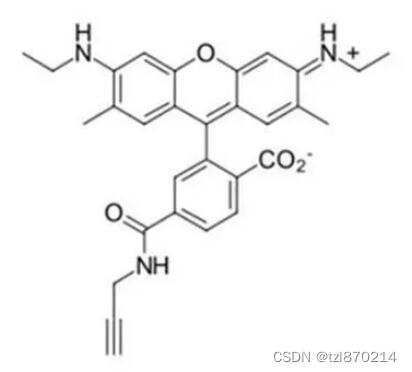
本文记录在进行变化检测数据集制作过程中所使用的代码
首先需要准备相同地区不同时间的两幅影像,裁减成合适大小,如256*256。相同区域命名相同放在两个文件夹下。


接着使用labelme对变化区域进行标注,这里不再进行labelme安装及标注的赘述。
在标注完成后,会在A、B两个文件夹下生成对应的json文件,A文件夹的json文件为对影像A的标注,B同上。
代码块包含四个部分:
1.json to png
2.同名png合并(处理AB都发生变化的标签)
3.独有png提取(处理只在A或B发生变化的标签)
4.png对应jpg提取(根据生成的标签检索AB)
1、将A的json文件放在Ajson文件夹,B同上,进行json转png
# json转png 开发时间:2023/5/13 21:19
#------------------------------------------------------#
# 文件夹A\B所有影像
# 文件夹Ajson\Bjson所有json文件
#------------------------------------------------------#
import json
import os
import numpy as np
import cv2
def json_to_png(json_file_path, png_file_path):
with open(json_file_path, 'r') as f:
data = json.load(f)
# 将json文件中的标注信息读取出来
shapes = data['shapes']
label_names = [shape['label'] for shape in shapes]
# 获取每个标签对应的颜色值
distinct_label_names = list(set(label_names))
# 标签对应色彩字典
label_name_to_color = {'1': (255, 255, 255)}
# 创建空白的图片,并将每个像素点的值初始化为0
img_height = data['imageHeight']
img_width = data['imageWidth']
img = np.zeros((img_height, img_width), dtype=np.uint8)
# 为每个标注区域填充对应的颜色
for shape in shapes:
label_name = shape['label']
color = label_name_to_color[label_name]
points = shape['points']
pts = np.array(points, np.int32)
cv2.fillPoly(img, [pts], color=color)
# 将生成的png图片保存到文件
cv2.imwrite(png_file_path, img)
if __name__ == '__main__':
json_file_path = 'Ajson'
json_fileList = os.listdir(json_file_path)
for json_file in json_fileList:
a = json_file
file_path_name = json_file_path + '/' + json_file
# 截取文件名,用来命名图片
name = os.path.splitext(file_path_name)[0]
index = name + '.png'
json_to_png(file_path_name, index)
print(file_path_name, 'to', index)
json_file_path_b = 'Bjson'
json_fileList = os.listdir(json_file_path_b)
for json_file in json_fileList:
a = json_file
file_path_name = json_file_path_b + '/' + json_file
# 截取文件名,用来命名图片
name = os.path.splitext(file_path_name)[0]
index = name + '.png'
json_to_png(file_path_name, index)
print(file_path_name, 'to', index)2、按名称将A、B相同标签png的变化部分进行合并,使一对A、B的变化标签成为一张png
# 合并两个文件夹下相同名称的两张png标签
#
# 开发时间:2023/5/18 16:38
import os
from PIL import Image
def merge(path1, path2, path3):
img1 = Image.open(path1)
img2 = Image.open(path2)
width, height = img1.size
new_img = Image.new('L', (width, height), 0)
for x in range(width):
for y in range(height):
pixel1 = img1.getpixel((x, y))
pixel2 = img2.getpixel((x, y))
if pixel1 == 255 or pixel2 == 255:
new_img.putpixel((x, y), 255)
else:
new_img.putpixel((x, y), 0)
file_name = os.path.split(path1)[1]
path_new = os.path.join(path3, file_name)
# 保存新的图片
new_img.save(path_new)
# 提取需要合并的同名文件
A_file_path = 'Ajson'
A_fileList = os.listdir(A_file_path)
B_file_path = 'Bjson'
B_fileList = os.listdir(B_file_path)
result = 'result'
Alist = []
for file_a in A_fileList:
Alist.append(file_a)
Blist = []
for file_b in B_fileList:
Blist.append(file_b)
common_set = set(Alist).intersection(set(Blist))
common_list = list(common_set)
if len(common_list) == 0:
print("这两个列表没有相同的元素")
else:
print("这两个列表有相同的元素:")
print(len(common_list))
for item in common_list:
print(item)
print(len(common_list))
for item in common_list:
path_a = os.path.join(A_file_path, item)
path_b = os.path.join(B_file_path, item)
path_result = result
if not os.path.exists(path_result):
os.makedirs(path_result)
merge(path_a, path_b, path_result)
print('merge successfully!!!')3、检测AB文件夹下的文件的交集并集情况,把AB中独有的图片放进result
# 检测AB文件夹下的文件的交集并集情况,把AB中独有的图片放进result
#
# 开发时间:2023/5/19 10:09
import os
import shutil
folder1 = "Ajson"
folder2 = "Bjson"
result = 'result'
if not os.path.exists(result):
os.makedirs(result)
files1 = set(os.listdir(folder1))
files2 = set(os.listdir(folder2))
common_files = files1.intersection(files2)
# 获取不同的文件名
# different_files = files1.difference(files2).union(files2.difference(files1))
# A中独有的标签
different_filesA = files1.difference(files2)
# B中独有的标签
different_filesB = files2.difference(files1)
# 将AB独有的标签放进result
for a in different_filesA:
pngA = os.path.join(folder1, a)
pngA_new = os.path.join(result, a)
shutil.copy(pngA, pngA_new)
for b in different_filesB:
pngB = os.path.join(folder2, b)
pngB_new = os.path.join(result, b)
shutil.copy(pngB, pngB_new)
# 输出结果
print("相同的文件名:", common_files)
print("相同的文件数量:", len(common_files))
print("A独有的文件名:", different_filesA)
print("A独有的文件数量:", len(different_filesA))
print("B独有的文件名:", different_filesB)
print("B独有的文件数量:", len(different_filesB))
print('detection successfully!!!')4、按照标签统计结果检索AB中对应的变化标签(此步骤如不需要可以不进行)
# 提取出result中的png对应于AB文件夹的jpg文件
#
# 开发时间:2023/5/25 8:27
import os
import shutil
folder1 = "A_rea"
folder2 = "B_rea"
result = 'result'
# 原始ab文件夹
allA = 'A'
allB = 'B'
if not os.path.exists(folder1):
os.makedirs(folder1)
if not os.path.exists(folder2):
os.makedirs(folder2)
# 获取result文件夹中的所有文件名
files_result = set(os.listdir(result))
# 修改后缀
name = []
for item in files_result:
name.append(item.split('.')[0])
for i in name:
imgName = i + '.jpg'
pathA = os.path.join(folder1, imgName)
pathB = os.path.join(folder2, imgName)
oldA = os.path.join(allA, imgName)
oldB = os.path.join(allB, imgName)
shutil.copy(oldA, pathA)
shutil.copy(oldB, pathB)
# 输出结果
print("正在处理:", oldA)
print("文件数量:", len(name))
print('Same_A_B successfully!!!')

![2023年中国粘度指数改进剂行业需求现状及前景分析[图]](https://img-blog.csdnimg.cn/img_convert/793e6aed00a3b74dd57974b0e85a5ece.png)