本文重点
欠拟合是机器学习中常见的问题之一,指的是模型无法很好地拟合训练数据,导致预测结果的误差较大。欠拟合问题一般是由于模型过于简单或者训练数据过少导致的。下面将详细介绍如何解决欠拟合问题。
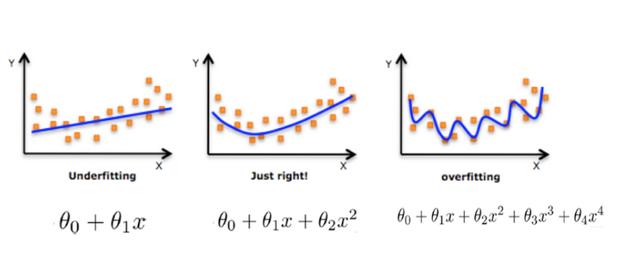
增加模型复杂度
1. 增加模型的层数:对于神经网络模型,可以增加隐藏层数或者每层的神经元个数,以增加模型的复杂度。
2. 增加特征的多项式次数:对于线性回归模型,可以通过增加特征的多项式次数来增加模型的复杂度,例如将特征 x 转化为 x^2、x^3 等。
3. 增加模型的参数个数:对于线性回归模型,可以增加模型的参数个数,例如引入交互项、多项式项等。
特征工程
1. 特征选择:选择对目标变量具有较大影响的特征,去除无关特征,以减少噪声对模型的干扰。
2. 特征提取:从原始数据中提取更有用的特征,例如通过统计学方法、主成分分析等方法提取出更具代表性的特征。
3. 特征变换:对原始特征进行变换,例如对数变换、归一化、标准化等,使得特征更符合模型的假设。
增加训练数据
1. 收集更多的数据:增加训练数据的数量可以提高模型的泛化能力,减少欠拟合问题。
2. 数据增强:通过对原始数据进行旋转、翻转、缩放等操作,生成更多的训练样本,以增加模型的泛化能力。
正则化方法
1. L1 正则化: