💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码实现

💥1 概述
我们开发了两种进化算法,即合取子句进化算法(CCEA)和析取范式进化算法(DNFEA),旨在探索与真实世界数据中的复杂交互相关的因果关系。这些算法可以应用于监督学习任务,帮助我们发现与特定目标结果(比如疾病)相关的复杂多变量关系。在不同类型的数据集中,包括带有噪声、缺失数据和多种数据类型(连续、有序和标称)的情况下,CCEA能够寻找特征(上位)之间的交互。为了防止过拟合特征交互,CCEA还利用特征敏感度函数来辅助筛选。而DNFEA主要用于在CCEA的基础上寻找更强相关性的异构组合,这些组合能够比任何单个连接子句更好地预测输出类别。CCEA和DNFEA都使用超几何概率质量函数作为适应度函数来评估。
总的来说,我们提出了一种新的进化算法,旨在从批量数据中发现复杂分类问题的因果关系规则。这种方法的关键特点包括:(a)使用超几何概率质量函数作为评估适应度的统计指标,以量化临时关联结果与目标类之间的偶然性概率,同时考虑数据集大小、缺失数据和结果类别的分布情况;(b)采用串联年龄分层进化算法,演化出连接子句的简约档案以及这些连接子句的析取,使得每个连接子句都与结果类之间具有概率显著关联;(c)使用单独的档案箱来存储不同顺序的子句,并具有动态调整的顺序特定阈值。我们通过在多个基准问题上的实验验证了该方法的有效性,这些问题包括具有异质性、上位性、重叠、类别关联噪声、缺失数据、无关特征和类别不平衡等各种组合。此外,我们还在更真实的合成基因组数据集上进行了验证,该数据集具有异质性、上位性、外源特征和噪声。在所有合成上位基准问题中,我们始终能够准确恢复出用于生成数据的真实因果关系规则集。最后,我们还讨论了将这种方法应用于真实世界调查数据集的潜在应用,该数据集旨在提供有关恰加斯病可能的生态健康干预措施的信息。
📚2 运行结果
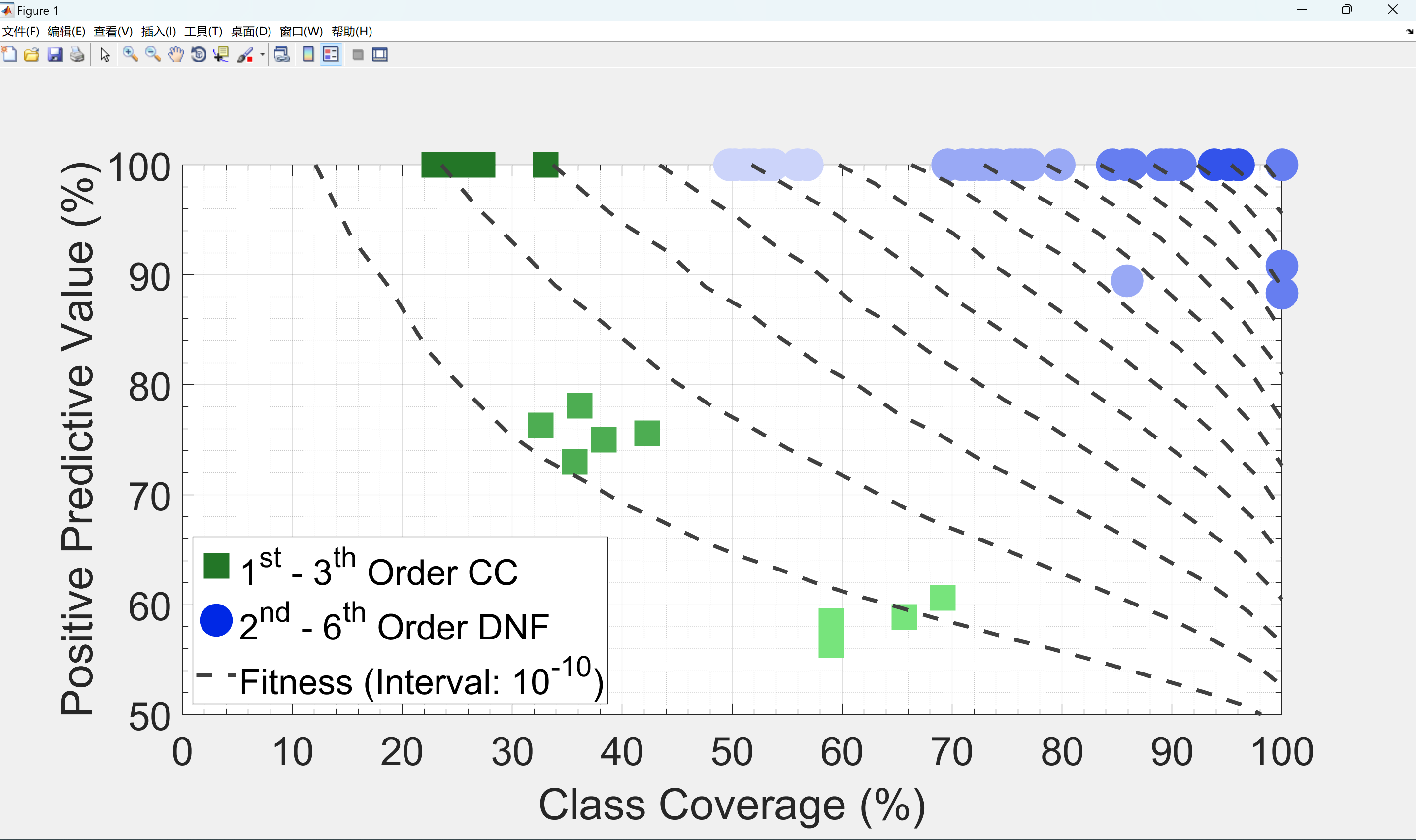
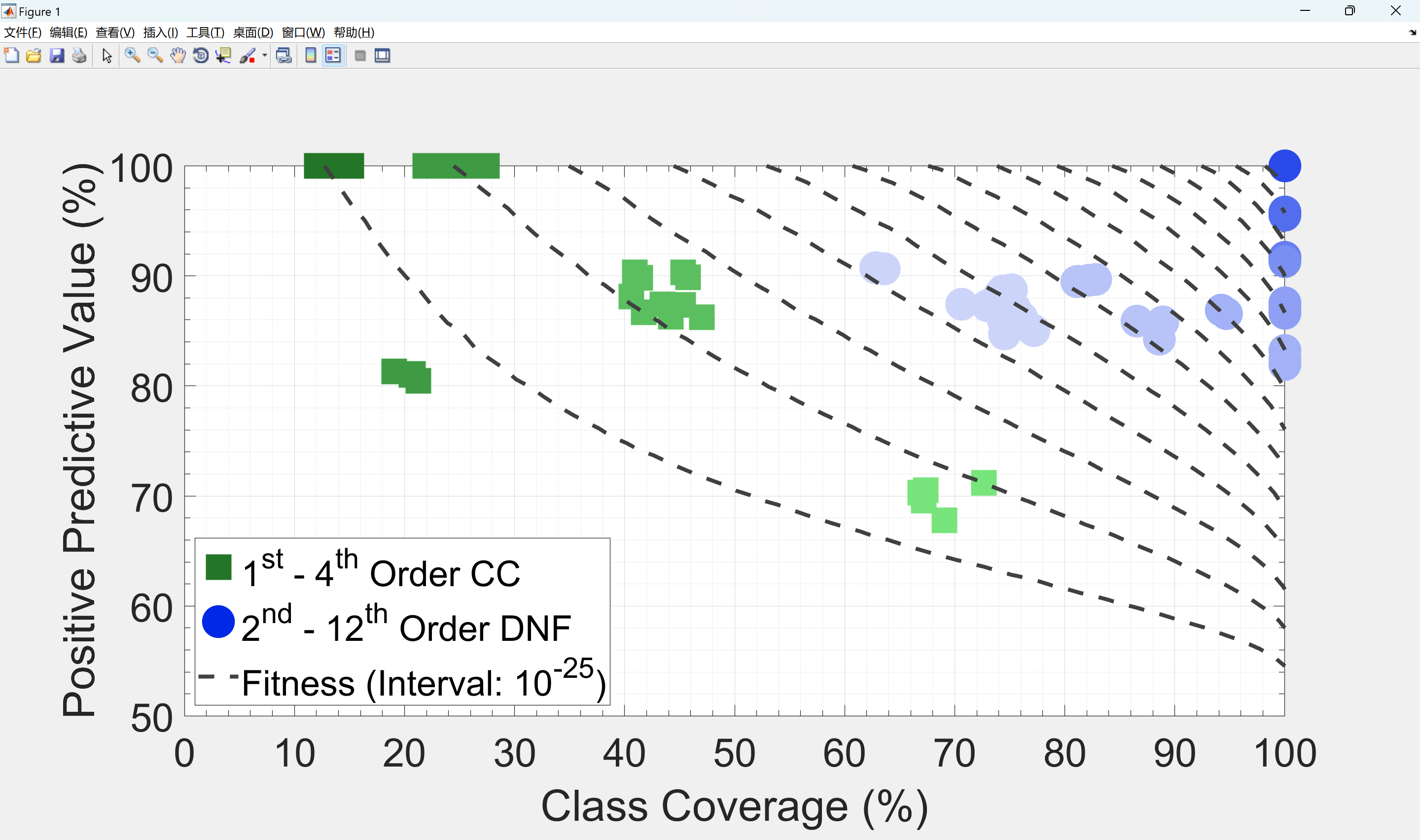
部分代码:
% set the number of address bits for the majority-on problem
NumFeat=5;
% set the number of observations
NumObs=1250;
% Now create the majority on dataset
Data=(rand(NumObs,NumFeat)<0.5)+0;
% Determine output
Output=(sum(Data,2)>NumFeat/2)+0;
% There are three data types that can be input into the CCEA
% 1) continuous or ordinal data (ContData)
% 2) nominal data (Cat
% 3) binary data or any feature where the user only wants one value
% assigned to a feature in a conjunctive clause
% For each data type list the corresponding columns in the Data matrix that
% correspond to the data type of the feature (i.e., if the data in columns
% 1 and 3 are ordinal or continuous then ConOrdData=[1 3]).;
ContOrdData=[]; % To be used for ordinal or continuous features
NomData=[]; % To be used for nominal features
BinData=1:NumFeat; % To be used for binary features or any feature where
% the user only wants one value associated with the
% conjunctive clause.
% Set the target class
TargetClass=Output==1;% In this case only data with an output of 1 will be
% analyzed
% Run my algorithm convert the data to binary
[DataBin, Param, DataSum]=Data2BinaryTarget(Data, Output, ...
ContOrdData, NomData, BinData, TargetClass);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Set the CCEA parameters
% The below settings are appropriate but not necessarily optimal for the
% 6-bit multiplexer dataset. The user can play with the parameter settings
% to find the best combination for a given dataset.
% Note: there are numerous input parameters for the CCEA. The idea is to
% give the user control over the optimal way to search a dataset. For
% instance, Datasets with binary features may require fewer age layers and
% fewer generations between novel generations; while datasets with
% continuous or ordinal features may require more age layers and more
% generations between novel generations.
Param.NumNewPop=NumFeat; % The # of new offspring created every Param.GENn
Param.TotGens=30; % Total # generations to run the CCEA
% Param.FeatLabels=[]; % The feature labels (not needed for CCEA but
% necessary for understanding the features)
Param.BestFit=false(); % Will record the best hypergeometric fitness for
% each CC order each generation
Param.ALna=5; % The # of layers that are not archived
% (helps maintain diversity)
Param.GENn=3; % The # of generations until a new population of offspring
% are created.
Param.NonArchLMax=Param.NumNewPop*1;% Max population per non-archive layer
Param.ArchOff=Param.NonArchLMax*Param.ALna; %The max # of Archive offspring
%created each generation
Param.Px=0.5; % Probability of crossover
Param.Pwc=0.75; % probability that feature selected for mutation will be
% removed from the conjunctive clause
Param.Pm=1/NumFeat; % probability that a feature will be selected for
% mutation. Only if the parent is selected for mutation
% instead of crossover.
Param.TournSize=3; % # of parents with replacement that are in the
% tournament to mate with the parent. Only most fit will
% mate.% set the number of address bits for the majority-on problem
NumFeat=5;
% set the number of observations
NumObs=1250;
% Now create the majority on dataset
Data=(rand(NumObs,NumFeat)<0.5)+0;
% Determine output
Output=(sum(Data,2)>NumFeat/2)+0;
% There are three data types that can be input into the CCEA
% 1) continuous or ordinal data (ContData)
% 2) nominal data (Cat
% 3) binary data or any feature where the user only wants one value
% assigned to a feature in a conjunctive clause
% For each data type list the corresponding columns in the Data matrix that
% correspond to the data type of the feature (i.e., if the data in columns
% 1 and 3 are ordinal or continuous then ConOrdData=[1 3]).;
ContOrdData=[]; % To be used for ordinal or continuous features
NomData=[]; % To be used for nominal features
BinData=1:NumFeat; % To be used for binary features or any feature where
% the user only wants one value associated with the
% conjunctive clause.
% Set the target class
TargetClass=Output==1;% In this case only data with an output of 1 will be
% analyzed
% Run my algorithm convert the data to binary
[DataBin, Param, DataSum]=Data2BinaryTarget(Data, Output, ...
ContOrdData, NomData, BinData, TargetClass);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Set the CCEA parameters
% The below settings are appropriate but not necessarily optimal for the
% 6-bit multiplexer dataset. The user can play with the parameter settings
% to find the best combination for a given dataset.
% Note: there are numerous input parameters for the CCEA. The idea is to
% give the user control over the optimal way to search a dataset. For
% instance, Datasets with binary features may require fewer age layers and
% fewer generations between novel generations; while datasets with
% continuous or ordinal features may require more age layers and more
% generations between novel generations.
Param.NumNewPop=NumFeat; % The # of new offspring created every Param.GENn
Param.TotGens=30; % Total # generations to run the CCEA
% Param.FeatLabels=[]; % The feature labels (not needed for CCEA but
% necessary for understanding the features)
Param.BestFit=false(); % Will record the best hypergeometric fitness for
% each CC order each generation
Param.ALna=5; % The # of layers that are not archived
% (helps maintain diversity)
Param.GENn=3; % The # of generations until a new population of offspring
% are created.
Param.NonArchLMax=Param.NumNewPop*1;% Max population per non-archive layer
Param.ArchOff=Param.NonArchLMax*Param.ALna; %The max # of Archive offspring
%created each generation
Param.Px=0.5; % Probability of crossover
Param.Pwc=0.75; % probability that feature selected for mutation will be
% removed from the conjunctive clause
Param.Pm=1/NumFeat; % probability that a feature will be selected for
% mutation. Only if the parent is selected for mutation
% instead of crossover.
Param.TournSize=3; % # of parents with replacement that are in the
% tournament to mate with the parent. Only most fit will
% mate.
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]古华茂,石锦芹,高济.基于子句的ALCN语言tableau算法增强方式[J].东南大学学报(英文版), 2008.DOI:JournalArticle/5af28551c095d718d8f5e7c5.
[2]姚明臣.机器学习和神经网络学习中的若干问题研究[D].大连理工大学,2016.