NetworkDeviceBase<TNetMessage, TTransform> : NetworkDoubleBase<TNetMessage, TTransform> , IReadWriteNet where TNetMessage : INetMessage, new() where TTransform : IByteTransform, new()
{}
服务器程序的基础类:包含了主动异步接收的方法实现和文件类异步读写的实现基类:
public class NetworkXBase : NetworkBase{}
public class NetworkServerBase : NetworkXBase{}常用Socket服务器基类:
/// 文件服务器类的基类,为直接映射文件模式和间接映射文件模式提供基础的方法支持
public class NetworkFileServerBase : NetworkServerBase{}
/// 异形客户端的基类,提供了基础的异形操作
public class NetworkAlienClient : NetworkServerBase{}
/// 发布订阅服务器的类,支持按照关键字进行数据信息的订阅
public class NetPushServer : NetworkServerBase{}
/// 同步消息处理服务器
public class NetSimplifyServer : NetworkServerBase{}
/// 用于服务器支持软件全自动更新升级的类
public sealed class NetSoftUpdateServer : NetworkServerBase{}
// 终极文件管理服务器,实现所有的文件分类管理,读写分离,不支持直接访问文件名
public class UltimateFileServer : NetworkFileServerBase{}常用Socket客户端基类:
//与服务器文件引擎交互的客户端类,支持操作Advanced引擎和Ultimate引擎
public abstract class FileClientBase : NetworkXBase{}
public class IntegrationFileClient : FileClientBase{}
//发布订阅
public class NetPushClient : NetworkXBase{}
//异步访问数据的客户端类
public class NetSimplifyClient : NetworkDoubleBase<HslMessage, RegularByteTransform>{}
//西门子PLC
public class SiemensS7Net : NetworkDeviceBase<SiemensS7Message, ReverseBytesTransform>{}
public class SiemensPPI : SerialDeviceBase<ReverseBytesTransform>{}
public class SiemensFetchWriteNet : NetworkDeviceBase<SiemensFetchWriteMessage, ReverseBytesTransform>{}
//松下PLC
public class PanasonicMewtocol : SerialDeviceBase<RegularByteTransform>{}
//欧姆龙PLC
public class OmronFinsNet : NetworkDeviceBase<OmronFinsMessage,ReverseWordTransform>{}
//三菱PLC
public class MelsecMcNet : NetworkDeviceBase<MelsecQnA3EBinaryMessage, RegularByteTransform>{}
public class MelsecMcAsciiNet : NetworkDeviceBase<MelsecQnA3EAsciiMessage, RegularByteTransform>{}
public class MelsecFxSerial : SerialDeviceBase<RegularByteTransform>{}
public class MelsecFxLinks : SerialDeviceBase<RegularByteTransform>{}
public class MelsecA1ENet : NetworkDeviceBase<MelsecA1EBinaryMessage, RegularByteTransform>{}
客户端和服务器端必须使用相同的 消息解析规则和数据转换规则要不然解析不通过。
整体框架说明
整个框架的项目结构如下: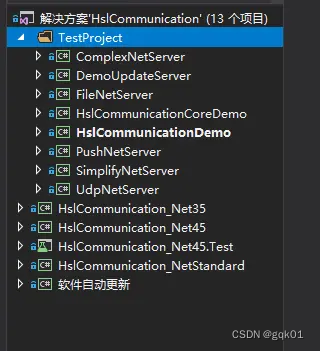
首先文件夹 TestProject 里面的项目都是一些 demo 项目,当然最重要的就是 HslCommunicationDemo 项目了。就是最上面的 demo 项目的截图,Hsl 具体能干什么可以参照这个。
本项目使用了三个框架的项目,也就是说,本项目提供 dll 文件包含了三个框架版本:
- .net framework 3.5
- .net framework 4.5
- .net standard 2.0
维护三份源代码显然是什么痛苦的,所以我采用了维护一份源代码,也就是 .Net 4.5 的代码,其他两个项目引用.net 4.5 的代码,如果有不一致的地方,就用预编译指令进行区分。例如在 modbusserver 类中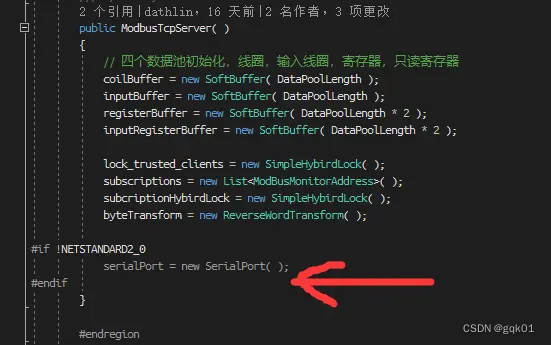
而 HslCommunication_Net45.Test 项目是一个单元测试项目,包含了一些代码类的测试,还有示例代码的编写。所以我们的重点来看看 .net 4.5 的项目即可,整体的结构如下图: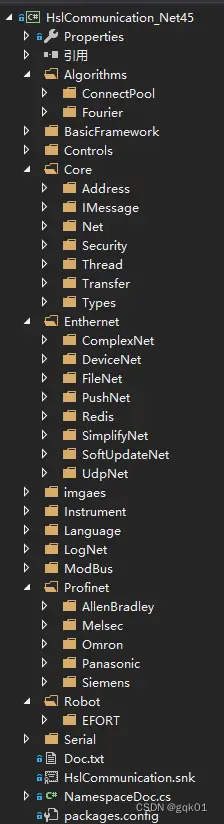
BasicFramework 放些了一些基于的小工具的类,比如 SoftBasic 提供了大量小的静态辅助方法,帮助你快速开发实现一些基础的小功能的。
Core 里放置了一些本项目的核心代码,所有网络通信类的基础类,基础功能实现都在 Core 里。
Enthernet 里放置了一些高级程序语言之间的通信,比如两个 exe 间通信,或是局域网两台电脑通信,或是多个电脑程序通信。
LogNet 是实现了本项目的日志工具,可以方便的存储日志信息。
ModBus 实现了基于网络的 modbus-tcp 协议,modbus-rtu 协议,modbus-server,modbus-ascii 协议的通信。
Profinet 实现了三菱,西门子,欧姆龙,松下,ab plc 的数据通信。
OperateResult 类说明
这个类为什么拿出来出来说呢?因为这个类贯穿了 HSL 整个项目,是本开源项目的思想之一。对这个类的理解,和对于本项目的理解至关重要。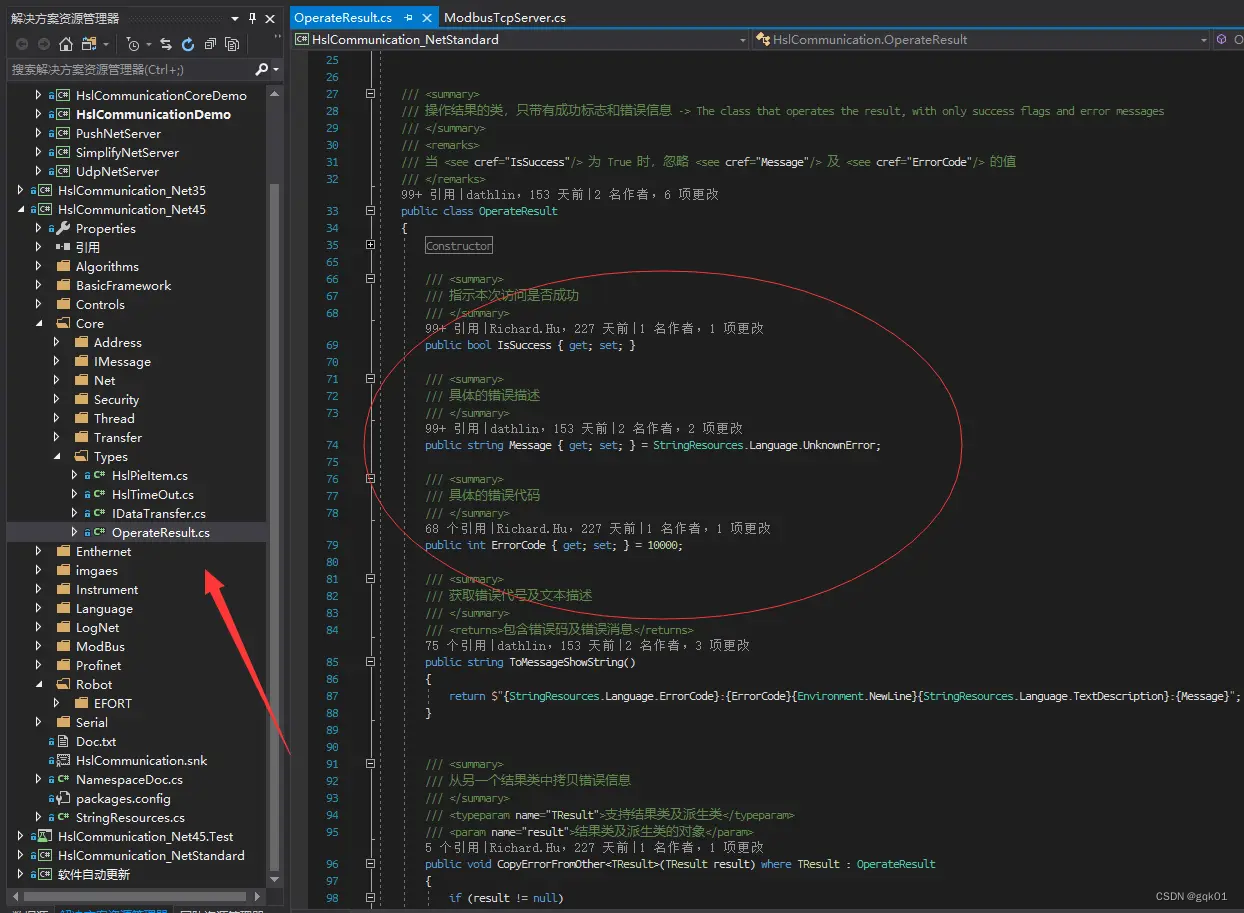
左边也即是这个类的位置,右边是这个类的定义,在项目最初的开发阶段,我遇到了一个问题,这也是软件开发过程中大家都会遇到的问题,比如我要实现一个读取 PLC 一个数据的操作,读取成功了自然皆大欢喜,如果读取失败了呢?
我如何将读取失败,或是写入失败,或是操作失败的信息传递给调用者呢?除了失败的信息之外,应该还要包含一个为什么失败的信息,PLC 本身的失败会返回一个错误码,那就也需要一个错误码。所以就有了 OperateResult 的雏形:
/// <summary>
/// 指示本次访问是否成功
/// </summary>
public bool IsSuccess { get; set; }
/// <summary>
/// 具体的错误描述
/// </summary>
public string Message { get; set; } = StringResources.Language.UnknownError;
/// <summary>
/// 具体的错误代码
/// </summary>
public int ErrorCode { get; set; } = 10000;于是就有了上面的三个属性内容,但是这时候还有一点需要注意,返回的结果对象应该是可以带内容的,比如你读取了一个 int 数据,应该带一个 int 的结果,读取了一个 short 的数据,就应该带一个 short 类型的数据,如果需要这个结果对象支持多类型的内容的话,查了查书,发现有个泛型的功能刚好合适,但是之后又发现,万一我想要带 2 个不同类型的结果对象时,那怎么办?这时候就需要定义多个不同类型的 OperateResult 类型了。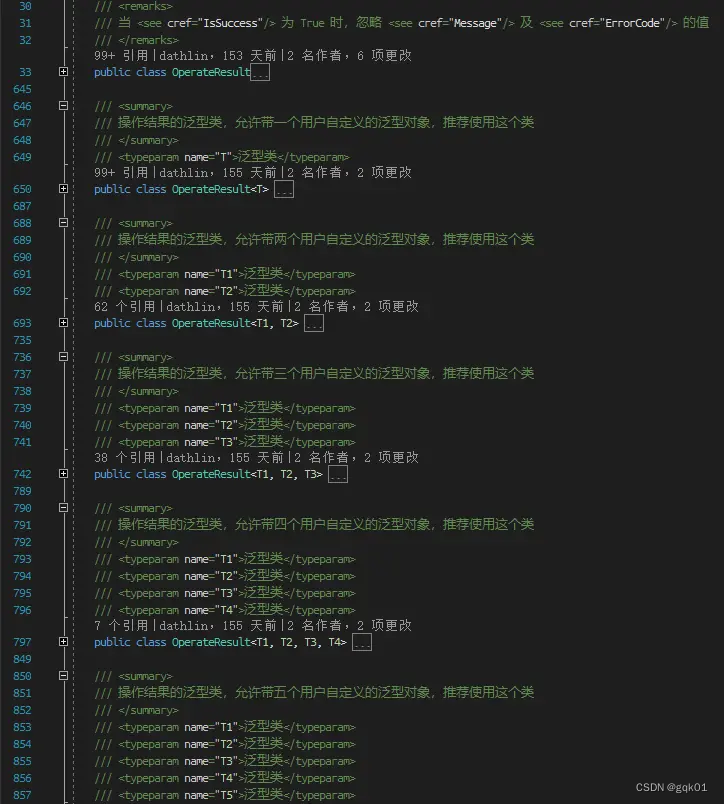
此处定义多达十个的泛型对象,满足绝大多数的情况请用。这个类型对象除了能返回带有错误信息的结果对象之外,还允许进行结果路由,我们来看看这个项目里的一个方法:
/// <summary>
/// 使用底层的数据报文来通讯,传入需要发送的消息,返回最终的数据结果,被拆分成了头子节和内容字节信息
/// </summary>
/// <param name="socket">网络套接字</param>
/// <param name="send">发送的数据</param>
/// <returns>结果对象</returns>
/// <remarks>
/// 当子类重写InitializationOnConnect方法和ExtraOnDisconnect方法时,需要和设备进行数据交互后,必须用本方法来数据交互,因为本方法是无锁的。
/// </remarks>
protected OperateResult<byte[], byte[]> ReadFromCoreServerBase(Socket socket, byte[] send )
{
LogNet?.WriteDebug( ToString( ), StringResources.Language.Send + " : " + BasicFramework.SoftBasic.ByteToHexString( send, ' ' ) );
TNetMessage netMsg = new TNetMessage
{
SendBytes = send
};
// 发送数据信息
OperateResult sendResult = Send( socket, send );
if (!sendResult.IsSuccess)
{
socket?.Close( );
return OperateResult.CreateFailedResult<byte[], byte[]>( sendResult );
}
// 接收超时时间大于0时才允许接收远程的数据
if (receiveTimeOut >= 0)
{
// 接收数据信息
OperateResult<TNetMessage> resultReceive = ReceiveMessage(socket, receiveTimeOut, netMsg);
if (!resultReceive.IsSuccess)
{
socket?.Close( );
return new OperateResult<byte[], byte[]>( StringResources.Language.ReceiveDataTimeout + receiveTimeOut );
}
LogNet?.WriteDebug( ToString( ), StringResources.Language.Receive + " : " +
BasicFramework.SoftBasic.ByteToHexString( BasicFramework.SoftBasic.SpliceTwoByteArray( resultReceive.Content.HeadBytes,
resultReceive.Content.ContentBytes ), ' ' ) );
// Success
return OperateResult.CreateSuccessResult( resultReceive.Content.HeadBytes, resultReceive.Content.ContentBytes );
}
else
{
// Not need receive
return OperateResult.CreateSuccessResult( new byte[0], new byte[0] );
}
} 我们看到,方法里面的错误信息,可以由结果路由进行层层上传,最终抛给调用者,代码里需要做的就是发生错误的时候处理好后续的逻辑即可。这个类提供了几个静态方法快速的处理结果路由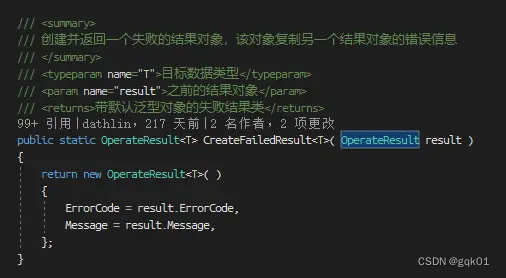

通讯核心说明
讲完了结果路由再来说说,整个网络类的核心在于 NetworkBase 类,在项目的开发过来中,尤其是开发了几个不同的 PLC 和 C# 程序之间的服务器客户端通信之后,发现有些底层代码是有些重复的,所以经过不断的提炼代码形成了所有网络的底层基类,这个类呢,只是提供了一个 socket 相关通用的操作逻辑,比如,创建并连接的 socket 对象,接收指定长度的数据,发送字节数据,关闭,接收流,发送流等等操作。
这个类实现了基础的字节收发功能和连接断开功能。接下来就是 NetworkDoubleBase 类的实现,实现了长短连接的操作,在我们实际读写设备的过程中,网络状况往往是差别很大,所以本项目的初衷就是同时支持长连接和短连接。根据大家需求的不同,
所谓的短连接是读取的时候再连接,读取完成就关闭连接。缺点就是连接打开和关闭耗时,影响读取速率,优点就是对网络状况反馈即使,读取失败了就说明网络断了,适合频率较低的读写。
长连接就是读取开始前连接一次,就不再关闭,进行频繁的读取,最后再关闭,好处当然是高速了,缺点就是网络状况不是那么好的时候,效率比较低下,对网络状况反应也不及时。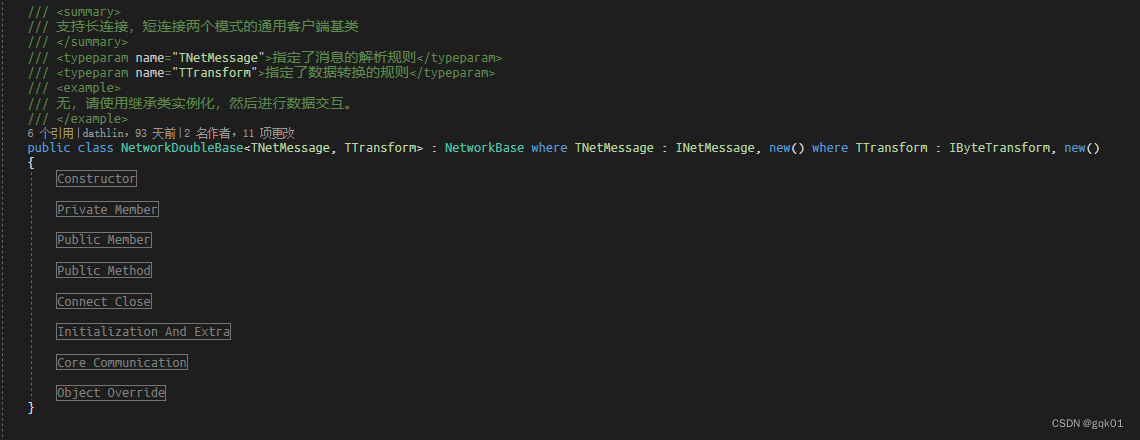
短连接就是直接的实例化,然后读取写入操作,每一次操作都是一次完整的通信过程。
切换长连接有两种办法,效果是一致的,
1. 对象读写前调用 ConnectServer ();
2. 对象读写前调用 SetPersistentConnection ( );
这两个方法都是双模式类里支持并实现的。所有的派生类都符合这个调用机制。
实现了长短的连接后,还要实现设备的 BCL 类型的读写,本质是基于 byte 数组和 C# 基础类型的转换,但是这里有个问题,不同的 PLC,modbus 协议对于转换的格式不是固定的,有可能是一样的,有可能不是一样的,所以又抽象出来一个 IByteTransform 接口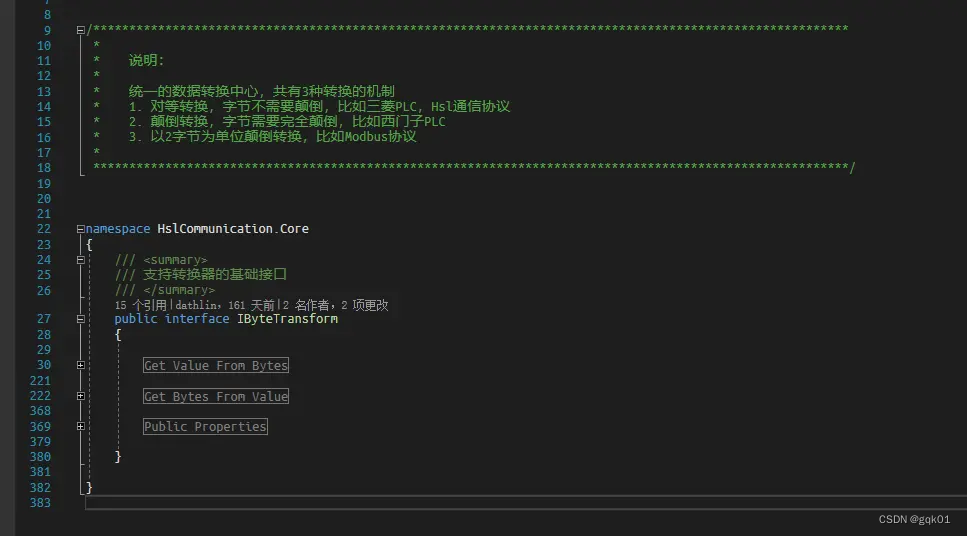
这个接口集成到了下面的设备交互的基类 NetworkDeviceBase 里,这个基类实现了一些基础的类型的数据读写。
所以到这里可以看到,从 NetworkDeviceBase 类继承出去的设备类(大部分的设备通信协议都是从这个继承出去的),其基本的读写代码都是一致的,关于解析协议,通信的底层都是封装完毕,
通讯举例说明
先举例说明三菱 PLC 的读写操作:
// 实例化对象,指定PLC的ip地址和端口号
MelsecMcNet melsecMc = new MelsecMcNet( "192.168.1.110", 6000 );
// 连接对象
OperateResult connect = melsecMc.ConnectServer( );
if (!connect.IsSuccess)
{
Console.WriteLine( "connect failed:" + connect.Message );
return;
}
// 举例读取D100的值
short D100 = melsecMc.ReadInt16( "D100" ).Content;
melsecMc.ConnectClose( );经过层层封装后,读写的逻辑精简为,实例化,连接,读写,关闭。无论是三菱的 PLC,还是西门子的 PLC,都是一致的,因为基类的模型都是一致的。
// 实例化对象,指定PLC的ip地址和端口号
SiemensS7Net siemens = new SiemensS7Net( SiemensPLCS.S1200, " 192.168.1.110" );
// 连接对象
OperateResult connect = siemens.ConnectServer( );
if (!connect.IsSuccess)
{
Console.WriteLine( "connect failed:" + connect.Message );
return;
}
// 举例读取M100的值
short M100 = siemens.ReadInt16( "M100" ).Content;
siemens.ConnectClose( );当然,支持大多数的 C# 类型数据读写
MelsecMcNet melsec_net = new MelsecMcNet( "192.168.0.100", 6000 );
// 此处以D寄存器作为示例
short short_D1000 = melsec_net.ReadInt16( "D1000" ).Content; // 读取D1000的short值
ushort ushort_D1000 = melsec_net.ReadUInt16( "D1000" ).Content; // 读取D1000的ushort值
int int_D1000 = melsec_net.ReadInt32( "D1000" ).Content; // 读取D1000-D1001组成的int数据
uint uint_D1000 = melsec_net.ReadUInt32( "D1000" ).Content; // 读取D1000-D1001组成的uint数据
float float_D1000 = melsec_net.ReadFloat( "D1000" ).Content; // 读取D1000-D1001组成的float数据
long long_D1000 = melsec_net.ReadInt64( "D1000" ).Content; // 读取D1000-D1003组成的long数据
ulong ulong_D1000 = melsec_net.ReadUInt64( "D1000" ).Content; // 读取D1000-D1003组成的long数据
double double_D1000 = melsec_net.ReadDouble( "D1000" ).Content; // 读取D1000-D1003组成的double数据
string str_D1000 = melsec_net.ReadString( "D1000", 10 ).Content; // 读取D1000-D1009组成的条码数据
// 读取数组
short[] short_D1000_array = melsec_net.ReadInt16( "D1000", 10 ).Content; // 读取D1000的short值
ushort[] ushort_D1000_array = melsec_net.ReadUInt16( "D1000", 10 ).Content; // 读取D1000的ushort值
int[] int_D1000_array = melsec_net.ReadInt32( "D1000", 10 ).Content; // 读取D1000-D1001组成的int数据
uint[] uint_D1000_array = melsec_net.ReadUInt32( "D1000", 10 ).Content; // 读取D1000-D1001组成的uint数据
float[] float_D1000_array = melsec_net.ReadFloat( "D1000", 10 ).Content; // 读取D1000-D1001组成的float数据
long[] long_D1000_array = melsec_net.ReadInt64( "D1000", 10 ).Content; // 读取D1000-D1003组成的long数据
ulong[] ulong_D1000_array = melsec_net.ReadUInt64( "D1000", 10 ).Content; // 读取D1000-D1003组成的long数据
double[] double_D1000_array = melsec_net.ReadDouble( "D1000", 10 ).Content; // 读取D1000-D1003组成的double数据写入的操作:
MelsecMcNet melsec_net = new MelsecMcNet( "192.168.0.100", 6000 );
// 此处以D寄存器作为示例
melsec_net.Write( "D1000", (short)1234 ); // 写入D1000 short值 ,W3C0,R3C0 效果是一样的
melsec_net.Write( "D1000", (ushort)45678 ); // 写入D1000 ushort值
melsec_net.Write( "D1000", 1234566 ); // 写入D1000 int值
melsec_net.Write( "D1000", (uint)1234566 ); // 写入D1000 uint值
melsec_net.Write( "D1000", 123.456f ); // 写入D1000 float值
melsec_net.Write( "D1000", 123.456d ); // 写入D1000 double值
melsec_net.Write( "D1000", 123456661235123534L ); // 写入D1000 long值
melsec_net.Write( "D1000", 523456661235123534UL ); // 写入D1000 ulong值
melsec_net.Write( "D1000", "K123456789" ); // 写入D1000 string值
// 读取数组
melsec_net.Write( "D1000", new short[] { 123, 3566, -123 } ); // 写入D1000 short值 ,W3C0,R3C0 效果是一样的
melsec_net.Write( "D1000", new ushort[] { 12242, 42321, 12323 } ); // 写入D1000 ushort值
melsec_net.Write( "D1000", new int[] { 1234312312, 12312312, -1237213 } ); // 写入D1000 int值
melsec_net.Write( "D1000", new uint[] { 523123212, 213,13123 } ); // 写入D1000 uint值
melsec_net.Write( "D1000", new float[] { 123.456f, 35.3f, -675.2f } ); // 写入D1000 float值
melsec_net.Write( "D1000", new double[] { 12343.542312d, 213123.123d, -231232.53432d } ); // 写入D1000 double值
melsec_net.Write( "D1000", new long[] { 1231231242312,34312312323214,-1283862312631823 } ); // 写入D1000 long值
melsec_net.Write( "D1000", new ulong[] { 1231231242312, 34312312323214, 9731283862312631823 } ); // 写入D1000 ulong值这里举例了三菱的 PLC,实际上各种 PLC 的操作都是类似的。
Redis 实现
除了上述的基本的设备通信,还实现了 redis 数据库读写操作,分了两个类实现,下图为一般的通信功能
同时 demo 中实现了一个浏览 redis 服务器的界面功能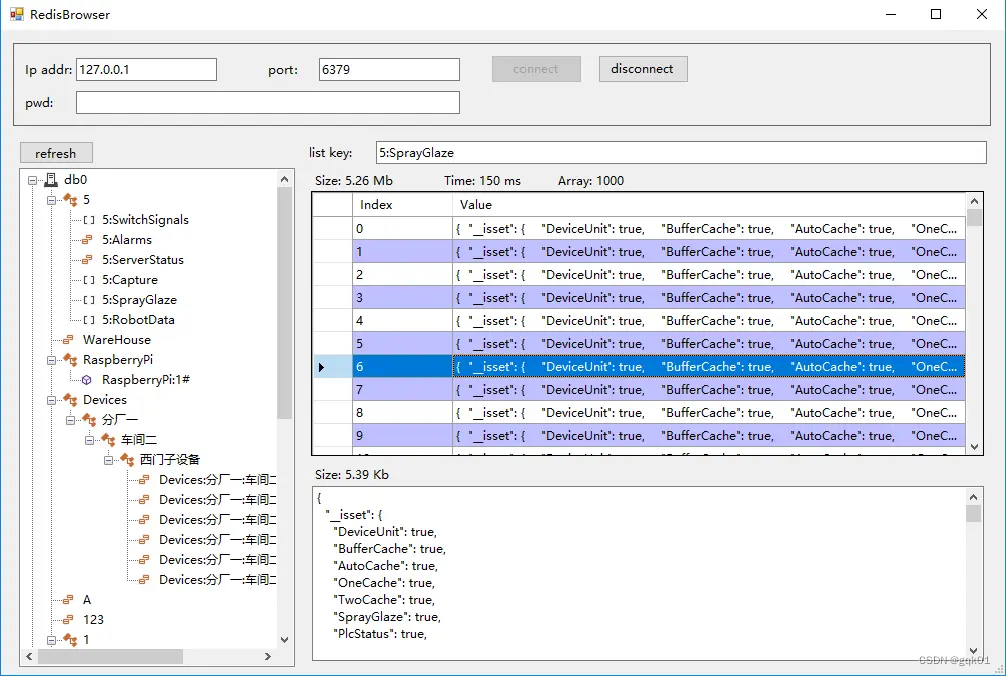
本通信库实现了.net 3.5 和 .net 4.5 的框架,还附带了一些简单的控件,此外还实现了.net standard 版本,已在 linux 测试成功,由于官方在.net core2.2 中还未实现串口类,所以暂时没有实现串口相关的。
未来的方向,希望继续优化代码,架构,集成实现更多设备通信,方便广大的网友直接开发测试。
就比如上面生成的exe程序,它到底是什么玩意,我想很多人都会疑问,刚学习C#的我也是这样。
- 我们首先在VS中写了很多的代码,点击生成或是调试的时候,IDE使用了C#编译器将我们写的所有的代码编译成了一种中间语言IL语言,写入到了生成的exe中。
- 可以想想看exe包含了什么东西,我们在上述的项目中定义了新的类Form1,那么这些类系统又不提供,所以肯定会把类写入到exe中,只要是自定义的类肯定会写入进去。
- 我们可以猜测exe文件应该还有个文件头,来标识这是一个可执行的Win32程序,我们在创建项目时可以选择.NET版本,应该还包含了环境版本
到这里我们的猜测已经非常的接近事实的情况了, 所以当我们点击exe程序的时候,windows到底干了什么东西。
首先windows会检查exe文件的文件头,检查程序类型是不是PE32文件头还是PE32+文件头的,这个文件头要求程序的运行环境,是不是32位,还是64位的,如果和操作系统不匹配,则不会运行,检查.NET 的版本号。
windows检查完exe后,检查合格后,接下来就要创建程序需要运行的进程空间了,在进程的地址空间加载MSCorEE.dll(一个.NET framework自带的链接库,可以在安装目录找到)。
MSCorEE.dll的用处非常大,进程的主线程会调用组件的方法来初始化运行的CLR,然后加载exe的数据(就是中间语言IL代码,包含了所有的类型说明和数据,即使加载了,还是IL代码,还不不能直接运行的,如果你的exe还引用了其他的dll,那么所有的关联的dll都会加载进来)。
然后MSCorEE.dll组件调用Main方法,这个和我们大学学的C语言是一致的,但是问题出现了,我们上面说过这时候CLR加载的还是IL代码,IL代码又不能直接运行,所以CLR内部的JITCompiler方法就出来干活了,工作是将IL代码编译成本机的CPU指令,这样操作后Main方法才可以真正的运行,如果Main方法调用了其他方法(这不是废话么),那么JITCompiler又出来工作了,如果每次调用方法,都要重新编译一次,那么应用程序的性能就非常差了,所以CLR使用了缓存的机制,所有的方法只有在第一次调用的时候存在一点性能损耗,以后调用就直接使用了本地指令。
绕着这么多的弯路,终于窗体运行了,展示给你看了,汗颜-------
数据的本质
我们已经非常习惯的使用基本的数据类型,比如bool,byte,short,ushort,int,uint,long,ulong,float,double,string等等,这就是常用的大部分类型。比如我们写了int i=0;那么请你用二进制来表示这个数据,一般只要学习过计算机原理的人都比较容易就可以写出0000_0000_0000_0000_0000_0000_0000_0000,因为是32位的数据,所以必须这么写,这还是相对好理解的,如果是-1呢,学过计算机的都知道,通常在计算机中,负数采用补码的形式来存储,也就是1111_1111_1111_1111_1111_1111_1111_1111,为什么会是这个数据,一定要搞清楚,因为这个数据+1=0,而且更关键的是,这个二进制的数据只有在int下面才表示-1,如果是uint呢,表示多少?就是2^32-1,所以我们可以得出结论,相同的数据在不同的类型下,表示的数据是不一样的。
所以说,类型是什么?类型规定了生成和解析数据的规则,以便我们得到准确的数据,再比如float类型
1 float i = 1; 2 int j = BitConverter.ToInt32(BitConverter.GetBytes(i), 0);
这两行代码就是将float的i的真实数据byte[],用int去解析的话会得到什么,j=1065353216;这个数据和原来的1真是风马牛不相及啊。因为整数的存储机制我们还算比较好理解的,但是计算机只有0和1,想要存小数确实挺困难的,所以采用了一个整数+一个指数的方式来存储,比如0.1=1*10^(-1),那么0.1就可以用坐标(1,-1)来标识,想要更深入的了解浮点数的存储规则,可以查看相关的知识。
下面来看一个实际的基本应用,在实际的开发中,我们会碰到一些问题,比如数据的简单存储,我们需要将数据存储到本地的一个文件中,一般的C#教程上都只是介绍了txt文件的读写,并没有针对实际开发提出有用的见解。所以此处我们假设我们需要存储10000个数据,没有数据都是0-100的整数,刚开始学习编程的时候比较容易想到下面的方法:
![]()
1 //生成一个随机0-100的10000个数据
2 int[] data = new int[10000];
3 Random r = new Random();
4 for (int i = 0; i < 10000; i++)
5 {
6 data[i] = r.Next(0, 101);
7 }
8
9
10 System.IO.StreamWriter sw = new System.IO.StreamWriter(@"D:\123.txt", false, Encoding.Default);
11 for (int i = 0; i < 10000; i++)
12 {
13 sw.WriteLine(data[i]);
14 }
15 sw.Dispose();
![]()
读取数据的时候就反其道而行,一行行的读取,读取一行就将字符串转化成int,这种方式读取比较慢,而且数据存储浪费了硬盘空间,我们查看这个文件的大小发现,

还是占了38.1KB(这个是实际的数据,占用空间是指数据消耗掉的容量)的数据,以下是经过改良的版本:
1 System.IO.FileStream fs = new System.IO.FileStream(@"D:\123.txt", System.IO.FileMode.Create);
2 for (int i = 0; i < 10000; i++)
3 {
4 fs.WriteByte(BitConverter.GetBytes(data[i])[0]);5 }
6 fs.Dispose();
因为我们的数据都是0-100的,所以我们就存储一个字节的数据即可,这样解析的时候更加的快速,文件本身的大小也缩小到了10K,虽然直接打开txt会出现乱码(因为此处我们写的数据本来就不是字符串)。10000字节差不多就是10K的样子,那么我们还有没有可能在缩小所存储的数据呢?答案当然是可以的,此处就使用了一种简单的压缩方式,假设数据存储的顺序没有关系,那我们在存储的时候,一共也就101种数据,每种数据出现0-10000次,而已,每个数据可以表示成 数据+重复次数来表示,因为重复次数不清楚,所以需要2个字节来表示,那么每个数据占用3个字节,101*3共占用了303个字节,你看我们就把数据压缩到了0.3K大小,只是在读取数据时需要根据存储规则来反解。
所以我们在提取重复次数的时候,一般比较容易想到的是这样的代码:
![]()
1 //生成一个随机0-100的10000个数据
2 int[] data = new int[10000];
3 Random r = new Random();
4 for (int i = 0; i < 10000; i++)
5 {
6 data[i] = r.Next(0, 101);
7 }
8
9
10 short[] repeat = new short[101];//因为最多重复一万次而已
11 for (int i = 0; i < 101; i++)
12 {
13 short count = 0;
14 for (int j = 0; j < 10000; j++)
15 {
16 if (data[j] == i) count++;
17 }
18 repeat[i] = count;
19 }
![]()
这么写代码有个问题,如果不是10000个数据呢,而是1000000个呢,那么计算重复次数的代码就会非常耗时,我们可以对data进行排序再进行高效的分析,这个就是后话了。同理对于其他的float,double都是一致的效果。
关于两套类型
不知道大家在学习C#的时候,会不会碰到这样的情况,定义一个int时,还有另一种Int32,所以此处列举所有对应的类型。
![]()
1 sbyte ==== System.SByte 2 byte ==== System.Byte 3 short ==== System.Int16 4 ushort ==== System.UInt16 5 int ==== System.Int32 6 uint ==== System.UInt32 7 long ==== System.Int64 8 ulong ==== System.UInt64 9 char ==== System.Char 10 float ==== System.Single 11 double ==== System.Double 12 bool ==== System.Boolean 13 decimal ==== System.Decimal 14 string ==== System.String 15 object ==== System.Object 16 dynamic==== System.Object
![]()
使用的效果上,两个是完全等价的,编译后的结果也是一致的,给我们的感觉就是这里有两套不同的命名方式,有些地方用第一套,有些地方用第二套,相对比较乱,原理是第二套的类型是FCL中原生支持的,也叫基元类型,而第一套类型是C#编译器提供一个等价的写法而已,从我们学习C语言的基础来看,左边这套命名似乎更加的符合我们的习惯,但是碰到下面的情况又有点尴尬:
![]()
1 byte[] data = new byte[4]; 2 3 //写法一 4 int i = BitConverter.ToInt32(data, 0); 5 float f = BitConverter.ToSingle(data, 0); 6 7 //写法二 8 Int32 j= BitConverter.ToInt32(data, 0); 9 Single g = BitConverter.ToSingle(data, 0);
![]()
第一种写法看上去总有点怪怪的,第二种写法阅读起来更加的舒适,实际中具体使用哪个根据自身的情况来选择,微软建议是用第一套,但是有些书籍推荐第二套。
类型背后的东西
上面的一切一切都让我们以为int i=0;i就真的只是一个4个字节的数据而已,因为我们在使用的过程中从没有发现其他东西,如果不是自己看书学习,或是从别人那里得知,就根本不会知道没有对象还包含了另外两个数据块,同步索引块和类型对象指针,这两个数据块构成了整个CLR的基础,为什么这么说呢,首先我们考虑第一个问题:
如果我写了个静态的int变量,就可以在程序的任何地方(可以在不同的线程)进行引用,获取,设置值而不用担心其他问题,比如竞争问题。不要思考也还好,一旦要去考虑这个问题的答案,背后就隐藏了一个极大的秘密,对象数据的本质。我们在实例化一个对象后,如下
1 puclic class class1
2 {
3 public static int i=0;
4 }
这行代码不仅仅只是生成了一个4个字节的变量数据,准确的说,对象i的数据部分确实是4个字节而已,但是对象本身绝对不是4个字节的问题,它还有另外两个非常重要的数据对象,叫同步索引块和类型对象块,而其中的同步索引块就控制了类型在同一瞬间只能进行一次设置,我们知道数据都是01组成,我们在执行i=0xffffff时,在另一个地方刚好获取i的值,这样就避免了万一设置到一半(i=0xff0000),我们就获取到了错误的值的可能性。
第二个有意思的问题是对象其实知道它自己的类型,这真的是一个很有意思的东西,如果上述的 i 只有4个字节的byte数据,那根本判断不出来数据类型,现在我们可以调用i.GetType()来获取i本身的类型,你可能会觉得这玩意到底有什么用,我自己定义的i我还不知道他是什么类型吗?事实上用处大了,我先说明有什么用处,在说明原因。正是因为对象自己知道自己的类型,才能执行一些类型的转换,强制转换也好,隐式转换也罢,C#所有的转换建立在这个基础之上的,再看下面的代码:
1 int i=0; 2 3 object obj=(object)i; 4 5 string m=(string)obj;
在第二行代码中,因为编译器知道object是所有类的基类,所以可以转化,但是obj对象的类型真的是object吗?答案是不一定的,因为object是所有类的基类,所以obj理论上来说可以是任何类型,此处你可以获取类型来确认,obj其实是int类型。正是因为int类型和string类型不存在继承关系,所以第三行代码报错。
上面也说了另一个数据块是类型对象指针,说明它会指向一个对象,而这个对象是关于类型的对象,该对象就是在CLR加载程序的时候创建的,我们可以通过类型对象来获取到更多有用的数据,这部分内容主要涉及到反射技术,将在以后有机会说明。
string类型特点
string类型有个非常大的特点,字符串是不易变的,所以刚开始写代码的时候容易会犯这样的错误(其实也不算错误,至少运行仍然可以运行)
1 string str = "";
2 for (int i = 0; i < 10000; i++)
3 {
4 str += "1";
5 }
虽然结果上来说,str最终是长达一万个长度的1组成的,但是这么写的效率非常的差,如果你定义了一个字符串string m="123456",它就傻傻的呆在一个内存块中,不会变化,直到被清除为止,所以上述的代码需要不停的重新分配和删除,实际的性能非常差,应该避免这种情况。关于string类型最难的就是本地化了,虽然大多数的程序员都不太关心这个问题,因为大多数的程序都只是给一个特定语言使用的,比如说中文,比如说英文,所以此处就简单的提个例子,即时两个看着不同的string,因为语言文化不一致,在比较相同的时候也是可能相同的。
数据重叠问题
虽然这个技术实际中很少碰到,但是用到的时候就特别合适,它允许数据区域进行重叠,比如和int数据和byte数据,结果就是更改了一个,另一个也会改变,代码如下:
1 [System.Runtime.InteropServices.StructLayout(System.Runtime.InteropServices.LayoutKind.Explicit)]
2 public class SomeValType
3 {
4 [System.Runtime.InteropServices.FieldOffset(0)]
5 public byte ValueByte = 0;
6 [System.Runtime.InteropServices.FieldOffset(0)]
7 public int ValueInt = 0;
8 [System.Runtime.InteropServices.FieldOffset(0)]
9 public bool ValueBool = false;
10 }
![]()
也可以自己写写代码,测试测试,还是相当有意思的。