Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 五、Catalog API
- 4、分区操作
- 1)、官方示例
- 2)、API创建hive分区示例
- 1、maven依赖
- 2、代码
- 3、运行结果
- 5、函数操作
- 1)、官方示例
- 2)、API操作Function
- 1、maven依赖
- 2、代码
- 3、运行结果
- 6、表操作(补充)
- 1)、官方示例
- 2)、SQL创建hive表示例
- 1、maven依赖
- 2、代码
- 3、运行结果
- 3)、API创建hive表-普通表
- 1、maven依赖
- 2、代码
- 3、运行结果
- 4)、API创建hive表-流式表
- 1、maven依赖
- 2、代码
- 3、运行结果
- 5)、API创建hive表-分区表
- 1、maven依赖
- 2、代码
- 3、运行结果
- 6)、SQL创建hive表-带hive属性的表(分隔符、分区以及ORC存储)
- 1、maven依赖
- 2、代码
- 3、运行结果
本文简单介绍了通过java api或者SQL操作分区、函数以及表,特别是创建hive的表,通过6个示例进行说明 。
本文依赖flink和hive、hadoop集群能正常使用。
本文示例java api的实现是通过Flink 1.13.5版本做的示例,hive的版本是3.1.2,hadoop的版本是3.1.4。
五、Catalog API
4、分区操作
1)、官方示例
// create view
catalog.createPartition(
new ObjectPath("mydb", "mytable"),
new CatalogPartitionSpec(...),
new CatalogPartitionImpl(...),
false);
// drop partition
catalog.dropPartition(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...), false);
// alter partition
catalog.alterPartition(
new ObjectPath("mydb", "mytable"),
new CatalogPartitionSpec(...),
new CatalogPartitionImpl(...),
false);
// get partition
catalog.getPartition(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));
// check if a partition exist or not
catalog.partitionExists(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));
// list partitions of a table
catalog.listPartitions(new ObjectPath("mydb", "mytable"));
// list partitions of a table under a give partition spec
catalog.listPartitions(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));
// list partitions of a table by expression filter
catalog.listPartitions(new ObjectPath("mydb", "mytable"), Arrays.asList(epr1, ...));
2)、API创建hive分区示例
本示例旨在演示如何使用flink api创建hive的分区表,至于hive的分区表如何使用,请参考hive的相关专题。同时,修改分区、删除分区都比较简单不再赘述。
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabase;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogPartition;
import org.apache.flink.table.catalog.CatalogPartitionImpl;
import org.apache.flink.table.catalog.CatalogPartitionSpec;
import org.apache.flink.table.catalog.CatalogTable;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogTable;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.module.hive.HiveModule;
/**
* @author alanchan
*
*/
public class TestHivePartitionByAPI {
static final String TEST_COMMENT = "test table comment";
static String databaseName = "viewtest_db";
static String tableName1 = "t1";
static String tableName2 = "t2";
static boolean isGeneric = false;
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
// catalog.createDatabase(db1, createDb(), false);
HiveCatalog hiveCatalog = init(tenv);
// 2、创建分区表
// catalog.createTable(path1, createPartitionedTable(), false);
// 2.1 创建分区表 t1
ObjectPath path1 = new ObjectPath(databaseName, tableName1);
hiveCatalog.createTable(path1, createPartitionedTable(), false);
// 2.21 创建分区表 t2,只有表名称不一致,体现不使用方法化的创建方式
ObjectPath path2 = new ObjectPath(databaseName, tableName2);
ResolvedSchema resolvedSchema = new ResolvedSchema(
Arrays.asList(Column.physical("id", DataTypes.INT()), Column.physical("name", DataTypes.STRING()), Column.physical("age", DataTypes.INT())),
Collections.emptyList(), null);
// Schema schema,
// @Nullable String comment,
// List<String> partitionKeys,
// Map<String, String> options
CatalogTable origin = CatalogTable.of(Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(), TEST_COMMENT, Arrays.asList("name", "age"),
new HashMap<String, String>() {
{
put("streaming", "false");
putAll(getGenericFlag(isGeneric));
}
});
CatalogTable catalogTable = new ResolvedCatalogTable(origin, resolvedSchema);
hiveCatalog.createTable(path2, catalogTable, false);
// 3、断言
// assertThat(catalog.listPartitions(path1)).isEmpty();
// 3、创建分区
// 3.1 创建分区方式1
// catalog.createPartition(path1, createPartitionSpec(), createPartition(), false);
// ObjectPath tablePath,
// CatalogPartitionSpec partitionSpec,
// CatalogPartition partition,
// boolean ignoreIfExists
hiveCatalog.createPartition(path1, createPartitionSpec(), createPartition(), false);
// 3.21 创建分区方式2
hiveCatalog.createPartition(path2, new CatalogPartitionSpec(new HashMap<String, String>() {
{
put("name", "alan");
put("age", "20");
}
}), new CatalogPartitionImpl(new HashMap<String, String>() {
{
put("streaming", "false");
putAll(getGenericFlag(isGeneric));
}
}, TEST_COMMENT), false);
System.out.println("path1 listPartitions:"+hiveCatalog.listPartitions(path1));
System.out.println("path2 listPartitions:"+hiveCatalog.listPartitions(path2));
System.out.println("path1 listPartitions:"+hiveCatalog.listPartitions(path1, createPartitionSpecSubset()));
System.out.println("path2 listPartitions:"+hiveCatalog.listPartitions(path2, createPartitionSpecSubset()));
// assertThat(hiveCatalog.listPartitions(path1)).containsExactly(createPartitionSpec());
// assertThat(catalog.listPartitions(path1, createPartitionSpecSubset())).containsExactly(createPartitionSpec());
// 4、检查分区
// CatalogTestUtil.checkEquals(createPartition(), catalog.getPartition(path1, createPartitionSpec()));
//5、删除测试数据库
// tenv.executeSql("drop database " + databaseName + " cascade");
}
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
// tenv.executeSql("create database "+databaseName);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
CatalogDatabase createDb() {
return new CatalogDatabaseImpl(new HashMap<String, String>() {
{
put("k1", "v1");
}
}, TEST_COMMENT);
}
static CatalogTable createPartitionedTable() {
final ResolvedSchema resolvedSchema = createSchema();
final CatalogTable origin = CatalogTable.of(Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(), TEST_COMMENT, createPartitionKeys(), getBatchTableProperties());
return new ResolvedCatalogTable(origin, resolvedSchema);
}
static ResolvedSchema createSchema() {
return new ResolvedSchema(
Arrays.asList(Column.physical("id", DataTypes.INT()), Column.physical("name", DataTypes.STRING()), Column.physical("age", DataTypes.INT())),
Collections.emptyList(), null);
}
static List<String> createPartitionKeys() {
return Arrays.asList("name", "age");
}
static Map<String, String> getBatchTableProperties() {
return new HashMap<String, String>() {
{
put("streaming", "false");
putAll(getGenericFlag(isGeneric));
}
};
}
static Map<String, String> getGenericFlag(boolean isGeneric) {
return new HashMap<String, String>() {
{
String connector = isGeneric ? "COLLECTION" : "hive";
put(FactoryUtil.CONNECTOR.key(), connector);
}
};
}
static CatalogPartitionSpec createPartitionSpec() {
return new CatalogPartitionSpec(new HashMap<String, String>() {
{
put("name", "alan");
put("age", "20");
}
});
}
static CatalogPartitionSpec createPartitionSpecSubset() {
return new CatalogPartitionSpec(new HashMap<String, String>() {
{
put("name", "alan");
}
});
}
static CatalogPartition createPartition() {
return new CatalogPartitionImpl(getBatchTableProperties(), TEST_COMMENT);
}
}
3、运行结果
- flink 运行结果
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.4-SNAPSHOT.jar
path1 listPartitions:[CatalogPartitionSpec{{name=alan, age=20}}]
path2 listPartitions:[CatalogPartitionSpec{{name=alan, age=20}}]
path1 listPartitions:[CatalogPartitionSpec{{name=alan, age=20}}]
path2 listPartitions:[CatalogPartitionSpec{{name=alan, age=20}}]
- hive 查看表分区情况
0: jdbc:hive2://server4:10000> desc formatted t1;
+-------------------------------+----------------------------------------------------+-----------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------+
| # col_name | data_type | comment |
| id | int | |
| | NULL | NULL |
| # Partition Information | NULL | NULL |
| # col_name | data_type | comment |
| name | string | |
| age | int | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | viewtest_db | NULL |
| OwnerType: | USER | NULL |
| Owner: | null | NULL |
| CreateTime: | Tue Oct 17 10:43:55 CST 2023 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopHAcluster/user/hive/warehouse/viewtest_db.db/t1 | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | bucketing_version | 2 |
| | comment | test table comment |
| | numFiles | 0 |
| | numPartitions | 1 |
| | numRows | 0 |
| | rawDataSize | 0 |
| | streaming | false |
| | totalSize | 0 |
| | transient_lastDdlTime | 1697510635 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+----------------------------------------------------+-----------------------+
5、函数操作
1)、官方示例
// create function
catalog.createFunction(new ObjectPath("mydb", "myfunc"), new CatalogFunctionImpl(...), false);
// drop function
catalog.dropFunction(new ObjectPath("mydb", "myfunc"), false);
// alter function
catalog.alterFunction(new ObjectPath("mydb", "myfunc"), new CatalogFunctionImpl(...), false);
// get function
catalog.getFunction("myfunc");
// check if a function exist or not
catalog.functionExists("myfunc");
// list functions in a database
catalog.listFunctions("mydb");
2)、API操作Function
通过api来操作函数,比如创建、修改删除以及查询等。
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
import java.util.HashMap;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogFunctionImpl;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.hadoop.hive.ql.udf.UDFRand;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDFAbs;
/**
* @author alanchan
*
*/
public class TestFunctionByAPI {
static String databaseName = "viewtest_db";
static String tableName1 = "t1";
public static void main(String[] args) throws Exception {
// 0、环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
// catalog.createDatabase(db1, createDb(), false);
HiveCatalog hiveCatalog = init(tenv);
// 2、检查function是否存在
ObjectPath path1 = new ObjectPath(databaseName, tableName1);
System.out.println("function是否存在 :" + hiveCatalog.functionExists(path1));
// 3、创建function
hiveCatalog.createFunction(path1, new CatalogFunctionImpl(GenericUDFAbs.class.getName()), false);
System.out.println("function是否存在 :" + hiveCatalog.functionExists(path1));
// 4、修改function
hiveCatalog.alterFunction(path1, new CatalogFunctionImpl(UDFRand.class.getName()), false);
System.out.println("修改后的function是否存在 :" + hiveCatalog.functionExists(path1));
System.out.println("查询function :" + hiveCatalog.getFunction(path1));
System.out.println("function 列表 :" + hiveCatalog.listFunctions(databaseName));
// 5、删除function
hiveCatalog.dropFunction(path1, false);
System.out.println("function是否存在 :" + hiveCatalog.functionExists(path1));
// 6、删除测试数据库
// tenv.executeSql("drop database " + databaseName + " cascade");
}
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
}
3、运行结果
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.5-SNAPSHOT.jar
function是否存在 :false
function是否存在 :true
修改后的function是否存在 :true
查询function :CatalogFunctionImpl{className='org.apache.hadoop.hive.ql.udf.UDFRand', functionLanguage='JAVA', isGeneric='false'}
function 列表 :[t1]
function是否存在 :false
6、表操作(补充)
1)、官方示例
// create table
catalog.createTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);
// drop table
catalog.dropTable(new ObjectPath("mydb", "mytable"), false);
// alter table
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);
// rename table
catalog.renameTable(new ObjectPath("mydb", "mytable"), "my_new_table");
// get table
catalog.getTable("mytable");
// check if a table exist or not
catalog.tableExists("mytable");
// list tables in a database
catalog.listTables("mydb");
2)、SQL创建hive表示例
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
import java.util.HashMap;
import java.util.List;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;
/**
* @author alanchan
*
*/
public class TestCreateHiveTableBySQLDemo {
static String databaseName = "viewtest_db";
public static final String tableName = "alan_hivecatalog_hivedb_testTable";
public static final String hive_create_table_sql = "CREATE TABLE " + tableName + " (\n" +
" id INT,\n" +
" name STRING,\n" +
" age INT" + ") " +
"TBLPROPERTIES (\n" +
" 'sink.partition-commit.delay'='5 s',\n" +
" 'sink.partition-commit.trigger'='partition-time',\n" +
" 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")";
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
HiveCatalog hiveCatalog = init(tenv);
// 2、创建表
tenv.getConfig().setSqlDialect(SqlDialect.HIVE);
tenv.executeSql(hive_create_table_sql);
// 3、插入数据
String insertSQL = "insert into " + tableName + " values (1,'alan',18)";
tenv.executeSql(insertSQL);
// 4、查询数据
List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + tableName).collect());
for (Row row : results) {
System.out.println(tableName + ": " + row.toString());
}
// 5、删除数据库
tenv.executeSql("drop database " + databaseName + " cascade");
}
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
}
3、运行结果
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.6-SNAPSHOT.jar
Hive Session ID = eb6579cd-befc-419b-8f95-8fd1e8e287e0
Hive Session ID = be12e47f-d611-4cc4-9be5-8e7628b7c90a
Job has been submitted with JobID 442b113232b8390394587b66b47aebbc
Hive Session ID = b8d772a8-a89d-4630-bbf1-fe5a3e301344
2023-10-17 07:23:31,244 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 0
Job has been submitted with JobID f24c2cc25fa3aba729fc8b27c3edf243
alan_hivecatalog_hivedb_testTable: +I[1, alan, 18]
Hive Session ID = 69fafc9c-f8c0-4f55-b689-5db196a94689
3)、API创建hive表-普通表
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogBaseTable;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogTable;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogTable;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;
/**
* @author alanchan
*
*/
public class TestCreateHiveTableByAPIDemo {
static String TEST_COMMENT = "test table comment";
static String databaseName = "hive_db_test";
static String tableName1 = "t1";
static String tableName2 = "t2";
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
HiveCatalog hiveCatalog = init(tenv);
// 2、创建表
ObjectPath path1 = new ObjectPath(databaseName, tableName1);
ResolvedSchema resolvedSchema = new ResolvedSchema(
Arrays.asList(
Column.physical("id", DataTypes.INT()),
Column.physical("name", DataTypes.STRING()),
Column.physical("age", DataTypes.INT())),
Collections.emptyList(), null);
CatalogTable origin = CatalogTable.of(
Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(),
TEST_COMMENT,
Collections.emptyList(),
new HashMap<String, String>() {
{
put("is_streaming", "false");
putAll(new HashMap<String, String>() {
{
put(FactoryUtil.CONNECTOR.key(), "hive");
}
});
}
});
CatalogTable catalogTable = new ResolvedCatalogTable(origin, resolvedSchema);
// 普通表
hiveCatalog.createTable(path1, catalogTable, false);
CatalogBaseTable tableCreated = hiveCatalog.getTable(path1);
List<String> tables = hiveCatalog.listTables(databaseName);
for (String table : tables) {
System.out.println(" tableNameList : " + table);
}
// 3、插入数据
String insertSQL = "insert into " + tableName1 + " values (1,'alan',18)";
tenv.executeSql(insertSQL);
// 4、查询数据
List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + tableName1).collect());
for (Row row : results) {
System.out.println(tableName1 + ": " + row.toString());
}
hiveCatalog.dropTable(path1, false);
boolean tableExists = hiveCatalog.tableExists(path1);
System.out.println("表是否drop成功:" + tableExists);
// 5、删除数据库
tenv.executeSql("drop database " + databaseName + " cascade");
}
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
// tenv.executeSql("create database "+databaseName);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
}
3、运行结果
- flink 运行结果
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.7-SNAPSHOT.jar
tableNameList : t1
Job has been submitted with JobID b70b8c76fd3f05b9f949a47583596288
2023-10-17 09:01:19,320 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 0
Job has been submitted with JobID 34650c04d0a6fb32f7336f7ccc8b9090
t1: +I[1, alan, 18]
表是否drop成功:false
- hive 表描述
下述结果是表和数据库没有删除的时候查询结果,也就是将上述示例中关于删除表和库的语句注释掉了。
0: jdbc:hive2://server4:10000> desc formatted t1;
+-------------------------------+----------------------------------------------------+-----------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------+
| # col_name | data_type | comment |
| id | int | |
| name | string | |
| age | int | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | hive_db_test | NULL |
| OwnerType: | USER | NULL |
| Owner: | null | NULL |
| CreateTime: | Tue Oct 17 16:55:02 CST 2023 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopHAcluster/user/hive/warehouse/hive_db_test.db/t1 | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | bucketing_version | 2 |
| | comment | test table comment |
| | streaming | false |
| | transient_lastDdlTime | 1697532902 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+----------------------------------------------------+-----------------------+
4)、API创建hive表-流式表
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
该示例与上述使用API创建hive表功能一样,仅仅表示了方法化和流式表的创建方式,运行结果也一样,不再赘述。
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogTable;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogTable;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;
/**
* @author alanchan
*
*/
public class TestCreateHiveTableByAPIDemo {
static String TEST_COMMENT = "test table comment";
static String databaseName = "hive_db_test";
static String tableName1 = "t1";
static String tableName2 = "t2";
static ObjectPath path1 = new ObjectPath(databaseName, tableName1);
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
HiveCatalog hiveCatalog = init(tenv);
// 2、创建表
// 2.1、创建批处理表
// testCreateTable_Batch(hiveCatalog);
// 2.2、创建流式表
testCreateTable_Streaming(hiveCatalog);
// 3、插入数据
String insertSQL = "insert into " + tableName1 + " values (1,'alan',18)";
tenv.executeSql(insertSQL);
// 4、查询数据
List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + tableName1).collect());
for (Row row : results) {
System.out.println(tableName1 + ": " + row.toString());
}
hiveCatalog.dropTable(path1, false);
boolean tableExists = hiveCatalog.tableExists(path1);
System.out.println("表是否drop成功:" + tableExists);
// 5、删除数据库
tenv.executeSql("drop database " + databaseName + " cascade");
}
/**
* 初始化hivecatalog
*
* @param tenv
* @return
* @throws Exception
*/
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
// tenv.executeSql("create database "+databaseName);
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
/**
* 创建流式表
*
* @param catalog
* @throws Exception
*/
static void testCreateTable_Streaming(HiveCatalog catalog) throws Exception {
CatalogTable table = createStreamingTable();
catalog.createTable(path1, table, false);
// CatalogTestUtil.checkEquals(table, (CatalogTable) catalog.getTable(path1));
}
/**
* 创建批处理表
*
* @param catalog
* @throws Exception
*/
static void testCreateTable_Batch(HiveCatalog catalog) throws Exception {
// Non-partitioned table
CatalogTable table = createBatchTable();
catalog.createTable(path1, table, false);
// CatalogBaseTable tableCreated = catalog.getTable(path1);
// CatalogTestUtil.checkEquals(table, (CatalogTable) tableCreated);
// assertThat(tableCreated.getDescription().isPresent()).isTrue();
// assertThat(tableCreated.getDescription().get()).isEqualTo(TEST_COMMENT);
// List<String> tables = catalog.listTables(databaseName);
// assertThat(tables).hasSize(1);
// assertThat(tables.get(0)).isEqualTo(path1.getObjectName());
// catalog.dropTable(path1, false);
}
/**
* 创建流式表
*
* @return
*/
static CatalogTable createStreamingTable() {
final ResolvedSchema resolvedSchema = createSchema();
final CatalogTable origin = CatalogTable.of(
Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(),
TEST_COMMENT,
Collections.emptyList(),
getStreamingTableProperties());
return new ResolvedCatalogTable(origin, resolvedSchema);
}
/**
* 创建批处理表
*
* @return
*/
static CatalogTable createBatchTable() {
final ResolvedSchema resolvedSchema = createSchema();
final CatalogTable origin = CatalogTable.of(
Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(),
TEST_COMMENT,
Collections.emptyList(),
getBatchTableProperties());
return new ResolvedCatalogTable(origin, resolvedSchema);
}
/**
* 设置批处理表的属性
*
* @return
*/
static Map<String, String> getBatchTableProperties() {
return new HashMap<String, String>() {
{
put("is_streaming", "false");
putAll(new HashMap<String, String>() {
{
put(FactoryUtil.CONNECTOR.key(), "hive");
}
});
}
};
}
/**
* 创建流式表的属性
*
* @return
*/
static Map<String, String> getStreamingTableProperties() {
return new HashMap<String, String>() {
{
put("is_streaming", "true");
putAll(new HashMap<String, String>() {
{
put(FactoryUtil.CONNECTOR.key(), "hive");
}
});
}
};
}
static ResolvedSchema createSchema() {
return new ResolvedSchema(
Arrays.asList(
Column.physical("id", DataTypes.INT()),
Column.physical("name", DataTypes.STRING()),
Column.physical("age", DataTypes.INT())),
Collections.emptyList(), null);
}
}
3、运行结果
运行结果参考上述示例,运行结果一致。
5)、API创建hive表-分区表
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
本示例没有加载数据,仅示例创建的分区表,并且是2重分区表。关于hive分区表的操作,请参考链接:
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogPartition;
import org.apache.flink.table.catalog.CatalogPartitionImpl;
import org.apache.flink.table.catalog.CatalogPartitionSpec;
import org.apache.flink.table.catalog.CatalogTable;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogTable;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.exceptions.TableAlreadyExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;
/**
* @author alanchan
*
*/
public class TestCreateHiveTableByAPIDemo {
static String TEST_COMMENT = "test table comment";
static String databaseName = "hive_db_test";
static String tableName1 = "t1";
static String tableName2 = "t2";
static ObjectPath path1 = new ObjectPath(databaseName, tableName1);
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
HiveCatalog hiveCatalog = init(tenv);
// 2、创建表
// 2.1、创建批处理表
// testCreateTable_Batch(hiveCatalog);
// 2.2、创建流式表
// testCreateTable_Streaming(hiveCatalog);
// 2.3、创建分区批处理表
testCreatePartitionTable_Batch(hiveCatalog);
// 2.4、创建带有hive属性的批处理表
// 3、插入数据
// 分区表不能如此操作,具体参考相关内容
// String insertSQL = "insert into " + tableName1 + " values (1,'alan',18)";
// tenv.executeSql(insertSQL);
// 4、查询数据
List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + tableName1).collect());
for (Row row : results) {
System.out.println(tableName1 + ": " + row.toString());
}
hiveCatalog.dropTable(path1, false);
boolean tableExists = hiveCatalog.tableExists(path1);
System.out.println("表是否drop成功:" + tableExists);
// 5、删除数据库
tenv.executeSql("drop database " + databaseName + " cascade");
}
/**
* 初始化hivecatalog
*
* @param tenv
* @return
* @throws Exception
*/
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
// tenv.executeSql("create database "+databaseName);
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
/**
* 创建流式表
*
* @param catalog
* @throws Exception
*/
static void testCreateTable_Streaming(HiveCatalog catalog) throws Exception {
CatalogTable table = createStreamingTable();
catalog.createTable(path1, table, false);
// CatalogTestUtil.checkEquals(table, (CatalogTable) catalog.getTable(path1));
}
/**
* 创建批处理表
*
* @param catalog
* @throws Exception
*/
static void testCreateTable_Batch(HiveCatalog catalog) throws Exception {
// Non-partitioned table
CatalogTable table = createBatchTable();
catalog.createTable(path1, table, false);
// CatalogBaseTable tableCreated = catalog.getTable(path1);
// CatalogTestUtil.checkEquals(table, (CatalogTable) tableCreated);
// assertThat(tableCreated.getDescription().isPresent()).isTrue();
// assertThat(tableCreated.getDescription().get()).isEqualTo(TEST_COMMENT);
// List<String> tables = catalog.listTables(databaseName);
// assertThat(tables).hasSize(1);
// assertThat(tables.get(0)).isEqualTo(path1.getObjectName());
// catalog.dropTable(path1, false);
}
/**
*
* @param catalog
* @throws DatabaseNotExistException
* @throws TableAlreadyExistException
* @throws CatalogException
*/
static void testCreatePartitionTable_Batch(HiveCatalog catalog) throws Exception {
CatalogTable table = createPartitionedTable();
catalog.createTable(path1, table, false);
// 创建分区
catalog.createPartition(path1, createPartitionSpec(), createPartition(), false);
}
/**
* 创建分区表
*
* @return
*/
static CatalogTable createPartitionedTable() {
final ResolvedSchema resolvedSchema = createSchema();
final CatalogTable origin = CatalogTable.of(Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(), TEST_COMMENT, createPartitionKeys(), getBatchTableProperties());
return new ResolvedCatalogTable(origin, resolvedSchema);
}
/**
* 创建分区键
*
* @return
*/
static List<String> createPartitionKeys() {
return Arrays.asList("name", "age");
}
/**
* 创建CatalogPartitionSpec。 Represents a partition spec object in catalog.
* Partition columns and values are NOT of strict order, and they need to be
* re-arranged to the correct order by comparing with a list of strictly ordered
* partition keys.
*
* @return
*/
static CatalogPartitionSpec createPartitionSpec() {
return new CatalogPartitionSpec(new HashMap<String, String>() {
{
put("name", "alan");
put("age", "20");
}
});
}
static CatalogPartition createPartition() {
return new CatalogPartitionImpl(getBatchTableProperties(), TEST_COMMENT);
}
/**
* 创建流式表
*
* @return
*/
static CatalogTable createStreamingTable() {
final ResolvedSchema resolvedSchema = createSchema();
final CatalogTable origin = CatalogTable.of(Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(), TEST_COMMENT, Collections.emptyList(),
getStreamingTableProperties());
return new ResolvedCatalogTable(origin, resolvedSchema);
}
/**
* 创建批处理表
*
* @return
*/
static CatalogTable createBatchTable() {
final ResolvedSchema resolvedSchema = createSchema();
final CatalogTable origin = CatalogTable.of(Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(), TEST_COMMENT, Collections.emptyList(),
getBatchTableProperties());
return new ResolvedCatalogTable(origin, resolvedSchema);
}
/**
* 设置批处理表的属性
*
* @return
*/
static Map<String, String> getBatchTableProperties() {
return new HashMap<String, String>() {
{
put("is_streaming", "false");
putAll(new HashMap<String, String>() {
{
put(FactoryUtil.CONNECTOR.key(), "hive");
}
});
}
};
}
/**
* 创建流式表的属性
*
* @return
*/
static Map<String, String> getStreamingTableProperties() {
return new HashMap<String, String>() {
{
put("is_streaming", "true");
putAll(new HashMap<String, String>() {
{
put(FactoryUtil.CONNECTOR.key(), "hive");
}
});
}
};
}
static ResolvedSchema createSchema() {
return new ResolvedSchema(Arrays.asList(Column.physical("id", DataTypes.INT()), Column.physical("name", DataTypes.STRING()), Column.physical("age", DataTypes.INT())),
Collections.emptyList(), null);
}
}
3、运行结果
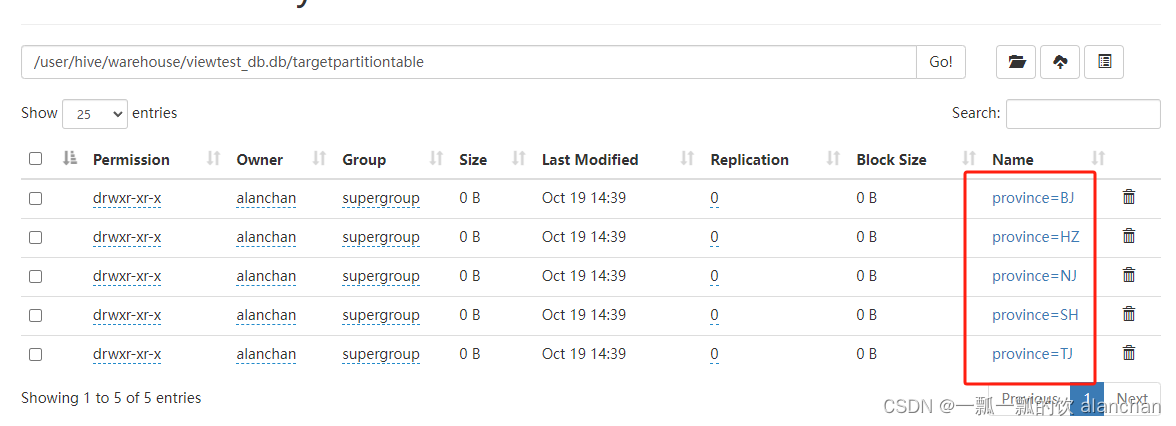
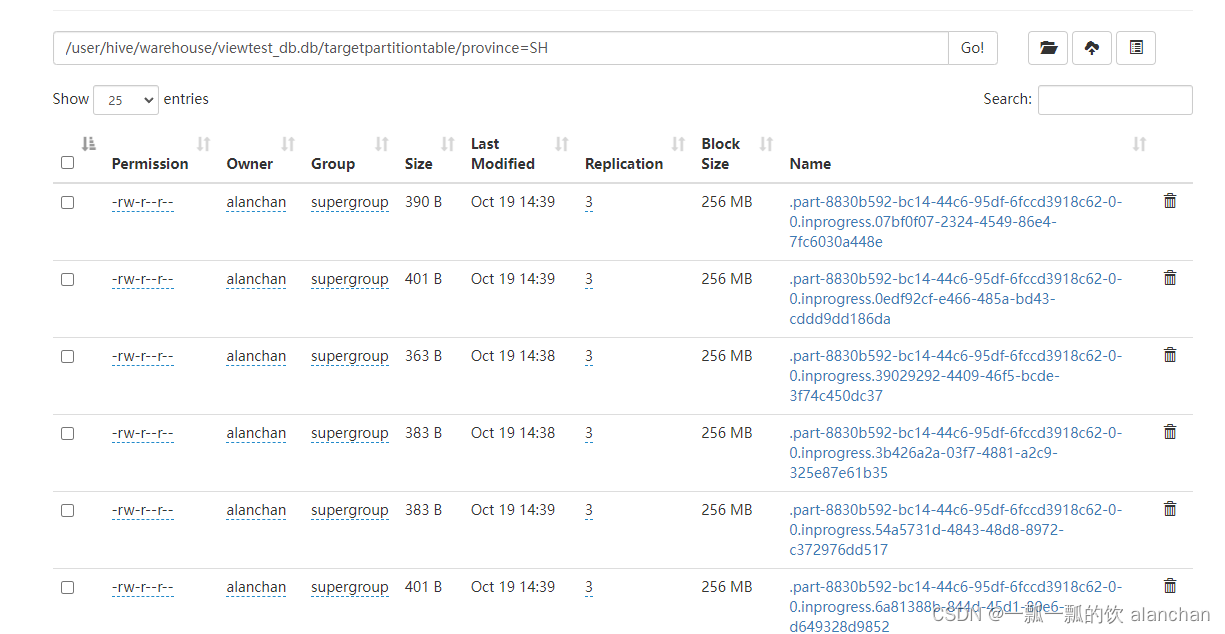
hdfs上创建的t1表结构如下:



6)、SQL创建hive表-带hive属性的表(分隔符、分区以及ORC存储)
本示例是通过SQL创建的分区ORC存储的表,然后通过源数据插入至目标分区表中。
关于hive的分区表使用,请参考:3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
具体打包的时候运行主类则需要视自己的运行情况决定是否修改。
2、代码
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;
/**
* @author alanchan
*
*/
public class TestCreateHiveTableBySQLDemo2 {
static String databaseName = "viewtest_db";
public static final String sourceTableName = "sourceTable";
public static final String targetPartitionTableName = "targetPartitionTable";
public static final String hive_create_source_table_sql =
"create table "+sourceTableName +"(id int ,name string, age int,province string) \r\n" +
"row format delimited fields terminated by ','\r\n" +
"STORED AS ORC ";
public static final String hive_create_target_partition_table_sql =
"create table "+targetPartitionTableName+" (id int ,name string, age int) \r\n" +
"partitioned by (province string)\r\n" +
"row format delimited fields terminated by ','\r\n" +
"STORED AS ORC "+
"TBLPROPERTIES (\n" +
" 'sink.partition-commit.delay'='5 s',\n" +
" 'sink.partition-commit.trigger'='partition-time',\n" +
" 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")";
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1、创建数据库
HiveCatalog hiveCatalog = init(tenv);
// 2、创建表
tenv.getConfig().setSqlDialect(SqlDialect.HIVE);
tenv.executeSql(hive_create_source_table_sql);
tenv.executeSql(hive_create_target_partition_table_sql);
// 3、插入sourceTableName数据
List<String> insertSQL = Arrays.asList(
"insert into "+sourceTableName+" values(1,'alan',18,'SH')",
"insert into "+sourceTableName+" values(2,'alanchan',18,'SH')",
"insert into "+sourceTableName+" values(3,'alanchanchn',18,'SH')",
"insert into "+sourceTableName+" values(4,'alan_chan',18,'BJ')",
"insert into "+sourceTableName+" values(5,'alan_chan_chn',18,'BJ')",
"insert into "+sourceTableName+" values(6,'alan',18,'TJ')",
"insert into "+sourceTableName+" values(7,'alan',18,'NJ')",
"insert into "+sourceTableName+" values(8,'alan',18,'HZ')"
);
for(String sql :insertSQL) {
tenv.executeSql(sql);
}
// 4、查询sourceTableName数据
List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + sourceTableName).collect());
for (Row row : results) {
System.out.println(sourceTableName + ": " + row.toString());
}
// 5、执行动态插入数据命令
System.out.println("dynamic.partition:["+ hiveCatalog.getHiveConf().get("hive.exec.dynamic.partition")+"]");
System.out.println("dynamic.partition.mode:["+hiveCatalog.getHiveConf().get("hive.exec.dynamic.partition.mode")+"]");
hiveCatalog.getHiveConf().setBoolean("hive.exec.dynamic.partition", true);
hiveCatalog.getHiveConf().set("hive.exec.dynamic.partition.mode", "nonstrict");
System.out.println("dynamic.partition:["+ hiveCatalog.getHiveConf().get("hive.exec.dynamic.partition")+"]");
System.out.println("dynamic.partition.mode:["+hiveCatalog.getHiveConf().get("hive.exec.dynamic.partition.mode")+"]");
//6、插入分区表数据
String insertpartitionsql =
"insert into table "+targetPartitionTableName+" partition(province)\r\n" +
"select id,name,age,province from "+ sourceTableName;
tenv.executeSql(insertpartitionsql);
//7、查询分区表数据
List<Row> partitionResults = CollectionUtil.iteratorToList(tenv.executeSql(
"select * from " + targetPartitionTableName).collect());
for (Row row : partitionResults) {
System.out.println(targetPartitionTableName + " : " + row.toString());
}
List<Row> partitionResults_SH = CollectionUtil.iteratorToList(tenv.executeSql(
"select * from " + targetPartitionTableName+" where province = 'SH'").collect());
for (Row row : partitionResults_SH) {
System.out.println(targetPartitionTableName + " SH: " + row.toString());
}
// 8、删除数据库
// tenv.executeSql("drop database " + databaseName + " cascade");
}
private static HiveCatalog init(StreamTableEnvironment tenv) throws Exception {
String moduleName = "myhive";
String hiveVersion = "3.1.2";
tenv.loadModule(moduleName, new HiveModule(hiveVersion));
String name = "alan_hive";
String defaultDatabase = "default";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tenv.registerCatalog(name, hiveCatalog);
tenv.useCatalog(name);
tenv.listDatabases();
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
tenv.useDatabase(databaseName);
return hiveCatalog;
}
}
3、运行结果
- flink 任务运行结果
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.10-SNAPSHOT.jar
Hive Session ID = ba971dc3-7fa5-4f2c-a872-9200a0396337
Hive Session ID = a3c01c23-9828-4473-96ad-c9dc40b417c0
Hive Session ID = 547668a9-d603-4c1d-ae29-29c4cccd54f0
Job has been submitted with JobID 881de04ddea94f2c7a9f5fb051e1d4af
Hive Session ID = 676c6dfe-11ae-411e-9be7-ddef386fb2ac
Job has been submitted with JobID 0d76f2446d8cdcfd296d82965f9f759b
Hive Session ID = b18c5e00-7da9-4a43-bf50-d6bcb57d45a3
Job has been submitted with JobID 644f094a3c9fadeb0d81b9bcf339a1e7
Hive Session ID = 76f06744-ec5b-444c-a2d3-e22dfb17d83c
Job has been submitted with JobID 1e8d36f0b0961f81a63de4e9f2ce21af
Hive Session ID = 97f14128-1032-437e-b59f-f89a1e331e34
Job has been submitted with JobID 3bbd81cf693279fd8ebe8a889bdb08e3
Hive Session ID = 1456c502-8c30-44c5-94d1-6b2e4bf71bc3
Job has been submitted with JobID 377101faffcc12d3d4638826e004ddc5
Hive Session ID = ef4f659d-735b-44ca-90c0-4e19ba000e37
Job has been submitted with JobID 33d50d9501a83f28068e52f77d0b0f6d
Hive Session ID = fccefaea-5340-422d-b9ed-dd904857346e
Job has been submitted with JobID 4a53753c008f16573ab7c84e8964bc48
Hive Session ID = 5c066f43-57e8-4aba-9c7b-b75caf4f9fe7
2023-10-19 05:49:12,774 INFO org.apache.hadoop.conf.Configuration.deprecation [] - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
Job has been submitted with JobID b44dd095b7460470c23f8e28243fc895
sourceTable: +I[1, alan, 18, SH]
sourceTable: +I[6, alan, 18, TJ]
sourceTable: +I[4, alan_chan, 18, BJ]
sourceTable: +I[2, alanchan, 18, SH]
sourceTable: +I[3, alanchanchn, 18, SH]
sourceTable: +I[5, alan_chan_chn, 18, BJ]
sourceTable: +I[7, alan, 18, NJ]
sourceTable: +I[8, alan, 18, HZ]
dynamic.partition:[true]
dynamic.partition.mode:[nonstrict]
dynamic.partition:[true]
dynamic.partition.mode:[nonstrict]
Hive Session ID = e63fd003-5d5f-458c-a9bf-e7cbfe51fbf8
Job has been submitted with JobID 59e2558aaf8daced29b7943e12a41164
Hive Session ID = 3111db81-a822-4731-a342-ab32cdc48d86
Job has been submitted with JobID 949435047e324bce96a5aa9e5b6f448d
targetPartitionTable : +I[2, alanchan, 18, SH]
targetPartitionTable : +I[7, alan, 18, NJ]
targetPartitionTable : +I[1, alan, 18, SH]
targetPartitionTable : +I[3, alanchanchn, 18, SH]
targetPartitionTable : +I[5, alan_chan_chn, 18, BJ]
targetPartitionTable : +I[4, alan_chan, 18, BJ]
targetPartitionTable : +I[8, alan, 18, HZ]
targetPartitionTable : +I[6, alan, 18, TJ]
Hive Session ID = 0bfbd60b-da1d-4a44-be23-0bde71e1ad59
Job has been submitted with JobID 49b728c8dc7fdc8037ab72bd6f3c5339
targetPartitionTable SH: +I[1, alan, 18, SH]
targetPartitionTable SH: +I[3, alanchanchn, 18, SH]
targetPartitionTable SH: +I[2, alanchan, 18, SH]
Hive Session ID = 68716de6-fceb-486e-91a8-8e4cf734ecfa
- hdfs数据存储情况
以上,介绍了java api/sql操作分区、函数和表,特别是针对表操作使用了6个示例进行说明。