文章目录
- Pytorch深度学习
- 1. Pytorch加载数据初认识
- 2. TensorBoard
- 3. Transforms
- 常见的transform
- 4. torchvision中的数据集使用
- 5. DataLoader使用
- 6. 神经网络
- 6.1 神经网络的基本骨架
- 6.2 卷积层
- 6.3 最大池化的使用
- 6.4 非线性激活
- 6.5 线性层及其他层
- 6.6 小实战及Sequential
- 7. 损失函数与反向传播
- 8. 优化器
- 9. 现有网络模型的使用
- 10. 网络模型的保存与读取
- 11. 完整的模型训练套路
- 12. 利用GPU训练
- 13. 完整的模型验证套路
Pytorch深度学习

dir():打开,看见包含什么
help():说明书
import torch
print(dir(torch))
# ['AVG', 'AggregationType', 'AliasDb', ...]
print(dir(torch.tensor))
# ['__call__', '__class__', '__delattr__', '__dir__', '__doc__',...]
1. Pytorch加载数据初认识
pytorch中读取数据主要涉及到两个类Dataset和Dataloader。
Dataset可以将可以使用的数据提取出来,并且可以对数据完成编号。即提供一种方式获取数据及其对应真实的label值。
Dataloader为网络提供不同的数据形式。
Dataset
Dataset是一个抽象类。所有数据集都应该继承Dataset,所有子类都应该重写__getitem__方法,该方法获取每个数据及其对应的label。我们可以选择重写Dataset的__len__方法
-
如何获取每一个数据及其label
-
告诉我们总共有多少数据
下载数据集hymenoptera_data。
Dataset测试
from torch.utils.data import Dataset
from PIL import Image
import os
# 创建MyData类,继承Dataset Dataset是一个抽象类
# 所有数据集都应该继承Dataset,所有子类都应该重写__getitem__方法,该方法获取每个数据及其对应的label
# 我们可以选择重写Dataset的__len__方法
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.image_path_list = os.listdir(self.path)
# 获取单个图片信息
def __getitem__(self, index):
img_name = self.image_path_list[index]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
# 读取图片
img = Image.open(img_item_path)
label = self.label_dir
return img,label
# 获取数据集长度
def __len__(self):
return len(self.image_path_list )
if __name__ == '__main__':
ants_dataset_train = MyData("data/hymenoptera_data/train","ants")
ants_dataset_train_len = ants_dataset_train.__len__()
print(ants_dataset_train_len)
# 124
bees_dataset_train = MyData("data/hymenoptera_data/train", "bees")
bees_dataset_train_len = bees_dataset_train.__len__()
print(bees_dataset_train_len)
# 121
train_dataset = ants_dataset_train + bees_dataset_train
print(train_dataset.__len__())
# 245
img, label = train_dataset.__getitem__(12)
img.show() # 展示图片
print(label)
# ants
2. TensorBoard
TensorBoard是一个可视化的模块,该模块功能强大,可用于深度学习网络模型训练查看模型结构和训练效果(预测结果、网络模型结构图、准确率、loss曲线、学习率、权重分布等),可以帮我们更好的了解网络模型,设计TensorBoard调用相关代码,以上结果即可保存,是整合资料、梳理模型的好帮手。
安装TensorBoard
pip install tensorboard
首先要导入SummaryWriterl类,直接向log_dir文件夹写入事件文件,可以被Tensorboard进行解析。
add_scalar()方法
'''
参数:
- tag:相当于title标题
- scalar_value:需要保存的数值,对应y轴
- global_step:步数,对应x轴
'''
writer.add_scalar()
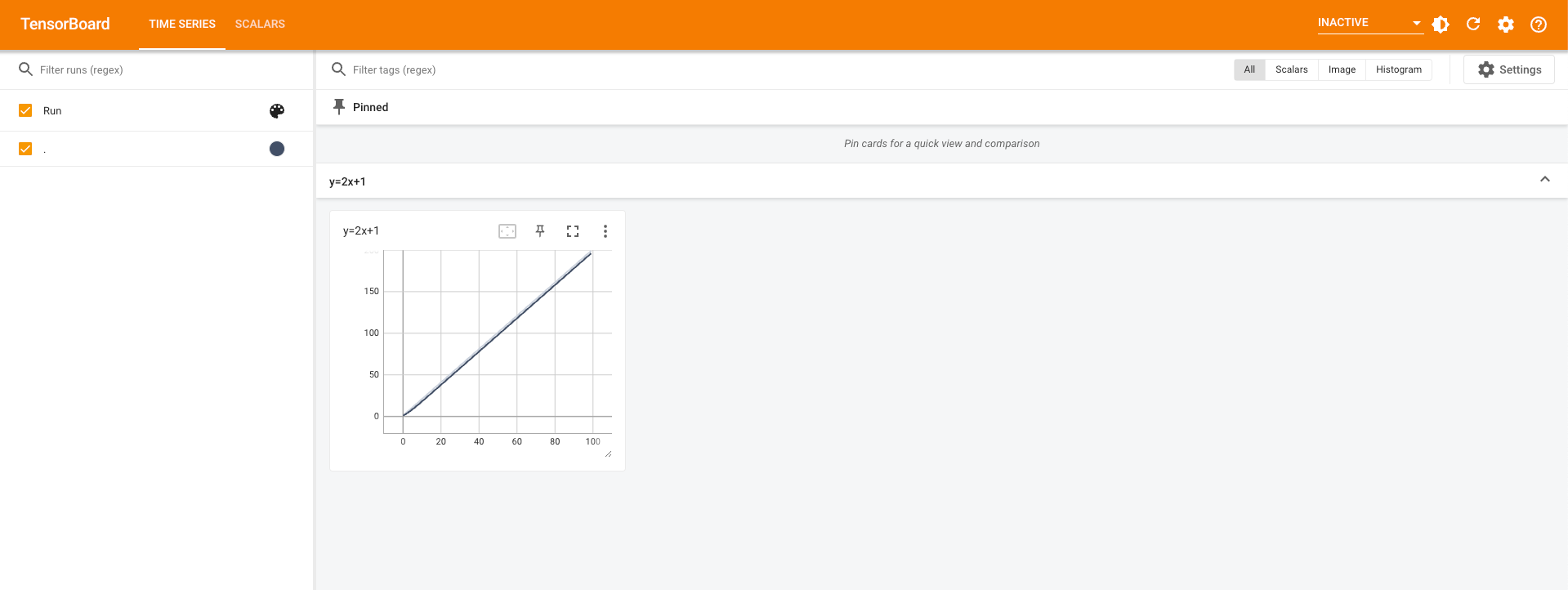
测试add_scalar()
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 指定一个文件夹,存储事件文件
# 添加标量到summary
'''
参数:
- tag:相当于title标题
- scalar_value:需要保存的数值,对应y轴
- global_step:步数,对应x轴
'''
for i in range(100):
writer.add_scalar(tag="y=2x+1",scalar_value=2*i+1,global_step=i)
writer.close()
打开生成的文件。在pycharm控制台窗口中,切换到项目目录下,使用命令
tensorboard --logdir=事件文件夹名称
如:
tensorboard --logdir=logs
使用命令,指定端口
tensorboard --logdir=logs --port=端口号

点击链接,打开网页查看结果。
add_image()方法
'''
参数:
- tag:标题title
- image_tensor:图像类型 torch.Tensor、numpy.array、string/blobname
- global_step:步数
'''
writer.add_image()
测试add_image()
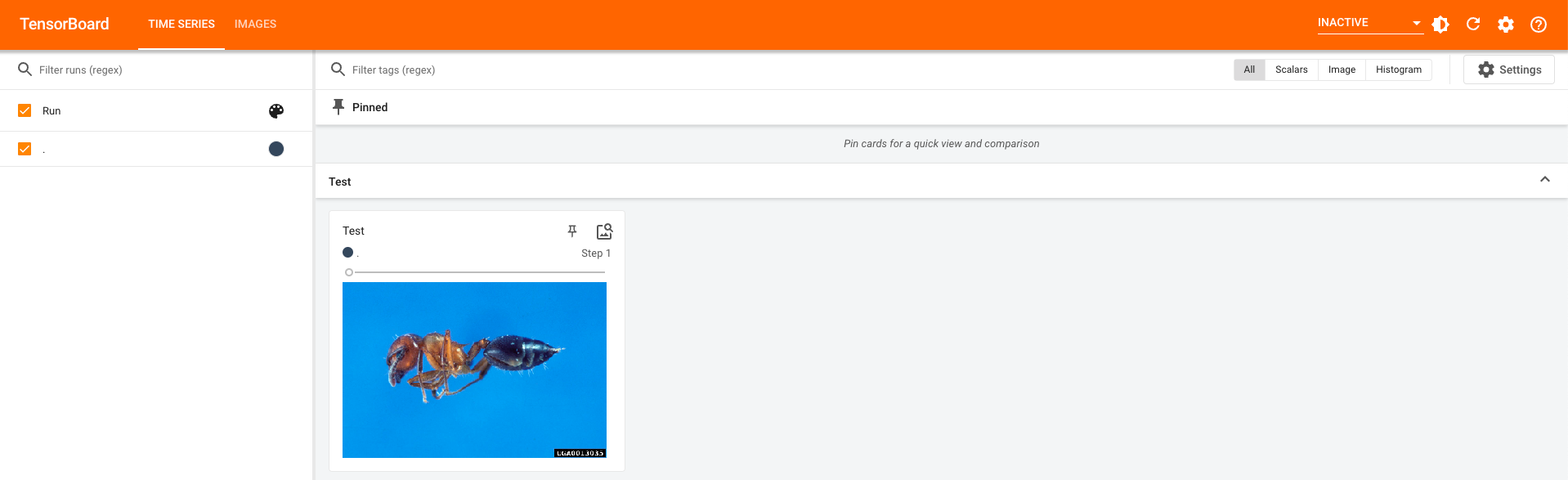
因为图片接收的数据为tensor或者numpy型,所以这里我们使用numpy型。
利用numpy.array(),对PIL图片进行转换
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
img_path = "data/练手数据集/train/ants_image/0013035.jpg"
# Image读入图片
image_PIL = Image.open(img_path)
img_array = np.array(image_PIL)
# 添加图片
'''
参数:
- tag:标题title
- image_tensor:图像类型 torch.Tensor、numpy.array、string/blobname
- global_step:步数
- dataformats:指定img_tensor值的格式
'''
writer.add_image(tag="Test",img_tensor=img_array,global_step=1,dataformats="HWC")
writer.close()
3. Transforms
Transforms是pytorch的图像处理工具包,是torchvision模块下的一个一个类的集合,可以对图像或数据进行格式变换,裁剪,缩放,旋转等,在进行深度学习项目时用途很广泛。
ToTensor
from torchvision import transforms
from PIL import Image
image_path = "data/hymenoptera_data/train/ants/0013035.jpg"
image_PIL = Image.open(image_path)
# 示例话tensor对象
to_tensor = transforms.ToTensor()
# 调用__call__方法 实现PIL图片对象转为tensor图片对象
image_tensor = to_tensor(image_PIL)
print(image_tensor)
'''
tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],
[0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],
[0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],
...,
[0.3412, 0.3412, 0.3373, ..., 0.1725, 0.3725, 0.3529],
[0.3412, 0.3412, 0.3373, ..., 0.3294, 0.3529, 0.3294],
[0.3412, 0.3412, 0.3373, ..., 0.3098, 0.3059, 0.3294]],
...]]])
'''
常见的transform
关注三个点:输入、输出、作用。
Compose
把几个transforms结合在一起,按顺序执行。Compose()中的参数需要是一个列表。如:
Compose([transforms参数1,transforms参数2,...])
ToPILImage
将tensor或numpy数据类型转为PIL Image类型。
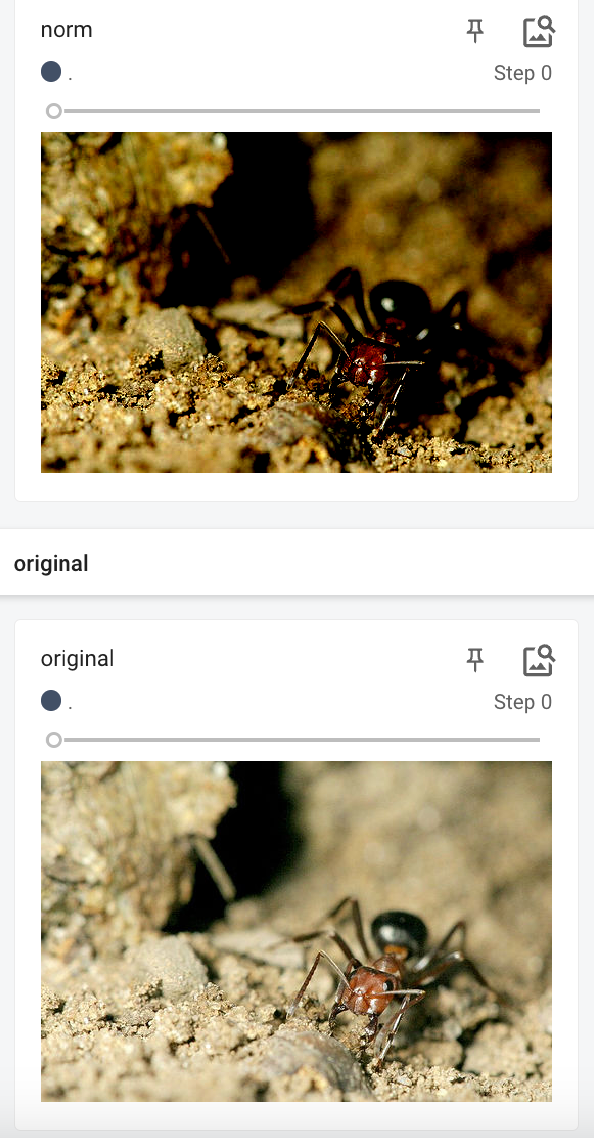
Normalize
归一化。用平均值和标准差对tensor image进行归一化。
归一化计算方式:
output[channel] = (input[channel] - mean[channel]) / std[channel]
测试:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# PIL读取图片
img_PIL = Image.open("data/hymenoptera_data/train/ants/9715481_b3cb4114ff.jpg")
# 将PIL图片转为tensor
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_PIL)
# 进行归一化
n = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = n(img_tensor)
writer = SummaryWriter("logs")
writer.add_image(img_tensor=img_tensor,tag="original",global_step=0)
writer.add_image(img_tensor=img_norm,tag="norm",global_step=0)
writer.close()
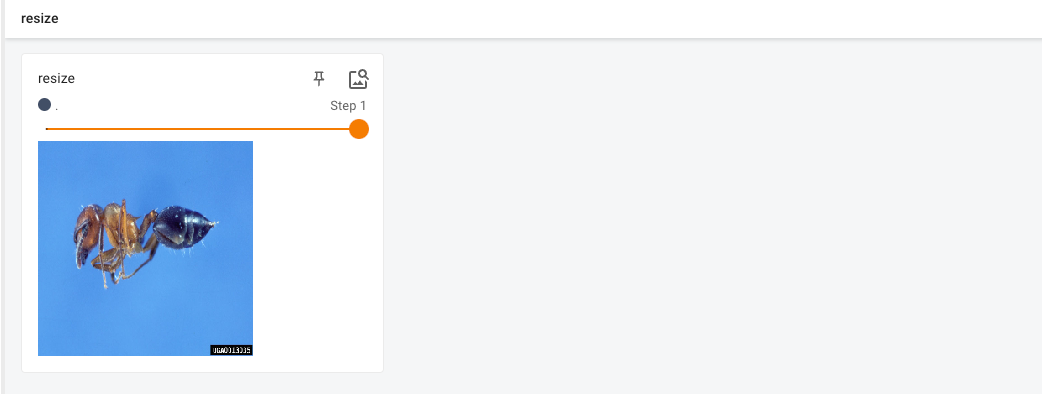
Resize
将PIL Image重置大小为给定的尺寸。如果size只给了一个数,则我们原图最小的边才会匹配该数值,进行等比的缩放。
测试:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
totensor = transforms.ToTensor()
writer = SummaryWriter("logs")
image_PIL = Image.open("data/hymenoptera_data/train/ants/0013035.jpg")
image_tensor_0 = totensor(image_PIL)
writer.add_image(tag="resize",global_step=0,img_tensor=image_tensor_0)
# 定义重置大小
resize = transforms.Resize((512,512))
image_resize = resize(image_PIL)
image_tensor_1 = totensor(image_resize)
writer.add_image(tag="resize",global_step=1,img_tensor=image_tensor_1)
writer.close()
RandomCrop
随机裁剪。
RandomCrop()
'''
参数:
- size:给定高和宽或只给定一个数值(裁剪为正方形)。
'''
测试:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
image_PIL = Image.open("data/hymenoptera_data/train/ants/20935278_9190345f6b.jpg")
to_tensor = transforms.ToTensor()
# 定义裁剪
trans_random = transforms.RandomCrop(256)
trans_compose = transforms.Compose([to_tensor,trans_random])
writer = SummaryWriter("logs")
for i in range(10):
random_img = trans_compose(image_PIL)
writer.add_image(tag="random",img_tensor=random_img,global_step=i)
writer.close()
4. torchvision中的数据集使用
数据集:
CelebA、CIFAR、Cityscapes、COCO、DatasetFolder、EMNIST、FakeData、Fashion-MNIST、Flickr、HMDB51、ImageFolder、ImageNet、Kinetics-400、KMNIST、LSUN、MNIST、Omniglot、PhotoTour、Places365、QMNIST、SBD、SBU、STL10、SVHN、UCF101、USPS、VOC
需要设定参数:
-
root:数据集的存放位置
-
train:数据集是否为训练集
-
transform: 要对数据集进行什么变化
-
target_transform:对target进行变换
-
download:是否自动下载数据集
测试:
import torchvision.datasets
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set.classes)
image,target = test_set[0]
print(image)
print(test_set.classes[target])
'''
Files already downloaded and verified
Files already downloaded and verified
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
<PIL.Image.Image image mode=RGB size=32x32 at 0x1760360A0>
cat
'''
CIFAR-10
包含了60000张32*32对彩色图片,共有10个类别,每个类别有6000张图片。50000张图片为训练集,10000张图片为测试集。
transforms和datasets结合,测试:
import torchvision
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
to_tensor = transforms.ToTensor()
train_set = torchvision.datasets.CIFAR10(root="./dataset",transform=to_tensor,train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",transform=to_tensor,train=False,download=True)
writer = SummaryWriter("logs")
for i in range(10):
image_tensor,target = train_set[i]
writer.add_image(tag="CIFAR10",global_step=i,img_tensor=image_tensor)
writer.close()
5. DataLoader使用
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
'''
datase:自定义的数据集
batch_size:每组数据的数量
shuffle:是否打乱数据
num_workers:加载数据,采用进行的数量。0:采用一个主进程加载数据
drop_list:分组余下的数据是否舍去。如80个数据,分组大小为30,余下20数据无法成为一组,是否舍去
'''
DataLoader会将每个batch中的img和target分别打包
测试:
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=transforms.ToTensor())
# 定义dataloader
test_loader = DataLoader(test_data,shuffle=True,batch_size=4,num_workers=0,drop_last=False)
# 测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)
'''
torch.Size([3, 32, 32])
3
torch.Size([4, 3, 32, 32])
tensor([7, 0, 8, 7])
torch.Size([4, 3, 32, 32])
tensor([2, 6, 9, 3])
'''
使用tensorboard进行展示
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=transforms.ToTensor())
# 定义dataloader
test_loader = DataLoader(test_data,shuffle=True,batch_size=4,num_workers=0,drop_last=False)
writer = SummaryWriter("logs")
i = 0
for data in test_loader:
imgs,targets = data
writer.add_images(tag="DataLoader",img_tensor=imgs,global_step=i)
i = i + 1
writer.close()

6. 神经网络
6.1 神经网络的基本骨架
Torch.NN,(Neural network)。
| 模块 | 介绍 |
|---|---|
Module | Base class for all neural network modules.所有神经网络的基类。 |
Sequential | A sequential container. |
ModuleList | Holds submodules in a list. |
ModuleDict | Holds submodules in a dictionary. |
ParameterList | Holds parameters in a list. |
ParameterDict | Holds parameters in a dictionary. |
前向传播:
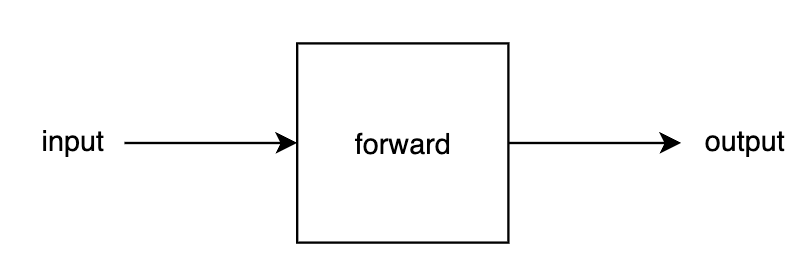
定义网络,继承Module类,重写forward方法。官方示例:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
测试:
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self,input):
output = input + 1
return output
my_model = MyModel()
x = torch.tensor(1.0)
output = my_model(x)
print(output) # tensor(2.)
6.2 卷积层
卷积层涉及参数:
- 滑动窗口步长
- 卷积核尺寸
- 边缘填充
- 卷积核个数
特征图尺寸计算:
长度:
H
2
=
H
1
−
F
H
+
2
P
S
+
1
宽度:
W
2
=
W
1
−
F
W
+
2
P
S
+
1
其中,
W
1
、
H
1
表示输入的宽度、长度;
W
2
、
H
2
表示输出特征图的宽度、长度;
F
表示卷积核长和宽的大小;
S
表示滑动窗口的步长;
P
表示边界填充(加几圈
0
)
长度:H_2 = \frac{H_1-F_H+2P}{S}+1 \\ 宽度:W_2 = \frac{W_1-F_W+2P}{S}+1\\ 其中,W_1、H_1表示输入的宽度、长度;W_2、H_2表示输出特征图的宽度、长度;\\ F表示卷积核长和宽的大小;S表示滑动窗口的步长;P表示边界填充(加几圈0)
长度:H2=SH1−FH+2P+1宽度:W2=SW1−FW+2P+1其中,W1、H1表示输入的宽度、长度;W2、H2表示输出特征图的宽度、长度;F表示卷积核长和宽的大小;S表示滑动窗口的步长;P表示边界填充(加几圈0)
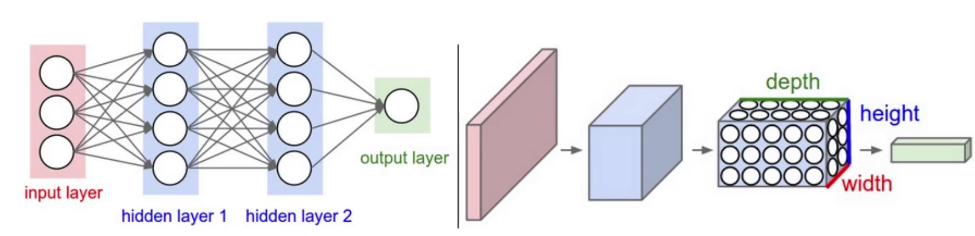
| 名称 | 介绍 |
|---|---|
nn.Conv1d | Applies a 1D convolution over an input signal composed of several input planes. |
nn.Conv2d | Applies a 2D convolution over an input signal composed of several input planes. |
nn.Conv3d | Applies a 3D convolution over an input signal composed of several input planes. |
nn.ConvTranspose1d | Applies a 1D transposed convolution operator over an input image composed of several input planes. |
nn.ConvTranspose2d | Applies a 2D transposed convolution operator over an input image composed of several input planes. |
nn.ConvTranspose3d | Applies a 3D transposed convolution operator over an input image composed of several input planes. |
nn.LazyConv1d | A torch.nn.Conv1dmodule with lazy initialization of the in_channels argument of the Conv1d that is inferred from the input.size(1). |
nn.LazyConv2d | A torch.nn.Conv2dmodule with lazy initialization of the in_channels argument of the Conv2d that is inferred from the input.size(1). |
nn.LazyConv3d | A torch.nn.Conv3dmodule with lazy initialization of the in_channels argument of the Conv3d that is inferred from the input.size(1). |
nn.LazyConvTranspose1d | A torch.nn.ConvTranspose1d module with lazy initialization of the in_channels argument of the ConvTranspose1d that is inferred from the input.size(1). |
nn.LazyConvTranspose2d | A torch.nn.ConvTranspose2dmodule with lazy initialization of the in_channels argument of the ConvTranspose2d that is inferred from the input.size(1). |
nn.LazyConvTranspose3d | A torch.nn.ConvTranspose3d module with lazy initialization of the in_channels argument of the ConvTranspose3d that is inferred from the input.size(1). |
nn.Unfold | Extracts sliding local blocks from a batched input tensor. |
nn.Fold | Combines an array of sliding local blocks into a large containing tensor. |
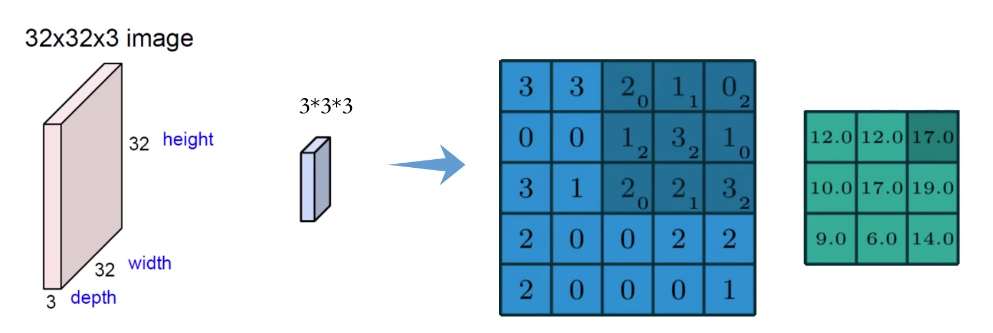
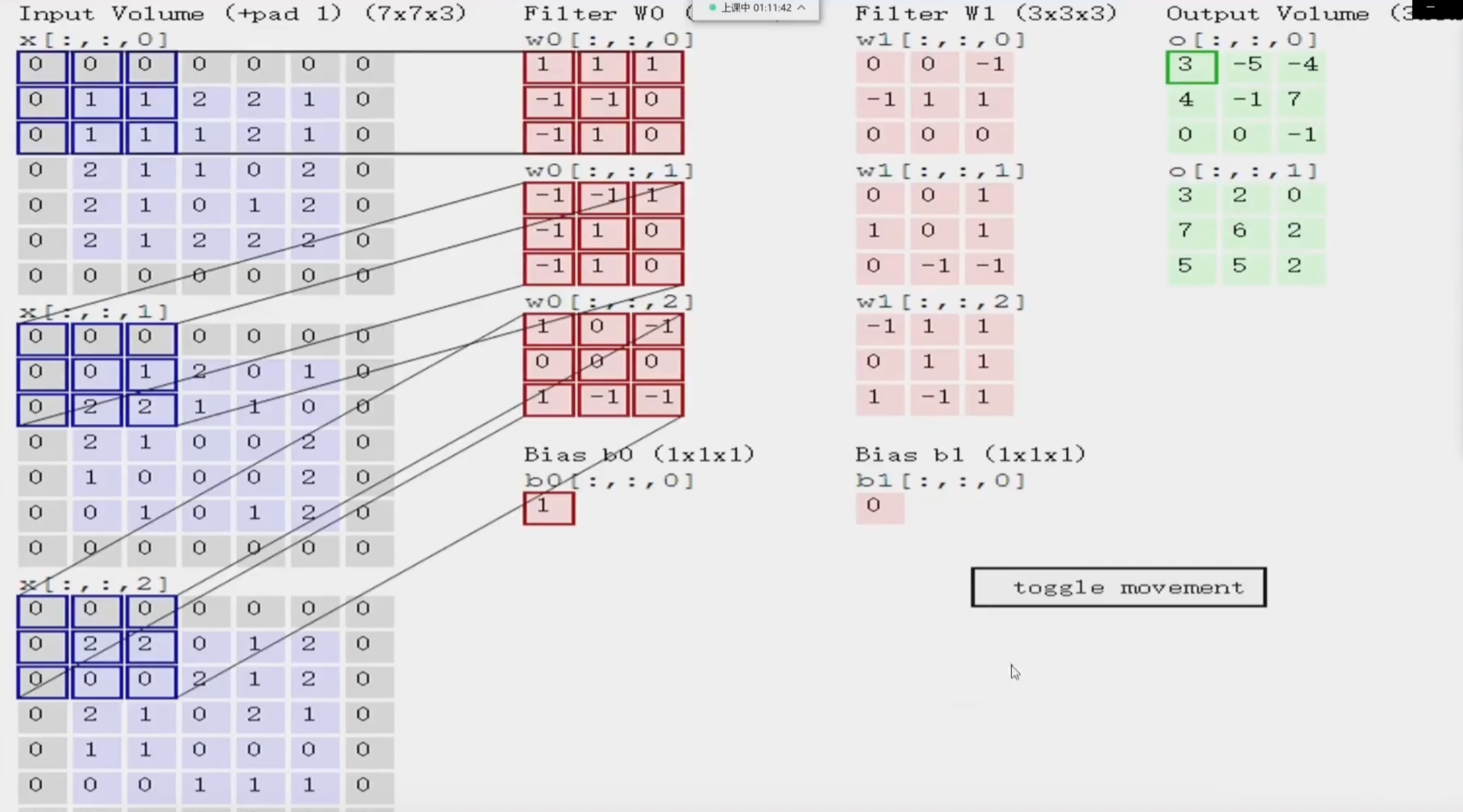
CONV2D
需要自定义卷积核时使用:
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
参数:

测试:
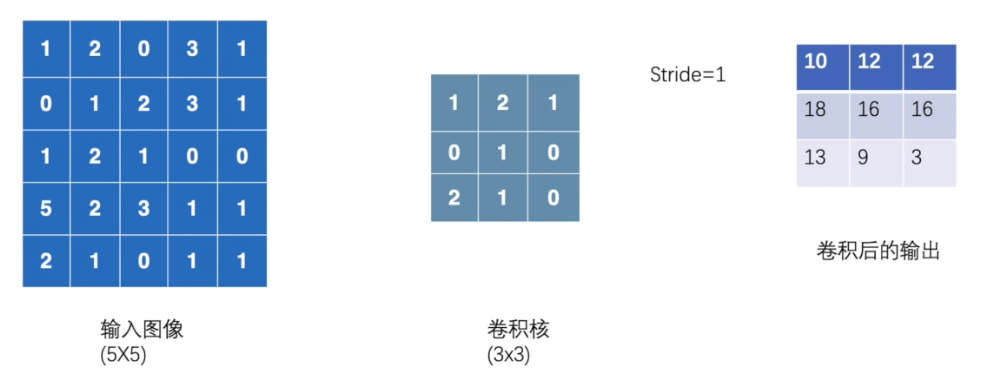
"""
@Author :shw
@Date :2023/10/17 13:35
"""
import torch.nn.functional as F
import torch
# 定义输入
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
# 定义卷积核
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
# CONV2D要求输入为(minibatch,in_channels,iH,iW)格式,所以要对格式进行变换
input = torch.reshape(input,(1,1,5,5))
# CONV2D要求卷积核为(out_channels,in_channels/groups,kH,kW)格式
kernel = torch.reshape(kernel,(1,1,3,3))
output = F.conv2d(input,kernel,stride=1)
print(output)
'''
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
'''
不需要自定义卷积核
语法:
torch.nn.Conv2d(in_channels: int, out_channels: int, kernel_size: Union[T, Tuple[T, T]], stride: Union[T, Tuple[T, T]] = 1, padding: Union[T, Tuple[T, T]] = 0, dilation: Union[T, Tuple[T, T]] = 1, groups: int = 1, bias: bool = True, padding_mode: str = 'zeros')
参数:
- in_channels (int) – Number of channels in the input image
- out_channels (int) – Number of channels produced by the convolution
- kernel_size (int or tuple) – Size of the convolving kernel
- stride (int or tuple, optional) – Stride of the convolution. Default: 1
- padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
- padding_mode (string*,* optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros' - dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
- groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
- bias (bool, optional) – If
True, adds a learnable bias to the output. Default:True
测试:
from torchvision import datasets
from torch.nn import Conv2d
import torch
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
to_tensor = transforms.ToTensor()
# 读入数据
input = datasets.CIFAR10(root="./dataset",train=False,transform=to_tensor,download=True)
# 定义dataloader
dataloader = DataLoader(input,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
class MyModel(torch.nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,input):
x = self.conv1(input)
return x
writer = SummaryWriter("logs")
mymodel = MyModel()
step = 0
for data in dataloader:
images,targets = data
output = mymodel(images)
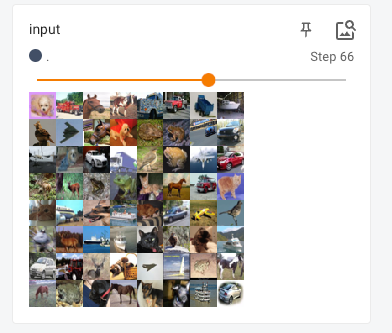
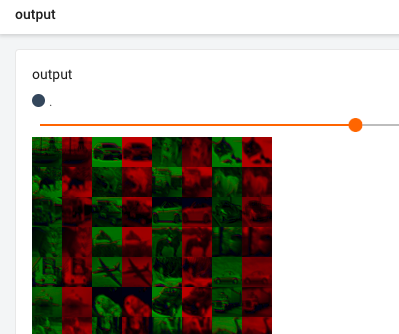
writer.add_images("input",images,global_step=step)
# 因为显示图片最多3个通道,这里我们输出的结果为6个通道,所以要进行变换
# 第一个值我们不知道为多少,所以填写-1,会自动根据设定的数值进行计算
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,global_step=step)
step = step + 1
writer.close()
6.3 最大池化的使用
最大池化(MaxPool),也称为下采样。MaxUnpool,称为下采样。
语法:
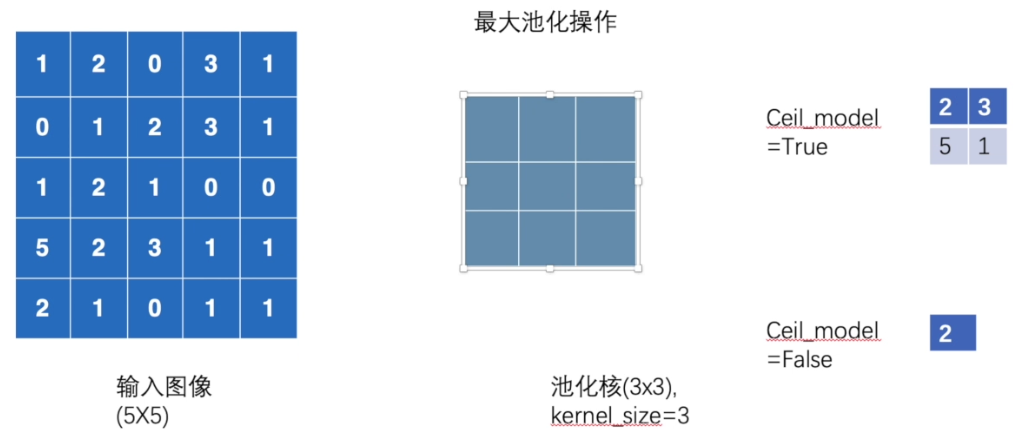
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数:
- kernel_size – the size of the window to take a max over
- stride – the stride of the window. Default value is
kernel_size - padding – implicit zero padding to be added on both sides
- dilation – a parameter that controls the stride of elements in the window
- return_indices – if
True, will return the max indices along with the outputs. Useful fortorch.nn.MaxUnpool2dlater - ceil_mode – when True, will use ceil(向上取整) instead of floor(向下取整) to compute the output shape,且保留模式。

测试:
import torch
from torch.nn import Conv2d,MaxPool2d,Module
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
to_tensor = transforms.ToTensor()
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
input = torch.reshape(input,(-1,1,5,5))
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
x = self.maxpool1(input)
return x
mymodel = MyModel()
res = mymodel(input)
print(res)
'''
tensor([[[[2, 3],
[5, 1]]]])
'''
通过引入数据集进行测试:
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch.nn import MaxPool2d,Module
to_tensor = transforms.ToTensor()
dataset = datasets.CIFAR10(root="./dataset",train=False,transform=to_tensor,download=True)
dataloader = DataLoader(dataset,batch_size=64,shuffle=True)
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
x = self.maxpool1(input)
return x
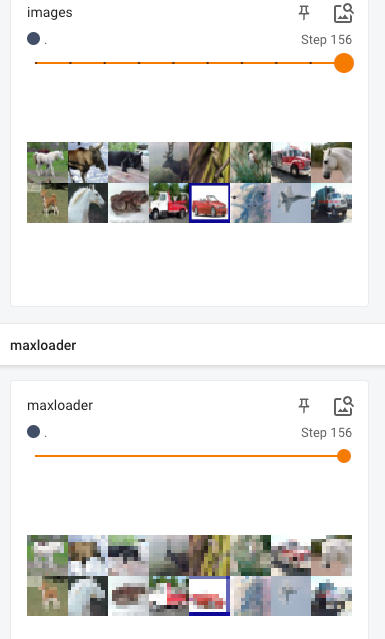
writer = SummaryWriter("logs")
step = 0
mymodel = MyModel()
for data in dataloader:
images,targets = data
writer.add_images(tag="images",img_tensor=images,global_step=step)
outputs = mymodel(images)
writer.add_images(tag="maxloader",img_tensor=outputs,global_step=step)
step = step + 1
writer.close()
6.4 非线性激活
常用的非线性激活:
- ReLU(线性整流单元)
- PReLU(参数线性整流单元)
- LeakyReLU(泄漏线性整流单元)
- ELU(指数线性单元)
- Sigmod
- Tanh
- Softmax
- …
ReLU
测试:
from torch.nn import ReLU,Module
import torch
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.relu1 = ReLU()
def forward(self,input):
output = self.relu1(input)
return output
mymodel = MyModel()
output = mymodel(input)
print(output)
'''
tensor([[[[1., 0.],
[0., 3.]]]])
'''
引入数据集,进行测试
"""
@Author :shw
@Date :2023/10/17 16:35
"""
from torch.nn import Sigmoid,Module
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 导入数据集
to_tensor = transforms.ToTensor()
dataset = datasets.CIFAR10(root="./dataset",train=False,transform=to_tensor,download=True)
dataloader = DataLoader(dataset,batch_size=64,shuffle=True,num_workers=0)
# 定义模型
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.sigmoid1 = Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
writer = SummaryWriter("logs")
step = 0
mymodel = MyModel()
for data in dataloader:
imgs,targets = data
outputs = mymodel(imgs)
writer.add_images(tag="img",img_tensor=imgs,global_step=step)
writer.add_images(tag="sigmoid",img_tensor=outputs,global_step=step)
step = step + 1
writer.close()
6.5 线性层及其他层
1. Normalization层(归一化层)
语法:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
参数:
- num_features – C* from an expected input of size(N,C,H,W)
- eps – a value added to the denominator for numerical stability. Default: 1e-5
- momentum – the value used for the running_mean and running_var computation. Can be set to
Nonefor cumulative moving average (i.e. simple average). Default: 0.1 - affine – a boolean value that when set to
True, this module has learnable affine parameters. Default:True - track_running_stats – a boolean value that when set to
True, this module tracks the running mean and variance, and when set toFalse, this module does not track such statistics, and initializes statistics buffersrunning_meanandrunning_varasNone. When these buffers areNone, this module always uses batch statistics. in both training and eval modes. Default:True
例子:
# With Learnable Parameters
m = nn.BatchNorm2d(100)
# Without Learnable Parameters
m = nn.BatchNorm2d(100, affine=False)
input = torch.randn(20, 100, 35, 45)
output = m(input)
2. Recurrent层(循环层)
nn.RNNBase | |
|---|---|
nn.RNN | Applies a multi-layer Elman RNN with tanhtanh or ReLUReLU non-linearity to an input sequence. |
nn.LSTM | Applies a multi-layer long short-term memory (LSTM) RNN to an input sequence. |
nn.GRU | Applies a multi-layer gated recurrent unit (GRU) RNN to an input sequence. |
nn.RNNCell | An Elman RNN cell with tanh or ReLU non-linearity. |
nn.LSTMCell | A long short-term memory (LSTM) cell. |
nn.GRUCell | A gated recurrent unit (GRU) cell |
3. Transformer层
nn.Transformer | A transformer model. |
|---|---|
nn.TransformerEncoder | TransformerEncoder is a stack of N encoder layers |
nn.TransformerDecoder | TransformerDecoder is a stack of N decoder layers |
nn.TransformerEncoderLayer | TransformerEncoderLayer is made up of self-attn and feedforward network. |
nn.TransformerDecoderLayer | TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network. |
4. Dropout层
为了防止过拟合
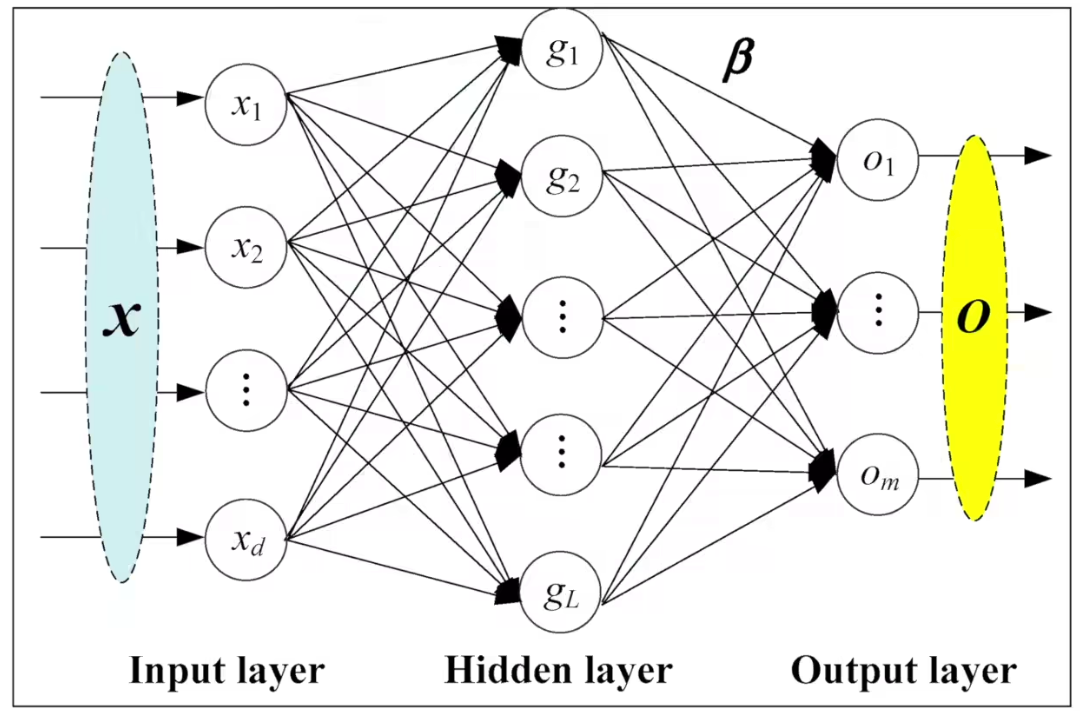
5. Liner层(线性层)
即全连接层。
nn.Identity | A placeholder identity operator that is argument-insensitive. |
|---|---|
nn.Linear | Applies a linear transformation to the incoming data: y = x T A + b y=x^TA+b y=xTA+b |
nn.Bilinear | Applies a bilinear transformation to the incoming data: y = x 1 T A x 2 + b y=x_1^TAx_2+b y=x1TAx2+b |
nn.LazyLinear | A torch.nn.Linearmodule with lazy initialization. |
测试:
import torch
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch.nn import Module,Linear
to_tensor = transforms.ToTensor()
dataset = datasets.CIFAR10(root="./dataset",train=True,transform=to_tensor,download=True)
dataloader = DataLoader(dataset,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.linear1 = Linear(in_features=196608,out_features=10)
def forward(self,input):
output = self.linear1(input)
return output
mymodel = MyModel()
for data in dataloader:
imgs,targets = data
imgs_flatten = torch.flatten(imgs) # 将数据展平
output = mymodel(imgs_flatten)
print(output)
'''
tensor([-0.3241, 0.1549, -0.3120, 0.1616, -0.0332, 0.0360, 0.0210, 0.0720,
-0.1955, 0.0475], grad_fn=<ViewBackward0>)
tensor([-0.0349, -0.1776, -0.5392, 0.2040, 0.1981, -0.0211, -0.0833, 0.3111,
-0.2447, -0.2244], grad_fn=<ViewBackward0>)
......
'''
torch.flatten
将多维数据展平(一维)
语法:
torch.flatten(input, start_dim=0, end_dim=-1) → Tensor
参数:
- input (Tensor) – the input tensor.
- start_dim (int) – the first dim to flatten
- end_dim (int) – the last dim to flatten
6.6 小实战及Sequential
Sequential
语法:
torch.nn.Sequential(*args)
例子:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
对CIFAR10进行分类的神经网络
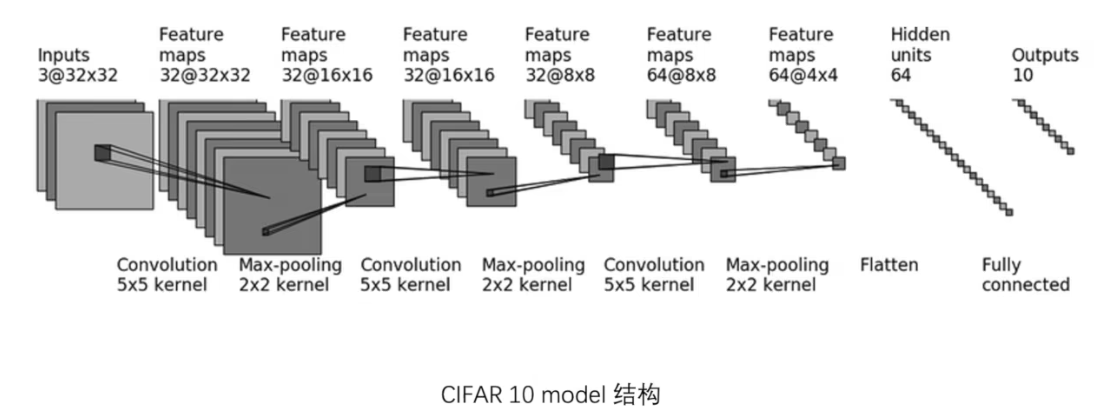
import torch
from torch.nn import Module,Conv2d,Linear,MaxPool2d,Sequential,Flatten
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.conv1 = Conv2d(3,32,5,padding=2,stride=1)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32,5,padding=2,stride=1)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,5,padding=2,stride=1)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
mymodel = MyModel()
input = torch.ones((63,3,32,32))
output = mymodel(input)
print(output.shape)
# torch.Size([63, 10])
使用Sequential进行改进
import torch
from torch.nn import Module,Conv2d,Linear,MaxPool2d,Sequential,Flatten
from torch.utils.tensorboard import SummaryWriter
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model1 = Sequential(
Conv2d(3,32,5,padding=2,stride=1),
MaxPool2d(2),
Conv2d(32,32,5,padding=2,stride=1),
MaxPool2d(2),
Conv2d(32,64,5,padding=2,stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
mymodel = MyModel()
input = torch.ones((63,3,32,32))
output = mymodel(input)
print(output.shape)
# torch.Size([63, 10])
writer = SummaryWriter("logs") # 使用SummaryWriter展示模型
writer.add_graph(mymodel,input)
writer.close()

7. 损失函数与反向传播
损失函数:
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据(反向传播),为每个卷积核中的参数设置了一个
grad,即梯度。
nn.L1Loss
nn.MSELoss
nn.CrossEntropyLoss
nn.CTCLoss
nn.NLLLoss
nn.PoissonNLLLoss
nn.GaussianNLLLoss
nn.KLDivLoss
nn.BCELoss
nn.BCEWithLogitsLoss
nn.MarginRankingLoss
nn.HingeEmbeddingLoss
nn.MultiLabelMarginLoss
nn.HuberLoss
nn.SmoothL1Loss
nn.SoftMarginLoss
nn.MultiLabelSoftMarginLoss
nn.CosineEmbeddingLoss
nn.MultiMarginLoss
nn.TripletMarginLoss
nn.TripletMarginWithDistanceLoss
L1Loss测试
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss()
result = loss(inputs,targets)
print(result) # tensor(0.6667)
均方误差MSELOSS

测试:
import torch
from torch.nn import MSELoss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = MSELoss()
result_mse = loss_mse(inputs,targets)
print(result_mse)
# tensor(1.3333)
交叉熵损失函数 CROSSENTROPYLOSS
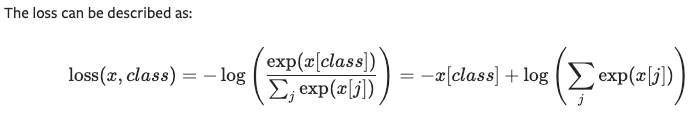
测试:
import torch
from torch.nn import CrossEntropyLoss
cross_entropy_loss = CrossEntropyLoss()
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
result_cross_entropy_loss = cross_entropy_loss(x,y)
print(result_cross_entropy_loss)
# tensor(1.1019)
使用数据集,测试交叉熵损失函数:
from torch.nn import Linear, Flatten, Conv2d, MaxPool2d, Sequential, Module
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch import nn
to_tensor = transforms.ToTensor()
dataset = datasets.CIFAR10(root="./dataset",transform=to_tensor,download=True,train=False)
dataloader = DataLoader(dataset,batch_size=64,shuffle=True,num_workers=0)
class MyModel(Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model1 = Sequential(
Conv2d(3,32,5,padding=2,stride=1),
MaxPool2d(2),
Conv2d(32,32,5,padding=2,stride=1),
MaxPool2d(2),
Conv2d(32,64,5,padding=2,stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
mymodel = MyModel()
for data in dataloader:
images,targets = data
outputs = mymodel(images)
loss_res = loss(outputs,targets)
print("loss:{}".format(loss_res))
'''
loss:2.310953140258789
loss:2.3043782711029053
loss:2.318134307861328
loss:2.308051347732544
......
'''
反向传播
loss_res.backward() # 对损失结果 进行反向传播,求梯度
8. 优化器
根据优化器,使用反向传播求出的参数的梯度,对参数进行调整,达到误差降低目的。
| Algorithms | 描述 |
|---|---|
Adadelta | Implements Adadelta algorithm. |
Adagrad | Implements Adagrad algorithm. |
Adam | Implements Adam algorithm. |
AdamW | Implements AdamW algorithm. |
SparseAdam | Implements lazy version of Adam algorithm suitable for sparse tensors. |
Adamax | Implements Adamax algorithm (a variant of Adam based on infinity norm). |
ASGD | Implements Averaged Stochastic Gradient Descent. |
LBFGS | Implements L-BFGS algorithm, heavily inspired by minFunc |
RMSprop | Implements RMSprop algorithm. |
Rprop | Implements the resilient backpropagation algorithm. |
SGD | Implements stochastic gradient descent (optionally with momentum). |
官方例子:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # lr 学习率
optimizer = optim.Adam([var1, var2], lr=0.0001)
for input, target in dataset:
optimizer.zero_grad() # 将上一次求出的梯度清零
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step() # 将参数进行调整优化
梯度下降SGD
语法:
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
参数:
- params (iterable) – iterable of parameters to optimize or dicts defining parameter groups
- lr (float) – learning rate
- momentum (float, optional) – momentum factor (default: 0)
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
- dampening ([float, optional) – dampening for momentum (default: 0)
- nesterov (bool optional) – enables Nesterov momentum (default: False)
测试:
from torchvision import datasets,transforms
from torch import nn,optim
from torch.utils.data import DataLoader
lr = 0.01
epochs = 10
# 导入数据
to_tensor = transforms.ToTensor()
train_data = datasets.CIFAR10(root="./dataset",train=True,transform=to_tensor,download=True)
test_data = datasets.CIFAR10(root="./dataset",train=False,transform=to_tensor,download=True)
# 处理数据,分组打包
train_dataloader = DataLoader(train_data,batch_size=64,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_data,batch_size=64,shuffle=True,num_workers=0)
# 构建网络
class Net(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self,x):
return self.model1(x)
# 实例化模型
net = Net()
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化器
optimer = optim.SGD(net.parameters(),lr=lr)
# 训练
for epoch in range(epochs):
# 每个epoch,总损失
running_loss = 0.0
for data in train_dataloader:
images, targets = data
optimer.zero_grad()
outputs = net(images)
loss_output = loss(outputs,targets)
loss_output.backward()
optimer.step()
running_loss = running_loss + loss_output
print("epoch:{},loss:{}".format(epoch, running_loss))
'''
epoch:0,loss:1705.0546875
epoch:1,loss:1461.0814208984375
epoch:2,loss:1306.674072265625
epoch:3,loss:1216.27001953125
epoch:4,loss:1149.858154296875
'''
9. 现有网络模型的使用
分类模型:
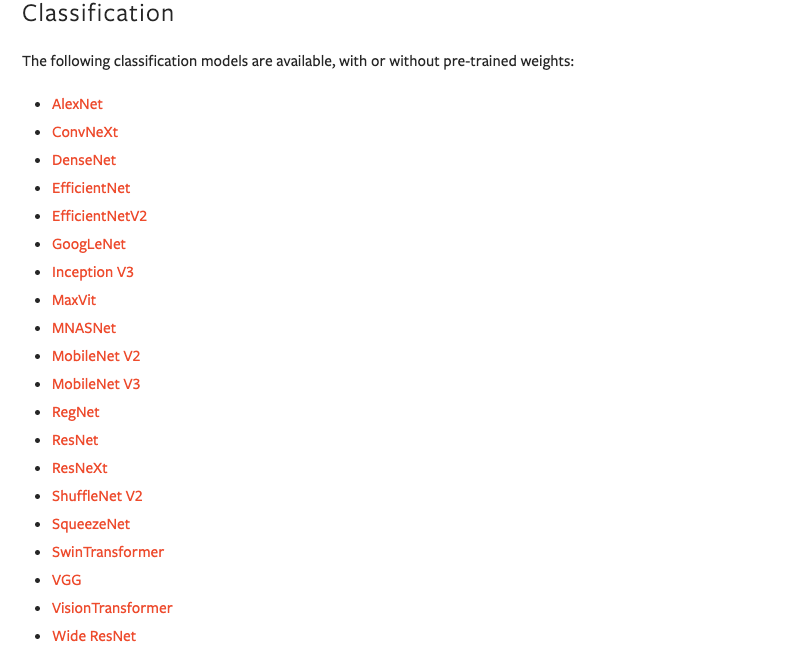
目标检测模型:

ImageNet数据集
注意:
- 下载ImageNet数据集,要求已经安装了Scipy模块。
- 数据集不能公开访问了,必须自己手动去下载数据文件,然后放在root指定的路径中
语法:
torchvision.datasets.ImageNet(root: str, split: str = 'train', **kwargs: Any)
参数:
- root (string) – Root directory of the ImageNet Dataset.
- split (string*,* optional) – The dataset split, supports
train, orval. - transform (callable*,* optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g,
transforms.RandomCrop - target_transform (callable*,* optional) – A function/transform that takes in the target and transforms it.
- loader – A function to load an image given its path.
测试:
train_data = datasets.ImageNet(root="../dataset",split="train",transform=to_tensor)
VGG模型
VGG模型分类VGG11、VGG13、VGG16、VGG19。
VGG16
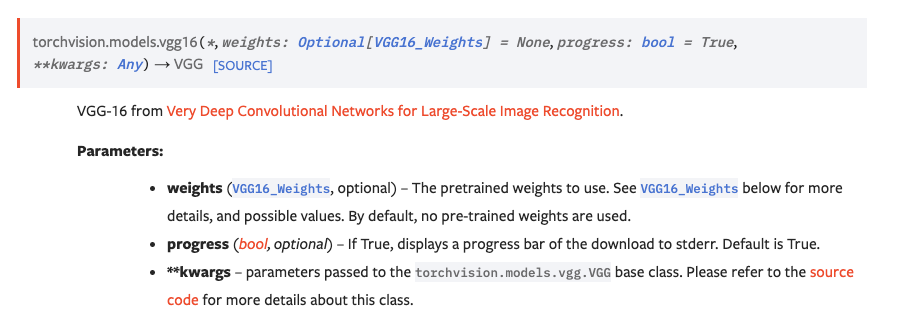
测试:
vgg16 = vgg16(weights=VGG16_Weights.DEFAULT,progress=True)
利用现有的网络,改动其结构。
例如:
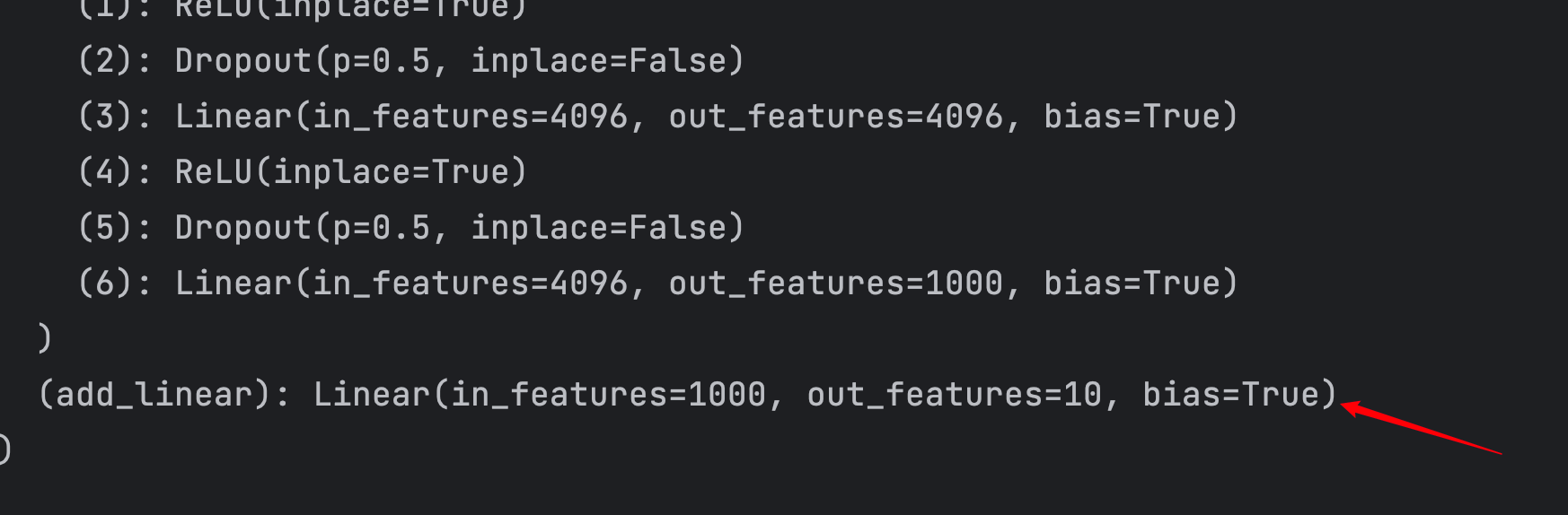
添加一个线性层,将输出out_features为1000改为10。
from torchvision.models import vgg16,VGG16_Weights
from torch import nn
vgg16 = vgg16(weights=VGG16_Weights.DEFAULT,progress=True)
# 添加一个线性层
vgg16.add_module("add_linear",nn.Linear(1000,10))
print(vgg16)
在VGG中的classifier中添加一层
from torchvision.models import vgg16,VGG16_Weights
from torch import nn
vgg16 = vgg16(weights=VGG16_Weights.DEFAULT,progress=True)
# 在classifier中添加一层
vgg16.classifier.add_module("add_linear",nn.Linear(1000,10))
print(vgg16)
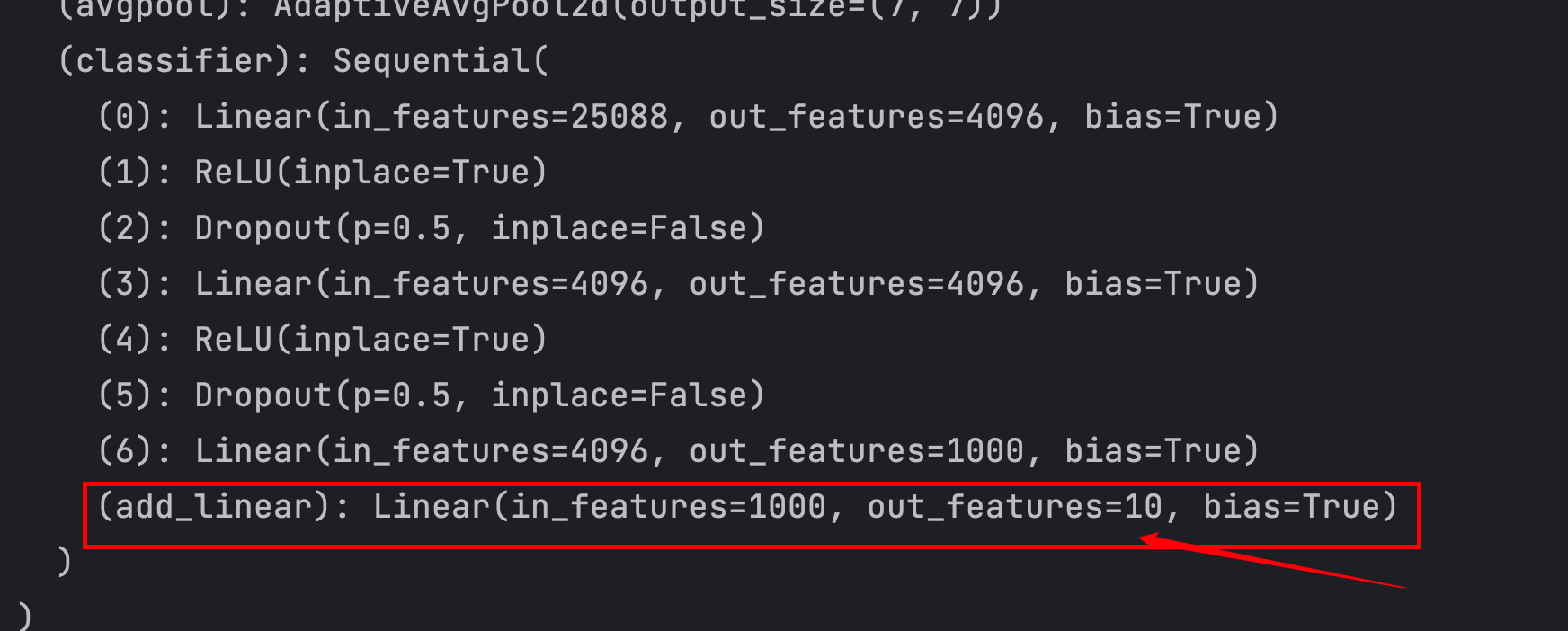
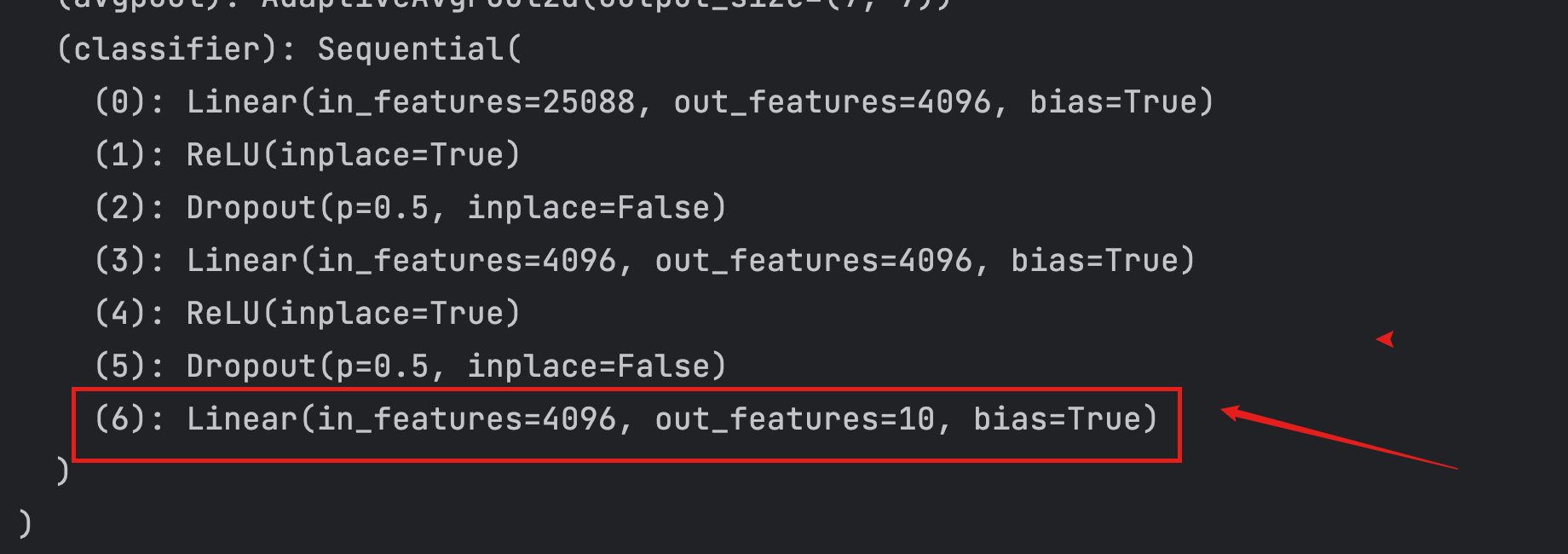
不进行添加,而在原来的基础上直接进行修改
from torchvision.models import vgg16,VGG16_Weights
from torch import nn
vgg16 = vgg16(weights=VGG16_Weights.DEFAULT,progress=True)
# 不进行添加,而在原来的基础上直接进行修改
vgg16.classifier[6] = nn.Linear(4096,10)
print(vgg16)
10. 网络模型的保存与读取
方式一:使用torch.save()保存模型,使用torch.load()读取模型
保存模型结构和模型参数
-
保存
import torch from torchvision.models import vgg16,VGG16_Weights vgg16 = vgg16(weights=VGG16_Weights.DEFAULT,progress=True) # 保存方式 - 1 torch.save(vgg16,"./model/vgg16_method1.pth") # 模型一般保存为pth格式
-
读取
import torch # 方式一 -> 保存方式1 , 加载模型 vgg16_method1 = torch.load("./model/vgg16_method1.pth") print(vgg16_method1)
方式二:
保存模型参数,官方推荐!对于大模型来说,会节省存储空间。
-
保存
import torch from torchvision.models import vgg16,VGG16_Weights vgg16 = vgg16(weights=VGG16_Weights.DEFAULT,progress=True) # 保存方式 - 2 # 将vgg16的状态保存为一种字典格式(不保存网络模型的结构,只保存网络模型的参数) torch.save(vgg16.state_dict(),"./model/vgg16_method2.pth") -
读取
因为直接读取到的知识参数,没有网络结构,所以我们要先创建网络结构,然后通过网络结构加载保存的参数
import torch from torchvision.models import vgg16 # 方式二 -> 保存方式2 , 加载模型 vgg16_method2 = torch.load("./model/vgg16_method2.pth") vgg16 = vgg16() vgg16.load_state_dict(vgg16_method2) print(vgg16)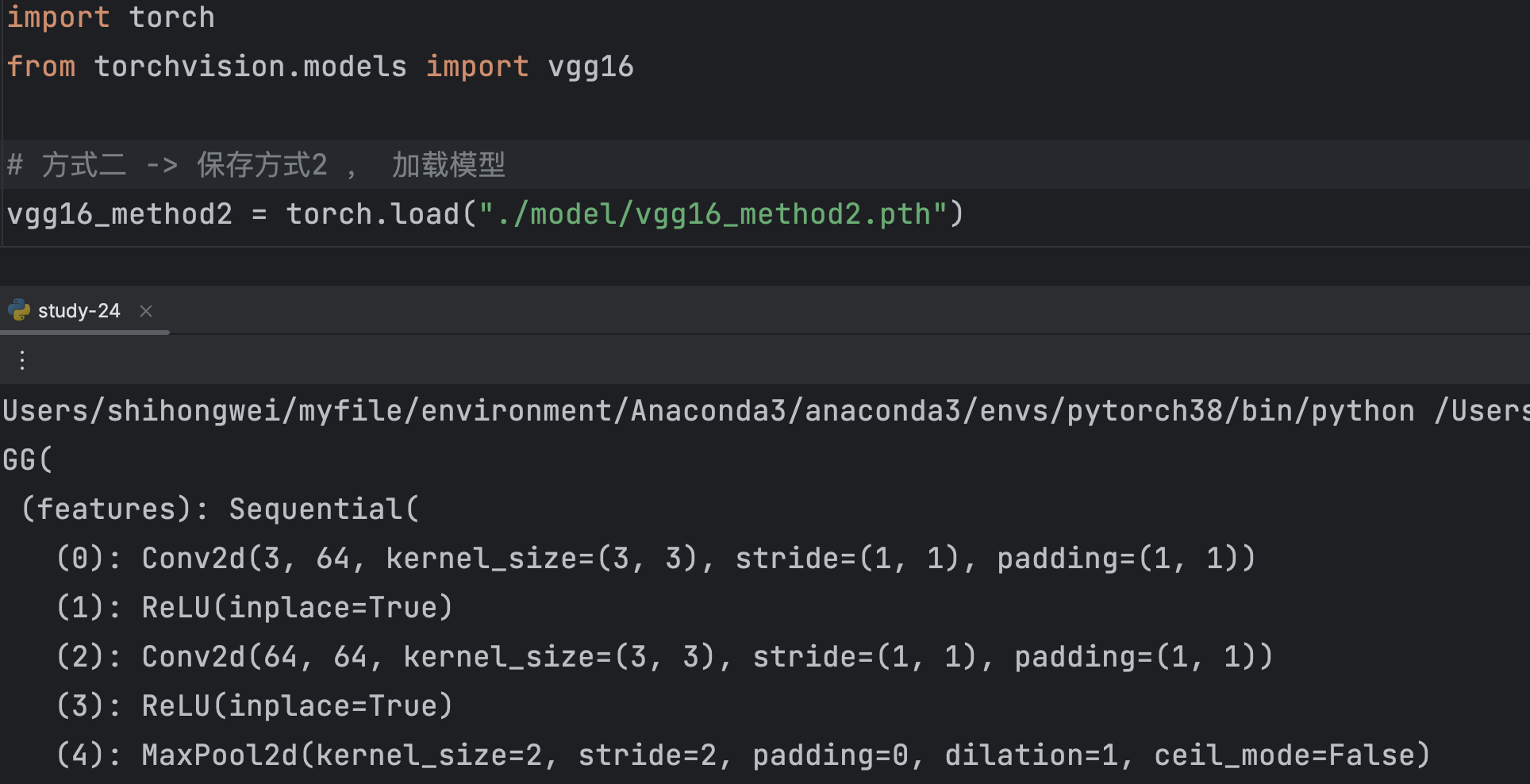
11. 完整的模型训练套路
使用CIFAR10数据集。
model.py
import torch
from torch import nn
# 搭建网络
class Net(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3,32,kernel_size=5,padding=2,stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, padding=2,stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32,64,kernel_size=5,padding=2,stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
return self.model(x)
# 验证网络正确性
if __name__ == '__main__':
net = Net()
my_input = torch.ones((64,3,32,32))
my_output = net(my_input)
print(my_output.shape)
work_main.py
import torch
from torch.utils.data import DataLoader
from torchvision import transforms,datasets
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from model import Net
# 扫描数据集次数
epochs = 10
# 学习率
# learning_rate = 0.01
learning_rate = 1e-2 # 1e-2 = 1*10^(-2) = 0.01
to_tensor = transforms.ToTensor()
# 读取数据
train_dataset = datasets.CIFAR10(root="./dataset",train=True,download=True,transform=to_tensor)
test_dataset = datasets.CIFAR10(root="./dataset",train=False,download=True,transform=to_tensor)
# 加载数据
train_dataloader = DataLoader(train_dataset,batch_size=64,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_dataset,batch_size=64,shuffle=True,num_workers=0)
# 训练数据集大小
train_data_size = len(train_dataset)
# 测试数据集大小
test_data_size = len(test_dataset)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 创建网络
net = Net()
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 添加 tensorboard
writer = SummaryWriter("logs")
# 训练
for epoch in range(epochs):
print("--------------------第 {} 轮训练开始--------------------".format(epoch+1))
for data in train_dataloader:
images, targets = data
outputs = net(images)
loss_output = loss(outputs,targets)
# 优化器优化模型
optimizer.zero_grad()
loss_output.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step%100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss_output.item()))
writer.add_scalar(tag="Train_Loss", scalar_value=loss_output.item(), global_step=total_train_step)
# 在每轮训练之后进行测试
# torch.no_grad() 不进行调优
total_test_loss = 0 # 测试总损失
with torch.no_grad():
for data in test_dataloader:
images,targets = data
outputs = net(images)
loss_output = loss(outputs,targets)
total_test_loss = total_test_loss + loss_output
total_test_step = total_test_step + 1
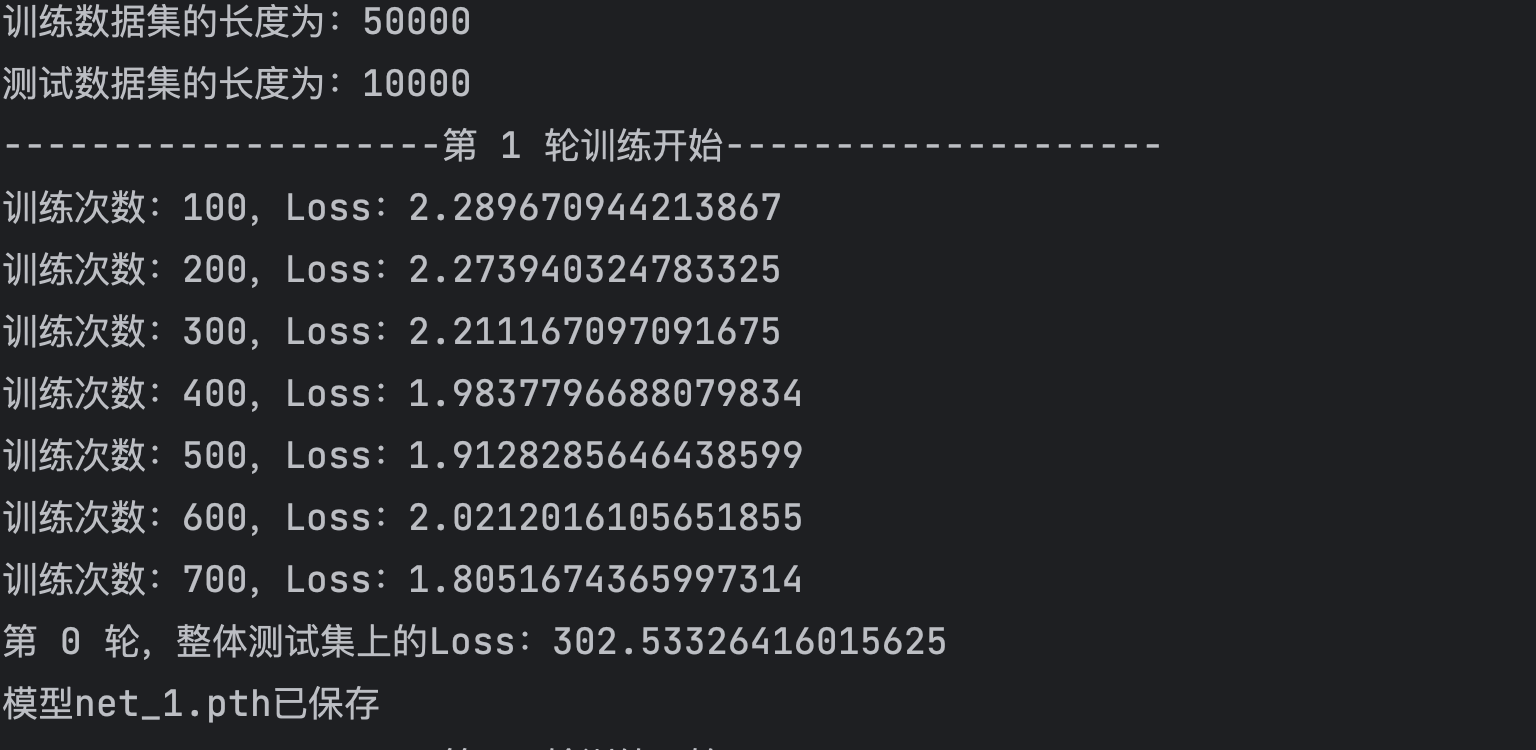
print("第 {} 轮,整体测试集上的Loss:{}".format(epoch,total_test_loss))
writer.add_scalar(tag="Test_Total_Loss",scalar_value=total_test_loss,global_step=total_test_step)
# 保存每一轮训练好的模型
torch.save(net,"./model/net_{}.pth".format(epoch+1))
print("模型net_{}.pth已保存".format(epoch+1))
writer.close()

在分类问题中,需要显示正确率衡量指标,如:
import torch
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
max_index = torch.argmax(outputs,dim=1) # 求出每行最大值的索引
input_targets = torch.tensor([0,1])
accuracy_num = (max_index==input_targets).sum()
print("准确率为:{}".format(accuracy_num/len(max_index)))
# 准确率为:0.5
将准确率加到我们上面所写的训练模型中
只需更改work_main.py
import torch
from torch.utils.data import DataLoader
from torchvision import transforms,datasets
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from model import Net
# 扫描数据集次数
epochs = 10
# 学习率
# learning_rate = 0.01
learning_rate = 1e-2 # 1e-2 = 1*10^(-2) = 0.01
to_tensor = transforms.ToTensor()
# 读取数据
train_dataset = datasets.CIFAR10(root="./dataset",train=True,download=True,transform=to_tensor)
test_dataset = datasets.CIFAR10(root="./dataset",train=False,download=True,transform=to_tensor)
# 加载数据
train_dataloader = DataLoader(train_dataset,batch_size=64,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_dataset,batch_size=64,shuffle=True,num_workers=0)
# 训练数据集大小
train_data_size = len(train_dataset)
# 测试数据集大小
test_data_size = len(test_dataset)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 创建网络
net = Net()
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 添加 tensorboard
writer = SummaryWriter("logs")
# 训练
for epoch in range(epochs):
print("--------------------第 {} 轮训练开始--------------------".format(epoch+1))
for data in train_dataloader:
images, targets = data
outputs = net(images)
loss_output = loss(outputs,targets)
# 优化器优化模型
optimizer.zero_grad()
loss_output.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step%100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss_output.item()))
writer.add_scalar(tag="Train_Loss", scalar_value=loss_output.item(), global_step=total_train_step)
# 在每轮训练之后进行测试
# torch.no_grad() 不进行调优
total_test_loss = 0 # 测试总损失
total_accuracy = 0 # 整体正确的个数
with torch.no_grad():
for data in test_dataloader:
images,targets = data
outputs = net(images)
loss_output = loss(outputs,targets)
total_test_loss = total_test_loss + loss_output
accuracy = (targets == torch.argmax(outputs,dim=1)).sum() # 计算正确的个数
total_accuracy = total_accuracy + accuracy
total_test_step = total_test_step + 1
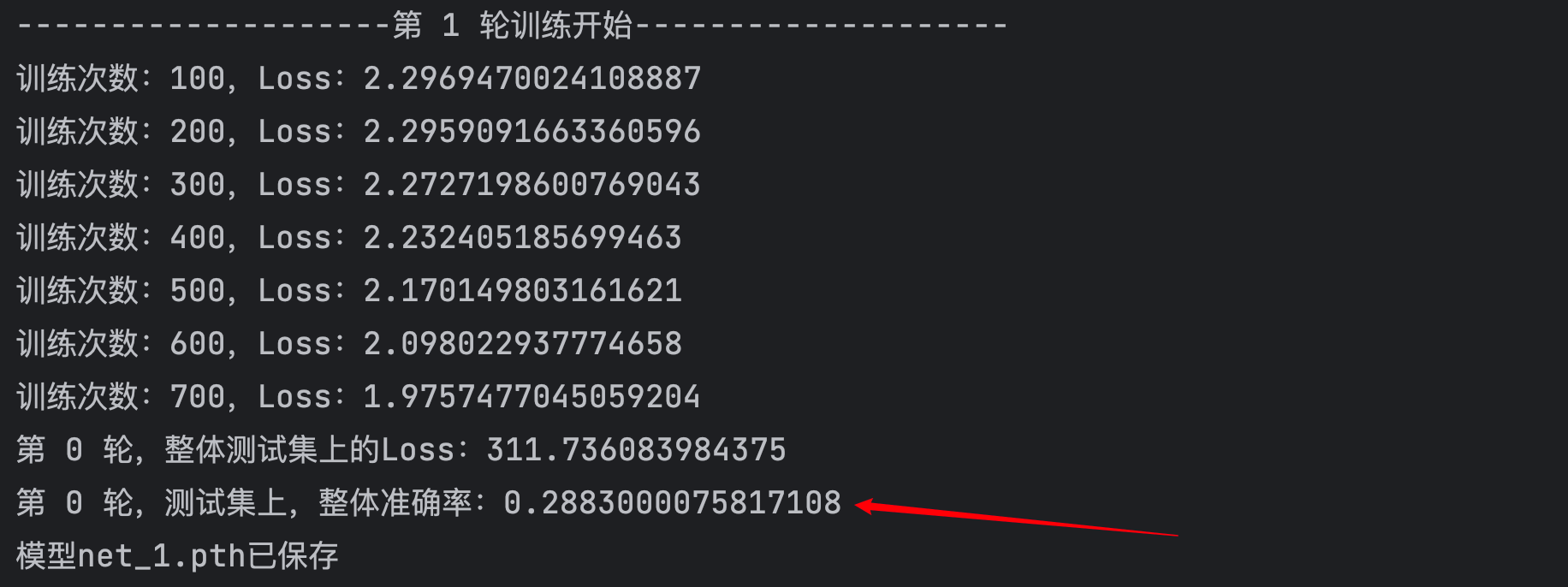
print("第 {} 轮,整体测试集上的Loss:{}".format(epoch,total_test_loss))
print("第 {} 轮,测试集上,整体准确率:{}".format(epoch,total_accuracy/test_data_size))
writer.add_scalar(tag="Test_Total_Loss",scalar_value=total_test_loss,global_step=total_test_step)
# 保存每一轮训练好的模型
torch.save(net,"./model/net_{}.pth".format(epoch+1))
print("模型net_{}.pth已保存".format(epoch+1))
writer.close()
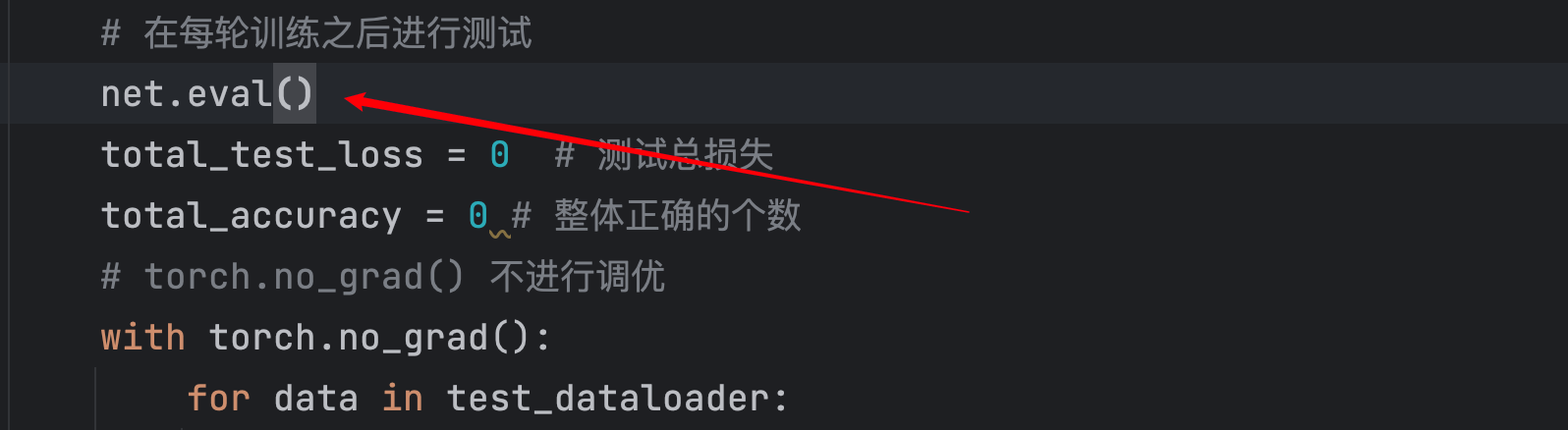
在有些代码中,人们在开始训练之前加上
net.train()。在开始测试之前加上net.eval()。train(),eval(),这仅仅对某些层有影响,如Dropout层、BatchNorm层等。并非全部的网络开始训练或者测试时都需要调用该方法。
12. 利用GPU训练
第一种GPU训练方式:
- 确定网络模型
- 准备数据(输入,标注)
- 损失函数
- 调用
.cuda()/或调用.to(device)方法
如:
device = torch.decive("cuda")
net = net.to(device)
使用CUDA
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch import nn
import torch
from torchvision import transforms,datasets
class Net(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3,32,kernel_size=5,padding=2,stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, padding=2,stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32,64,kernel_size=5,padding=2,stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
return self.model(x)
# 扫描数据集次数
epochs = 10
# 学习率
# learning_rate = 0.01
learning_rate = 1e-2 # 1e-2 = 1*10^(-2) = 0.01
to_tensor = transforms.ToTensor()
# 读取数据
train_dataset = datasets.CIFAR10(root="./dataset",train=True,download=True,transform=to_tensor)
test_dataset = datasets.CIFAR10(root="./dataset",train=False,download=True,transform=to_tensor)
# 加载数据
train_dataloader = DataLoader(train_dataset,batch_size=64,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_dataset,batch_size=64,shuffle=True,num_workers=0)
# 训练数据集大小
train_data_size = len(train_dataset)
# 测试数据集大小
test_data_size = len(test_dataset)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 创建网络
net = Net()
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)
# 使用GPU!!
if torch.cuda.is_available():
net = net.cuda()
loss = loss.cuda()
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 添加 tensorboard
writer = SummaryWriter("logs")
# 训练
for epoch in range(epochs):
print("--------------------第 {} 轮训练开始--------------------".format(epoch+1))
net.train()
for data in train_dataloader:
images, targets = data
# 使用GPU!!
if torch.cuda.is_available():
images = images.cuda()
targets = targets.cuda()
outputs = net(images)
loss_output = loss(outputs,targets)
# 优化器优化模型
optimizer.zero_grad()
loss_output.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step%100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss_output.item()))
writer.add_scalar(tag="Train_Loss", scalar_value=loss_output.item(), global_step=total_train_step)
# 在每轮训练之后进行测试
net.eval()
total_test_loss = 0 # 测试总损失
total_accuracy = 0 # 整体正确的个数
# torch.no_grad() 不进行调优
with torch.no_grad():
for data in test_dataloader:
images,targets = data
# 使用GPU!!
if torch.cuda.is_available():
images = images.cuda()
targets = targets.cuda()
outputs = net(images)
loss_output = loss(outputs,targets)
total_test_loss = total_test_loss + loss_output
accuracy = (targets == torch.argmax(outputs,dim=1)).sum() # 计算正确的个数
total_accuracy = total_accuracy + accuracy
total_test_step = total_test_step + 1
print("第 {} 轮,整体测试集上的Loss:{}".format(epoch,total_test_loss))
print("第 {} 轮,测试集上,整体准确率:{}".format(epoch,total_accuracy/test_data_size))
writer.add_scalar(tag="Test_Total_Loss",scalar_value=total_test_loss,global_step=total_test_step)
# 保存每一轮训练好的模型
torch.save(net,"./model/net_{}.pth".format(epoch+1))
print("模型net_{}.pth已保存".format(epoch+1))
writer.close()
在MAC上,使用MPS
import torch
from torch.utils.data import DataLoader
from torchvision import transforms,datasets
from torch import nn
from torch.utils.tensorboard import SummaryWriter
class Net(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3,32,kernel_size=5,padding=2,stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, padding=2,stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32,64,kernel_size=5,padding=2,stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
return self.model(x)
# 扫描数据集次数
epochs = 10
# 学习率
# learning_rate = 0.01
learning_rate = 1e-2 # 1e-2 = 1*10^(-2) = 0.01
to_tensor = transforms.ToTensor()
# 读取数据
train_dataset = datasets.CIFAR10(root="./dataset",train=True,download=True,transform=to_tensor)
test_dataset = datasets.CIFAR10(root="./dataset",train=False,download=True,transform=to_tensor)
# 加载数据
train_dataloader = DataLoader(train_dataset,batch_size=64,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_dataset,batch_size=64,shuffle=True,num_workers=0)
# 训练数据集大小
train_data_size = len(train_dataset)
# 测试数据集大小
test_data_size = len(test_dataset)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 创建网络
net = Net()
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)
# 使用GPU
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
net.to(device)
loss.to(device)
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 添加 tensorboard
writer = SummaryWriter("gpu_logs")
# 训练
for epoch in range(epochs):
print("--------------------第 {} 轮训练开始--------------------".format(epoch+1))
net.train()
for data in train_dataloader:
images, targets = data
# 使用GPU
images = images.to(device)
targets = targets.to(device)
outputs = net(images)
loss_output = loss(outputs,targets)
# 优化器优化模型
optimizer.zero_grad()
loss_output.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step%100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss_output.item()))
writer.add_scalar(tag="Train_Loss", scalar_value=loss_output.item(), global_step=total_train_step)
# 在每轮训练之后进行测试
net.eval()
total_test_loss = 0 # 测试总损失
total_accuracy = 0 # 整体正确的个数
# torch.no_grad() 不进行调优
with torch.no_grad():
for data in test_dataloader:
images,targets = data
# 使用GPU
images = images.to(device)
targets = targets.to(device)
outputs = net(images)
loss_output = loss(outputs,targets)
total_test_loss = total_test_loss + loss_output
accuracy = (targets == torch.argmax(outputs,dim=1)).sum() # 计算正确的个数
total_accuracy = total_accuracy + accuracy
total_test_step = total_test_step + 1
print("第 {} 轮,整体测试集上的Loss:{}".format(epoch,total_test_loss))
print("第 {} 轮,测试集上,整体准确率:{}".format(epoch,total_accuracy/test_data_size))
writer.add_scalar(tag="Test_Total_Loss",scalar_value=total_test_loss,global_step=total_test_step)
# 保存每一轮训练好的模型
torch.save(net,"./model/net_{}.pth".format(epoch+1))
print("模型net_{}.pth已保存".format(epoch+1))
writer.close()
M1 Pro 使用GPU跑20轮,用时 0:01:39.507960 ,YYDS!
cuda分配给:
- 网络模型对象
- 损失函数对象
- 训练数据输入、标签,测试数据输入、标签
mps要分配给:
- 网络模型对象
- 损失函数对象
- 训练数据输入、标签,测试数据输入、标签
13. 完整的模型验证套路
利用已经训练好的模型,然后给它提供输入。
从网上下载几张图片。

import torch
from torchvision import transforms, datasets
from PIL import Image, ImageDraw, ImageFont
from model import Net
import os
# 读取数据 为了获取标签
test_dataset = datasets.CIFAR10(root="./dataset",train=False,download=True)
classes = test_dataset.classes
# 定义图片变换
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor()
])
# 读取图片
root_dir = "./images"
image_list = os.listdir("./images")
image_tensor_list = []
image_PIL_list = []
for item in image_list:
path = os.path.join(root_dir,item)
image_PIL = Image.open(path)
image_tensor = transform(image_PIL)
image_tensor = torch.reshape(image_tensor, (-1, 3, 32, 32))
image_tensor = image_tensor.to(device)
image_PIL_list.append(image_PIL)
image_tensor_list.append(image_tensor)
# 读取模型 因为训练时使用的是gpu(mps) 我们测试时要映射为使用cpu进行测试
net = torch.load("./model/net_gpu_43.pth",map_location="cpu")
# 测试
num = 0
net.eval()
with torch.no_grad():
for item in image_tensor_list:
output = net(item)
output_index = torch.argmax(output, dim=1)
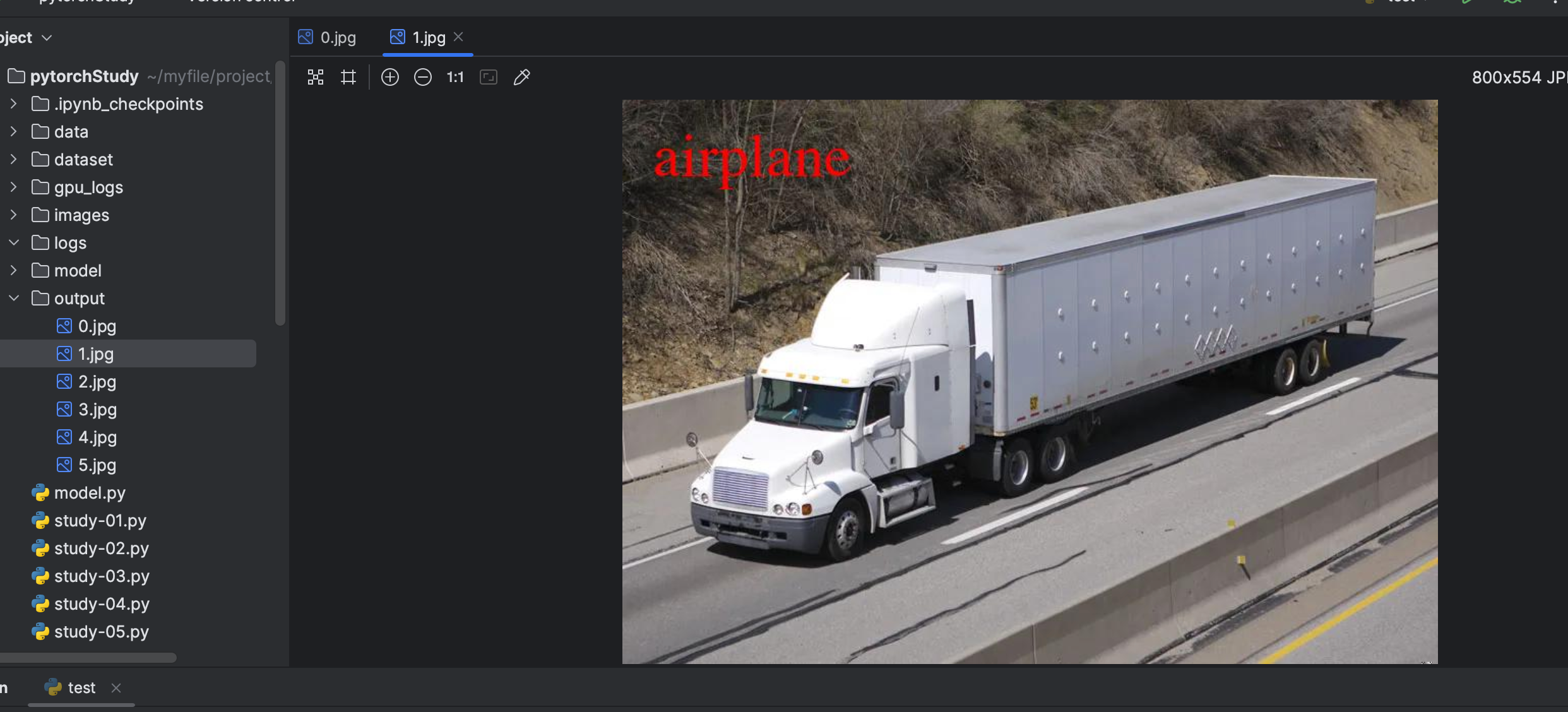
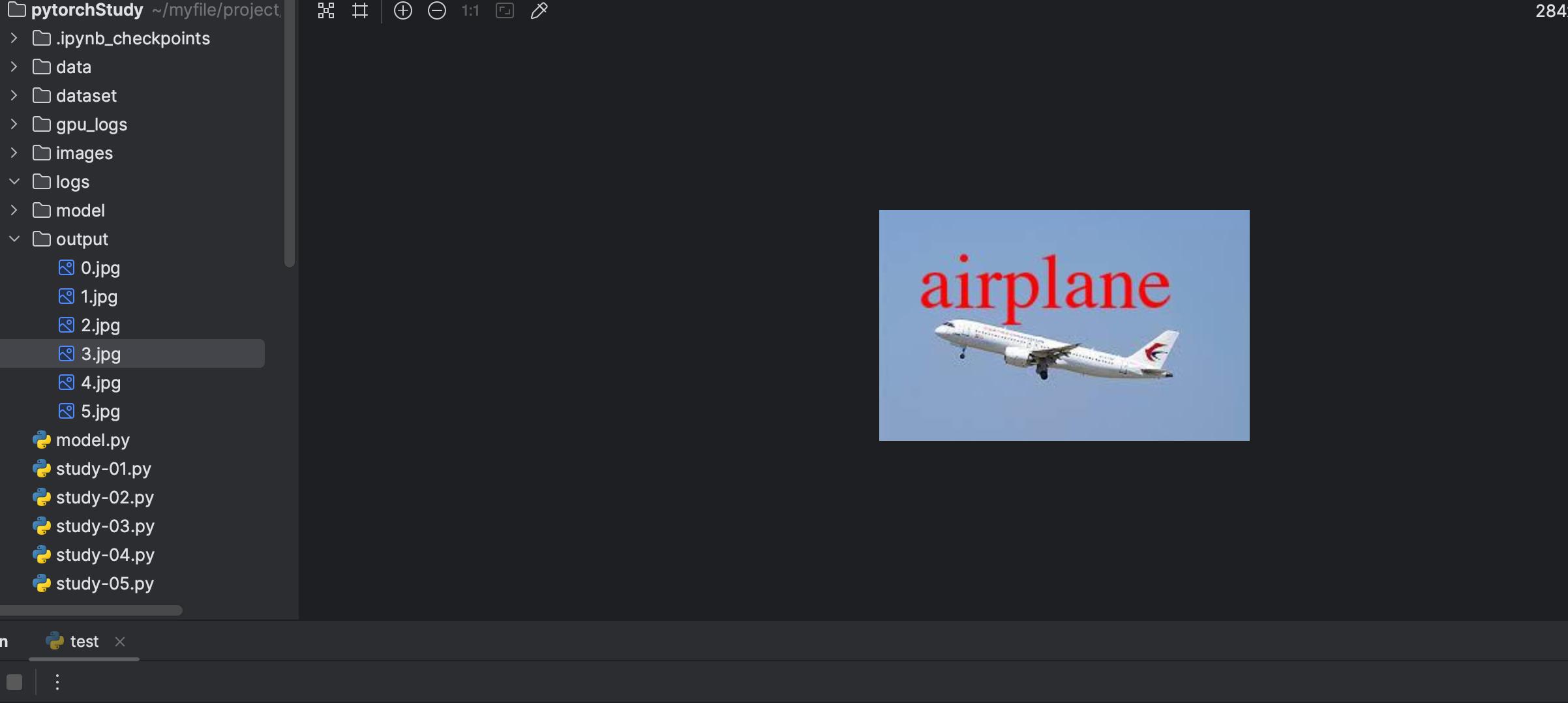
out_text = classes[output_index]
# 图片中写入文字
H1 = ImageDraw.Draw(image_PIL_list[num])
myFont = ImageFont.truetype('/System/Library/Fonts/Times.ttc', size=60)
H1.text((30,30),out_text,fill=(255,0,0),font=myFont)
image_PIL_list[num].save(os.path.join("./output",str(num)+".jpg"))
num = num + 1