基于语义和几何约束的方法
1. Deep3DBox
- 3D Bounding Box Estimation Using Deep Learning and Geometry [CVPR2017]
- https://arxiv.org/pdf/1612.00496.pdf
- https://zhuanlan.zhihu.com/p/414275118

核心思想:通过利用2D bounding box与3D bounding box之间的几何约束,结合相机内参以及目标的物理尺寸和朝向信息,构造方程组求解出目标的位置信息
基于2D Box预测3D Box时的假设:3D Box在图像平面上的投影应该与其对应的目标的2D Box紧密贴合。如Figure 2所示,目标的2D Box的四条边都分别包含至少1个3D Box的角点投影
2. CenterNet3D
- CenterNet3D: An Anchor Free Object Detector for Point Cloud
- https://arxiv.org/pdf/2007.07214.pdf
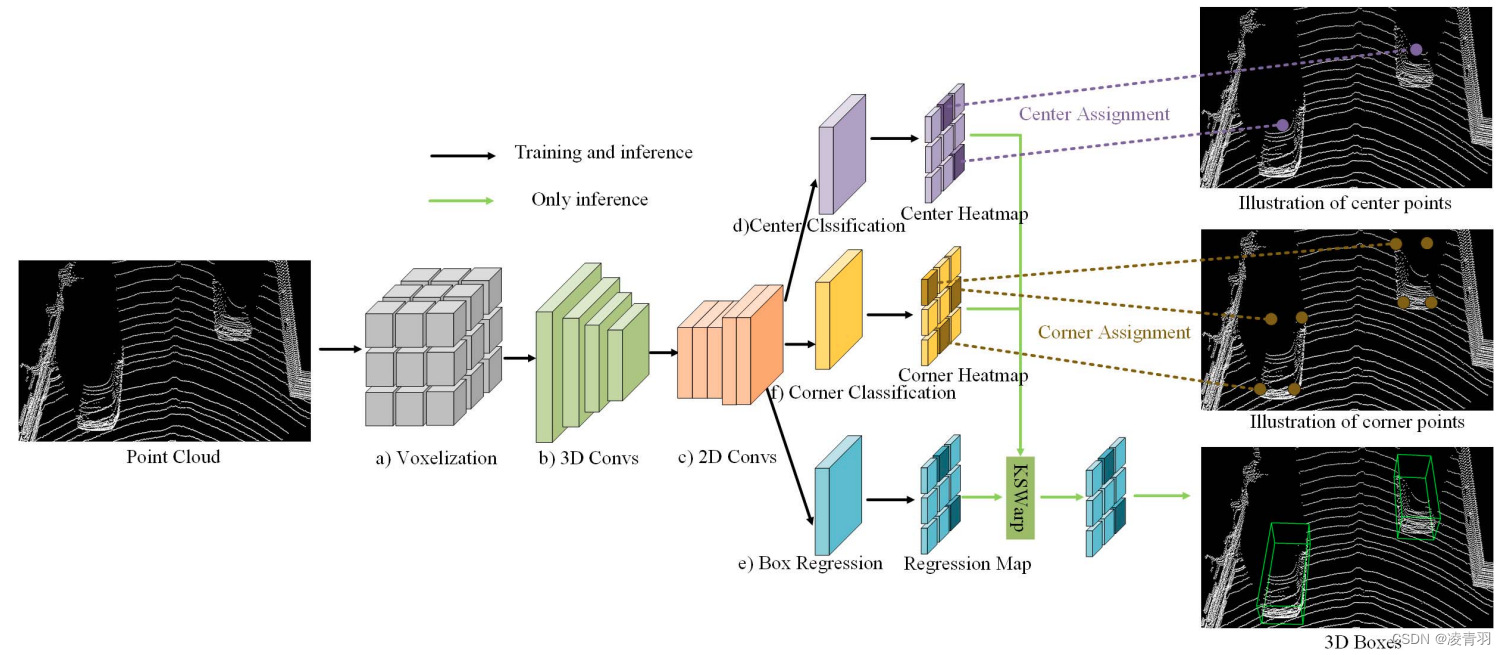
CenterNet3D:回归2D框的中心点
Centernet检测头在点云3D检测和BEV检测上也适用,如Centerpoint,BEVDet、BEVDepth
- 2D框的中心点和3D投影点的位置偏差,距离越近越大,特别是截断物体偏差很大,所以不用2D框中心索引3D信息(不准确)
- Center3D:
- backbone:dla3d
- 分类头:heatmap分类信息,focal loss,分类标签是高斯形状
- 回归头:8个通道,(1,2,3,2)=(depth,keypoint_量化误差,长宽高,航向角)
3. KM3D
- Monocular 3D Detection with Geometric Constraints Embedding and Semi-supervised Training
- https://arxiv.org/pdf/2009.00764.pdf
- RTM3D:https://arxiv.org/pdf/2001.03343.pdf
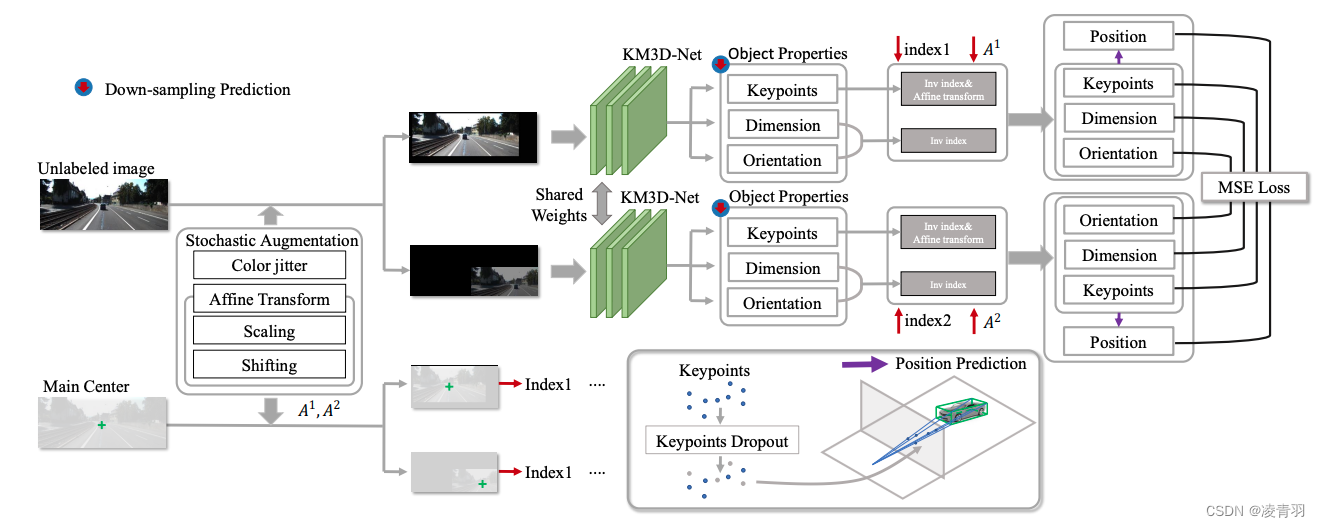
KM3D:回归3D投影点+3D数据增强
KM3D的几何推理模块(GRM)代替了RTM3D的后处理
- 网络结构继承CenterNet,backbone是dla34,回归头类别一样
- 分类头回归的是3D投影点信息
- 数据增强:
- 外观增强(内外参不用变换):颜色抖动,随机mask
- 几何信息增强(内外参要变换):图像仿射变换,缩放等
- 3D数据增强
- 提点最明显:带iou碰撞的Mixup,涨点4.5
- CutPaste涨点4.2
- Pix-aug + mosaic掉点,其余的均有涨点
- Pedestrian和Cyclist因为样本数量较少,不具备参考意义
4.Monocon
- Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection
- AAAI2022
- https://arxiv.org/pdf/2112.04628.pdf
- https://github.com/Xianpeng919/MonoCon
KM3D + 2D辅助监督
动机:3D框投影到2D图像上有丰富语义信息的监督信息,如2D框、车辆关键点和对应的偏移量
- 做法:
- 训练阶段辅助监督,9个关键点(一个中心点+8个角点)、8个角点偏移量、2D框的宽高
- 训练和测试都有的检测头:3个类别的2D框的中心,2D框中心和3D投影点的偏移量,深度值,深度的不确定值,长宽高和航向角
- 实验结果:monoconv耗时25.8ms,BEV的3D AP为31.2,都是领先的
5. Monoflex
- Objects are Different: Flexible Monocular 3D Object Detection
- CVPR2021
- https://arxiv.org/pdf/2104.02323.pdf
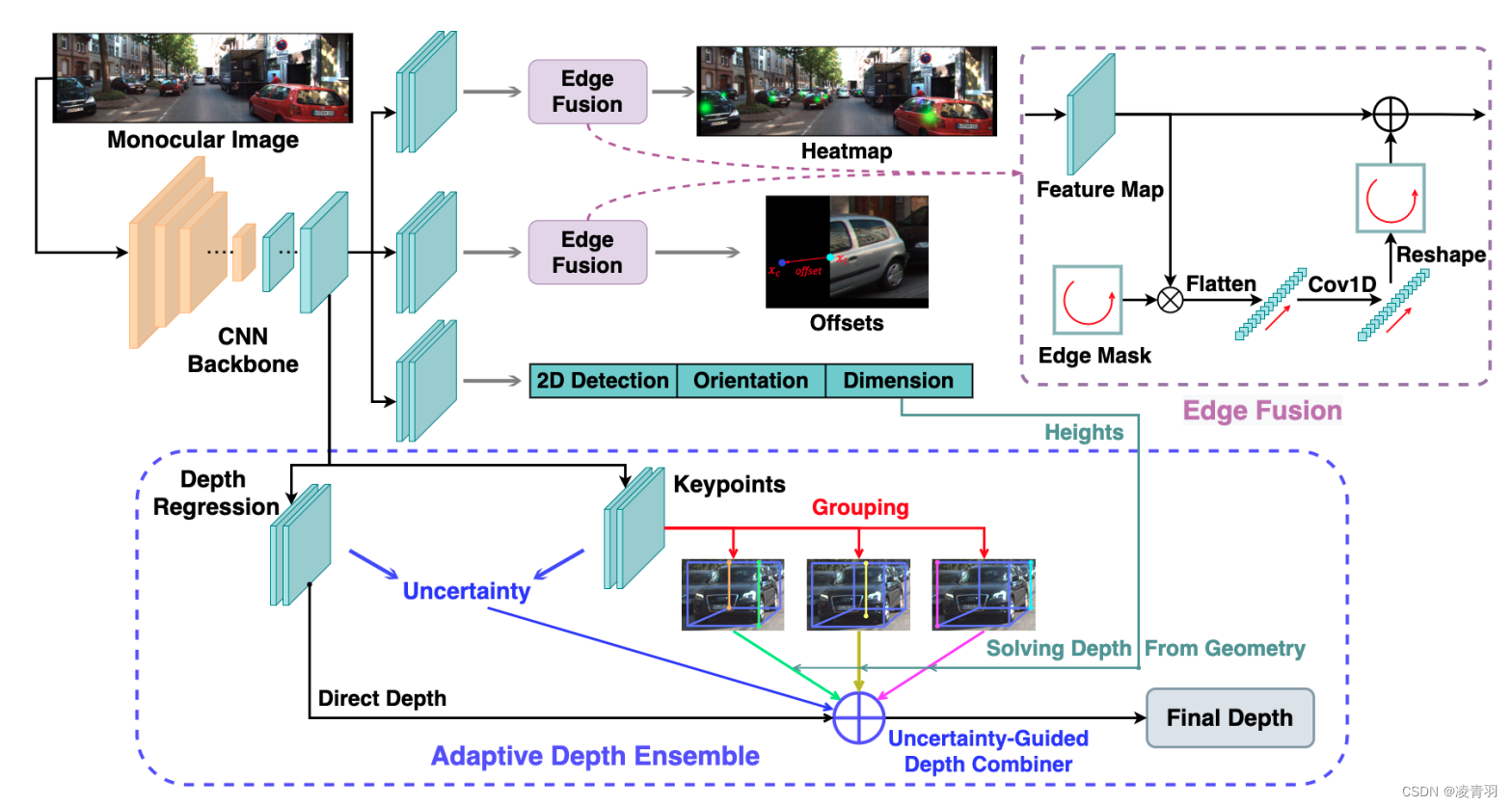
KM3D + 解决遮挡问题
动机:截断物体和非截断物体的投影点跟2D框中心的距离呈现不同的分布,所以需要解耦成inside-object和outside-object
- 创新点:
- 添加额外分支预测截断目标(之前的monodle等算法发现训练时去掉outside object可以提高整体的3D AP,但是没有对截断物体进行建模),提升截断物体的检出率
- 截断物体的标签是用一维高斯生成的
- 将深度估计建模为直接回归对象深度和从不同的关键点组得到的深度值加权(继承学习,soft ensemble)
- 建立2D信息与3D box的约束
- 添加额外分支预测截断目标(之前的monodle等算法发现训练时去掉outside object可以提高整体的3D AP,但是没有对截断物体进行建模),提升截断物体的检出率
- 整体结构:
-
模型结构继承Centernet3d
-
引入edge fusion为outside object提供强大的边界先验假设
- 提取特征图的四个边界,并按顺时针顺序将其连接成一个边缘特征向量,然后通过两个1D卷积层并reshape成edge mask,并与原来特征图相加,以学习截断对象的唯一特征

- 提取特征图的四个边界,并按顺时针顺序将其连接成一个边缘特征向量,然后通过两个1D卷积层并reshape成edge mask,并与原来特征图相加,以学习截断对象的唯一特征
-
深度估计模块:
- 相对于3D box长宽的预测,高度的预测误差是最低的,因为高度的预测不受航向角的影响
- 深度预测的具体流程:
- 关键点得到深度:10组关键点(3D框8个角点+底部中心和顶部中心)分成3组,每组可以独立产生2D box高度,再结合模型预测的3D高度,根据投影关系可得3组深度
- 直接预测深度
- 四种深度做ensemble得到最终深度
-