由于平日系统导出的文档均为.xls的execel,故本文主要讲如何使用xlrd进行读取表格以及操作过程遇到的报错以及对应解决版本
一、基本使用
准备“成绩表.xlsx”文件,如下:
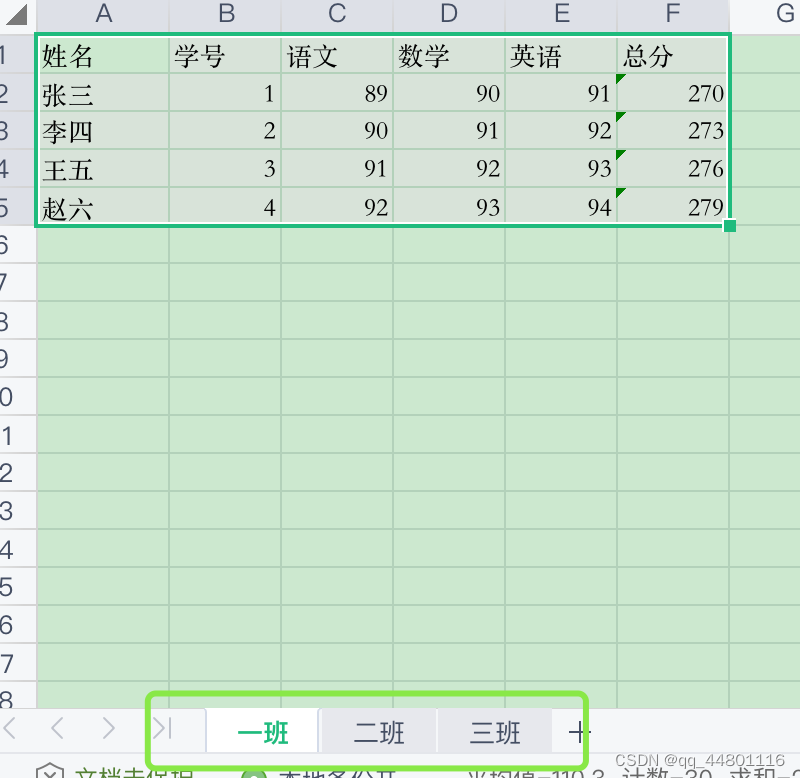
1、读取文件并获得文件的sheet名字
(1)代码
import xlrd
import os
def base_use(file_name):
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path, file_name)
# 打开文件
data = xlrd.open_workbook(base_path)
#基本信息1:获取表格sheet名字
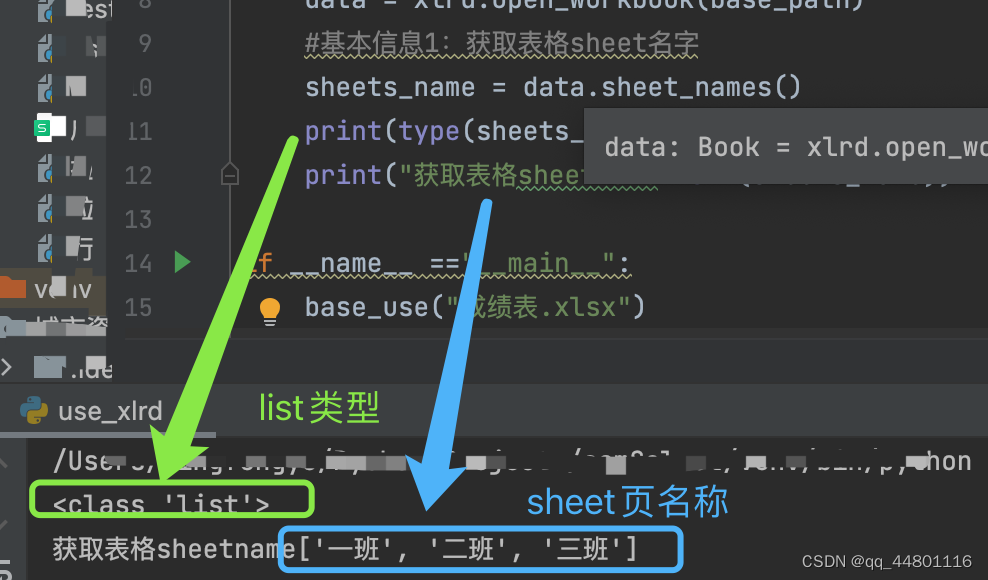
sheets_name = data.sheet_names()
print(type(sheets_name))
print("获取表格sheetname"+str(sheets_name))
if __name__ =="__main__":
base_use("成绩表.xlsx")
(2)解析,以及运行结果
通过上面程序,
**解析1:**os.path.dirname获取到python文件所在的绝对路径
使用join函数,将文件进行拼接,从而实现路径的灵活性
解析2:通过sheet_names()获取文件中的sheet页的名字,结果并以list类型存储,后续使用可按照list进行访问
2、读取文件并获取每一行数据
(1)通过sheets方式获取表个数,并通过row_values获取每行数据
遍历获取三个表格每行数据如下:
def get_row_values(filename):
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path,filename)
#打开文件
data = xlrd.open_workbook(base_path)
#获取sheet文档的方式一:sheets函数遍历
print(len(data.sheets()))
for i in range(len(data.sheets())):
print("___________________________")
table = data.sheets()[i]
print(table.nrows)
for j in range(table.nrows):
print(table.row_values(j))
代码结果:
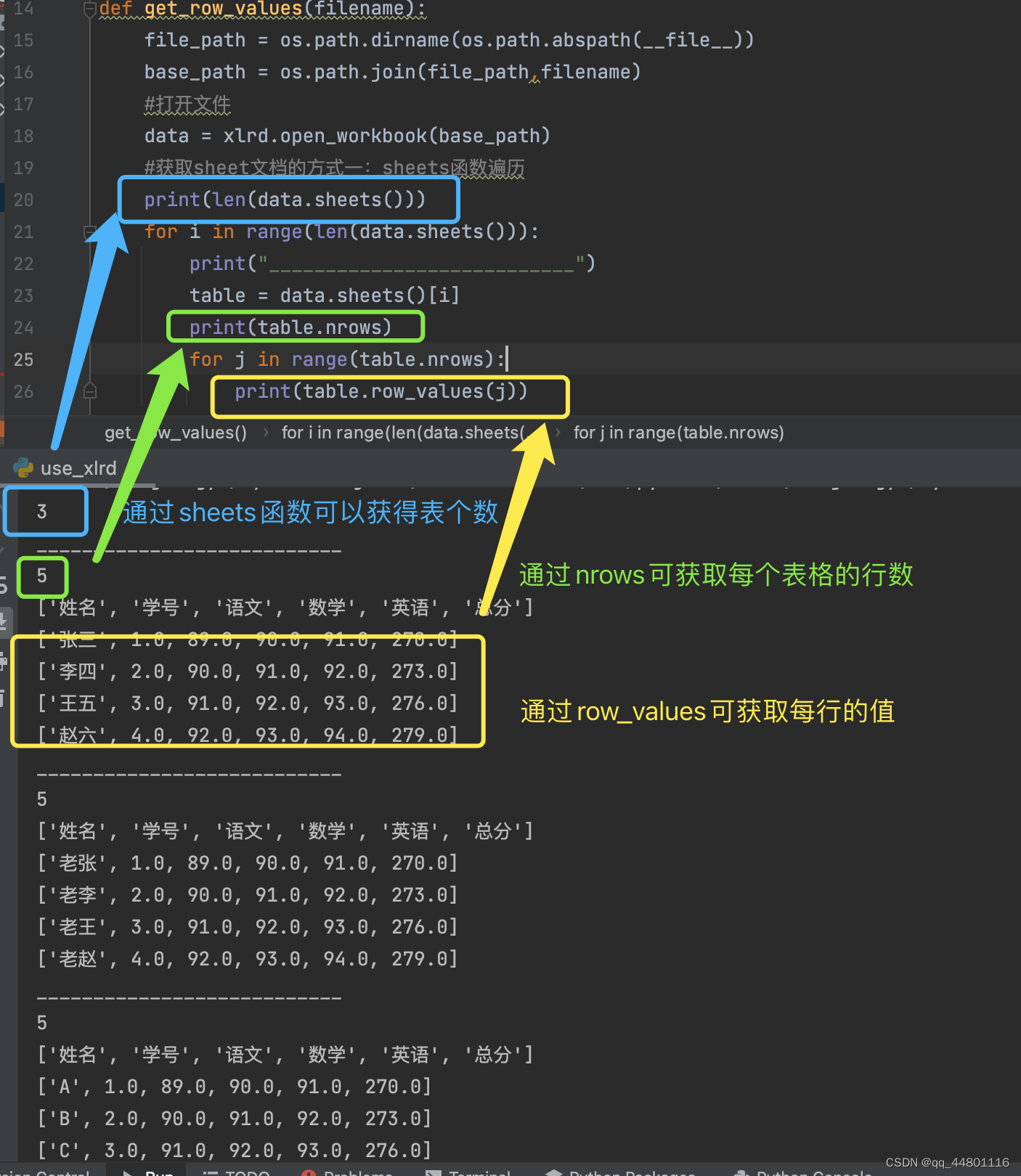
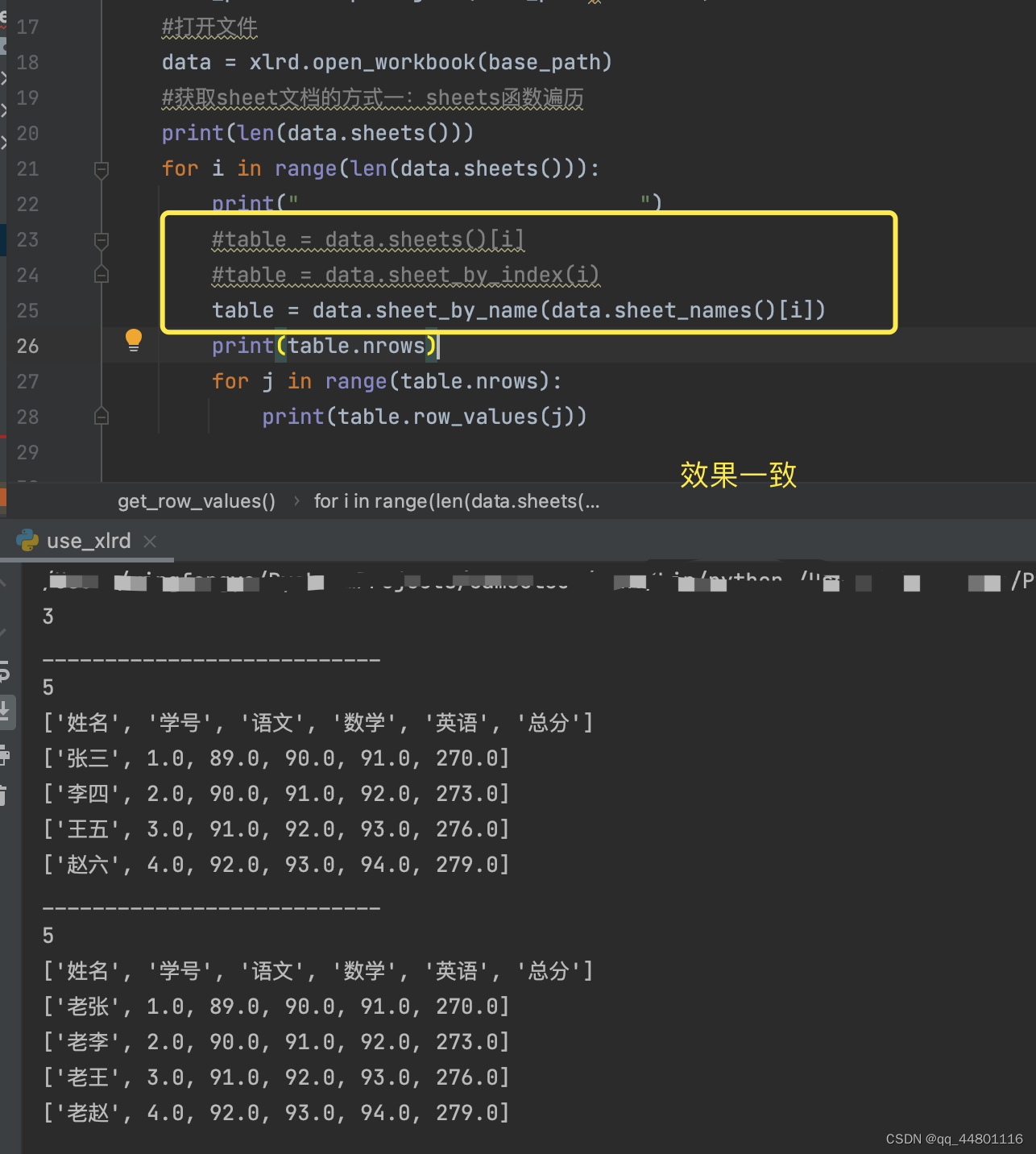
说明:也可以通过下面两种的语句获取到sheet
table = data.sheet_by_index(i):通过索引
table = data.sheet_by_name(data.sheet_names()[i]):通过sheetname
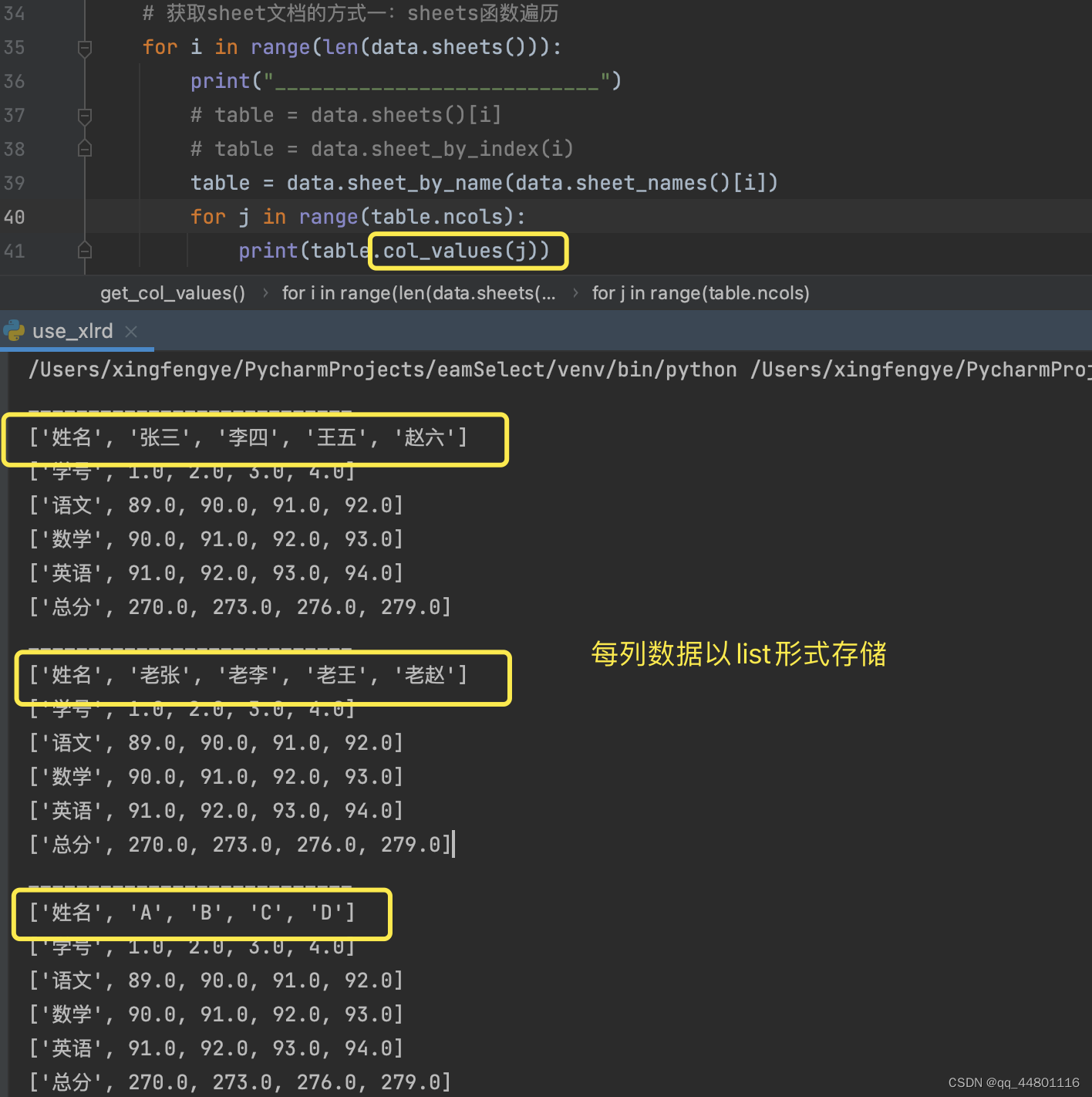
3、读物文件并获取每一列数据
def get_col_values(filename):
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path, filename)
# 打开文件
data = xlrd.open_workbook(base_path)
# 获取sheet文档的方式一:sheets函数遍历
for i in range(len(data.sheets())):
print("___________________________")
# table = data.sheets()[i]
# table = data.sheet_by_index(i)
table = data.sheet_by_name(data.sheet_names()[i])
for j in range(table.ncols):
print(table.col_values(j))
运行结果:
与每行获取数据类似,只是使用col_values()进行获取
4、读取文件并获取制定行列的数据
def get_one_row_col_value(filename):
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path, filename)
# 打开文件
data = xlrd.open_workbook(base_path)
for i in range(len(data.sheets())):
print("___________________________")
# table = data.sheets()[i]
# table = data.sheet_by_index(i)
table = data.sheet_by_name(data.sheet_names()[i])
print(table.cell_value(0,0))
print(table.cell(1,1).value)
print(table.row(2)[2].value)
代码解析
可通过table.cell_value(0,0)、table.cell(1,1).value、table.row(2)[2].value三种方式获取单元格的值
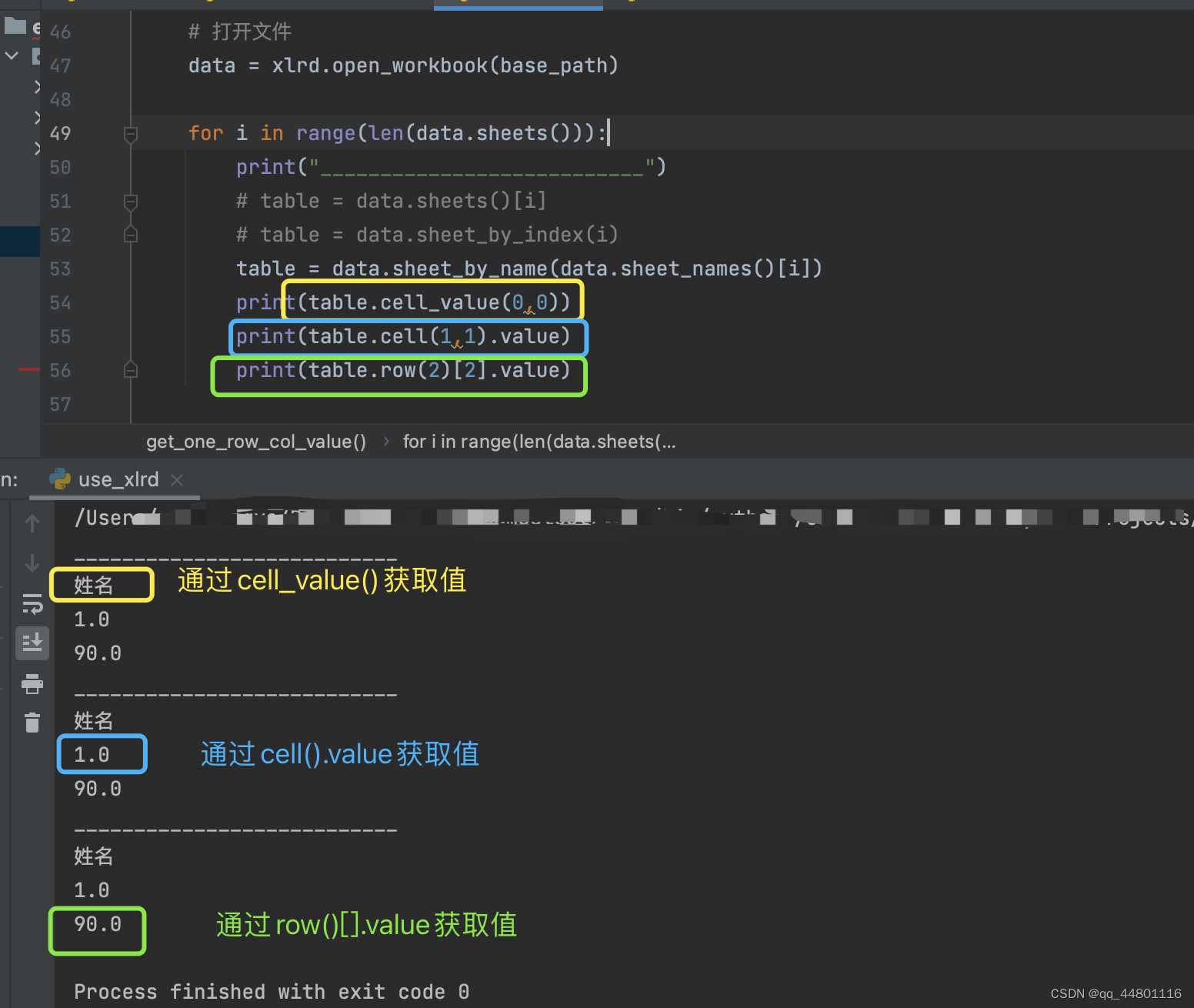
通过运行结果,我们可以看到,存储的行和列的均是从0开始的**【使用的时候需要注意哦】**
二、遇到的报错
1、raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+‘; not supported’)
原因:遇到高xird版本导致不支持xlsx格式数据
报错:
raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+‘; not supported’)
解决版本:
安装版本的:
在这里插入代码片
pip install xlrd==1.2.0
安装完毕后:
2、FileNotFoundError: [Errno 2] No such file or directory:

原因:文件路径不正确
反复查询了好几遍均未发现问题所在,后来通过复制文件,发现多一个空格
最终通过去掉空格,程序运行完毕
三、实践
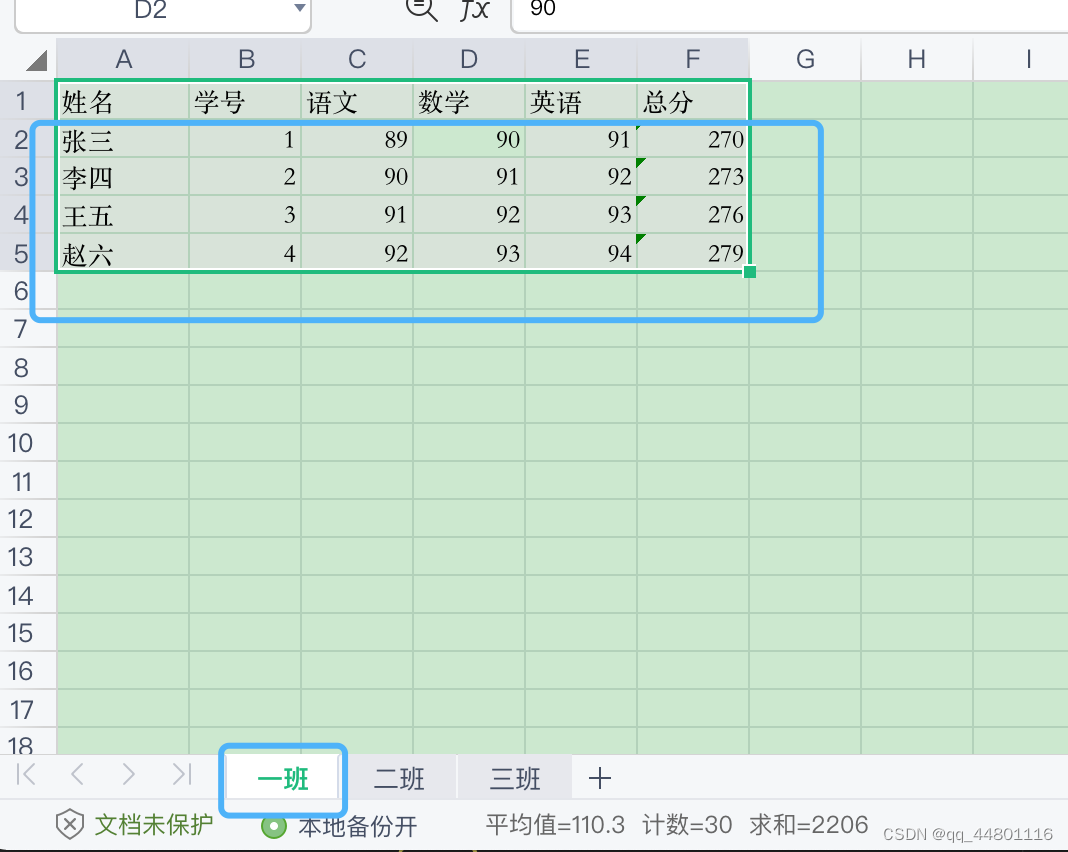
1、示例1:获取某个表格中从[x,y]行区间中的数据并存储到列表中
def get_some_rows_values(file_name,sheet_num,start_row,end_row):
"""
功能:实现获取某个sheet页(sheet_num)中从[start_row,end_row]行的数据,并存储到list中
*list中每个元素为一行数据
:param file_name:文件的名称
:param sheet_num:要查询第n个sheet页 n取值范围为【1,sheet个数】
:param start_row:要查询的开始的行号 start_row取值范围[1,sheet最大行号]
:param end_row: 要查询的结束的行号 end_row取值范围[1,∞]
:return:row_data_list
"""
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path,file_name)
#打开文件
data = xlrd.open_workbook(base_path)
table = data.sheets()[sheet_num - 1]
if end_row > table.nrows:
end_row = table.nrows
if start_row>table.nrows:
print("请检查起始行,当前检测到起始行大于表格的最大行数了")
else:
row_data_list = []
for i in range(start_row-1,end_row):
row_data_list.append(table.row_values(i))
return row_data_list
运行结果:

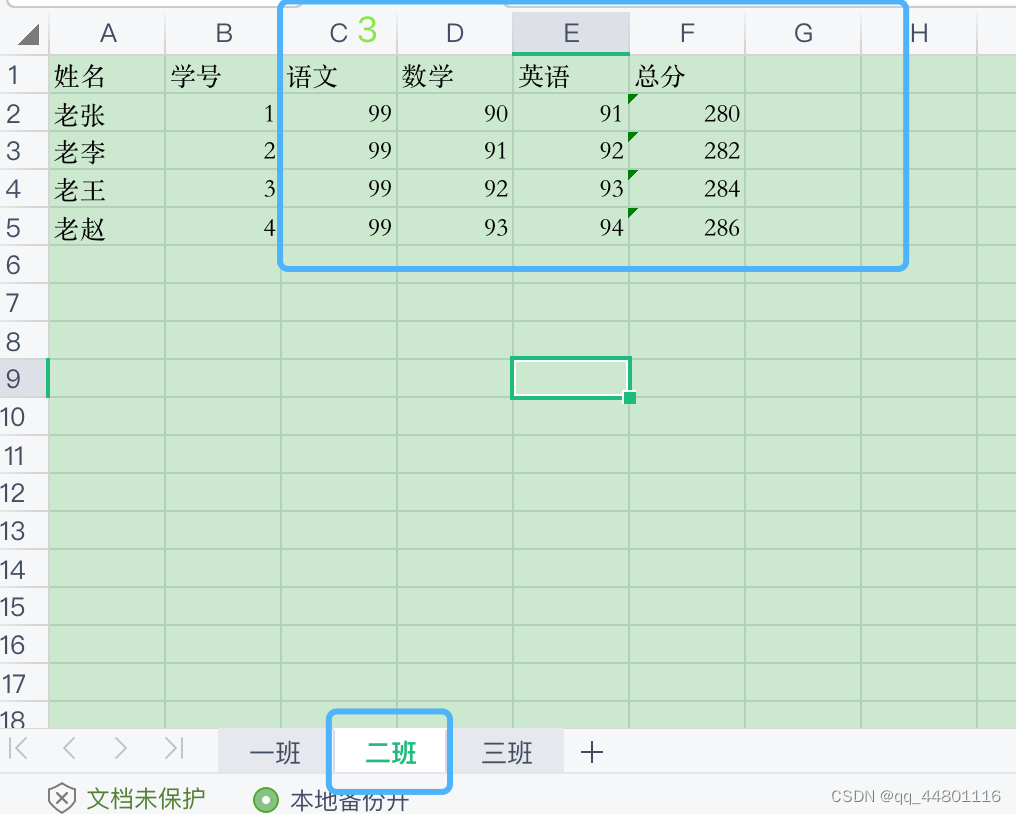
2、示例2:获取某些列的信息
该部分与示例1代码结构相同,只是把行相关函数更换为列函数,需要注意的是:如果第一行是字段名,获取到的列信息第一个元素是字段名,实际取用的时候,需要进行处理
def get_some_cols_values(file_name,sheet_num,start_col,end_col):
"""
功能:实现获取某个sheet页(sheet_num)中从[start_row,end_row]行的数据,并存储到list中
*list中每个元素为一行数据
:param file_name:文件的名称
:param sheet_num:要查询第n个sheet页 n取值范围为【1,sheet个数】
:param start_col:要查询的开始的行号 start_row取值范围[1,sheet最大行号]
:param end_col: 要查询的结束的行号 end_row取值范围[1,∞]
:return:col_data_list
"""
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path,file_name)
#打开文件
data = xlrd.open_workbook(base_path)
table = data.sheets()[sheet_num - 1]
#针对填写的末列号大于总行号的情况进行处理
if end_col > table.ncols:
end_col = table.ncols
#针对首列号填写进行检查,并将获取的值存储到list中
if start_col>table.ncols:
print("请检查起始列,当前检测到起始列大于表格的最大列数了")
else:
col_data_list = []
for i in range(start_col-1,end_col):
col_data_list.append(table.col_values(i))
return col_data_list
运行结果:

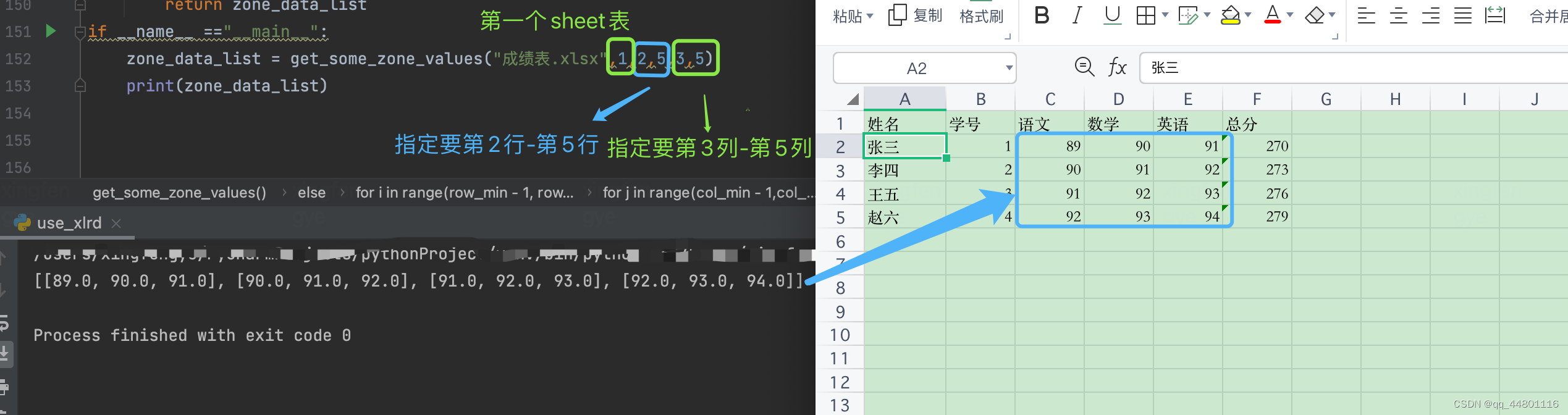
3、示例3:获取某些行和某些列之间交集的数据
def get_some_zone_values(file_name,sheet_num,row_min,row_max,col_min,col_max):
"""
功能:实现行号【row_min,row_max】->【col_min,col_max】之间的表格中的数据
最终存储到嵌套list中,每个子list为一行数据
:param file_name: 文件的名称
:param sheet_num: 要查询第n个sheet页 n取值范围为【1,sheet个数】
:param row_min: 要查询的开始的行号,取值范围【1,∞)
:param row_max: 要查询的结束的行号,取值范围【1,∞)
:param col_min: 要查询的开始的列号,取值范围【1,∞)
:param col_max: 要查询的结束的列号,取值范围【1,∞)
:return: zone_data_list
"""
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path, file_name)
# 打开文件
data = xlrd.open_workbook(base_path)
table = data.sheets()[sheet_num - 1]
# 针对填写的末列号大于总行号的情况进行处理
if col_max > table.ncols:
col_max = table.ncols
if row_max > table.nrows:
row_max = table.nrows
# 针对首列号填写进行检查,并将获取的值存储到list中
if col_min > table.ncols or row_min > table.nrows:
print("请检查起始列/起始行,当前检测到起始值大于表格的最大值了")
else:
zone_data_list = []
#进行存储数据
for i in range(row_min - 1, row_max):
row_data_list = []
for j in range(col_min - 1,col_max):
row_data_list.append(table.cell_value(i,j))
"""
方式二
row_data_list.append(table.cell(i, j).value)
方式三
row_data_list.append(table.row(i)[j].value)
"""
zone_data_list.append(row_data_list)
return zone_data_list
运行结果: