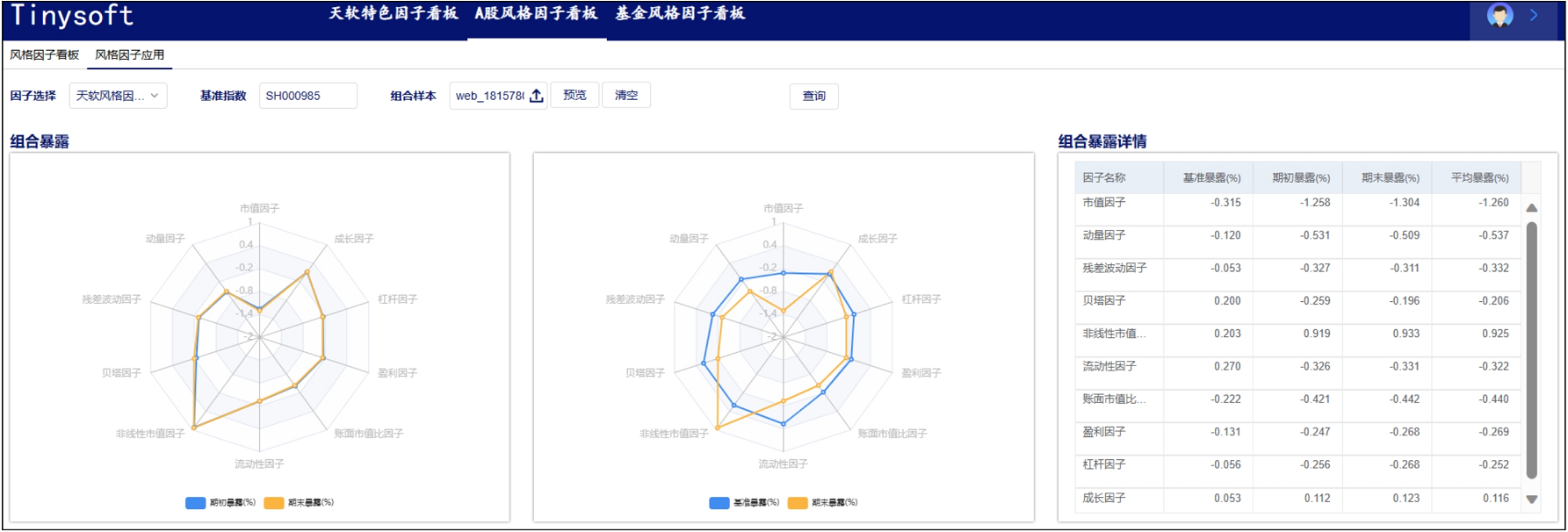
半监督学习,一般应用于少量带标签的数据(数量R)和大量未带标签数据的场景(数量U),一般来说,U>>R。
半监督学习一般可以分为2种情况,一种是transductive learning,这种情况下,将unlabeled data的feature利用进来。另外一种是inductive learning,这种情况下,在训练的整个过程中,完全不看任何unlabeled data的信息。
为什么要做semi-supervised learning呢,因为我们现实中大多数情况下,搜集数据比较容易,但是数据标注比较困难。包括我们的人生中,我们自己也是一直在做semi-supervised learning.

为什么semi-supervised learning会有用呢,因为unlabeled data可以告诉我们一些信息。通常,我们在做semi-supervised learning时,会做出一些假设,这个假设很关键,会影响最后的结果。
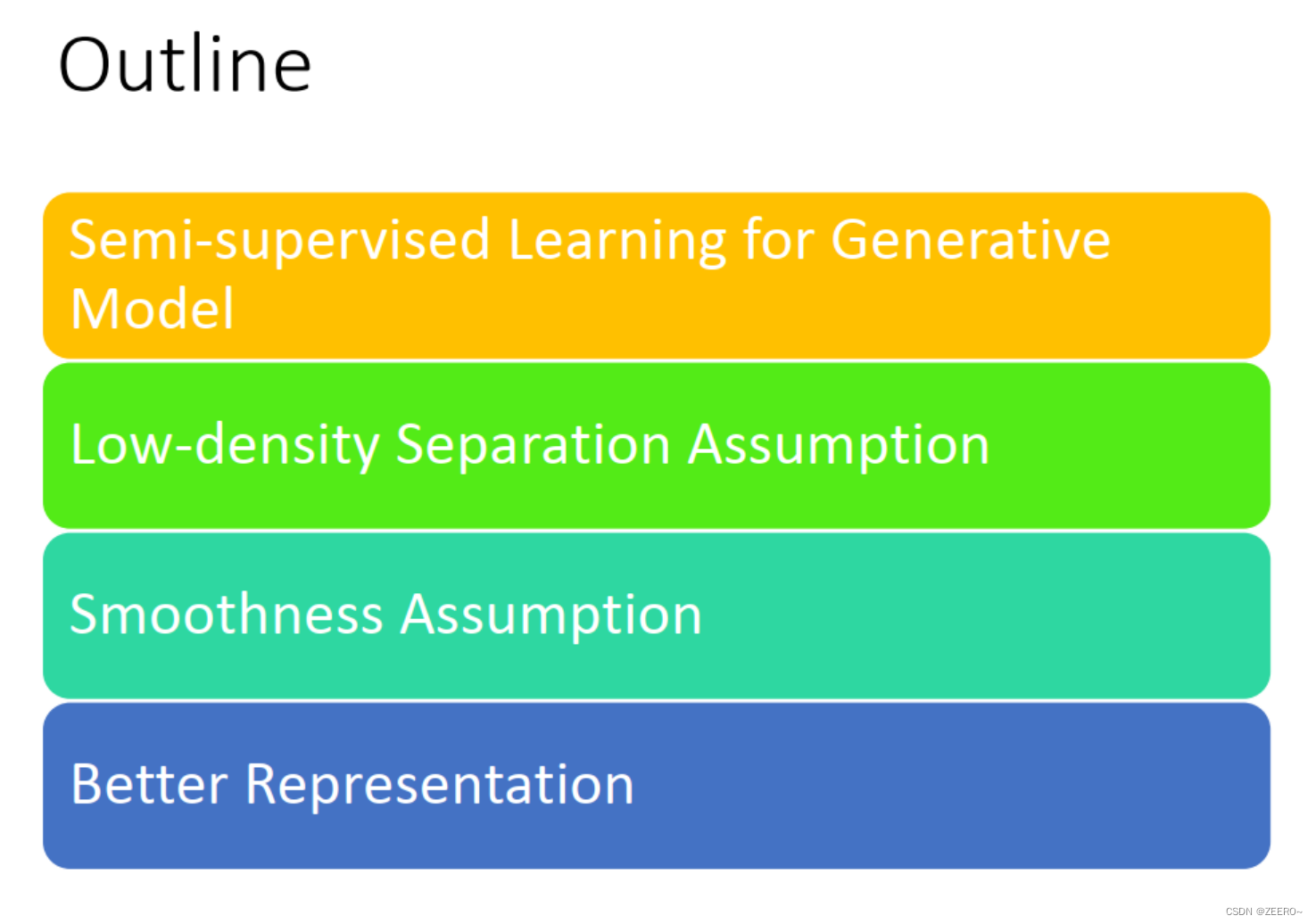
这节课的主要讲述4个部分,第一个是讲generative model时如何做semi-supervised learning。然后在讲述2个常用的通用假设,分别是low density separation假设和smoothness假设,最后,semi-supervised learning还有一个比较好用的一招是better representation。
1、Generative Model

假设说我们已知标签的数据,有两个类别C1和C2,假设他们是属于高斯分布。我们可以画出我们的决策边界,对于任何一个数据,可以求出这个数据x属于类别C1的概率,如上图所示。
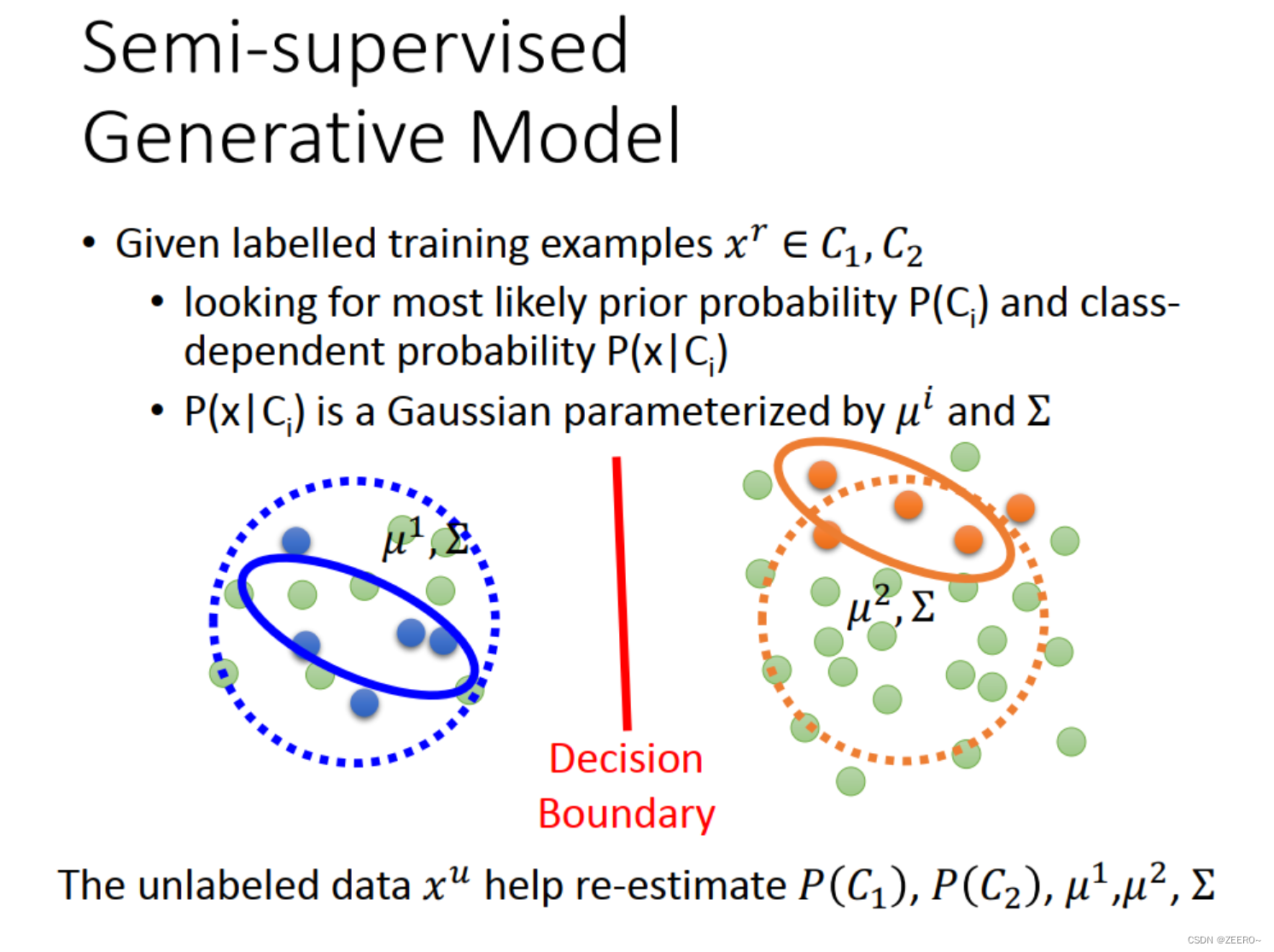
但是,这个时候如果再给了一个unlabeled data,那么我们上面的决策边界就会受到影响。这在直觉上是这样。

实际操作是怎么做的呢?
首先,先初始化一组参数
θ
\theta
θ。初始化可以随机设定参数,虽然说初始化的值也很重要。
第一步, 根据初始设定的参数,可以估计每个unlabeled data属于class 1的概率。
第二步,算出第一步的概率之后,便可以update 我们的model。
后续不断重复第一步和第二步。
如果我们知道EM算法的话,那么第一步就是E的过程,第二步就是M的过程。

这件事情直觉上可以理解为何这样做,我们实际上还是分析下原因,如上图所示。
2、Low density Separation Assumption

我们认为这个世界是一个非黑即白的世界。意思就是,在两个类别的交界处,密度是比较低的,data量是很少的,基本上不太会出现data。Low density最具代表性的方法就是self training。

self training的方法非常的直觉和通俗易懂,我们不做过多的讲述。
我们现在需要来考虑的一个问题时,self training的方法如果用来做回归regression,会怎么样呢?work吗?
我们可以花5s的时间思考一下。
答案其实是无效的。拿最简单的线性回归为例,不断self training出来的数据,再加入到model中进行训练,model不会发生变化,因此这招对于regression是无效的。
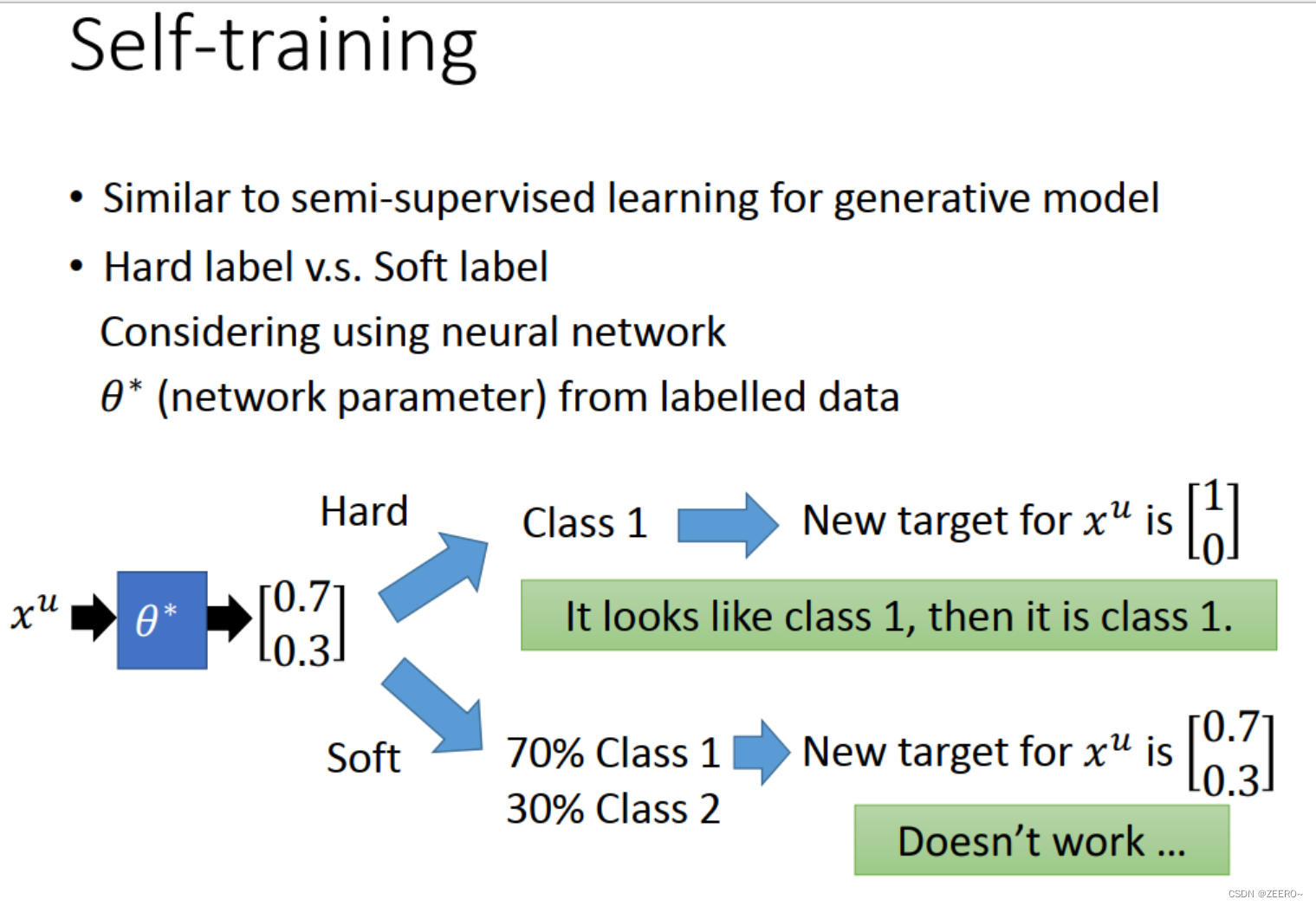
self training的过程和之前的generative model的过程还是非常相似的,但也有不同之处。主要的不同之处在于hard label和soft label的区别。以神经网络为例,我们可以想下hard label和soft label哪个有效?
实际上,如果以ANN为例,soft label是完全无效的。为什么呢?因为在现有的参数上这个unlabeled data都可以做到[0.7,0.3]的输出,如果此时标签还是[0.7,0.3],那么就完全不需要更新参数了,不需要更新model了。
Entropy-based Regularization

熵要越小越好。可以在损失函数时将unlabeled data的熵一起加入作为最小化项。
3、Smoothness Assumption