一、前言
迪拜是否过圣诞节日,迪拜信基督教的人过圣诞,其他一般不过。
圣诞节(Christmas)又称耶诞节、耶稣诞辰,译名为“基督弥撒”,是西方传统节日,起源于基督教,在每年公历12月25日。弥撒是教会的一种礼拜仪式。圣诞节是一个宗教节,因为把它当作耶稣的诞辰来庆祝,故名“耶诞节”。
大部分的天主教教堂都会先在12月24日的平安夜,亦即12月25日凌晨举行子夜弥撒,而一些基督教会则会举行报佳音,然后在12月25日庆祝圣诞节;基督教的另一大分支——东正教的圣诞节庆则在每年的1月7日。
圣诞节也是西方世界以及其他很多地区的公共假日,例如:在亚洲的中国香港和澳门地区、马来西亚、新加坡。古罗马教会在君士坦丁时代(公元年),就逐渐习惯在十二月二十五日庆祝主的诞生。

二、创意名
基于Flink的数据实时展示平台
三、效果展示
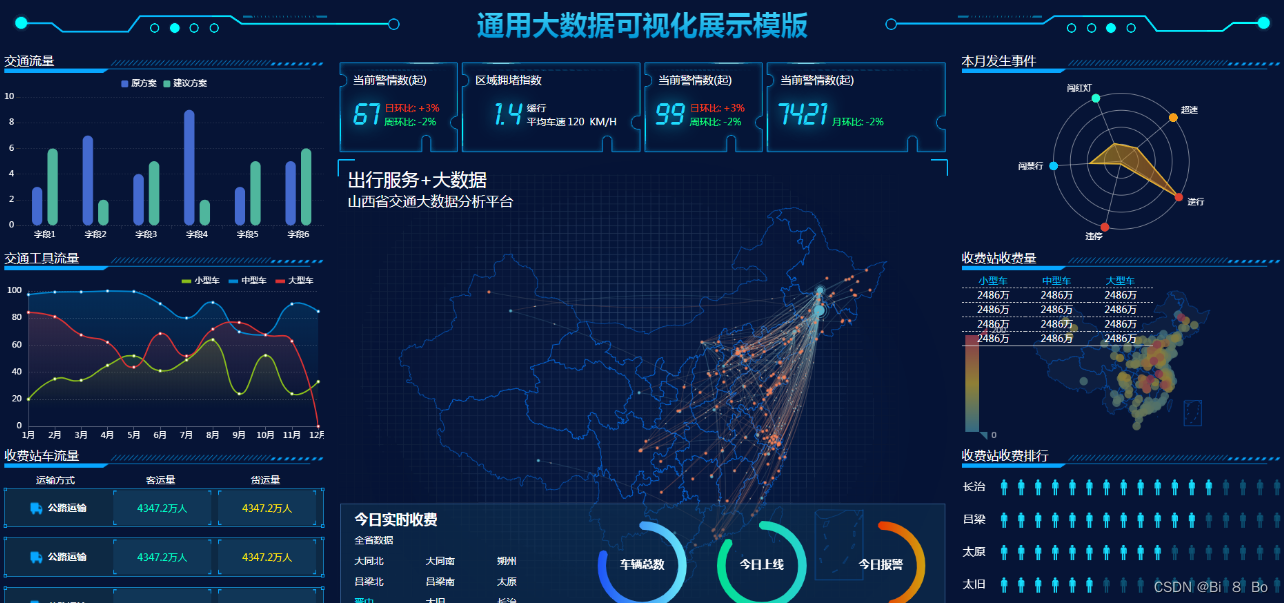
四、实现步骤
Spark的技术理念是使用微批来模拟流的计算,基于Micro-batch,数据流以时间为单位被切分为一个个批次,通过分布式数据集RDD进行批量处理,是一种伪实时。
而Flink是基于事件驱动的,它是一个面向流的处理框架,Flink基于每个事件一行一行地流式处理,是真正的流式计算.另外他也可以基于流来模拟批进行计算实现批处理,所以他在技术上具有更好的扩展性,未来可能会成为一个统一的大数据处理引擎。
因为他们技术理念的不同,也就导致了性能相关的指标的差别,spark是基于微批的,而且流水线优化做的很好,所以说他的吞入量是最大的,但是付出了延迟的代价,它的延迟是秒级;而Flink是基于事件的,消息逐条处理,而且他的容错机制很轻量级,所以他能在兼顾高吞吐量的同时又有很低的延迟,它的延迟能够达到毫秒级;
SparkStreaming只支持处理时间,折中地使用processingtime来近似地实现eventtime相关的业务。显然,使用processingtime模拟eventtime必然会产生一些误差,特别是在产生数据堆积的时候,误差则更明显,甚至导致计算结果不可用。
Structuredstreaming支持处理时间和事件时间,同时支持watermark机制处理滞后数据
Flink支持三种时间机制:事件时间,注入时间,处理时间,同时支持watermark机制处理迟到的数据,说明Flink在处理乱序大实时数据的时候,优势比较大。
其实和Kafka结合的区别还是跟他们的设计理念有关,SparkStreaming是基于微批处理的,所以他采用DirectDstream的方式根据计算出的每个partition要取数据的Offset范围,拉取一批数据形成Rdd进行批量处理,而且该Rdd和kafka的分区是一一对应的;
Flink是真正的流处理,他是基于事件触发机制进行处理,在KafkaConsumer拉取一批数据以后,Flink将其经过处理之后变成,逐个Record发送的事件触发式的流处理。另外,Flink支持动态发现新增topic或者新增partition,而SparkStreaming和0.8版本的kafka结合是不支持的,后来跟0.10版本的kafka结合的时候,支持了,看了源码;
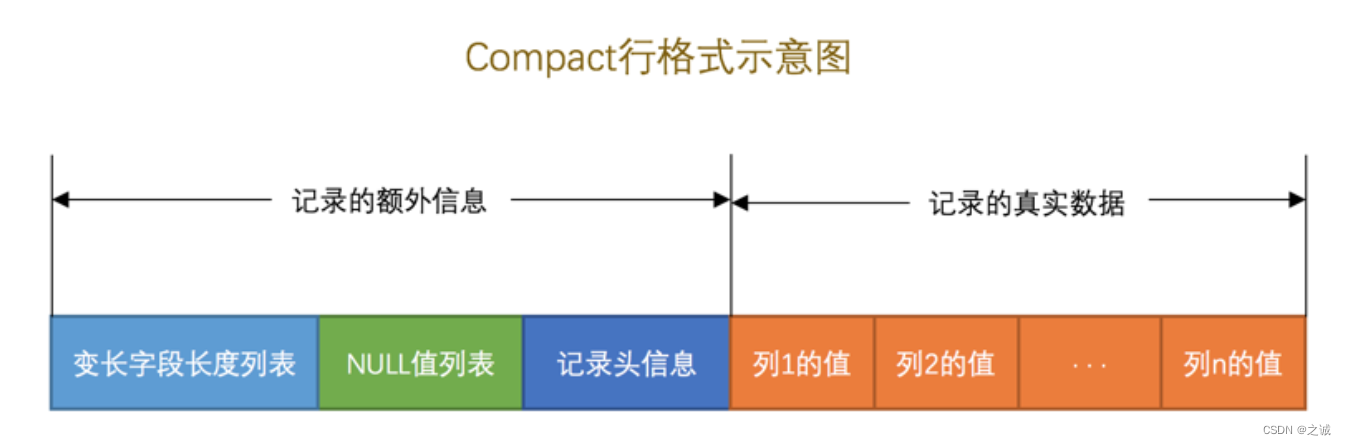
五、编码实现
server:
port: 8080
# port: ${server.port}
spring:
#数据源
datasource:
username: root
password: 123456
url: jdbc:mysql://192.168.1.100:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
# password: ${DB_PASSWORD:password}
# username: ${DB_USERNAME:username}
# url: jdbc:mysql://${DB_HOST:127.0.0.1}:${DB_PORT:3306}/${DB_DATABASE:dataxweb}?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
hikari:
## 最小空闲连接数量
minimum-idle: 5
## 空闲连接存活最大时间,默认600000(10分钟)
idle-timeout: 180000
## 连接池最大连接数,默认是10
maximum-pool-size: 10
## 数据库连接超时时间,默认30秒,即30000
connection-timeout: 30000
connection-test-query: SELECT 1
##此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
max-lifetime: 1800000
# datax-web email
mail:
host: smtp.qq.com
port: 25
username: gree2@qq.com
password: xxxxxxxx
# username: ${mail.username}
# password: ${mail.password}
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory
management:
health:
mail:
enabled: false
server:
servlet:
context-path: /actuator
mybatis-plus:
# mapper.xml文件扫描
mapper-locations: classpath*:/mybatis-mapper/*Mapper.xml
# 实体扫描,多个package用逗号或者分号分隔
#typeAliasesPackage: com.yibo.essyncclient.*.entity
global-config:
# 数据库相关配置
db-config:
# 主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID", ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
id-type: AUTO
# 字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
field-strategy: NOT_NULL
# 驼峰下划线转换
column-underline: true
# 逻辑删除
logic-delete-value: 0
logic-not-delete-value: 1
# 数据库类型
db-type: mysql
banner: false
# mybatis原生配置
configuration:
map-underscore-to-camel-case: true
cache-enabled: false
call-setters-on-nulls: true
jdbc-type-for-null: 'null'
type-handlers-package: com.wugui.datax.admin.core.handler
# 配置mybatis-plus打印sql日志
logging:
level:
com.wugui.datax.admin.mapper: info
path: ./data/applogs/admin
# level:
# com.wugui.datax.admin.mapper: error
# path: ${data.path}/applogs/admin
#datax-job, access token
datax:
job:
accessToken:
#i18n (default empty as chinese, "en" as english)
i18n:
## triggerpool max size
triggerpool:
fast:
max: 200
slow:
max: 100
### log retention days
logretentiondays: 30
datasource:
aes:
key: AD42F6697B035B75











![离线下载NLTK依赖包([WinError 10061] 由于目标计算机积极拒绝,无法连接)的解决方案](https://img-blog.csdnimg.cn/d97f17482c624511830c7b7ec79cea6b.png#pic_center)
