文章目录
- 双端口RAM
- 多模块存储器
- 多体并行存储器
- 高位交叉编址
- 低位交叉编址
- 单体多字存储器
- 存储周期和访存
双端口RAM

在双端口RAM中,两个端口使用了不同的译码器,数据线,控制线,和读写电路。所以两个端口可以做到同时访问相同的存储单元。
访存的时候不是有恢复时间吗?为什么双端口RAM可以做到同时访问相同的存储的单元?
首先,恢复时间的存在一定是为了存储器工作进行状态的恢复,例如刷新,在DRAM中,因为需要刷新所以导致恢复时间很长。但是在双端口RAM中我们可以不考虑这个恢复时间带来因素,因为刷新的时候处于死区,这时候是不可能会进行访存的,所以我们应该讲恢复时间认为是存储器内部状态的恢复,并且这个恢复应该是控制电路的恢复。而在双端口RAM中,两个端口采用了不同的控制电路,数据线,控制线,地址线等所以两者的恢复时间是没有任何关系的,因为电路都不同。
双端口RAM对主存操作具有以下四种情况:
两个端口同时对不同的地址单元存取数据
两个端口同时对相同的地址单元读出数据
下面的两种情况是可能会发生错误的:
两个端口同时对同一地址单元写入数据
两个端口同时对同一地址单元进行操作,一个读入,一个写出。
在双端口RAM中对于这个进行了解决:
在双端口RAM中,有逻辑判断电路,其会根据两个端口的读写信号进行逻辑判断,当碰到下面的两种错误情况时,逻辑电路会发送一个busy信号给其中一个端口,即将这个端口关闭(延时)一段时间,先让另一个端口进行访问。
多模块存储器
多模块存储器是一种空间并行技术,利用多个结构完全相同的存储器芯片(宏观上并行,微观上交替)并行工作来提高存储器的吞吐率,常用的有单体多字存储器,和多体低位交叉存储器。(多体高位交叉存储器也是多模块存储器,但是其比较难完成宏观上并行,因为地址是在一个存储器芯片内连续存放的)。
如何理解多模块存储器可以提高存储器的吞吐率
首先,吞吐量是单位时间内的响应次数,主机向存储器发起一个响应,存储器需要多久才能回应。而多模块存储器中,通过将数据放在不同的存储器芯片,可以使得宏观上不需要等待存储器芯片的恢复时间,可以更快的取出数据,所以对于存储器而言,吞吐率应该是取出数据的速度。
多体并行存储器
多体并行存储器分为低位交叉编址和高位交叉编址:
在多体并行存储器中,每个存储器芯片具有相同的容量和存取速度(其实就是相同的存储器芯片),每个存储器芯片都有独立的读写电路,数据寄存器,地址寄存器,能够做到并行工作(宏观上),交叉工作,既宏观上每次访存可以选择不同位置的芯片。
多体并行存储器的地址线,数据线,读写线共用吗?
不一定。
高位交叉编址
注:无论是高位交叉编址和低位交叉编址中,题目可能会给一个地址问当前地址所属的芯片是哪一个?我们只要记住一点, 2 n \color{red}{2^n} 2n个芯片,其本质是二进制的取模运算,所以如果是高位交叉编址,那么我就只需要看地址的前n位,如果是低位交叉编址,那我们就只需要看地址的最后n位,然后翻译成十进制我们就可以知道是第几个芯片了,注意的是芯片一般从第0个开始计算。
高位交叉编址:高位说的就是片选信号采用高位地址总线,并且地址在同一个存储芯片内是连续的,其中高位片选信号代表的地址又叫做体号。
高位交叉编址存储器是如何完成译码工作的?
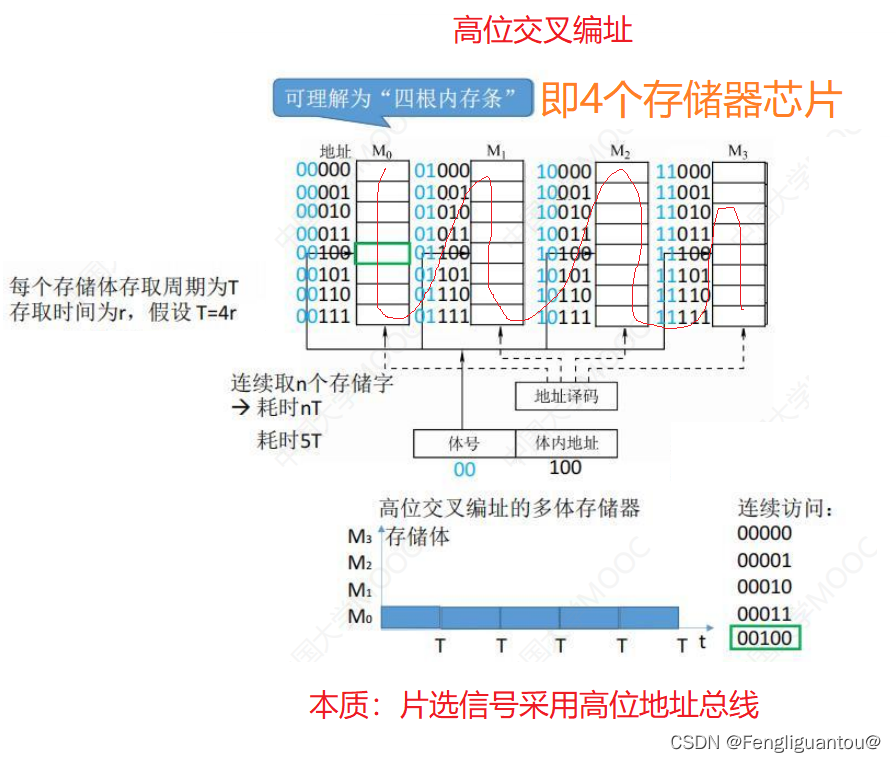
在高位交叉编址中,只有一个存储器芯片具有译码器,一般把译码器设置到高体号的模块内,即最后一个模块内,然后里面的译码器会将翻译后的地址传输给其他模块的存储器芯片,其他存储器芯片内部应该具有缓冲器,就不用对地址进行翻译了,直接选择字选线即可。即地址总线是连接到最后一个模块的译码器内的。
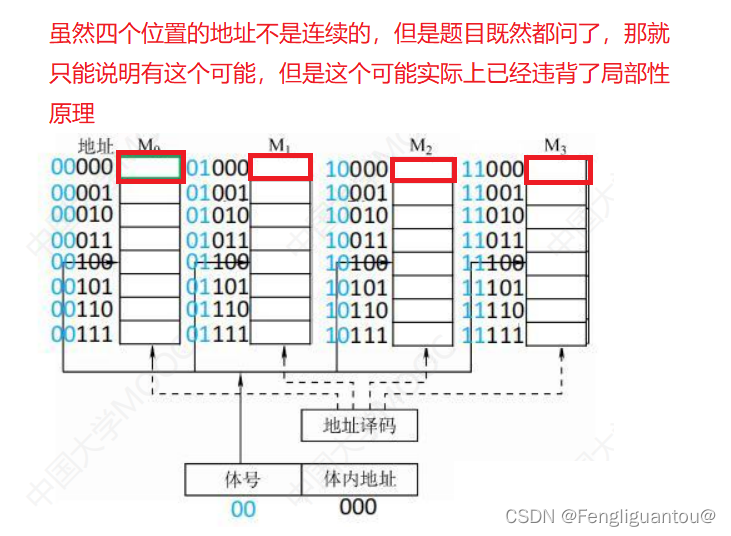
注意:高位交叉编址的多体存储器也有可能可以做到在一个存储周期内访问多个连续的存储器芯片:
这种做法实际上有点逆天。
低位交叉编址
低位交叉编址:低位交叉编址本质上就是片选线采用低位的地址总线,所以地址中最后几位的片选地址又叫做体号,地址在不同的存储器芯片之间是连续的。
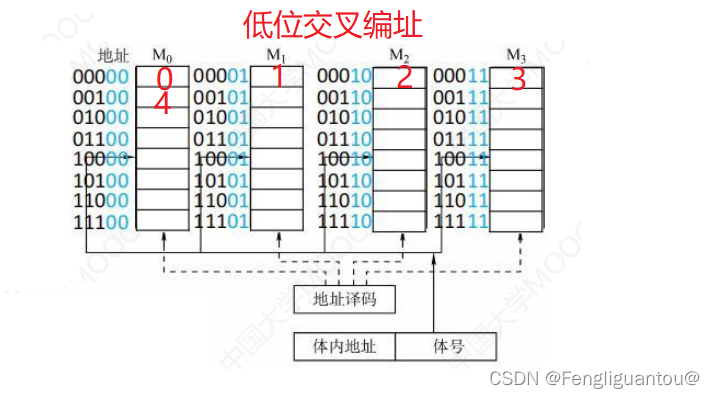
低位交叉编址是如何完成译码的?
在低位交叉编址中,一般把译码器设置到低体号的模块内,即第一个模块内,然后里面的译码器会将翻译后的地址传输给其他模块的存储器芯片,其他存储器芯片内部应该是有寄存器之类的东西,就不用对地址进行翻译了,直接选择子选线即可。即地址总线是连接到第一个模块的译码器内的。
低位交叉编址在读取数据在有什么特点?
依旧还是下面这个图,假设有这个低位交叉编址存储器中具有4个存储器芯片。我们可以发现,因为低位交叉编址是地址是在不同的存储器芯片是连续的,所以读完一个地址以后,可以读取下一个存储器芯片,由于存储器芯片之间的读写电路是独立的,所以读写下一个存储器芯片的时候不需要等待恢复,可以直接进行读写。只要存储器芯片的个数满足一定的条件,在宏观上就可以做到每次读取一个存储器芯片只需要一个存取时间,需要知道,低位交叉编址只有在长时间的连续访问中才能发挥自己的魅力。
事实上,低位交叉编址是一种流水线模型,只有流水线充分流动起来了才能达到我们上述说的宏观上,读取一个存储单元只需要一个存取时间,并且低位交叉编址还需要满足一定的条件:
首先,低位交叉编址中,假设存储周期为T,存取时间为r,那么该低位交叉存储器中存储器芯片的个数应该大于等于T/r,因为只有这样才能避过所有的恢复时间。
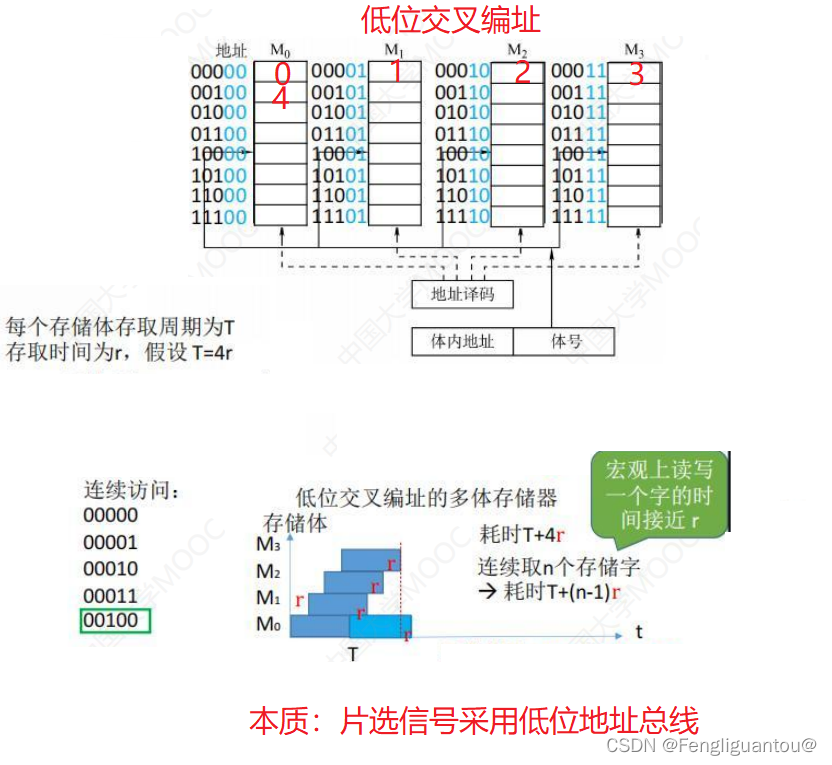
存储器芯片个数<T/r 连续读取时,会需要进行等待芯片的恢复
存储器芯片个数>T/r 连续读取时,虽然不用等待芯片的恢复,但是芯片会存在空闲时间不能完美的发挥芯片的性能
存储器芯片个数=T/r 不需要等待芯片的恢复,可以完美的发挥芯片的性能。
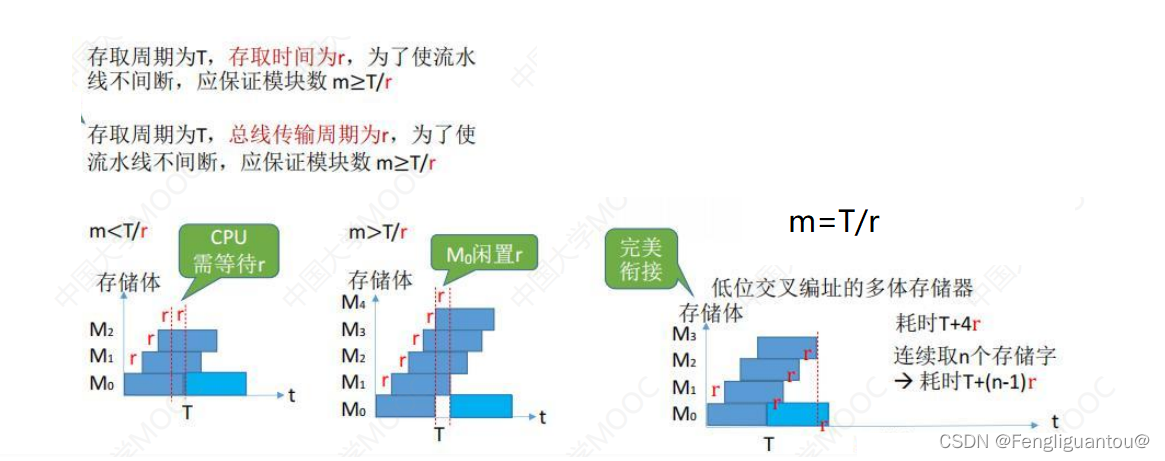
现在我们来讲讲流水线:
所谓的流水线就是指CPU不断的访问低位交叉编址模拟器,一轮又一轮,因此内部芯片的工作就像芯片一样,当读的时间足够长以后,最后一次读取的恢复时间可以近似忽略,所以宏观上可以认为读取一个存储器芯片需要的时间就是一个读写时间r。
如何理解一个存取周期可以读写多个存储器芯片?
首先需要纠正一个概念,存取周期和访存次数没有必然联系。当流水线模型充分流动以后,读取一个存储器芯片的时间近似可以看作是r,所以基本可以忽略等待时间。其中有一个点非常注意,虽然我们说一个存取周期可以读这么多个芯片,但是不是指一次访存可以读取这么多个存储器芯片,每次读取都是一次访存,因为CPU每次都是需要送地址的。
需要注意是:流水线只有充分流动起来了,才能在T存取周期中读取T/r个存储器芯片:
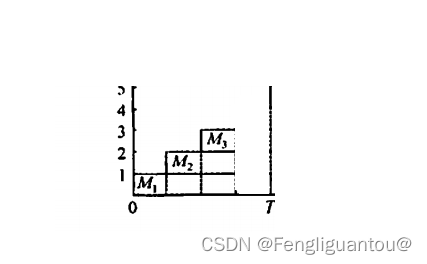
这里的充分流动的意思在宏观上,进行多轮循环读取以后,当基数达到一定量级以后,读取最后一块存储器芯片的恢复时间我们大致是可以进行忽略的。例如下图,我们只读了三块存储器芯片,这时候我们的工作时间太短,所以就不能说平均r周期读取一块存储器芯片。
注意:在选择题中如果考察低位交叉编址,这时候一般都是问使用低位交叉编址以后能够达到什么样的性能效果,即流水线充分流动以后能够达到什么样的效果,这时候就得从宏观上进行分析,例如下面这题:
这是一题选择题,这题我们应该从宏观上进行分析,即流水线充分流动,那么这时候每个读写时间r可以读写一个存储器芯片,所以一个存储周期可以读写4个,所以答案选B。

如果是在计算题中考察低位交叉编址,如果题目没有说明流水线充分流动,或者间接说明流水线充分流动,那么这时候就得出微观上进行分析,即读取最后一个存储器芯片的恢复时间不能省略。
例如上面那题做一个裁剪:假设下面为一道计算题,题目没有说明流水线充分流动,那么这时候读取4个存储器芯片就需要50+50+50+200=350ns

低位交叉编址满足程序的局部性原理:
首先我们需要知道什么是程序的局部性原理:对于高位交叉编址和低位交叉编址来说,其中空间局部性都是能够满足的,但是时间局部性高位交叉编址无法满足,因为其存储单元是在相同的存储器芯片内连续存放,其每次读完一个存储单元都需要一段恢复时间,而低位交叉编址中,连续的存储单元在不同的存储器芯片,所以可以实现较短时间的访问连续的存储单元。

单体多字存储器


存储周期和访存
我们知道,在低位交叉编址中,一个存储周期,我们可以读出若干个不同存储器芯片的存储单元。但是需要知道的是我们是进行了多次的访存,因为我们每次访存只送一次地址,所以每次只能取对应地址的存储单元的数据。但是如果是突发传送方式,我们送一个地址,就可以连续读出好几个存储单元的内容,(一般是读取的存储单元的数据刚好能够用满数据总线)。我们需要知道,如果没有说明是突发传送方式,那么每次访存只能取一个存储单元。



![[管理与领导-122]:IT人看清职场中的隐性规则 - 18- 一半佛一半魔,一半君子一半小人,阴阳互转,生生不息,儒、释、道、法,一个不能少](https://img-blog.csdnimg.cn/0fb6bfed49694226b9e558fb2b9fd04f.png)