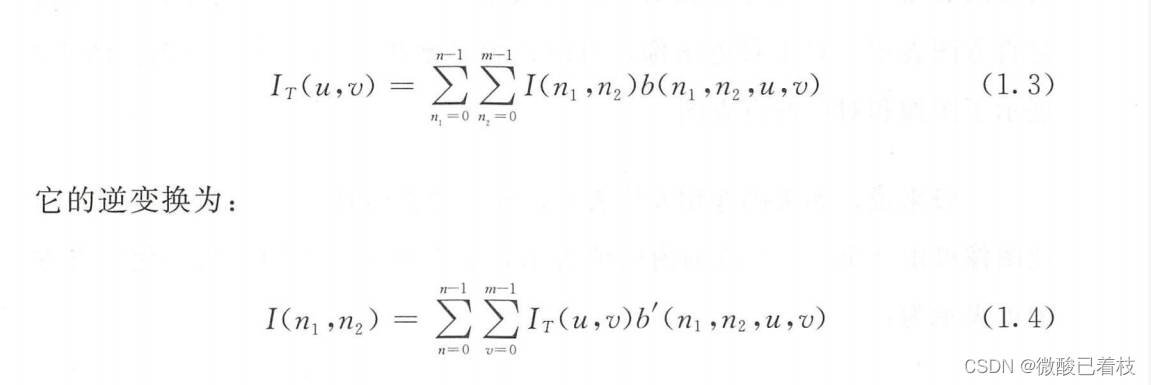目录
文件和目录路径
选择Path的片段
分析Path
添加或删除路径片段
目录
文件系统
监听Path
查找文件
读写文件
本笔记参考自: 《On Java 中文版》
更多详细内容请查看官方文档。
Java 7优化了Java的I/O编程,具体的表现就是java.nio.file。其中,nio中的n原本表示“new”,现在则是指代“non-blocking”(非阻塞)。在此之后的Java 8还新增了流,因此现在可以较为轻松地使用Java的文件编程。
文件和目录路径
Path对象表示的是一个文件或目录的路径,它是在不同操作系统和文件系统之上的抽象。

这一对象存在的目的是,让我们在构建路径时不必在意底层的操作系统。换言之,我们的代码无须重写就能在不同的操作系统上运行。
在开始第一个示例之前,需要先介绍static get方法,它在java.nio.file.Paths类中进行了重载:
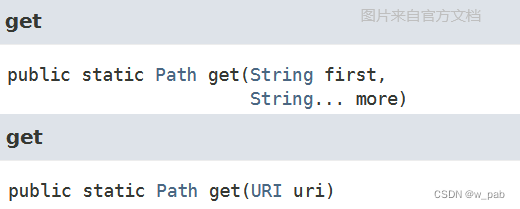
现在它能够接受一个String,或是一个URL(统一资源标志符),并将其转换为一个Path对象。
【例子:查看文件的信息】
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.nio.file.Files;
import java.nio.file.Path;
public class PathInfo {
static void show(String id, Object p) {
System.out.println(id + p);
}
static void info(Path p) {
show("显示文件路径(toString):", p);
show("路径指向文件是否存在:", Files.exists(p));
show("路径指向文件是否是常规文件:", Files.isRegularFile(p));
show("路径是否指向目录:", Files.isDirectory(p));
show("判断该路径是否为绝对路径:", p.isAbsolute());
show("返回路径指向文件的名字:", p.getFileName());
show("返回父路径(若路径不存在,返回null):", p.getParent());
show("当前路径的根:", p.getRoot());
System.out.println("=========================");
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name")); // 显示操作系统的名称
info(Path.of(
"./", "path", "to", "nowhere", "该文件不存在.txt"));
Path p = Path.of("PathInfo.java");
info(p);
Path ap = p.toAbsolutePath(); // 返回绝对路径
info(ap);
info(ap.getParent());
try {
info(p.toRealPath()); // 返回p的实际路径
} catch (IOException e) {
System.out.println(e);
}
URI u = p.toUri();
System.out.println("URI: " + u);
Path puri = Path.of(u);
System.out.println(Files.exists(puri));
File f = ap.toFile(); // 注意:toFile生成的File对象表示的是一个文件,或者是目录
}
}程序执行的结果是:

“该文件不存在.txt”表示,我们可以描述一个不存在的文件,这就允许我们创建一条新的路径。
在上述的show()方法中,存在一条用来描述实际路径的语句。实际上,文档中对实际路径的定义较为模糊,因为这一路径取决于特定的文件系统。
最后是toFile(),这一方法的存在是为了向后兼容。它表示的是文件或者目录(就像Path)。
选择Path的片段
可以使用方法获取Path对象路径的各个部分:
【例子:获取Path的片段】
import java.nio.file.Path;
public class PartsOfPaths {
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
System.out.println();
Path p = Path.of("PartsOfPaths.java").toAbsolutePath();
for (int i = 0; i < p.getNameCount(); i++)
System.out.println(p.getName(i));
System.out.println("此路径是否以【.java】结尾:" + p.endsWith(".java"));
System.out.println();
for (Path pp : p) {
System.out.println("当前路径是否以【"+pp+"】为开始:"+p.startsWith(pp));
System.out.println("当前路径是否以【"+pp+"】结尾:"+p.endsWith(pp));
System.out.println("---------------");
}
System.out.println("是否以【" + p.getRoot() +
"】作为路径起点:" + p.startsWith(p.getRoot()));
}
}程序执行的结果是:

因为Path可以生成Iterator,因此我们可以使用for-in来遍历整个Path。这里有一个问题,尽管路径确实以.java结尾,但是endsWith()方法的结果依旧是false。这是因为endsWith()会比较整个路径组件,而不是路径中单一的子串,for-in循环验证了这一点。
另外,当我们对Path进行遍历时,并没有包含根目录。当我们使用startsWith()检查根目录时,我们获得了true。
分析Path
files工具包中存在许多用来检查Path信息的方法:
【例子:检查Path的信息】
import java.io.IOException;
import java.nio.file.FileSystems;
import java.nio.file.Files;
import java.nio.file.Path;
public class PathAnalysis {
static void say(String id, Object result) {
System.out.print(id + ": ");
System.out.println(result);
}
public static void main(String[] args)
throws IOException {
System.out.println(System.getProperty("os.name"));
System.out.println();
Path p =
Path.of("PathAnalysis.java").toAbsolutePath();
say("是否存在", Files.exists(p));
say("是否是一个目录:", Files.isDirectory(p));
say("是否是一个常规文件", Files.isRegularFile(p));
say("是否可执行:", Files.isExecutable(p));
say("是否可读:", Files.isReadable(p));
say("是否可写", Files.isWritable(p));
say("按当前路径定位的文件是否存在:", Files.notExists(p));
say("是否是被隐藏的:", Files.isHidden(p));
say("文件的大小(以字节为单位):", Files.size(p));
say("文件所在存储区的FileStore(卷):", Files.getFileStore(p));
say("文件上次修改的时间:", Files.getLastModifiedTime(p));
say("文件的所有者:", Files.getOwner(p));
say("文件的内容类型:", Files.probeContentType(p));
say("是否是一个符号链接:", Files.isSymbolicLink(p));
if (Files.isSymbolicLink(p))
say("读取当前符号链接:", Files.readSymbolicLink(p));
if (FileSystems.getDefault()
.supportedFileAttributeViews().contains("posix"))
say("文件的POSIX文件权限:", Files.getPosixFilePermissions(p));
}
}程序执行的结果是:

最后一项测试,若系统不支持Posix,会得到一个运行时异常。
添加或删除路径片段
Java允许我们通过对Path对象进行路径片段的增删来构建Path对象。对应增删的有两个方法:
- relativize():可用来删除基准路径,基准路径由使用者自己决定(只有当Path是绝对路径时,才能作为该方法的参数)。
- resolve():可用来增加路径片段。
【例子:Path的增删】
import java.io.IOException;
import java.nio.file.Path;
public class AddAndSubtractPaths {
// 自定义基准路径
static Path base = Path.of("..", "..", "..")
.toAbsolutePath()
.normalize(); // 消除路径中的冗余元素
static void show(int id, Path result) {
if (result.isAbsolute())
System.out.println("绝对路径(" + id + ") "
+ base.relativize(result));
else
System.out.println("(" + id + ") " + result);
try {
System.out.println("实际路径:" + result.toRealPath());
} catch (IOException e) {
System.out.println(e);
}
System.out.println("-------------");
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
System.out.println();
System.out.println("base: " + base);
Path p = Path.of("AddAndSubtractPaths.java")
.toAbsolutePath();
show(1, p);
Path convoluted = p
.getParent()
.getParent()
.resolve("strings")
.resolve("..")
.resolve(p.getParent().getFileName());
show(2, convoluted);
show(3, convoluted.normalize());
Path p2 = Path.of("..", "..");
show(4, p2);
show(5, p2.normalize());
show(6, p2.toAbsolutePath().normalize());
Path p3 = Path.of(".").toAbsolutePath();
Path p4 = p3.resolve(p2);
show(7, p4);
show(8, p4.normalize());
Path p5 = Path.of("").toAbsolutePath();
show(9, p5);
show(10, p5.resolveSibling("strings"));
show(11, Path.of("不存在的路径"));
}
}程序执行的结果是:

目录
Files工具类包含了操作目录和文件的大部分操作。但遗憾的是,其中并没有用于删除目录树的工具。下面是一个删除目录树的例子:
【例子:删除目录树】
package onjava;
import java.io.IOException;
import java.nio.file.FileVisitResult;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.SimpleFileVisitor;
import java.nio.file.attribute.BasicFileAttributes;
public class Rmdir {
public static void rmdir(Path dir)
throws IOException {
Files.walkFileTree(dir, // 遍历目录树
// 访问目录中的文件
new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file,
BasicFileAttributes attrs)
throws IOException {
Files.delete(file); // 删除文件
return FileVisitResult.CONTINUE;
}
// 该方法在访问了目录的所有条目后调用
@Override
public FileVisitResult postVisitDirectory(Path dir,
IOException exc)
throws IOException {
Files.delete(dir); // 删除目录
return FileVisitResult.CONTINUE;
}
});
}
}
walkFileTree的意思是查找每个子目录和文件,也就是遍历。

这种访问者的设计模式提供了一个访问集合中的每个对象的标准机制,它要求我们提供需要在每个对象上执行的动作。而这一动作又取决于我们如何实现FileVisitor。
FileVisitor接口包含了以下方法:
- preVisitDirectory():先处理当前目录,再进入这个目录下的文件和目录中。
- visitFile():在这个目录下的每个文件上运行。
- visitFileFailed():当文件无法访问时调用。
- postVisitDirectory():先进入这个目录下的文件和目录中(包括子目录),最后处理当前目录。
java.nio.file.SimpleFileVisitor为所有这些方法提供了默认的定义。上述例子仅仅简单(而不规范)地重写了这些方法。
下面的例子会根据一个基准目录test,通过旋转parts生成不同的子目录路径:
【例子:生成子目录】
import onjava.RmDir;
import java.nio.file.FileSystems;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class Directories {
static Path test = Path.of("test"); // 生成一个基准目录test的Path对象
static String sep = // 获取默认文件系统的分隔符(在Windows中,就是【/】)
FileSystems.getDefault().getSeparator();
static List<String> parts =
Arrays.asList("foo", "bar", "baz", "bag");
static Path makeVariant() {
Collections.rotate(parts, 1); // 将parts中的元素进行旋转
return Path.of("test", String.join(sep, parts)); // 通过分隔符sep连接parts中的元素,形成字符串
}
static void refreshTestDir()
throws Exception {
if (Files.exists(test)) // 若文件存在
RmDir.rmdir(test);
if (!Files.exists(test)) // 再次检查
Files.createDirectory(test);
}
public static void main(String[] args)
throws Exception {
refreshTestDir(); // 检测test是否已经存在
Files.createFile(test.resolve("Hello.txt")); // 根据路径创建一个文件
Path variant = makeVariant();
try {
Files.createDirectory(variant); // 只能用于创建单层目录
} catch (Exception e) {
System.out.println("无法正常工作(目录层次太多)");
}
populateTestDir();
Path tempdir =
Files.createTempDirectory(test, "DIR_"); // 使用给定前缀创建目录
Files.createTempFile(tempdir, "pre", ".non"); // 使用给定的前缀和后缀生成文件
Files.newDirectoryStream(test) // 一个流,用以迭代目录中的所有条目
.forEach(System.out::println);
System.out.println("============");
Files.walk(test) // 遍历目录树
.forEach(System.out::println);
}
static void populateTestDir()
throws Exception {
for (int i = 0; i < parts.size(); i++) {
Path variant = makeVariant();
if (!Files.exists(variant)) {
Files.createDirectories(variant); // 与createDirectory的不同之处在于,不会因为目录已经存在而抛出异常
Files.copy(Path.of("Directories.java"),
variant.resolve("File.txt")); // 将Directories.java的内容复制到File.txt中
Files.createTempFile(variant, null, null); // 在临时目录中创建一个空文件
}
}
}
}程序执行的结果是:

若一个目录已经存在,此时调用createDirectory()将会产生异常。因此在创建目录之前最好检查一下。另外,该方法只能用于创建单层目录,所以当我们传入一个包含许多层次的variant时,我们捕获了异常。
再说一下newDirectoryStream()和walk()的区别,这两者都会生成一个关于目录的流。但从结果就可以看出,newDirectoryStream()中只有test目录下的内容,并没有进入目录内部,而walk()可以做到这点。
文件系统
获取文件系统信息的方式有3种:
- 通过FileSystems工具来获取“默认”的文件系统信息。
- 通过Path对象的getFileSystem()来获取创建这个路径对象的文件系统的信息。
另外,我们还可以通过给定的URI获得或构建一个文件系统。
【例子:获取文件系统的信息】
import java.nio.file.FileStore;
import java.nio.file.FileSystem;
import java.nio.file.FileSystems;
import java.nio.file.Path;
public class FileStstemDemo {
static void show(String id, Object o) {
System.out.println(id + ": " + o);
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
System.out.println();
FileSystem fsys = FileSystems.getDefault(); // 获取默认的文件系统
for (FileStore fs : fsys.getFileStores()) // 获取底层(即硬盘上的)文件存储流
show("文件存储", fs);
for (Path rd : fsys.getRootDirectories()) // 获取根目录的流
show("根目录的路径", rd);
show("名称分隔符", fsys.getSeparator());
System.out.println();
show("此系统的UserPrincipalLookupService",
fsys.getUserPrincipalLookupService());
show("此文件系统是否打开", fsys.isOpen());
show("此文件存储区是否是只读访问", fsys.isReadOnly());
show("创建此文件系统的提供程序", fsys.provider());
show("此文件系统支持的文件属性视图", fsys.supportedFileAttributeViews());
}
}程序执行的结果是(由于Linux的文件存储过长,故不做展示):

监听Path
FileSystem还提供了WatchService,通过它我们能够监听目录的变化。
【例子:监听一个目录】
import java.io.IOException;
import java.nio.file.*;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import static java.nio.file.StandardWatchEventKinds.*;
public class PathWatcher {
static Path test = Path.of("test");
static void delTxtFiles() {
try {
Files.walk(test)
.filter(f -> // 删除所有以.txt结尾的文件
f.toString().endsWith(".txt"))
.forEach(f -> {
try {
System.out.println("正在删除:" + f);
Files.delete(f);
} catch (IOException e) {
throw new RuntimeException(e);
}
});
} catch (IOException e) { // 因为一些原因,Java会要求我们在内部和外部都捕获异常
throw new RuntimeException(e);
}
}
public static void main(String[] args)
throws Exception {
Directories.refreshTestDir(); // 创建目录
Directories.populateTestDir();
Files.createFile(test.resolve("Hello.txt"));
WatchService watcher =
FileSystems.getDefault().newWatchService(); // 创建一个新的监听
test.register(watcher, ENTRY_DELETE); // 向监听服务watcher注册test,监听删除行为
// 创建一个单线程执行器,在给定时延后运行delTxtFiles
Executors.newSingleThreadScheduledExecutor()
.schedule(
PathWatcher::delTxtFiles,
250, TimeUnit.MILLISECONDS);
WatchKey key = watcher.take(); //检索、删除(并返回)下一个监听标识
// 将监听的事件逐个打印
for (WatchEvent evt : key.pollEvents()) {
System.out.println(
"事件所处上下文: " + evt.context() +
"\n事件计数: " + evt.count() +
"\n事件类型: " + evt.kind());
System.exit(0);
}
}
}程序执行的结果是:
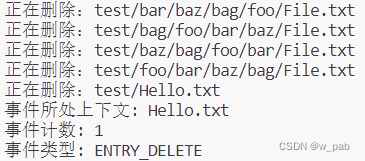
在delTxtFiles()中,需要显式地调用f.toString(),否则endWith()会比较整个Path对象,而不是用其字符串表示的名字部分。
FileSystem创建了一个WatchSerive:

可以将需要监听的事件(将其组成参数列表)传输给test.register()进行注册。可以注册三种事件:
- 创建:ENTRY_CREATE
- 删除:ENTRY_DELETE
- 修改:ENTRY_MODIFY
(注意,删除和创建并不算做修改)
当我们使用watcher.take()进行监听时,程序会停留在这里等待知道预订的事件出现(串行执行)。此时若没有外力介入删除其监听的文件,程序就不会继续执行。因此,我们需要并行执行delTxtFiles():
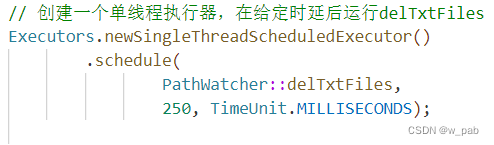
通过这条语句,我们设置了一个执行器。schedule()操作允许我们指定方法,在给定时间后执行它。此时我们调用watch.take(),主线程会等待,直到删除操作发生。
注意:WatchService只会监听当前目录,这意味着就算这个目录存在子目录,其中发生的任何事也不会被该WatchService中监听。
因此,若想要监听整个目录树,就必须为所有的子目录都设置一个WatchSerive:
【例子:监听整个目录树】
import java.io.IOException;
import java.nio.file.*;
import java.util.concurrent.Executors;
import static java.nio.file.StandardWatchEventKinds.*;
public class TreeWatcher {
static void watchDir(Path dir) {
try {
WatchService watcher =
FileSystems.getDefault().newWatchService();
dir.register(watcher, ENTRY_DELETE);
Executors.newSingleThreadScheduledExecutor().submit(() -> { // 直接运行任务
try {
WatchKey key = watcher.take();
for (WatchEvent evt : key.pollEvents()) {
System.out.println(
"事件所处上下文: " + evt.context() +
"\n事件计数: " + evt.count() +
"\n事件类型: " + evt.kind());
System.exit(0);
}
} catch (InterruptedException e) {
return;
}
});
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args)
throws Exception {
Directories.refreshTestDir();
Directories.populateTestDir();
Files.walk(Path.of("test"))
.filter(Files::isDirectory)
.forEach(TreeWatcher::watchDir);
PathWatcher.delTxtFiles();
}
}程序执行的结果是:

这次我们为每一个进程单独设置了一个WatchService。并且没有推迟任务运行,而是通过submit()操作让任务即刻生效。
查找文件
在此之前,我们使用Path的toString()和String的操作来查看结果。但java.nio.file提供了一个更好的方案:PathMatcher。FileSystem对象有一个getPathMatcher(),通过它我们能获取一个PathMatcher。

从图片的描述中可以发现,这个方法有一个参数,我们能够选择一个模式并且传给它。模式的两个选项分别为glob和regex,这里会展示前者的用法。
下面的例子会通过使用glob来查找所有文件以.tmp或.txt结尾的Path。
【例子:使用getPathMatcher】
import java.nio.file.FileSystems;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.PathMatcher;
public class Find {
public static void main(String[] args)
throws Exception {
Path test = Path.of("test");
Directories.refreshTestDir();
Directories.populateTestDir();
// 创建一个目录(而不是文件):
Files.createDirectory(test.resolve("dir.tmp"));
PathMatcher matcher1 = FileSystems.getDefault()
.getPathMatcher("glob:**/*.{tmp,txt}"); // 匹配目录树中,所有以.tmp或.txt结尾的文件
Files.walk(test)
.filter(matcher1::matches) // 匹配成功则进行打印
.forEach(System.out::println);
System.out.println("==============");
PathMatcher matcher2 = FileSystems.getDefault()
.getPathMatcher("glob:*.tmp");
Files.walk(test)
.map(Path::getFileName) // 使用map()操作将路径缩减至最后的名字
.filter(matcher2::matches)
.forEach(System.out::println);
System.out.println("==============");
Files.walk(test)
.filter(Files::isRegularFile)
.map(Path::getFileName)
.filter(matcher2::matches)
.forEach(System.out::println);
}
}程序执行的结果是:

介绍一下glob表达式。在使用glob时,可以使用类似于正则表达式的语言进行匹配(此处根据上述例子进行简单介绍,若需要详细了解,可前往官方文档):
| 规则(字符) | 解释 |
|---|---|
| * | 匹配任何名称,但不会跨越目录边界(不会进入子目录)。 |
| ** | 匹配零个或多个字符(例如:**/代表“所有子目录”)。 |
| ? | 和正则表达式中的类似,可以完全匹配一个字符。 |
| / | 用于转义。 |
| [ ] | 将一组字符与名称中的单个字符进行匹配。 |
| { } | 内部是一组子模式。每次从中取出一个子串进行匹配(子串之间用【 , 】进行分隔)。 |
注意:在第一次和第二次的walk()中,我们都看到了dir.tmp,尽管它是一个文件(而非目录)。若只需要文件,那么应该像最后一次的walk()那样进行过滤。
读写文件
java.nio.file.Files类包含了方便读写文本文件和二进制文件的工具函数。
若一个文件是较小的(内存中放得下),那么我们可以使用Files.readAllLines()一次性读入整个文件,并且生成一个List<String>。
【例子:读取文件】
设置一个需要读取的文件Cheese.dat(假设它被放在data文件夹中):

对其进行读取:
// 位于files文件夹中,files文件夹和data文件夹处于同一目录中
import java.nio.file.Files;
import java.nio.file.Path;
public class ListOfLines {
public static void main(String[] args)
throws Exception {
Files.readAllLines(
Path.of("../data/Cheese.dat"))
.stream()
.filter(line -> !line.startsWith("//"))
.map(line -> line.substring(0, line.length() / 2))
.forEach(System.out::println);
}
}程序执行的结果是:

注释行被跳过了,并且其他行只被打印了一半。
readAllLines()还有一个重载的版本,包含一个Charset参数,用于确定文件的Unicode编码。
除此之外,还可以使用Files.write()的重载方法。这些重载支持byte数组或任何实现了Iterable接口的类的对象。
【例子:写入数组或对象】
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;
import java.util.Random;
public class Writing {
static Random rand = new Random(47);
static final int SIZE = 1000;
public static void main(String[] args)
throws Exception {
// 将字节写入一个文件:
byte[] bytes = new byte[SIZE];
rand.nextBytes(bytes);
Files.write(Path.of("bytes.dat"), bytes);
System.out.println("bytes.dat: " +
Files.size(Path.of("bytes.dat")));
// 将实现了Iterable接口的类的对象写入文件:
List<String> lines = Files.readAllLines(
Path.of("../data/Cheese.dat"));
Files.write(Path.of("Cheese.txt"), lines);
System.out.println("Cheese.txt: " +
Files.size(Path.of("Cheese.txt")));
}
}程序执行的结果是:
![]()
目录中已经出现我们创建的文件了:
![]()
这里,我们需要提出一个疑问:如果文件太大了怎么办?一个好的办法是每次只使用文件的一部分,这时候就需要使用到流了。
Files.lines()可以将一个文件转变成一个由行组成的流。
【例子:文件的输入流】
import java.nio.file.Files;
import java.nio.file.Path;
public class ReadLineStream {
public static void main(String[] args)
throws Exception {
Files.lines(Path.of("PathInfo.java")) // 指定一个文件
.skip(13) // 跳过13行
.findFirst()
.ifPresent(System.out::println);
}
}程序执行的结果是:
![]()
上述程序完成了一个输入流,而下面的例子会展示在流中进行读取、处理和写入的过程:
【例子:使用流处理文件】
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.stream.Stream;
public class StreamInAndOut {
public static void main(String[] args) {
try (
Stream<String> input =
Files.lines(Path.of("StreamInAndOut.java"));
PrintWriter output = // 指定输出流
new PrintWriter("StreamInAndOut.txt");
) {
input.map(String::toUpperCase)
.forEachOrdered(output::println);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}PrintWriter来自于java.io类,用于向指定文件打印信息。可以观察StreamInAndOut.txt:

所有内容确实转变为了大写形式。