有帮助要帮我点赞哦
可以依据现在的流程,结合实际数据情况进行调整。
流程框架:
- eda
- 查看字段相似性,提炼相似字段
- 初步分箱
- 必要时展开二次分箱(或者多轮分箱调优)
- 可以进一步查看分箱后字段的相似性(woe值转化之后)
- 查看分箱效果
介绍的具体目录⬇️
(当前只试用了决策树分箱和等频|等距的简单分箱、不均衡分箱,一些其它分箱手段,后续可以在这些方面补充一下)
文章目录
- 查看字段相似性
- 1.相似矩阵图
- 2.拉取高相似度的字段
- 去除异常值
- 实施建议
- 分箱
- 1.初步分箱(等距|等频分箱)
- 2.决策树分箱
- 3.处理不均衡分箱
- 统计分箱效果
- 1.计算woe值,iv值等
- 2.异常情况处理——woe、iv值出现∞
- 3.异常情况处理——字段iv值很大
- 初步绘图查看分箱效果
- 1.单个字段绘图
- 2.对比多个字段一起查看
- 3.jupyter中直接查看df
- 评分卡工具
- 1.第三方python库--OptBinning(重点,单开一篇介绍)
- 2.第三方python库--toad
- 评分卡相关-很好但还没读的文章
查看字段相似性
1.相似矩阵图
# 相似矩阵
import matplotlib.pyplot as plt
import seaborn as sns
# 多变量分析
corr = df_train.corr() # 相关性系数图
cmap = sns.diverging_palette(200, 20, sep=20, as_cmap=True)
f, ax = plt.subplots(figsize=(15, 10))
sns.heatmap(corr, annot=True, cmap=cmap, annot_kws={'size': 10}, linewidths=.5, fmt= '.3f',ax=ax)
plt.show()
2.拉取高相似度的字段
# 筛选完全相似的列表团
def filter_sim_li(cal_li):
# 过滤单个列表
def len_li(x):
return len(x) - 1
# 过滤掉单个的列表
cal_li = list(filter(len_li, cal_li))
set_tmp = set()
len_tmp = 0
res_dict = dict()
for each in cal_li:
each.sort() # 排序,不然比较结果受元素顺序影响
aa = tuple(each)
set_tmp.add(aa)
if len_tmp == len(set_tmp):
res_dict[aa] += 1
else:
res_dict[aa] = 0
len_tmp = len(set_tmp)
# 过滤字典键值对函数
def filter_dict(pair):
key, value = pair
if value > 0:
return True
else:
return False
filtered_res = dict(filter(filter_dict, res_dict.items())) # 记一下
return list(filtered_res.keys())
def extract_corr(df, lim_val=0.8):
"""
提取给出相似字段的dict,默认筛选阈值为0.8,给出df中与字段a相似性大于等于0.8的字段列表
:param df: 需要计算相似性的dataframe
:param lim_val: 给定的筛选阈值,默认为0.8
:return: 返回高相似度的字典,键为df中存在高相似度的字段,值为相似度高的字段列表 以及 完全相似的字段组
"""
corr_df = df.corr()
corr_df['sim_li'] = corr_df.apply(lambda x: list(x[x >= lim_val].index) if any(x) >= lim_val else None, axis=1)
corr_df['col_name'] = list(corr_df.index)
corr_df['con_dict'] = corr_df[['sim_li', 'col_name']].apply(lambda x:
{x[1]: list(set(x[0]) - set(x[1]))}
if len(x[0]) > 1 else None, axis=1)
filter_col = list(filter(None, list(corr_df['con_dict'])))
corr_cluster = filter_sim_li(corr_df['sim_li'])
return filter_col, corr_cluster
test_a, test_b = extract_corr(df_train, lim_val=0.8) # 查看高相似性的字段详情
去除异常值
实施建议
- 数据量少的时候谨慎处理
- 可以结合具体的分箱方法再来看要不要去除
- 如果使用pd.cut方法,需要根据区间长度等分,异常值会对结果影响较大
- 如果使用qcut或者其它方法,异常值的影响可能相对较小,确定边界后包含异常值情况即可
- 可以先不去除,分箱看一下效果再进行必要地修订
def remove_outliers(df, min_dict=None, max_dict=None, min_lim=0.01, max_lim=0.99):
"""
分箱前用来去除异常值,不给定min_lim,max_lim的话,默认去除前1%和后1%的数据,
min_dict,max_dict可以用来单独调节部分特征的阈值
:param df: 传入的dataframe(不包含标签列)
:param min_dict: dict,给出需要手动调节的特征最小阈值
:param max_dict: dict,给出需要手动调节的特征最大阈值
:param min_lim: float,去除前百分之多少分位数的值,0.01为前1%的数据
:param max_lim: float,去除后百分之多少分位数的值,0.99为后1%的数据
:return: df,删除异常值后的数据
"""
describe_val = df.describe([min_lim, max_lim])
col_list = [f'{int(each*100)}%' for each in [min_lim, max_lim]]
out_lim = describe_val.loc[col_list, :].to_dict('records')
min_line = out_lim[0] # 最小边界
max_line = out_lim[1] # 最大边界
# 如果有值要替换的话
if min_dict:
min_line.update(min_dict)
if max_dict:
max_line.update(max_dict)
for each in min_line.keys():
print(each)
print('cut范围:', [min_line[each], max_line[each]+0.000001])
x = pd.cut(df[each], [min_line[each], max_line[each]+0.000001], right=False)
print('drop数量:', x.isnull().sum())
df = df[x.notnull()]
return df
min_dict_1 = {'NumberRealEstateLoansOrLines': 2.0, 'NumberOfTimes90DaysLate': 0.1}
df_train = remove_outliers(df_train, min_lim=0.01)
df_train3 = remove_outliers(df_train, min_dict_1, min_lim=0.01)
分箱
1.初步分箱(等距|等频分箱)
使用了等距分箱和等频分箱两种,可以用来初步尝试分箱效果。
-
等距分箱
优点:初步按照距离直接分割,较为简单
缺点:受异常值影响大 -
等频分箱
优点:按照分位数等分,每组内的数据量较为均衡
缺点:数据分布不均衡,大部分为1个值时,分割边界不好处理,如指定分为4组,前2组均为同一个值时会合并分组
实施建议:
结合前面数据探查的结果,可以用于初次分箱查看分箱效果时使用
批量使用,大致粗略查看
效果好的:微调,直接应用该分箱方案
效果不好的字段进行细调,或者尝试其它分箱方案
# (和前面去除异常值的自定义逻辑差不多,在等距or分位数分割基础上自定义修改)
def n_cut(df, cut_num=4, right=False, define_col=None, if_cut=True):
"""
用于等距分箱,默认所有字段都分4组,给定define_col的话对指定字段的分箱数进行修改
:param df: 传入待分箱的dataframe(不包含标签列)
:param cut_num: int,设置的分箱数(小于4组时,会按照实际存在的类别分)
:param right: bool,等距分箱cut时,False为左闭右开,True为左开右闭)
:param define_col: dict,对指定字段a设置其分箱数
:param if_cut: bool,默认为True,用等距分箱cut,False时使用等频分箱qcut
:return: 所有列的分箱结果
"""
if if_cut:
df_cut = df.apply(lambda x: pd.cut(x, cut_num, right=right)) # 先按照默认箱数等距分组
if define_col:
col_li = [each for each in define_col.keys()]
for each in col_li:
df_cut[each] = df[[each]].apply(lambda x: pd.cut(x, bins=define_col[each], right=right))
else:
df_cut = df.apply(lambda x: pd.qcut(x, cut_num, duplicates='drop')) # 先按照默认箱数等频分组
if define_col:
col_li = [each for each in define_col.keys()]
for each in col_li:
df_cut[each] = df[[each]].apply(lambda x: pd.qcut(x, q=define_col[each], duplicates='drop'))
return df_cut
ll1 = n_cut(df_train, cut_num=4, define_col={'age': 5}, if_cut=0)
ll = n_cut(df_train, 4)
2.决策树分箱
利用决策树的划分边界来作为分箱依据,可以在此基础上做进一步调整
(线上数据常出现的一个问题是“会返回一个单一区间,没有分割”,线下不知道能不能复现这个问题
推测还是和数据不均衡有关,我们设置了叶子结点样本数量最小占比
如果再遇到此类问题,可以尝试关闭|调节该参数)
def optimal_binning_boundary(x: pd.Series, y: pd.Series, nan: float = -999., cut_num = 4) -> list:
"""
利用决策树获得最优分箱的边界值列表
"""
boundary = [] # 待return的分箱边界值列表
x = x.fillna(nan).values # 填充缺失值
y = y.values
clf = DecisionTreeClassifier(criterion='entropy', # “信息熵”最小化准则划分
max_leaf_nodes=cut_num, # 最大叶子节点数
min_samples_leaf=0.05) # 叶子节点样本数量最小占比
clf.fit(x.reshape(-1, 1), y) # 训练决策树
# fig = plt.figure(figsize=(15, 10))
# _ = tree.plot_tree(clf,
# feature_names=features,
# # class_names=,
# filled=True)
# plt.show()
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
threshold = clf.tree_.threshold
for i in range(n_nodes):
if children_left[i] != children_right[i]: # 获得决策树节点上的划分边界值
boundary.append(threshold[i])
boundary.sort()
z = 0.0000000001
min_x = x.min()
max_x = x.max() + z # +0.1是为了考虑后续groupby操作时,能包含特征最大值的样本
boundary = [min_x] + boundary + [max_x]
return boundary
# 测试optimal_binning_boundary函数:
optimal_binning_boundary(x=train_data['RevolvingUtilizationOfUnsecuredLines'],
y=train_data['SeriousDlqin2yrs'])
上面是提取边界函数
下面是分割
def tree_cut(df, cut_num=4, right=False, define_col=None, label_name='label'):
"""
通过决策树获得划分边界,对数据进行分割,默认为4组分箱,可针对不同字段进行人工调节
:param df: 传入待分箱的dataframe
:param cut_num: int,设置的分箱数(小于4组时,会按照实际存在的类别分)
:param right: bool,False为左闭右开,True为左开右闭)
:param define_col: dict,对指定字段a设置其分箱数
:return: 所有列的分箱结果
"""
df_cut = pd.DataFrame()
if define_col:
col_name = list(set(df.columns) - set(define_col.keys()) - set(label_name))
else:
col_name = list(filter(None, [each if each != label_name else None for each in [*df.columns]]))
for each in col_name:
tree_boundary = optimal_binning_boundary(x=train_data[each],
y=train_data[label_name],
cut_num=cut_num)
df_cut[each] = pd.cut(df[each], bins=tree_boundary, right=right)
if define_col:
for each in define_col.keys():
tree_boundary = optimal_binning_boundary(x=train_data[each],
y=train_data[label_name],
cut_num=define_col[each])
df_cut[each] = pd.cut(df[each], bins=tree_boundary, right=right)
return df_cut
ll = tree_cut(df_train,label_name='SeriousDlqin2yrs')
3.处理不均衡分箱
用于数据分布严重不均衡的时候,eg:前60%都是0,到70%之后开始有值,取我们在分位数上的第一个值作为分箱边界划分时的最小值,切分有值后的区间,想要让前面的0值区域划分为一个单独区间时。
[0,0,0,0,0,1,3,4]
前面-1to0为一个区间(即所有0是一个区间,-1为自动补充的)
1到后面作为一个区间开始划分
以numberofdependents字段为例:
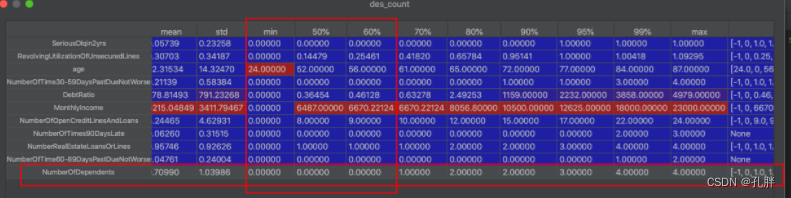
numberofdependents前60%都是0,到70%之后开始有值,-1到0为第一个区间
得到的边界为[-1, 0, 1.0, 1.33, 1.67, 2.0, 4.0]
# 实现一下简单分箱(等距,等频,自定义修改箱数)
# 处理不均衡分箱
def pre_boundary(df):
"""
处理不均衡分箱
:param df: 传入的dataframe
:return: 划分的切割边界
"""
if df['95%'] > 0:
tmp = [.6, .7, .8, .9, .95, .99]
q_val = df[[f"{int(each*100)}%" for each in tmp]].values.tolist()
boundary_1 = list(filter(None, [each if each > 0 else None for each in q_val]))[0]
boundary_2 = list(filter(None, [each if each > 0 else None for each in q_val]))[1]
cut_boundary = [round(each, 2) for each in list(np.linspace(boundary_1, boundary_2, 4))]
if df['min'] == 0:
return [-1, 0] + cut_boundary + [df['max']]
else:
return [df['min']] + [0] + cut_boundary + [df['max']]
else:
return None
# des_count = df_all0.describe([.6, .7, .8, .9, .95, .99]).T
# des_count['boundary'] = des_count.apply(lambda x:pre_boundary(x),axis=1)
上面这个是针对不均衡数据调试时采用的分箱函数,返回的是各字段的切割边界。
统计分箱效果
1.计算woe值,iv值等
bins_count函数,给定分好箱的df,返回计算的woe、iv值等结果。
# 初步查看各组分箱效果
def bins_count(df, df_label):
"""
计算分箱效果
:param df: dataframe,查看分箱的列
:param df_label: dataframe,标签列(一定要是dataframe,不能是series)
:return: result_df(指标计算结果),col_iv(各特征的iv值)
"""
df_label.columns = ['y']
fe_li = df.columns
df = pd.concat([df, df_label],axis=1)
result_df = pd.DataFrame()
for each in fe_li:
# print(each)
grouped = df.groupby(each)['y'] # 统计各分箱区间的好、坏、总客户数量
result_df0 = grouped.agg([('good', lambda y: (y == 0).sum()),
('bad', lambda y: (y == 1).sum()),
('total', 'count')])
result_df0['good_pct'] = result_df0['good'] / result_df0['good'].sum() # 好客户占比
result_df0['bad_pct'] = result_df0['bad'] / result_df0['bad'].sum() # 坏客户占比
result_df0['total_pct'] = result_df0['total'] / result_df0['total'].sum() # 总客户占比
result_df0['bad_rate'] = result_df0['bad'] / result_df0['total'] # 坏比率
result_df0['woe'] = np.log(result_df0['good_pct'] / result_df0['bad_pct']) # WOE
result_df0['iv'] = (result_df0['good_pct'] - result_df0['bad_pct']) * result_df0['woe'] # IV
# print(result_df0)
# result_df0 = result_df0.reset_index(names='bins') # 根据pandas版本,看能不能用names
result_df0.index.name = 'bins'
result_df0 = result_df0.reset_index()
result_df0['bin_names'] = each
result_df = result_df.append(result_df0)
col_iv = result_df.groupby('bin_names')['iv'].sum().sort_values(ascending=False)
return result_df[['bins', 'bin_names', 'good', 'bad', 'total', 'bad_rate', 'woe', 'iv']], col_iv
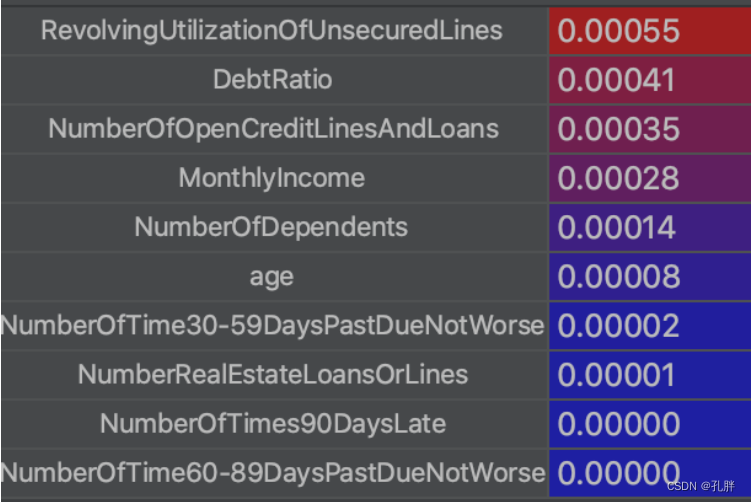
cc, bb = bins_count(ll, df_train[['SeriousDlqin2yrs']])
tmp = cc.query("bin_names == 'age'")
eg中的输入:
-
ll为分箱好后的各字段
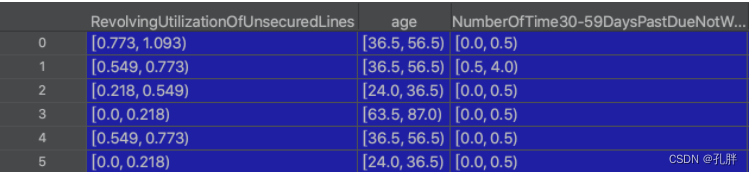
-
dataframe形式的y标签
eg中的输出: -
cc为各字段各分箱下的统计结果
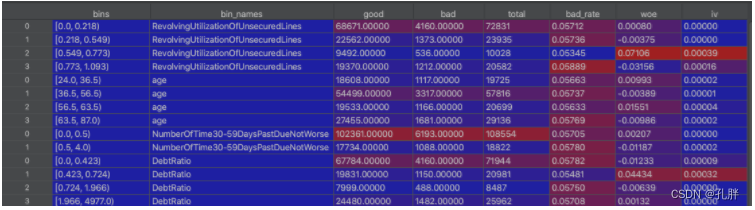
-
bb为各字段的信息值(可以根据此结果从筛选过滤字段后,再进行二次分箱调节)
2.异常情况处理——woe、iv值出现∞
可以参考下面几个文档的内容:
- 本质上还是采样问题,可以调整融合分箱或者重新采样,使得样本里尽可能包含各种情况下的预测目标

这个解答下面还提到的另外两个点,大意都是调整调整分箱边界
- 如果为了快速处理,也可以参照第三个链接,把woe值的计算公式做一个小的处理
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
https://stats.stackexchange.com/questions/418109/dealing-with-of-events-0-in-a-bin-when-computing-weight-of-evidence-woe(重点!)
https://stats.stackexchange.com/questions/196654/how-to-calculate-woe-weight-of-evidence-for-single-class-bins
https://blog.csdn.net/weixin_44625028/article/details/123716573
3.异常情况处理——字段iv值很大
这里需要注意一个问题是:
- 不同的文档可能略有差异,但一般iv值低于0.03我们就不认为其具有区分力度了。IV在0.1到0.5之间的变量通常具有中等-高区分性,可以优先入模。
- 如果iv值过大了,很高了,可能意味着该变量为滞后变量,需要结合业务逻辑进行辨别。
(IV一般用于变量筛选。IV值过低的变量不具有区分能力,还可能对模型产生干扰,应该予以舍弃。正常情况下,IV在0.1到0.5之间的变量都可以先加入模型。
IV过高并不是好事,需要警惕。它说明这个变量对y的区分度极好。很有可能它是滞后变量。比如B卡中的某些贷后变量就可能会有很高的IV值。此时需要结合业务逻辑进行排查。)
参考链接:https://zhuanlan.zhihu.com/p/110369440?utm_source=qq&utm_id=0
初步绘图查看分箱效果
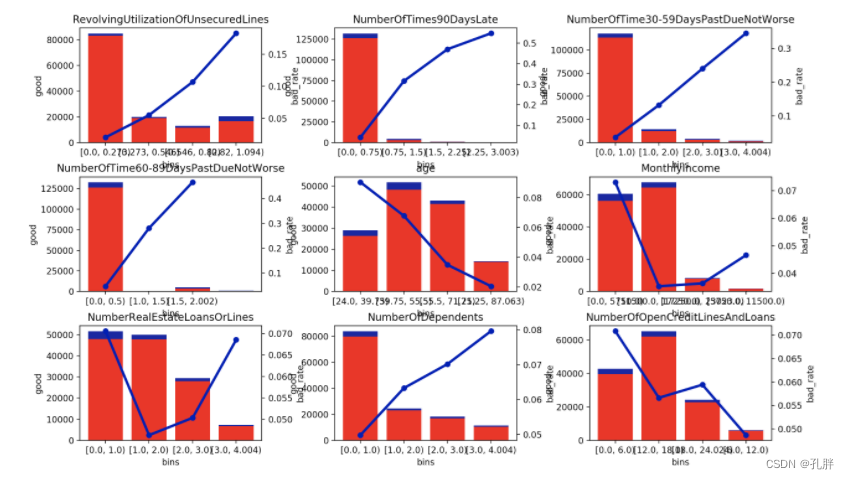
1.单个字段绘图
绘制单个变量各分箱的好坏数量以及bad_rate(这里目前是bad_rate,如果不想那么严格要求bad_rate的话,后面也可以换成woe值,保证woe值单调就可以了)
def plot_box_result(df, col_name):
tmp = df[df['bin_names'] == col_name]
fig, ax = plt.subplots(1, 1, figsize=(10,10))
sns.barplot(x=tmp.bins, y=tmp.total, color="#0000A3")
bottom_plot = sns.barplot(x=tmp.bins, y=tmp.good, color="red")
topbar = plt.Rectangle((0, 0), 1, 1, fc="#0000A3", edgecolor='none')
bottombar = plt.Rectangle((0, 0), 1, 1, fc='red', edgecolor='none')
l = plt.legend([bottombar, topbar], ['good', 'bad'], loc=2, ncol=1, prop={'size': 10})
l.draw_frame(False)
ax2 = ax.twinx() # 一定要放在这里啊
sns.lineplot(x=tmp["bins"].astype(str), y="bad_rate", data=tmp,
marker='o', lw=3, color="#0000A3",
linestyle='--', markeredgecolor='#0000A3', ax=ax2)
plt.title(col_name)
plt.show() # 明天对照着收藏夹整理一下这部分画图
plot_box_result(cc, 'age') # cc是前面bins_count的产出
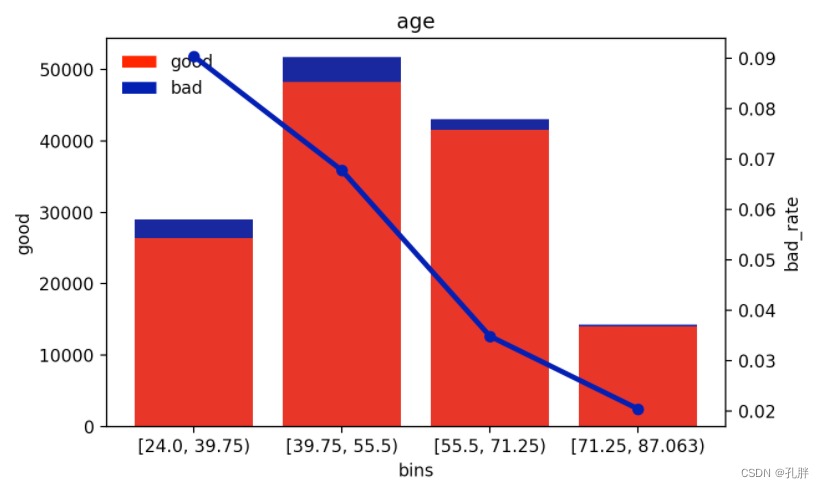
这个age分箱还可以,bad_rate单调性很明显
2.对比多个字段一起查看
def plot_filteredfe(df, bb):
aa = bb[bb > 0.03]
fig_num = aa.shape[0]
fig_col = 3 # 一行最多画3张图
fig_row = math.ceil(fig_num / fig_col)
fig, axs = plt.subplots(fig_row, fig_col, figsize=(8 * fig_col, 8 * fig_row)) # larger figure size for subplots
# ax2s = axs.twinx() # 一定要放在这里啊
# fig.tight_layout()
for i in range(fig_num):
tmp = df[df['bin_names'] == bb.index[i]]
col_name = aa.index[i]
if (i+1) % fig_col != 0:
xx = (i+1) % fig_col - 1
yy = (i+1)//fig_col
else:
xx = fig_col - 1
yy = (i+1)//fig_col - 1
# print(yy,xx)
ax1 = axs[yy][xx]
# ax = axs[0]
# print(ax.rowNum,ax.colNum)
sns.barplot(x=tmp.bins, y=tmp.total, color="#0000A3", ax=ax1)
bottom_plot = sns.barplot(x=tmp.bins, y=tmp.good, color="red", ax=ax1)
# topbar = plt.Rectangle((0, 0), 1, 1, fc="#0000A3", edgecolor='none')
# bottombar = plt.Rectangle((0, 0), 1, 1, fc='red', edgecolor='none')
# l = plt.legend([bottombar, topbar], ['good', 'bad'], loc=2, ncol=1, prop={'size': 10})
# l.draw_frame(False)
ax2 = ax1.twinx() # 一定要放在这里啊
# ax2 = ax2s[yy][xx]
# print('ax2',ax2.rowNum,ax2.colNum)
sns.lineplot(x=tmp["bins"].astype(str), y="bad_rate", data=tmp,
marker='o', lw=3, color="#0000A3",
linestyle='--', markeredgecolor='#0000A3', ax=ax2)
plt.title(col_name)
plt.subplots_adjust(wspace=0.4,hspace=0.3)
plt.show()
plot_filteredfe(cc, bb)
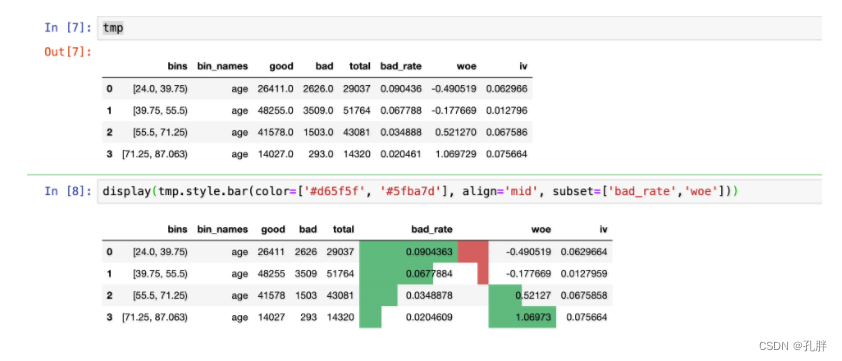
3.jupyter中直接查看df
tmp是之前bins_count计算出来的统计结果
display(tmp.style.bar(color=['#d65f5f', '#5fba7d'], align='mid', subset=['bad_rate','woe'])) # 可以快速查看bad_rate和woe
评分卡工具
1.第三方python库–OptBinning(重点,单开一篇介绍)
OptBinning is a library written in Python implementing a rigorous and flexible mathematical programming formulation to solve the optimal binning problem for a binary, continuous and multiclass target type, incorporating constraints not previously addressed.
先大概看一下有哪些应用范畴,好的话可以专门开一篇介绍。
git地址:https://github.com/guillermo-navas-palencia/optbinning/tree/master(还放了两片文章,好像和流数据分箱相关,另外这个库的教程写的不是很全面,如后面涉及optimal piecewise binning的OptimalPWBinning,感觉他描述的并不是很全面,需要结合他的文章再看一下才能理解它这个piecewise的概念(目前看感觉是不均匀的分箱,每段分箱间距都不一样!!!))
教程地址:https://gnpalencia.org/optbinning/tutorials.html#optimal-binning-tutorials
另:
这个创作者的博客还记载了另外一个软件用于ab test(ab测试):https://gnpalencia.org/software.html
2.第三方python库–toad
Toad is dedicated to facilitating model development process, especially for a scorecard. It provides intuitive functions of the entire process, from EDA, feature engineering and selection etc. to results validation and scorecard transformation. Its key functionality streamlines the most critical and time-consuming process such as feature selection and fine binning.
Toad 是专为工业界模型开发设计的Python工具包,特别针对评分卡的开发。Toad 的功能覆盖了建模全流程,从 EDA、特征工程、特征筛选 到 模型验证和评分卡转化。Toad 的主要功能极大简化了建模中最重要最费时的流程,即特征筛选和分箱。
git地址:
https://github.com/amphibian-dev/toad
这个是中文的哦~
-
一个总结
比较全的评分卡工具介绍可以看这里:
https://mp.weixin.qq.com/s/-WO74VGu83LqNtM7VrSzOQ -
一个总结
这里的最下面也有:
https://mp.weixin.qq.com/s/mzfLqhld_OcXMsjiMcx8FQ
它给出的建议是:
一般,评分卡只要用optbinning 与 toad 就够了。 -
alpha tools(付费的,博客里面为了恰饭推荐的,哈哈哈,感觉不是非常不会编程,可以不看这个工具)
这个人的博客里面有提及,但还没有仔细看:https://zhuanlan.zhihu.com/p/521833066
评分卡相关-很好但还没读的文章
https://zhuanlan.zhihu.com/p/521833066
https://mp.weixin.qq.com/s/mzfLqhld_OcXMsjiMcx8FQ