需求
找到最常用的200个协议
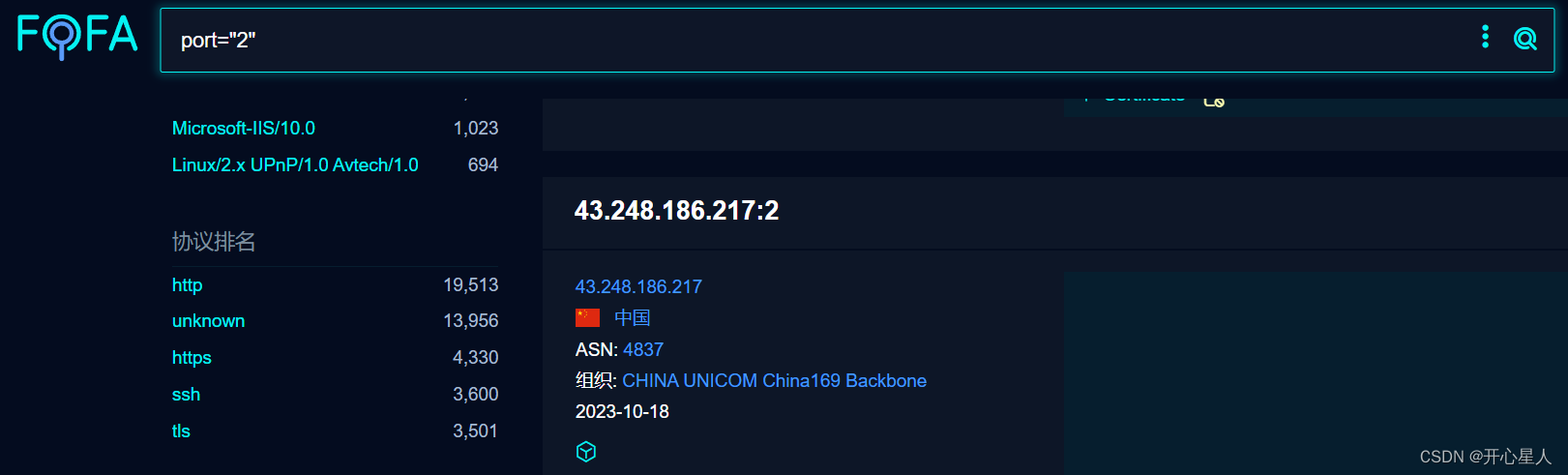
通过fofa搜索端口,得到协议排名前五名和对应机器的数目。
遍历端口,统计各个协议对应的机器数目(不准,但能看出个大概)
读写API
API需要会员,一天只能访问1000次。
import base64
import urllib
from time import sleep
import requests
res = {}
def onePort(j):
text = 'port="' + str(j) + '"'
text = base64.b64encode(text.encode("utf-8")).decode("utf-8")
text = urllib.parse.quote(text)
URL = f'https://fofa.info/api/v1/search/stats?fields=protocol&qbase64={text}&email=*****&key=*****'
r = requests.get(URL)
response_dict = r.json()
print("当前端口为:",j)
print(response_dict)
protocols=response_dict['aggs']['protocol']
for i in protocols:
if i['name'] in res:
res[i['name']] = res[i['name']] + i['count']
else:
res[i['name']] = i['count']
print(res)
for i in range(1,65535):
onePort(i)
sleep(10)
爬虫
页面动态加载,由于动态渲染的问题,有的请求返回结果为空。
单线程,未登录爬虫代码
import base64
import json
import urllib
from concurrent.futures import ThreadPoolExecutor
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from lxml import etree
from time import sleep
#直接添加这四行代码
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
# options.add_argument('--disable-gpu')
failed=[]
success=[]
res = {}
def onePort(j):
s = Service(r".\chromedriver.exe")
driver = webdriver.Chrome(service=s,options=options)
text = 'port="' + str(j) + '"'
text = base64.b64encode(text.encode("utf-8")).decode("utf-8")
text = urllib.parse.quote(text)
print(text)
driver.get("https://fofa.info/result?qbase64=" + text)
sleep(7)
page_text = driver.page_source
# print(page_text)
tree = etree.HTML(page_text)
protos = tree.xpath(
'//div[@class="hsxa-ui-component hsxa-meta-data-statistical-list hsxa-pos-rel"]/div[13]//li//a/text()')
nums = tree.xpath(
'//div[@class="hsxa-ui-component hsxa-meta-data-statistical-list hsxa-pos-rel"]/div[13]//li//span/text()')
for i in range(len(protos)):
protos[i] = protos[i].strip(' ')
protos[i] = protos[i].strip('\n')
protos[i] = protos[i].strip(' ')
nums[i] = nums[i].strip(' ')
nums[i] = nums[i].strip('\n')
nums[i] = nums[i].strip(' ')
nums[i] = nums[i].replace(',', '')
nums[i] = int(nums[i])
if protos[i] in res:
res[protos[i]] = res[protos[i]] + nums[i]
else:
res[protos[i]] = nums[i]
print(protos)
print(nums)
if len(protos) == 0:
failed.append(j)
else:
success.append(j)
print("当前端口号:", j)
print("失败列表:", failed)
print("成功列表:", success)
print(res)
driver.quit()
for j in range(5000,10000):
onePort(j)
多线程未登录代码
一定要注意多线程同时读写问题,全局变量上锁
import base64
import json
import urllib
from concurrent.futures import ThreadPoolExecutor
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from lxml import etree
from time import sleep
import threading
# 直接添加这四行代码
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
# options.add_argument('--disable-gpu')
failed = []
success = []
res = {}
lock = threading.Lock() # 创建线程锁
def onePort(j):
s = Service(r".\chromedriver.exe")
driver = webdriver.Chrome(service=s, options=options)
text = 'port="' + str(j) + '"'
text = base64.b64encode(text.encode("utf-8")).decode("utf-8")
text = urllib.parse.quote(text)
print(text)
driver.get("https://fofa.info/result?qbase64=" + text)
sleep(7)
page_text = driver.page_source
# print(page_text)
tree = etree.HTML(page_text)
protos = tree.xpath(
'//div[@class="hsxa-ui-component hsxa-meta-data-statistical-list hsxa-pos-rel"]/div[13]//li//a/text()')
nums = tree.xpath(
'//div[@class="hsxa-ui-component hsxa-meta-data-statistical-list hsxa-pos-rel"]/div[13]//li//span/text()')
with lock: # 使用线程锁保护对res变量的读写操作
for i in range(len(protos)):
protos[i] = protos[i].strip(' ')
protos[i] = protos[i].strip('\n')
protos[i] = protos[i].strip(' ')
nums[i] = nums[i].strip(' ')
nums[i] = nums[i].strip('\n')
nums[i] = nums[i].strip(' ')
nums[i] = nums[i].replace(',', '')
nums[i] = int(nums[i])
if protos[i] in res:
res[protos[i]] = res[protos[i]] + nums[i]
else:
res[protos[i]] = nums[i]
print(protos)
print(nums)
if len(protos) == 0:
failed.append(j)
else:
success.append(j)
print("当前端口号:", j)
print("失败列表:", failed)
print("成功列表:", success)
print(res)
driver.quit()
with ThreadPoolExecutor(30) as t:
for j in range(10000,10500):
# 把下载任务提交给线程池
t.submit(onePort, j)
手动登录获取cookie代码
# 填写webdriver的保存目录
s = Service(r".\chromedriver.exe")
driver= webdriver.Chrome(service=s)
# 记得写完整的url 包括http和https
driver.get('https://fofa.info')
# 程序打开网页后20秒内 “手动登陆账户”
time.sleep(20)
with open('cookies.txt','w') as f:
# 将cookies保存为json格式
f.write(json.dumps(driver.get_cookies()))
driver.close()
登录账号的单线程爬虫
from selenium import webdriver
import time
import json
from selenium.webdriver.chrome.service import Service
import base64
import json
import urllib
from concurrent.futures import ThreadPoolExecutor
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from lxml import etree
from time import sleep
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.options import Options
options = Options()
# options.add_argument('--headless')
# options.add_argument('--disable-gpu')
options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
failed=[]
success=[]
res = {}
s = Service(r".\chromedriver.exe")
driver = webdriver.Chrome(service=s, options=options)
driver.get('https://fofa.info')
# 首先清除由于浏览器打开已有的cookies
driver.delete_all_cookies()
with open('cookies.txt', 'r') as f:
# 使用json读取cookies 注意读取的是文件 所以用load而不是loads
cookies_list = json.load(f)
# 将expiry类型变为int
for cookie in cookies_list:
# 并不是所有cookie都含有expiry 所以要用dict的get方法来获取
if isinstance(cookie.get('expiry'), float):
cookie['expiry'] = int(cookie['expiry'])
driver.add_cookie(cookie)
# 重新发送请求(这步是非常必要的,要不然携带完cookie之后仍然在登录界面)
driver.get('https://fofa.info')
# sleep等待页面完全加载出来,这一步很关键
time.sleep(3)
j=2
text = 'port="' + str(j) + '"'
text = base64.b64encode(text.encode("utf-8")).decode("utf-8")
text = urllib.parse.quote(text)
print(text)
sleep(10)
driver.get("https://fofa.info/result?qbase64=" + text)
sleep(6)
page_text = driver.page_source
print(page_text)
tree = etree.HTML(page_text)
protos = tree.xpath(
'//div[@class="hsxa-ui-component hsxa-meta-data-statistical-list hsxa-pos-rel"]/div[13]//li//a/text()')
nums = tree.xpath(
'//div[@class="hsxa-ui-component hsxa-meta-data-statistical-list hsxa-pos-rel"]/div[13]//li//span/text()')
for i in range(len(protos)):
protos[i] = protos[i].strip(' ')
protos[i] = protos[i].strip('\n')
protos[i] = protos[i].strip(' ')
nums[i] = nums[i].strip(' ')
nums[i] = nums[i].strip('\n')
nums[i] = nums[i].strip(' ')
nums[i] = nums[i].replace(',', '')
nums[i] = int(nums[i])
if protos[i] in res:
res[protos[i]] = res[protos[i]] + nums[i]
else:
res[protos[i]] = nums[i]
print(protos)
print(nums)
if len(protos) == 0:
failed.append(j)
else:
success.append(j)
print("当前端口号:", j)
print("失败列表:", failed)
print("成功列表:", success)
print(res)
driver.quit()