GPT-3 内幕机制可视化解析
GPT-3是一个基于Transformer的语言模型,通过不同的层次提取语言不同层面的特性,构建整个语言的语义信息,它学习的过程跟人类正常学习的过程是类似的,开始的时候是一个无监督预训练,如图5-5所示,GPT-3模型可以将网络上的所有文档下载下来,包含 3000 亿个文本标记的数据集用于生成模型的训练示例,通过遮住下一个词的方式来训练模型,然后进行预测,如果模型的预测是正确的,那么这是一个很好的结果;如果预测不正确,可以通过误差来调整模型。 Gavin大咖微信:NLP_Matrix_Space

图5- 5无监督预训练
如图5-6所示,GPT-3 是一个大模型,使用1750 亿个参数,未经训练的模型以随机参数开始,从最原始的没有经过训练的GPT-3模型,通过一个无监督预训练的过程,形成一个新的网络,网络本身还是基于Transformer的解码器,但是这里面的参数已经做出了改变,从图中的颜色对比可以看出参数发生的一些变化,这只是第一个步骤,但是已经导致它本身非常强大了。
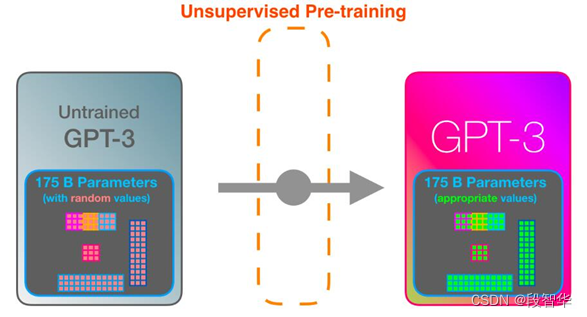
图5- 6 GPT-3模型的无监督预训练
GPT系列或者ChatGPT是一种基于人工智能的自然语言处理技术,其最根本的机制是预测下一个词是什么,通过加入人工干预和增强学习算法,使得ChatGPT具备强大的推理能力和信