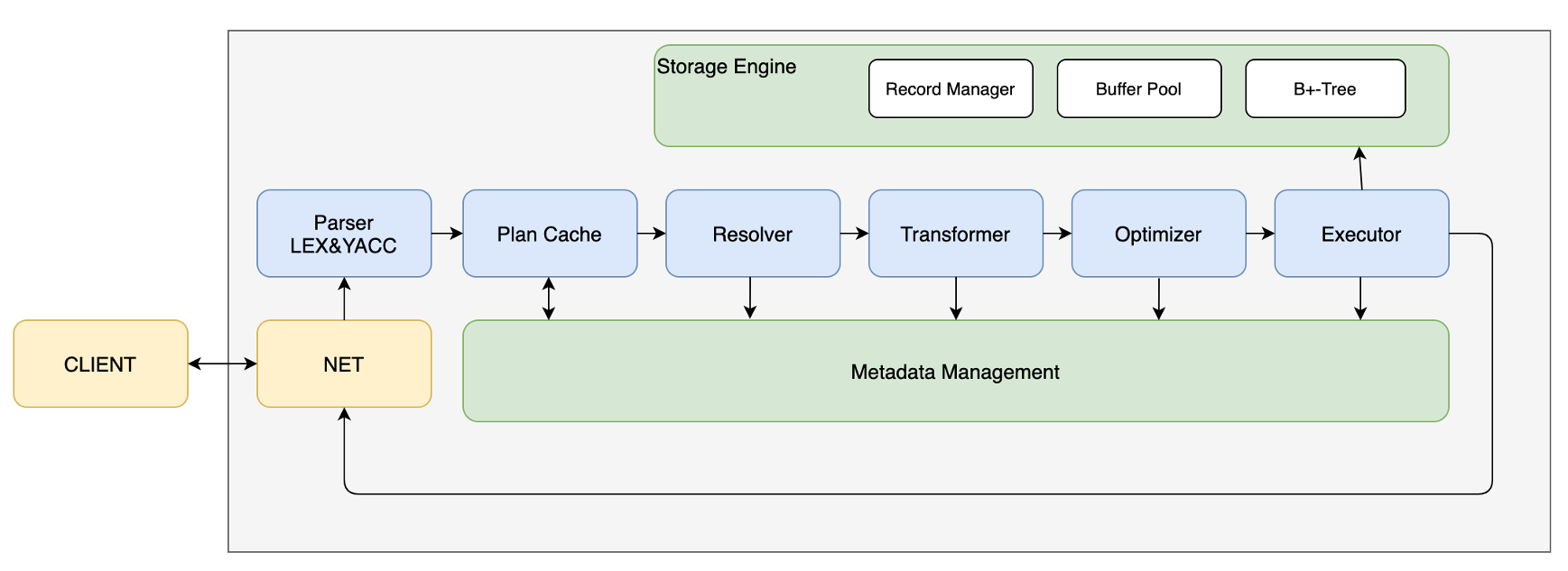
这个web应用放在在源码的demo文件夹里:
这个前端仅基于React的web演示了如何加载固定图像和相应的SAM image embedding的.npy文件。
运行需要配置npm环境。
首先导出onnx的模型:
import torch
import numpy as np
import cv2
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
from segment_anything.utils.onnx import SamOnnxModel
import onnxruntime
from onnxruntime.quantization import QuantType
from onnxruntime.quantization.quantize import quantize_dynamic
# 我本地存在checkpoints/sam_vit_h_4b8939.pth
checkpoint = "../checkpoints/sam_vit_h_4b8939.pth"
model_type = "vit_h"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
onnx_model_path = None # Set to use an already exported model, then skip to the next section.
import warnings
onnx_model_path = "sam_onnx_example.onnx"
onnx_model = SamOnnxModel(sam, return_single_mask=True)
dynamic_axes = {
"point_coords": {1: "num_points"},
"point_labels": {1: "num_points"},
}
embed_dim = sam.prompt_encoder.embed_dim
embed_size = sam.prompt_encoder.image_embedding_size
mask_input_size = [4 * x for x in embed_size]
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),
"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float),
"has_mask_input": torch.tensor([1], dtype=torch.float),
"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float),
}
output_names = ["masks", "iou_predictions", "low_res_masks"]
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=torch.jit.TracerWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# 这里导出了sam_onnx_example.onnx
with open(onnx_model_path, "wb") as f:
torch.onnx.export(
onnx_model,
tuple(dummy_inputs.values()),
f,
export_params=True,
verbose=False,
opset_version=17,
do_constant_folding=True,
input_names=list(dummy_inputs.keys()),
output_names=output_names,
dynamic_axes=dynamic_axes,
)
onnx_model_quantized_path = "sam_onnx_quantized_example.onnx"
quantize_dynamic(
model_input=onnx_model_path,
model_output=onnx_model_quantized_path,
# 这个实际运行的时候,会报错
#optimize_model=True,
per_channel=False,
reduce_range=False,
weight_type=QuantType.QUInt8,
)
onnx_model_path = onnx_model_quantized_path
这样会生成两个onnx模型:
- sam_onnx_example.onnx
- sam_onnx_example.onnx 这个模型是所需的,需要
然后选一个示例图像dog.jpg进行编码,输出其.npy的编码文件:
# 注意,这个一定要重新导入,因为下面的代码使用的cuda加速的,上面导出模型用的是CPU模式
checkpoint = "../checkpoints/sam_vit_h_4b8939.pth"
model_type = "vit_h"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
sam.to(device='cuda')
predictor = SamPredictor(sam)
image = cv2.imread('../demo/src/assets/data/dogs.jpg')
predictor.set_image(image)
image_embedding = predictor.get_image_embedding().cpu().numpy()
np.save("dogs_embedding.npy", image_embedding)
type(image_embedding),image_embedding.shape
按照demo/src/App.tsx规定的路径放置文件:
const IMAGE_PATH = "/assets/data/dogs.jpg";
const IMAGE_EMBEDDING = "/assets/data/dogs_embedding.npy";
const MODEL_DIR = "/model/sam_onnx_quantized_example.onnx";
运行demo:
cd demo
yarn




![2023年中国汽车差速器需求量、竞争现状及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/fdaf4f6e5958afc5775ff6ffcc82dc84.png)



![[AUTOSAR][诊断管理][ECU][$19] 读取ECU的DTC故障信息](https://img-blog.csdnimg.cn/3b0d29c96cbe4d27b7ede8870f04b1c8.png)