一 数学建模简介
数学建模创办于1992年,每年一届,是首批列入“高校学科竞赛排行榜”的19项竞赛之一。2022年,来自全国及英国、马来西亚的1606所院校/校区、54257队(本科49424队、专科4833队)、超过16万人报名参赛。是目前奖项最具有含金量的竞赛之一,对于工作和研究生之旅都有着极为关键的助力。
- 人数:按小组报名参加,每组三人
- 竞赛时长:三天
- 竞赛时间:每年9月初,为期三天,提前一天晚6点开始,最后一天20时前生成
MD5码,20时 至 22时之间最多只许上传参赛作品的MD5码1次(2023年是9月7日18时至9月10日20时,MD5码生成后不允许打开、查看、修改文件) - 赛题:本科组A、B、C任选一道,专科组则在ABCDE选
- 获奖:根据当地情况定获奖名额,有些地方是固定的可以问问学长学姐
- 历年真题和更多信息:官网http://www.mcm.edu.cn/index_cn.html
二 数学建模竞赛流程
2.1 软件安装
注意保证小组内软件安装的版本一致
- MATLAB:用于复杂数据分析、算法、数据矩阵等的应用程序
- Spss:快捷的数据分析工具
- Mathtype:专业的数学公式编辑器
- Mathpix: 截取数学公式图片并转换为 LaTeX/Word 格式代码的工具,可以在文档和电子表格中快速插入数学公式
- AxGlyph: 高效的学术绘图工具
2.2 赛前准备(时间安排)
- 赛前养足精神不熬夜
- 安排好时间,建议最后一晚熬夜
- 确定能够大声讨论,有插座(最好空调),无蚊虫叮咬的场地
- 确保手机和电脑没有违反比赛规则的群聊等(资料群考试期间必须禁言)
2.3 题型选择(本科组)
2.3.1 题型分析
A题偏向物理/工程类,
- 一般来说有固定答案
- 需要使用微分方程和偏微分方程模型
- 神经网络/遗传算法等求解较优解的启发式算法一般不适用
- 热力学等物理题可以先建立一个非常简陋的模型,再根据题目中的要求逐步改进
B题由于近两年改革,题型不定, 21年化学类, 22年运筹优化类
C题偏向经管/运筹/统计/数据分析类
- 赛题较开放易读懂
- 运筹优化类问题一般没有严格最优解,结果合理即可
- 数据往往需要自己找
2.3.1 选择原则
- 若问题背景描述的语句都读不懂,则优先排除
- 先查书籍、知网、百度、谷歌,优先考虑资料较多的
- 啥都不会就选C题
- 尽量开赛后6小时内定题,不要轻易换题
- 万一做到一半发现做不出来,就开始语文建模(瞎编)
2.4 查询资料
2.4.1 搜索引擎查询技巧(Baidu)
- 完全匹配搜索:查询词的外边加上双引号
“”(中英文均可),可以让搜索标题或者内容出现完全一致的查询词
- 标题必含关键词:查询词前加上
intitle:,查询词的外边加上双引号“” - 搜索文档文件:例如查询词后空格再输入
filetype:文件格式(doc/pdf/xls/等等)
例如:搜索:线性规划 filetype:pdf得到的就都是pdf版的资料 - 去掉不想要的:查询词后面加空格后加减号与关键字
例如:搜索后不想看百度文库的东西,搜索线性规划 filetype:pdf -百度文库
2.4.2 文献查询技巧(中国知网)
国赛一般无需查询外网的论文,从知网的硕博士论文看起,硕博论文会对研究的问题有详细的背景和基础知识介绍,可帮助我们快速理解题目
- 按照被引排序
- 使用高级检索(以神经网络在信贷策略中的应用为例)
- 进入高级检索界面,
+和-可以自定义增加和减少检索字段 - 主题为:企业信贷
- OR 主题为:信贷决策
- AND 关键词:神经网络,词频设置为模糊。模糊是指输入的检索词在检索结果中出现即可,字序、字间间隔可以产生变化。
- 检索结果可按相关度或被引排序

- 谷歌学术镜像国内不能访问谷歌学术,而镜像对一个网站内容的拷贝
- Open Access Library 文章都来自顶级著名的出版商和数据库,可以满足各个领域学者的需求,文章免费下载
2.4.3 数据查询技巧
- 优先在知网、谷歌学术等平台搜索
- 国家统计局最全面,月度季度年度,各地区各部门各行业,包罗万象。其他国家部门网站大多都有数据分页,如果需要可另行查找
- awesome-public-datasetsGitHub上的一个项目, 包含了经济、地理、能源、教育等所有你能想到的领域的数据
- EPSDATA平台有丰富的数据资源和大量分析处理过的数据结果,是收费的,不过可以申请7天的试用
- 其他:国家信息中心, kaggle和鲸社区等等
2.5 数据预处理
2.5.1 缺失值
比赛提供的数据,发现有些单元格是null或空的
-
删除
当缺失太多时,例如调查人口信息,发现“年龄”这一项缺失了40%,就直接把该项指标删除 -
均值、众数插补
- 定量数据,例如关于一群人的身高、年龄等数据,用整体的均值来补缺失
- 定性数据,例如关于一群人的性别、文化程度;某些事件调查的满意度,用出现次数最多的值补缺失
- 适用赛题: 人口的数量年龄、经济产业情况等统计数据,对个体精度要求不大的数据
- Newton插值法
- 根据固定公式,构造近似函数,补上缺失值,普遍适用性强
- 缺点:区间边缘处的不稳定震荡,即龙格现象。不适合对导数有要求的题目
- 适用赛题:热力学温度、地形测量、定位等只追求函数值精准而不关心变化的数据
- 样条插值法
- 用分段光滑的曲线去插值,光滑意味着曲线不仅连续,还要有连续的曲率
- 适用赛题: 零件加工,水库水流量,图像“基线漂移”,机器人轨迹等精度要求高、没有突变的数据
- 分段插值
- Hermite插值
…
2.5.2 异常值
异常值是指样本中明显和其他数值差异很大的数据,例如一群人的身高数据中有个3米2的。用合适的定位法定位到异常值后,异常值的处理方法与缺失值处理相同。
2.5.2.1 正态分布法
适用题目:总体符合正态分布,例如人口数据、测量误差、生产加工质量、考试成绩等
- 定位方法:正态分布3σ原则(正态分布的图像是中间多两边少)
数值分布在(μ -3σ,μ+3σ)中的概率为99.73%,其中μ为平均值,σ为标准差 - 求解步骤: (1)计算
均值μ和标准差σ;
(2)判断每个数据值是否在(μ -3σ,μ+3σ)内,不在则为异常值
2.5.2.2 画箱型图法
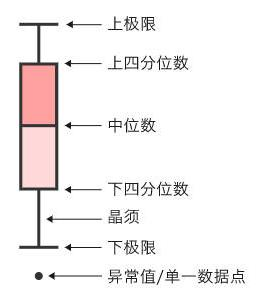
适用题目:普遍适用,常用于总体符合非正态分布,例如公交站人数排队论符合泊松分布。
- 定位方法:箱型图中,把数据从小到大排序。下四分位数
𝑄1是排第25%的数值,上四分位数𝑄3是排第75%的数值
• 四分位距𝐼𝑄𝑅 = 𝑄3- 𝑄1,也就是排名第75%的减去第25%的数值
• 与正态分布类似,设置个合理区间,在区间外的就是异常值
• 一般设[𝑄1 − 1.5 ∗ 𝐼𝑄𝑅, 𝑄3 + 1.5 ∗ 𝐼𝑄𝑅]内为正常值
三 数学建模基本步骤
- 研究问题
- 建模:问题数学化
- 求解:算法+软件
- 讨论分析
- 撰写数模论文
3.1 什么是建模
打开《大学物理》 ,里面的某一节,就是一个建模过程。
- 有理论基础(查文献,无需知道原理)
- 有推导过程
- 有最终结论
- 以文字描述、数学公式、图像表格展现出来
3.2 数模论文结构
一篇完整的数模论文包括摘要(最重要)、问题重述、模型假设和符号说明、模型建立与求解(最长)、模型的优缺点与改进、方法、参考文献和附录。
- 摘要(最重要):读者看完摘要,就知道论文研究的问题、用了什么方法、求得了什么结果,以及每一部分的大致步骤
- 问题重述:将题目简述一遍即可,并不重要。注意不要复制粘贴,避免查重
- 模型假设和符号说明:
• 好的假设能让你事半功倍
• 例如某一年太阳投影问题,影子长度与地球公转也有关系,但地球公转对影长的影响远远小于自转,可在模型假设里说明“忽略公转对影长的影响”
• 符号说明将论文中定义的重要符号列出表格说明即可 - 模型的建立:一组公式,和对公式中每个变量的解释,就是一个模型。建立模型时,先查阅资料, 用自己的话复述一个简单的模型,再根据题目中的约束条件去一步步修改模型,把题目中的变量带入模型中去。
模型的求解:
•
•
• 例如上文我们所建立的最短路径模型,查阅资料可知单源最短路径的常用算法是Dijkstra算法,那么模型的
求解过程可以把资料上的用自己的话复述一遍:
• 需要注意的是,必须根据赛题解释清楚“起始点”在本问题中究竟是什么、算法里的“节点”在本题中的
实际意义是什么、最短路径意味着什么
采用Dijkstra算法求解 : (以下内容可以百度或从常见资料里找到)
• 从起始点开始,将起点放进集合N中,查找所有与其相连的节点及到达下一节点的花费,
并且记录下来;
• 接下来选择花费最短的一条路径,到这条最短路径指向的节点去,把这个点也放进集
合N中,然后查找所有与这个节点相连的其他不在集合N中的点,并且也计算到达下一
点所需要的花费并记录下来。保存花费最小的一条记录;
• 继续选择花费最短的路径重复执行第2步,一直到所有的点都已有了最短路径,完毕。
视频出自b站up主:数学建模BOOM关注公众号/B站:数学建模BOOM,带你玩转数学建模~ 交流群: 887602371
数学建模 | 究竟怎么建模 数学建模BOOM
❑建模过程
• 不同小问
• 并不是针对题目的每一问都要建立一个模型
• 如果每小问之间具有相似性、仅仅是增加了约束条件的话,完全可以全文建立一个模型,再针对每一小问
进行模型改进。
视频出自b站up主:数学建模BOOM关注公众号/B站:数学建模BOOM,带你玩转数学建模~ 交流群: 887602371
数学建模 | 究竟怎么建模 数学建模BOOM
❑建模过程
• 模型的优缺点与改进方法
• 这一部分不是必须的,可以简单分析下前文模型的优缺点,若没有改进方法也可不写
• 结合查到的文献,分析正文中模型常用在什么哪种问题,又与本文所求解的问题有何区别
• 参考文献
• 格式一定要规范
• 知网检索结果右侧有引用按钮,打开后复制即可
• 附录
• 附录里要写出正文中求解时用到的代码
• 一定不要把网上搜到的代码直接复制粘贴!!!
• 把查到的代码里变量名换一换就不会被查重
• 曾出现过参加国赛,在省内被推到国奖,但查重发现代码是复制的,结果被取消获奖并官网通报的先例