题目链接
找出字符串中第一个匹配项的下标
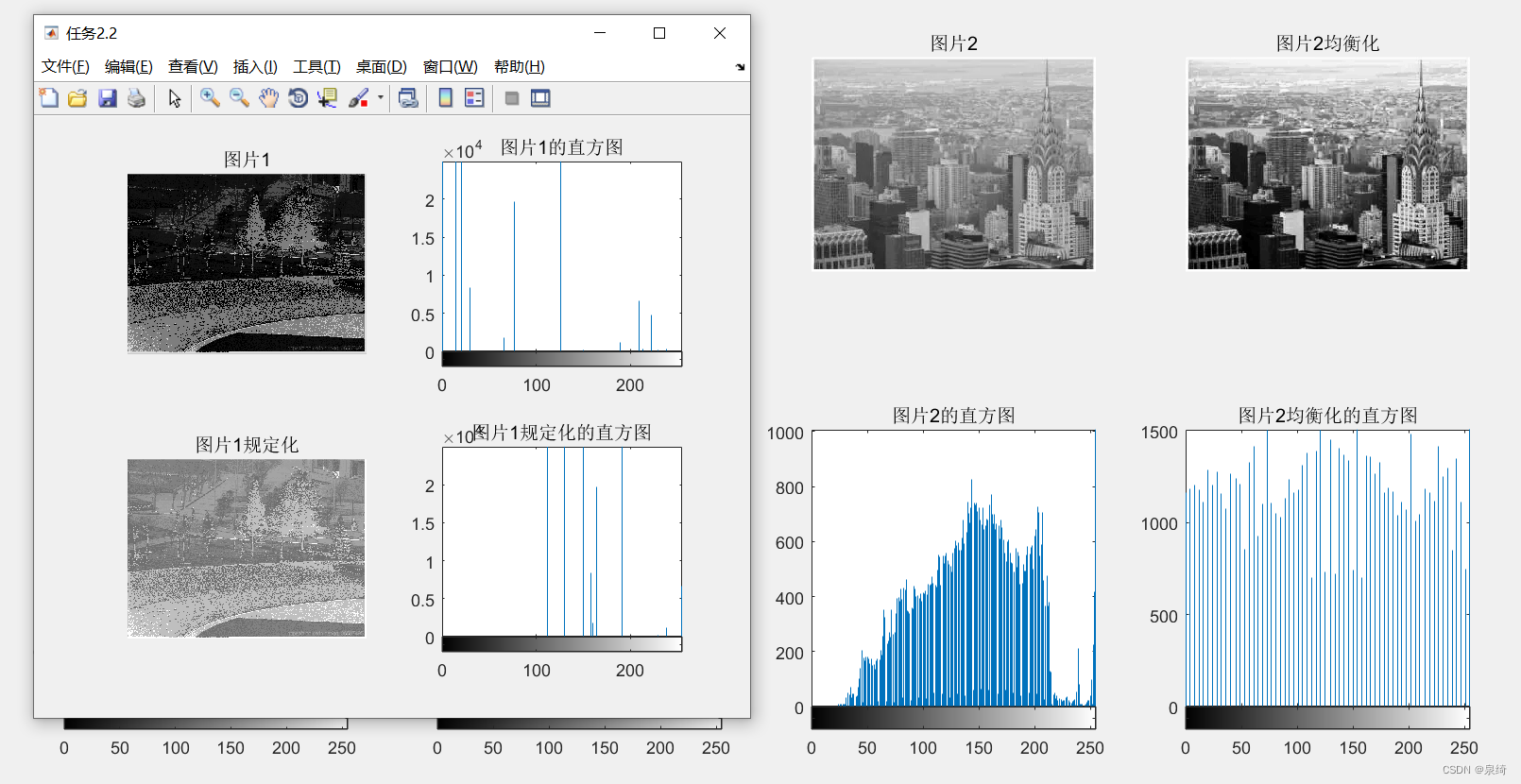
题目描述
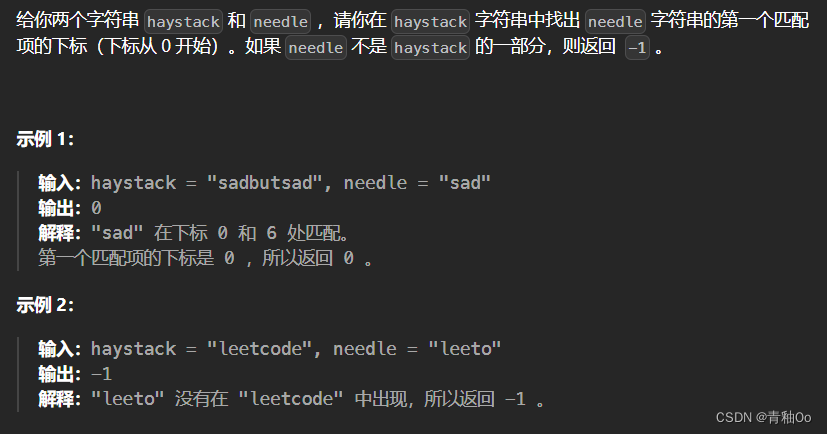
注意点
- haystack 和 needle 仅由小写英文字符组成
解答思路
- 使用KMP算法,相比于普通地将整个字符串分成多块大小为needle.length()的子串找到第一个与needle匹配的子串,其可以在判断出任意一个子串不是匹配项时,无需从haystack下一位和needle第一位开始判断,而是根据needle中相同的前缀,直接排除一定不是匹配项的下标,转而从有可能匹配的位置开始判断,其时间复杂度相比于O(mn)缩短到了O(m + n)
- KMP算法第一个关键点在于找到needle中相同的前缀,其思路为:建立两个指针i = 1,j = 0,遍历needle,如果i和j处的字符相同,则next[i] = j,且将i和j都向右移动一位;如果i和j处的字符不同,则将j移动至next[j - 1]处,直到i和j处的字符相同或j = 0为止,示例如abeabeabg对应的next数组为000123450
- KMP算法第二个关键点在于根据next优化查询匹配项的步骤,其思路为:建立两个指针i = 0,k = 0,遍历haystack,如果i和k处的字符相同,则将i和k都向右移动一位;如果i和j处的字符不同,则将k移动至next[k - 1]处,直到i和k处的字符相同或k = 0为止,其保证排除掉一定不是匹配项的下标。示例如在abeabeabeabeabg找到abeabeabg,其会在i = 8,k = 8时判断出当前子串不匹配,随后将指针k移动至5,从指针i = 9,k = 6再一次开启匹配项的判断
代码
class Solution {
public int strStr(String haystack, String needle) {
// abeabeabeabeabg
// abeabeabg
// 000123450
int m = haystack.length();
int n = needle.length();
if (n > m) {
return -1;
}
// 找到needle中相同的前缀
int[] next = new int[n];
int j = 0;
for (int i = 1; i < n; i++) {
// needle[i] != needle[j],则j = next[j - 1],直到j = 0或needle[i] = needle[j]为止
while(j > 0 && needle.charAt(i) != needle.charAt(j)) {
j = next[j - 1];
}
// needle[i] = needle[j],next[i] = j + 1,i++,j++
if (needle.charAt(i) == needle.charAt(j)) {
j++;
next[i] = j;
} else {
next[i] = 0;
}
}
int k = 0;
for (int i = 0; i < m; i++) {
while (k > 0 && haystack.charAt(i) != needle.charAt(k)) {
k = next[k - 1];
}
if (haystack.charAt(i) == needle.charAt(k)) {
k++;
}
if (k == n) {
return i - k + 1;
}
}
return -1;
}
}
关键点
- KMP算法的思想
- 注意边界问题