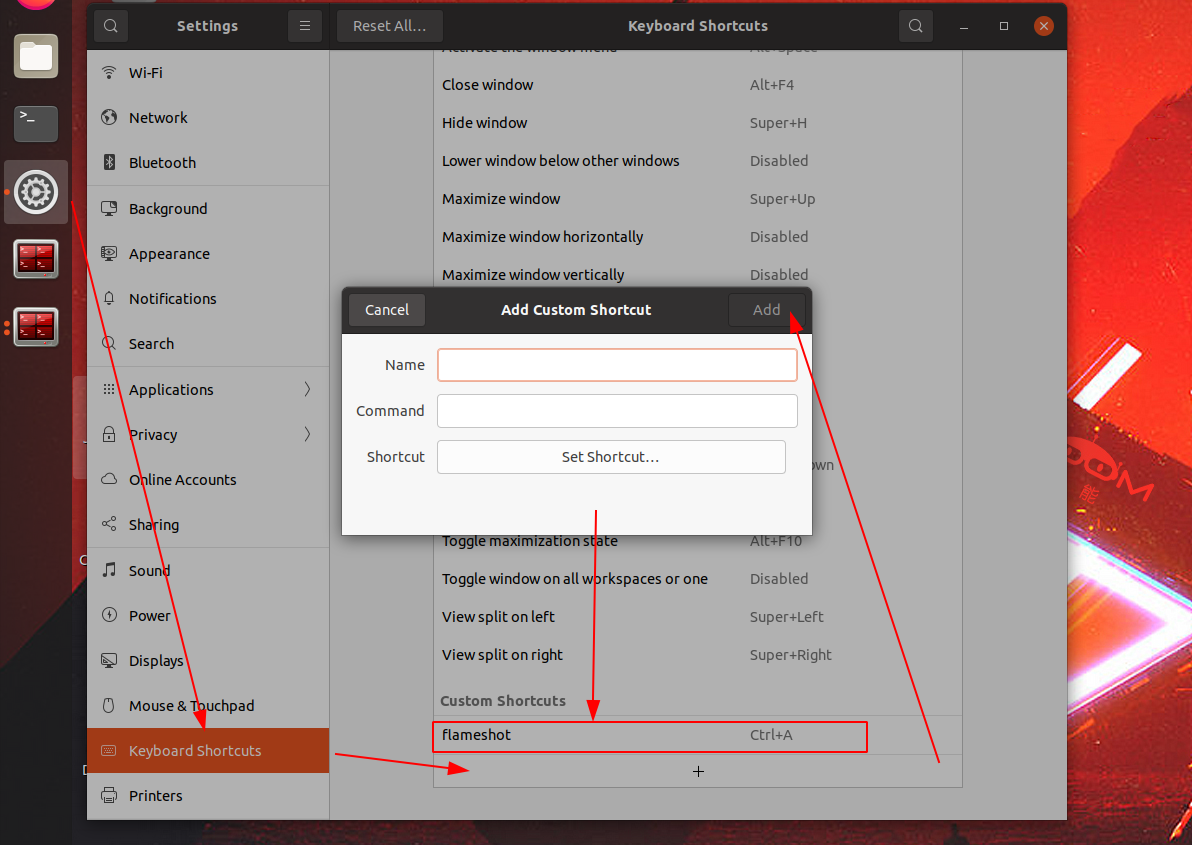
计算机视觉概述
a study of visual data
visual data has exploded to a ridiculous degree
手机上两三个摄像头,more camera than people,视觉传感器,摄像头终端,产生很多视觉数据
visual data构成互联网上传输的的大部分数据
80%的流量都是视频,visual date
理解和利用这些来赚钱
每经过1s世界上有5hours视频上传到YouTube
如果object recognition is too hard,先做object segmentation
计算机视觉历史背景
生物视觉的出现
start to gain momentum 开始加速发展
face detection
基础科学到实际应用
相机角度,光线,遮挡,视角,目标自身的变化
identify critical features which tends to remain diagnostic and invariant
具有表现型和不变性 的重要特征
recognize holistic scenes全面的场景
ImageNet发展介绍,带标签的图像数据集
1、我们是否具备识别真实世界中每一个物体的能力
2、大部分机器学习算法
graphical model,support vector machine 支持向量机
AdaBoost
可视化数据很复杂
模型维数往往较高,一堆参数要调优,当训练数据量不够,容易出现overfit
3、以来识别尽可能多的物体
克服机器学习的瓶颈,过拟合问题
由此诞生imageNet
some clever crowd engineering trick to sort ,clean,label each of images
imageNet,15millon~40million
目标检测算法的发展推到一个新的高度
push forward the algorithm development of object recognition into another phrase
imageNet classification error rate 降低到和肉眼识别一样低
使得错误率显著下降的获奖算法是一种 convolutional neural network model
这门课需要 了解 深度学习这个领域look at what these models,principles,good practice 模型的原理
convolutional neutral model or deep learning model模型容量和能力在计算机其他领域 NLP,speech recognition 也运用得很好
课程概述
object detection,image captioning图片摘要,根据图片生成一段句子
the setup in object detection is a little bit different rather than classfying an entire images
用在图像分类中的工具可以在 caption等等中用到
since then,there has been a lot of effort focused in tuning and tweaking微调 these algorithms
Convolutional neutral networks 90年代已经出现
98年就有与CNN类似结构的算法用于识别支票上的数字呀邮编呀,但是CV到2012年后才大量爆发应用。
计算机的计算速度,data数量
一来是由于现在计算能力大大提升,GPU等并行运算可以为CNN提供很好的算力
二来是现在的训练数据量很大,可以很好的减少函数的bias,按老师的说法,要很好的分辨世界万物,模型就会很复杂,模型很复杂就会参数很多,参数很多,training data很少就很容易过拟合,很难一般化。
this is by no means a standard approach at this point
from their external knowledge储备知识
despite the massive progress in the field that we’ve had over the past several years
计算机视觉的运用还有待发掘,攫取更深层次的图片蕴含信息
给出了CV研究的一些待解决问题或者能解决的问题,tackle more ambiguous problems ,例如图像分析+语义描述,activity recognition 行为识别
图像分类
numpy 短短几行代码做相当多的运算,超级重要 向量化操作(待学)
800×600pixels
每个像素由三个数字表示(RGB)
巨大数列giant array
难以从中提取喵咪的特性,称作semantic gap
challenge:viewpoint variation 视角不同,像素组合网格不同但仍然是一只猫
光线
物体的姿势和位置
algorithm must be robust to that occlusion
background clutter背景混乱
背景像猫的纹理
intraclass variation
类内种类差别, 不同
方略一
根据猫猫的轮廓特征等等制定一系列explicit set of rules
困难,当识别对象改变时需要重新制定规则
so the insight that, sort of, makes this all work is this idea of the data-driven approach
基于此!!!
方略二:数据驱动方法
不写具体的分类规则,抓取数据大量猫的图片数据集
有了数据集,训练机器来分类
Machine Learning: Data-Driven Approach
1、Collect a dataset of images and labels
2、Use Machine Learning to train a classifier
3、Evaluate the classifier on new images
函数API发生改变,
训练函数:接受图片和标签,输出模型
预测函数,接收模型 和要识别的图片

数据驱动类的算法
to be a little more concrete,具体来说
一个叫做CIFAR-10的数据集,常用的测试数据集
图像分类数据集:CIFAR-10。 一个非常流行的图像分类数据集是CIFAR-10。这个数据集包含了60000张32X32的小图像。每张图像都有10种分类标签中的一种。这60000张图像被分为包含 50000张图像的训练集和包含10000张图像的测试集 。在下图中你可以看见10个类的10张随机图片。
最邻近算法 the nearest neighbor algorithm
假设现在我们有CIFAR-10的50000张图片(每种分类5000张)作为训练集,我们希望将余下的10000作为测试集并给他们打上标签。Nearest Neighbor算法将会拿着测试图片和训练集中每一张图片去比较,然后 将它认为最相似的一个训练集图片的标签赋给这张测试图片。
如何比对两幅图片?采用怎样的比较函数
L1-distance 也叫曼哈顿距离
dumb stupid
像素之间绝对值的总和
另一种常见的选择是L2,欧氏距离
L1和L2比较。比较这两个度量方式是挺有意思的。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。L1和L2都是在p-norm常用的特殊形式。
问题一
训练是连续的过程,只需要存储数据,无论数据集有多大,都将是一个恒定的时间
测试时,需要将test image和数据集中N个训练实例进行比对
期待的是训练过程缓慢是OK的(在数据中心进行,可以负担起非常大的运算量),测试过程需要快,CNN就满足这一
问题二

为什么孤岛是个显然的错误结果现象
图片?和一张a类别图片 最相似,其次和众多b类别的图片相似,显然图片?应该是b类别,而不是a
你可能注意到了,为什么只用最相似的1张图片的标签来作为测试图像的标签呢?这不是很奇怪吗!是的,使用k-Nearest Neighbor分类器就能做得更好。它的思想很简单:与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
通过图片直观了解

一个实例在特征空间中的K个最接近(即特征空间中最近邻)的实例中的大多数属于某一个类别,则该实例也属于这个类别。
所选择的邻居都是已经正确分类的实例,是先验信息。
该算法假定所有的实例对应于N维欧式空间中的点。通过计算一个点与其他所有点之间的距离,取出与该点最近的K个点,然后统计这K个点里面所属分类比例最大的,则这个点属于该分类。
KNN分类器之NearestNeighbors详解
nice holistic translation!
k最邻近算法
k==1,就是最邻近算法
寄能找出与测试图片最相似的10张图片,最邻近算法只看最相似的一张
k=1,看最相似的前2张

改变坐标轴,L1距离会发生改变,而L2距离不受影响