语言模型概述
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布,这样的模型称为语言模型。
# 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如:
src1 = "I can do" tgt1 = "can do it"
src2 = "can do it", tgt2 = "do it <eos>"
语言模型能解决哪些问题:
- 根据语言模型的定义,可以在它的基础上完成机器翻译,文本生成等任务,因为通过最后输出的概率分布来预测下一个词汇是什么。
- 语言模型可以判断输入的序列是否为一句完整的话,因为可以根据输出的概率分布查看最大概率是否落在句子结束符上,来判断完整性。
- 语言模型本身的训练目标是预测下一个词,因为它的特征提取部分会抽象很多语言序列之间的关系,这些关系可能同样对其他语言类任务有效果。因此可以作为预训练模型进行迁移学习。
语言模型实现
- 第一步: 导入必备的工具包
- 第二步: 导入wikiText-2数据集并作基本处理
- 第三步: 构建用于模型输入的批次化数据
- 第四步: 构建训练和评估函数
- 第五步: 进行训练和评估(包括验证以及测试)
1. 导入必备的工具包
# 数学计算工具包math
import math
# torch以及torch.nn, torch.nn.functional
import torch
import torch.nn as nn
import torch.nn.functional as F
# torch中经典文本数据集有关的工具包
# 具体详情参考下方torchtext介绍
import torchtext
# torchtext中的数据处理工具, get_tokenizer用于英文分词
from torchtext.data.utils import get_tokenizer
# 已经构建完成的TransformerModel
from pyitcast.transformer import TransformerModel2. 导入wikiText-2数据集并作基本处理
# 创建语料域, 语料域是存放语料的数据结构,
# 它的四个参数代表给存放语料(或称作文本)施加的作用.
# 分别为 tokenize,使用get_tokenizer("basic_english")获得一个分割器对象,
# 分割方式按照文本为基础英文进行分割.
# init_token为给文本施加的起始符 <sos>给文本施加的终止符<eos>,
# 最后一个lower为True, 存放的文本字母全部小写.
TEXT = torchtext.data.Field(tokenize=get_tokenizer("basic_english"),
init_token='<sos>',
eos_token='<eos>',
lower=True)
# 最终获得一个Field对象.
# <torchtext.data.field.Field object at 0x7fc42a02e7f0>
# 然后使用torchtext的数据集方法导入WikiText2数据,
# 并切分为对应训练文本, 验证文本,测试文本, 并对这些文本施加刚刚创建的语料域.
train_txt, val_txt, test_txt = torchtext.datasets.WikiText2.splits(TEXT)
# 我们可以通过examples[0].text取出文本对象进行查看.
# >>> test_txt.examples[0].text[:10]
# ['<eos>', '=', 'robert', '<unk>', '=', '<eos>', '<eos>', 'robert', '<unk>', 'is']
# 将训练集文本数据构建一个vocab对象,
# 这样可以使用vocab对象的stoi方法统计文本共包含的不重复词汇总数.
TEXT.build_vocab(train_txt)
# 然后选择设备cuda或者cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
3. 构建用于模型输入的批次化数据
- 批次化过程的第一个函数batchify代码分析:
def batchify(data, bsz):
"""batchify函数用于将文本数据映射成连续数字, 并转换成指定的样式, 指定的样式可参考下图.
它有两个输入参数, data就是我们之前得到的文本数据(train_txt, val_txt, test_txt),
bsz是就是batch_size, 每次模型更新参数的数据量"""
# 使用TEXT的numericalize方法将单词映射成对应的连续数字.
data = TEXT.numericalize([data.examples[0].text])
# >>> data
# tensor([[ 3],
# [ 12],
# [3852],
# ...,
# [ 6],
# [ 3],
# [ 3]])
# 接着用数据词汇总数除以bsz,
# 取整数得到一个nbatch代表需要多少次batch后能够遍历完所有数据
nbatch = data.size(0) // bsz
# 之后使用narrow方法对不规整的剩余数据进行删除,
# 第一个参数是代表横轴删除还是纵轴删除, 0为横轴,1为纵轴
# 第二个和第三个参数代表保留开始轴到结束轴的数值.类似于切片
# 可参考下方演示示例进行更深理解.
data = data.narrow(0, 0, nbatch * bsz)
# >>> data
# tensor([[ 3],
# [ 12],
# [3852],
# ...,
# [ 78],
# [ 299],
# [ 36]])
# 后面不能形成bsz个的一组数据被删除
# 接着我们使用view方法对data进行矩阵变换, 使其成为如下样式:
# tensor([[ 3, 25, 1849, ..., 5, 65, 30],
# [ 12, 66, 13, ..., 35, 2438, 4064],
# [ 3852, 13667, 2962, ..., 902, 33, 20],
# ...,
# [ 154, 7, 10, ..., 5, 1076, 78],
# [ 25, 4, 4135, ..., 4, 56, 299],
# [ 6, 57, 385, ..., 3168, 737, 36]])
# 因为会做转置操作, 因此这个矩阵的形状是[None, bsz],
# 如果输入是训练数据的话,形状为[104335, 20], 可以通过打印data.shape获得.
# 也就是data的列数是等于bsz的值的.
data = data.view(bsz, -1).t().contiguous()
# 最后将数据分配在指定的设备上.
return data.to(device)
- batchify的样式转化图
大写字母A,B,C ... 代表句子中的每个单词
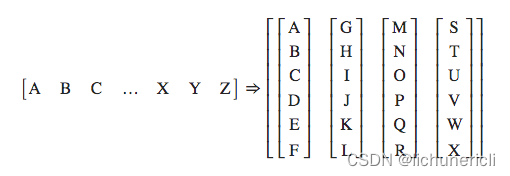
- 接下来将使用batchify来处理训练数据,验证数据以及测试数据
# 训练数据的batch size
batch_size = 20
# 验证和测试数据(统称为评估数据)的batch size
eval_batch_size = 10
# 获得train_data, val_data, test_data
train_data = batchify(train_txt, batch_size)
val_data = batchify(val_txt, eval_batch_size)
test_data = batchify(test_txt, eval_batch_size)
- 上面的分割批次并没有进行源数据与目标数据的处理,接下来将根据语言模型训练的语料规定来构建源数据与目标数据。
- 语言模型训练的语料规定:如果源数据为句子ABCD,ABCD代表句子中的词汇或符号,则它的目标数据为BCDE,BCDE分别代表ABCD的下一个词汇
- 如图所示,这里的句子序列是竖着的,而且发现如果用一个批次处理完所有数据,以训练数据为例,每个句子长度高达104335,这明显是不科学的,因此在这里要限定每个批次中的句子长度允许的最大值bptt。
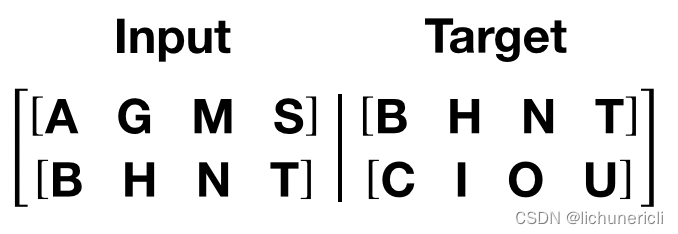
- 批次化过程的第二个函数get_batch代码分析
# 令子长度允许的最大值bptt为35
bptt = 35
def get_batch(source, i):
"""用于获得每个批次合理大小的源数据和目标数据.
参数source是通过batchify得到的train_data/val_data/test_data.
i是具体的批次次数.
"""
# 首先我们确定句子长度, 它将是在bptt和len(source) - 1 - i中最小值
# 实质上, 前面的批次中都会是bptt的值, 只不过最后一个批次中, 句子长度
# 可能不够bptt的35个, 因此会变为len(source) - 1 - i的值.
seq_len = min(bptt, len(source) - 1 - i)
# 语言模型训练的源数据的第i批数据将是batchify的结果的切片[i:i+seq_len]
data = source[i:i+seq_len]
# 根据语言模型训练的语料规定, 它的目标数据是源数据向后移动一位
# 因为最后目标数据的切片会越界, 因此使用view(-1)来保证形状正常.
target = source[i+1:i+1+seq_len].view(-1)
return data, target
4. 构建训练和评估函数
- 设置模型超参数和初始化模型
# 通过TEXT.vocab.stoi方法获得不重复词汇总数
ntokens = len(TEXT.vocab.stoi)
# 词嵌入大小为200
emsize = 200
# 前馈全连接层的节点数
nhid = 200
# 编码器层的数量
nlayers = 2
# 多头注意力机制的头数
nhead = 2
# 置0比率
dropout = 0.2
# 将参数输入到TransformerModel中
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)
# 模型初始化后, 接下来进行损失函数和优化方法的选择.
# 关于损失函数, 我们使用nn自带的交叉熵损失
criterion = nn.CrossEntropyLoss()
# 学习率初始值定为5.0
lr = 5.0
# 优化器选择torch自带的SGD随机梯度下降方法, 并把lr传入其中
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
# 定义学习率调整方法, 使用torch自带的lr_scheduler, 将优化器传入其中.
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
- 模型训练代码分析
# 导入时间工具包
import time
def train():
"""训练函数"""
# 模型开启训练模式
model.train()
# 定义初始损失为0
total_loss = 0.
# 获得当前时间
start_time = time.time()
# 开始遍历批次数据
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
# 通过get_batch获得源数据和目标数据
data, targets = get_batch(train_data, i)
# 设置优化器初始梯度为0梯度
optimizer.zero_grad()
# 将数据装入model得到输出
output = model(data)
# 将输出和目标数据传入损失函数对象
loss = criterion(output.view(-1, ntokens), targets)
# 损失进行反向传播以获得总的损失
loss.backward()
# 使用nn自带的clip_grad_norm_方法进行梯度规范化, 防止出现梯度消失或爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
# 模型参数进行更新
optimizer.step()
# 将每层的损失相加获得总的损失
total_loss += loss.item()
# 日志打印间隔定为200
log_interval = 200
# 如果batch是200的倍数且大于0,则打印相关日志
if batch % log_interval == 0 and batch > 0:
# 平均损失为总损失除以log_interval
cur_loss = total_loss / log_interval
# 需要的时间为当前时间减去开始时间
elapsed = time.time() - start_time
# 打印轮数, 当前批次和总批次, 当前学习率, 训练速度(每豪秒处理多少批次),
# 平均损失, 以及困惑度, 困惑度是衡量语言模型的重要指标, 它的计算方法就是
# 对交叉熵平均损失取自然对数的底数.
print('| epoch {:3d} | {:5d}/{:5d} batches | '
'lr {:02.2f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f}'.format(
epoch, batch, len(train_data) // bptt, scheduler.get_lr()[0],
elapsed * 1000 / log_interval,
cur_loss, math.exp(cur_loss)))
# 每个批次结束后, 总损失归0
total_loss = 0
# 开始时间取当前时间
start_time = time.time()
- 模型评估代码分析
def evaluate(eval_model, data_source):
"""评估函数, 评估阶段包括验证和测试,
它的两个参数eval_model为每轮训练产生的模型
data_source代表验证或测试数据集"""
# 模型开启评估模式
eval_model.eval()
# 总损失归0
total_loss = 0
# 因为评估模式模型参数不变, 因此反向传播不需要求导, 以加快计算
with torch.no_grad():
# 与训练过程相同, 但是因为过程不需要打印信息, 因此不需要batch数
for i in range(0, data_source.size(0) - 1, bptt):
# 首先还是通过通过get_batch获得验证数据集的源数据和目标数据
data, targets = get_batch(data_source, i)
# 通过eval_model获得输出
output = eval_model(data)
# 对输出形状扁平化, 变为全部词汇的概率分布
output_flat = output.view(-1, ntokens)
# 获得评估过程的总损失
total_loss += criterion(output_flat, targets).item()
# 计算平均损失
cur_loss = total_loss / ((data_source.size(0) - 1) / bptt)
# 返回平均损失
return cur_loss
5. 进行训练和评估
- 模型的训练与验证代码分析
# 首先初始化最佳验证损失,初始值为无穷大
import copy
best_val_loss = float("inf")
# 定义训练轮数
epochs = 3
# 定义最佳模型变量, 初始值为None
best_model = None
# 使用for循环遍历轮数
for epoch in range(1, epochs + 1):
# 首先获得轮数开始时间
epoch_start_time = time.time()
# 调用训练函数
train()
# 该轮训练后我们的模型参数已经发生了变化
# 将模型和评估数据传入到评估函数中
val_loss = evaluate(model, val_data)
# 之后打印每轮的评估日志,分别有轮数,耗时,验证损失以及验证困惑度
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
# 我们将比较哪一轮损失最小,赋值给best_val_loss,
# 并取该损失下的模型为best_model
if val_loss < best_val_loss:
best_val_loss = val_loss
# 使用深拷贝,拷贝最优模型
best_model = copy.deepcopy(model)
# 每轮都会对优化方法的学习率做调整
scheduler.step()
- 模型测试代码分析
# 我们仍然使用evaluate函数,这次它的参数是best_model以及测试数据
test_loss = evaluate(best_model, test_data)
# 打印测试日志,包括测试损失和测试困惑度
print('=' * 89)
print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(
test_loss, math.exp(test_loss)))
print('=' * 89)



![[翻译]理解Postgres的IOPS:为什么数据即使都在内存,IOPS也非常重要](https://img-blog.csdnimg.cn/img_convert/1e8e7e3ac9e0cf1dc5e3e6612cf80ba8.png)