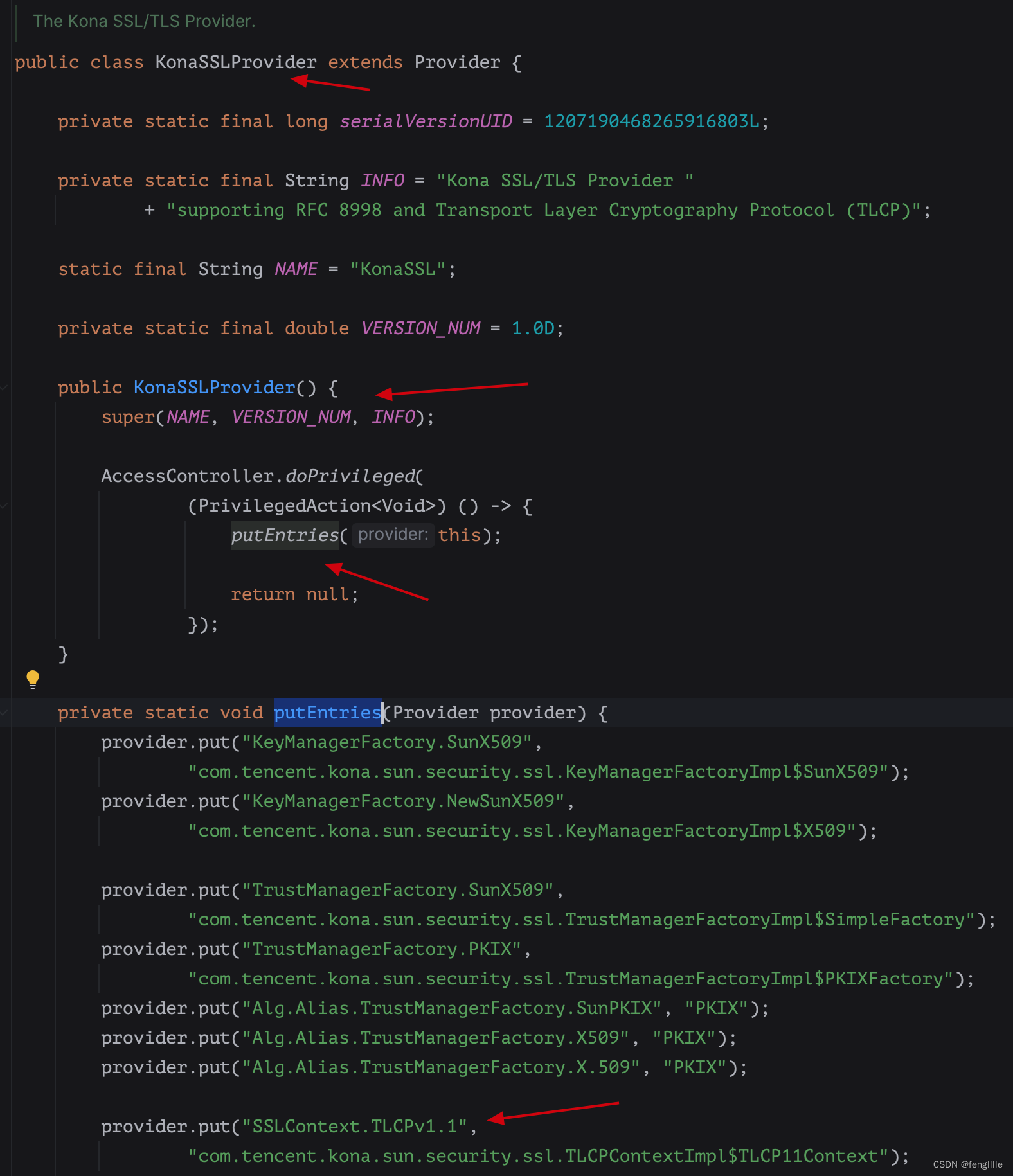
梯度泄露的攻击方法:深度泄露梯度(DLG)——>在高度压缩的场景下是失效的
原因:梯度压缩(可减小通信开销)——>存在信息损失<——从而DLG方法效果有限
但是这本身存在的信息损失怎么解决呢?会对所要达成的目标有影响吗?
揭示在梯度压缩防御设置下攻击者可获取多少隐私数据
度量的标准是什么呢?
在高度压缩的场景下梯度泄露攻击的方法:
- 基于属性推断的梯度泄露攻击:攻击者从共享梯度推断出原始私有训练数据的具体属性,以此作为先验信息补偿进行梯度泄露攻击
基于属性推断的梯度泄露攻击是一种针对深度学习模型的攻击方式。在这种攻击中,攻击者利用模型在训练过程中泄漏的梯度信息,推断出训练数据中包含的具体属性。这些属性可以包括性别、年龄、种族等等,攻击者利用这些属性作为先验信息,进一步进行攻击,例如针对特定群体的歧视性攻击。
梯度泄露是指在训练深度学习模型时,模型参数的更新算法会使用到训练数据的梯度信息。这些梯度信息包含了训练数据中的敏感信息,如果这些信息被攻击者获取,就可以用来推断出训练数据的具体属性。基于属性推断的梯度泄露攻击就是利用这种泄露的梯度信息,对训练数据进行推断,从而获取其中的具体属性。
这种攻击方式对深度学习模型的安全性造成了严重威胁。为了防止这种攻击,研究人员提出了一些防御方法,例如对抗训练、梯度掩盖等。这些方法可以增加模型的鲁棒性,防止攻击者利用梯度信息进行属性推断攻击攻击者首先准备一个辅助数据集,该数据集中包含数据- 属性对;然后,攻击者将这些数据输入联邦学习的全局模型中 (这个全局模型是如何获得呢) ,从而获得梯度- 属性对;最后,攻击者使用这些梯度 - 属性对来训练一个判别网络。在攻击阶段,攻击者只需要将捕获的梯度输入到已训练好的判别网络中,即可推断私有训练数据属性。
- 基于特征推断的梯度泄露攻击:在基于属性推断的梯度泄露攻击失效的情况下,攻击者从共享梯度推断出原始训练数据的低维向量表征,以此作为先验信息补偿进行梯度泄露攻击
这种攻击方法将梯度信息视为一种泄露的信号,通过分析这个信号,攻击者可以获取到训练数据中的有用信息。
在这种攻击中,攻击者利用梯度信息推断出原始训练数据在某个低维空间中的表征。这个低维空间可能是一个由模型学到的特征空间,或者是一个由攻击者预先设定的空间。攻击者利用推断出的低维向量表征作为先验信息,进一步进行攻击。
基于特征推断的梯度泄露攻击相对于基于属性推断的梯度泄露攻击更加复杂,因为它需要攻击者对模型的内部结构有一定的了解。
- 基于特征生成的梯度泄露攻击:在此方法中,攻击者进一步改进了基于特征推断的梯度泄露攻击,从共享梯度中推断出原始数据的特征后,利用该特征生成一张初始化图像,以此作为先验信息补偿进行梯度泄露攻击
基于特征推断的梯度泄露攻击和基于特征生成的梯度泄露攻击都是针对深度学习模型的攻击方式。这两种攻击方式的主要目标是推断出原始训练数据的特征,并利用这些特征进行攻击。不同之处在于,基于特征生成的梯度泄露攻击在推断出原始数据的特征后,进一步生成了一个初始化图像,作为先验信息进行梯度泄露攻击。
在这两种攻击方法中,攻击者首先需要从共享的梯度信息中推断出原始数据的特征。这些特征可以被看作是原始数据在某个特征空间中的表示。然后,攻击者利用这些推断出的特征生成一张初始化图像。这个初始化图像可以作为先验信息,帮助攻击者更好地进行梯度泄露攻击。
基于特征生成的梯度泄露攻击的优点在于,它不仅可以推断出原始数据的特征,还可以生成一个初始化图像。这个初始化图像可以作为攻击者的参考,使得攻击者更容易地进行梯度泄露攻击。
- 基于梯度生成的梯度泄露攻击:为了解决前三种攻击方式重构效率较低且不适用于批量数据重构的问题,该方法中的攻击者直接利用生成网络从共享梯度中生成一张图像,以此直接 作为私有数据重构结果。(我咋理解这个方法就是类似于DLG方法呀)
基于梯度生成的梯度泄露攻击是针对深度学习模型的一种攻击方式。与基于特征推断的梯度泄露攻击和基于特征生成的梯度泄露攻击不同,基于梯度生成的梯度泄露攻击直接从共享的梯度信息中生成一张图像,作为私有数据重构的结果。
这种攻击方法的优点在于,它可以直接从共享梯度中生成一张图像,而不需要进行特征推断或生成初始化图像。这意味着攻击者可以更有效地利用梯度信息进行数据重构。此外,这种攻击方法还可以应用于批量数据重构,而不仅仅是对单个数据点进行重构。
然而,需要注意的是,基于梯度生成的梯度泄露攻击仍然依赖于梯度信息,因此,它也可能会受到梯度泄露防御方法的抵抗。为了防止这种攻击,研究人员需要开发新的防御方法,以提高模型的安全性和鲁棒性
从视觉效果和客观数值指标进行验证
联邦学习中的梯度出现挑战:
-
暴露原始训练数据的某些属性
-
利用生成对抗网络生成与私有训练图像类似的图片
在高压缩的情况下攻击方是如何从梯度中复原数据?
虚假数据的定义标准是什么?
基于优化的攻击方法通常需要通过不断的迭代和调整来寻找最佳解决方案,而基于闭式解的攻击则直接提供一个明确的解决方案。闭式解是指一个问题的解决方案可以通过一组明确的数学表达式或算法来表示。这意味着,一旦我们有了问题的具体条件,就可以直接计算出解决方案,而不需要进行进一步的优化或调整。闭式解是指一个问题的解决方案可以通过一组明确的数学表达式或算法来表示。这意味着,一旦我们有了问题的具体条件,就可以直接计算出解决方案,而不需要进行进一步的优化或调整。
基于特征的梯度泄露攻击方法:基于特征推断的攻击方法,它可以从梯度中推断出原始数据的特征,并自动提取辅助数据集中的抽象特征,避免了对手动标注的二元属性值的需求。
第二种方法是基于特征生成的攻击方法,它可以利用从梯度中预先推断出的特征来生成图像,并扩大了虚假图像的空间,使得初始化虚假图像更有希望接近原始的真实图像,进而提高图像的重构效果。
- 参数服务器由于仅有模型聚合和分发的功能,它无法知道模型每个神经元所对应的真实标签是什么。
- 敌手不可能事先拥有与私有训练数据分布一致的辅助数据。


梯度压缩是一种用于减少神经网络训练中梯度消失或梯度爆炸问题的技术。然而,梯度压缩本身是一个不可微的操作,因为它不满足链式法则。
在梯度压缩中, 通常会使用一种阈值来决定哪些梯度值需要被压缩。topK 是一种流行的压缩算法,它会将低于某个阈值的梯度值置为 0。这种操作是不可微的,因为它直接将梯度值设置为 0,而不是通过一个可微的函数来压缩梯度。
如果优化目标是使压缩后的梯度与原始梯度尽可能相似,那么这个优化目标必须是二阶可微的。这是因为梯度消失或梯度爆炸问题通常与一阶导数有关,而二阶导数可以提供更丰富的信息来优化梯度。然而,直接将梯度值置为 0 的操作不满足二阶可微性,因此可能会导致优化困难。
因此,如果要使用梯度压缩来解决梯度消失或梯度爆炸问题,那么需要选择一种可微的压缩算法,或者使用其他技术来增加梯度的信息量。


![[SQL开发笔记]在windows系统安装Postgres](https://img-blog.csdnimg.cn/2b18009a42bf45a39774cae2a9ff35b7.png)