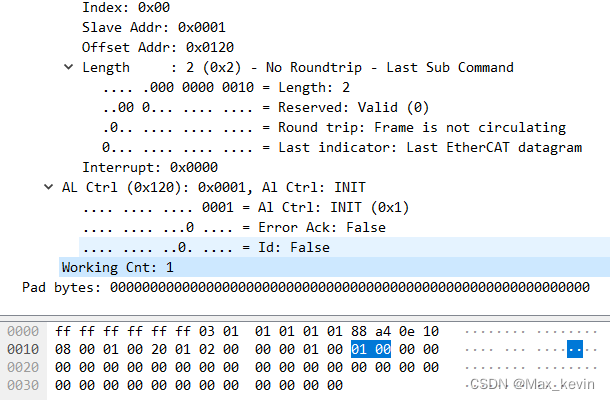
QueryByExampleExecutor用法
QueryByExampleExecutor(QBE)是一种用户友好的查询技术,具有简单的接口,它允许动态查询创建,并且不需要编写包含字段名称的查询。
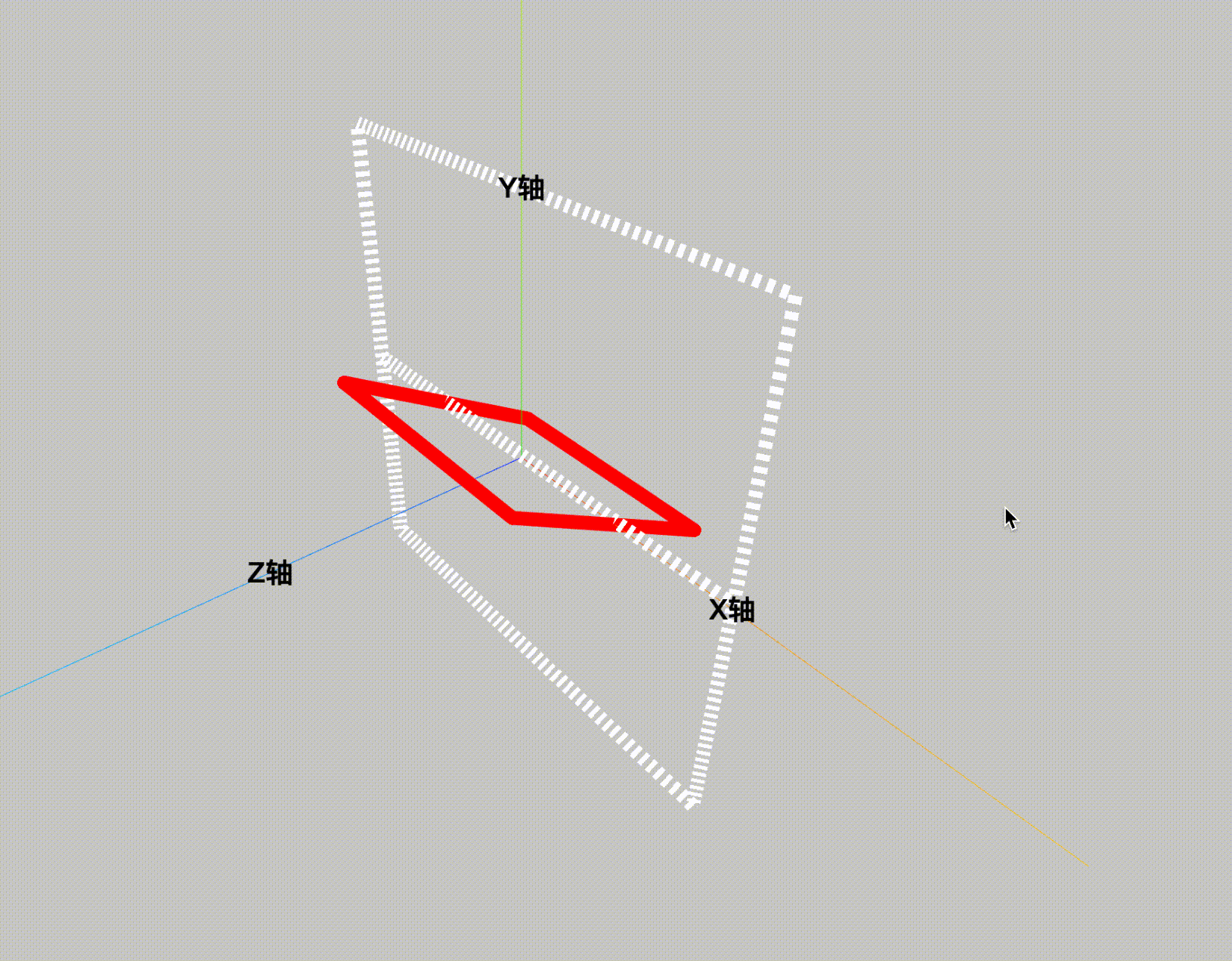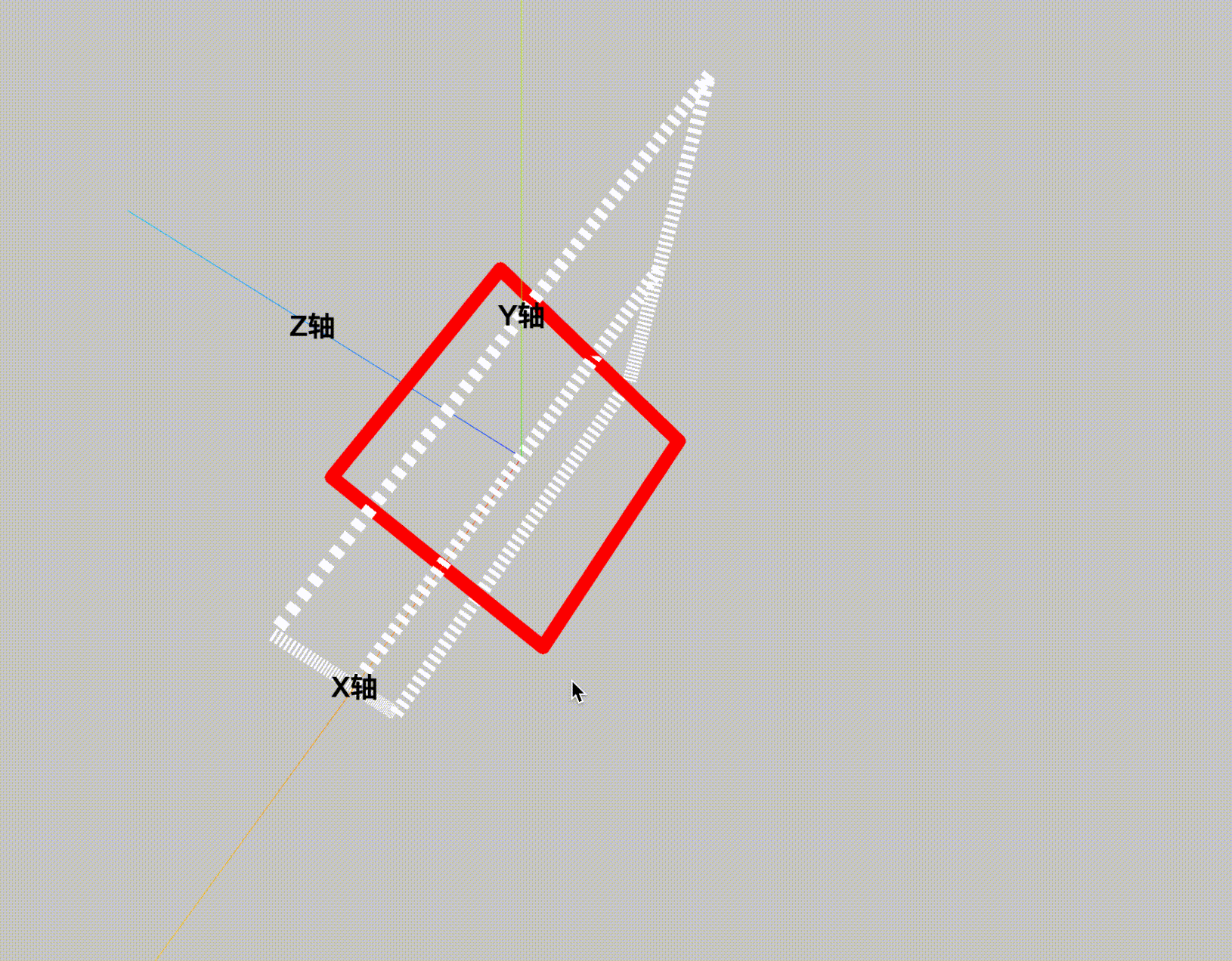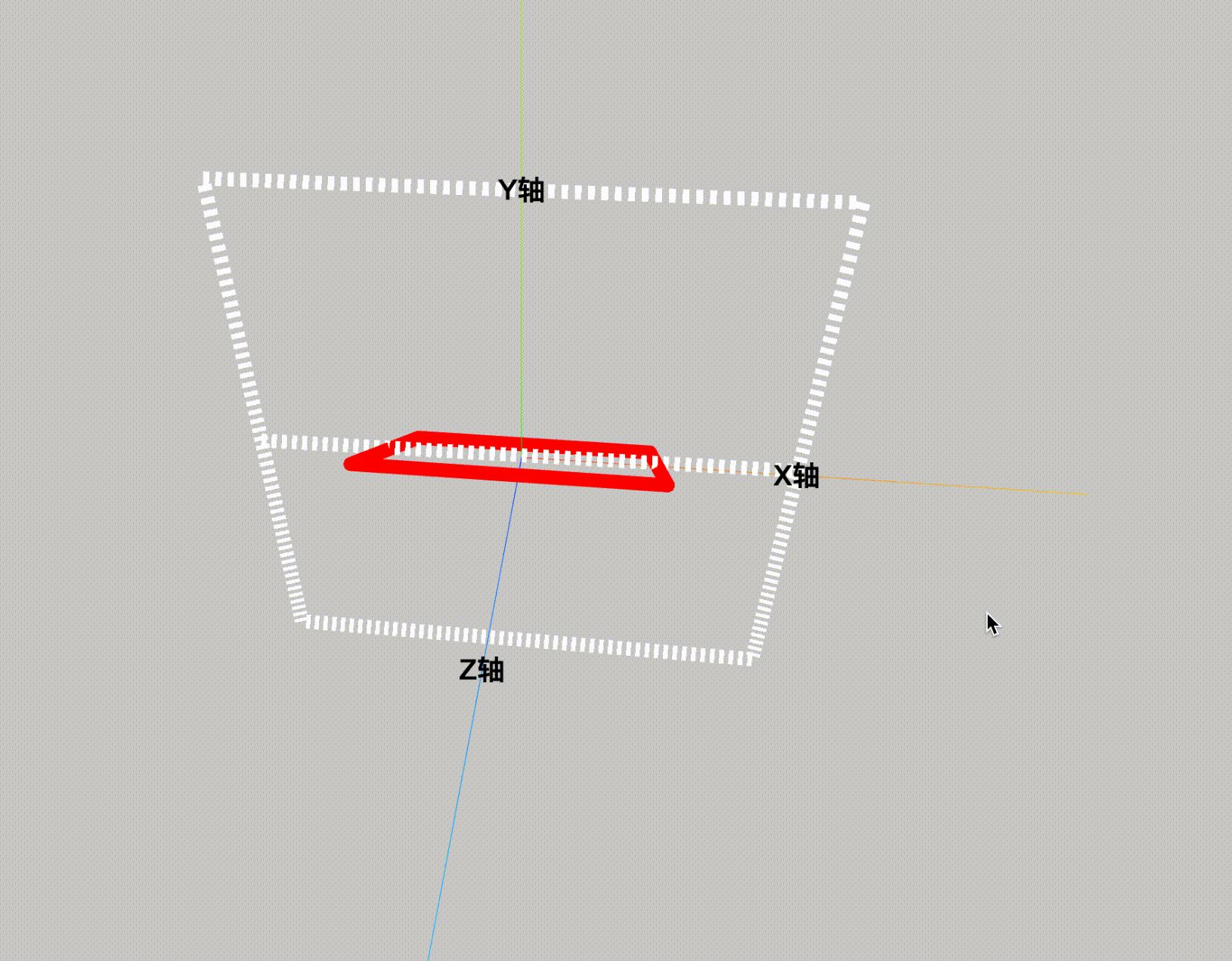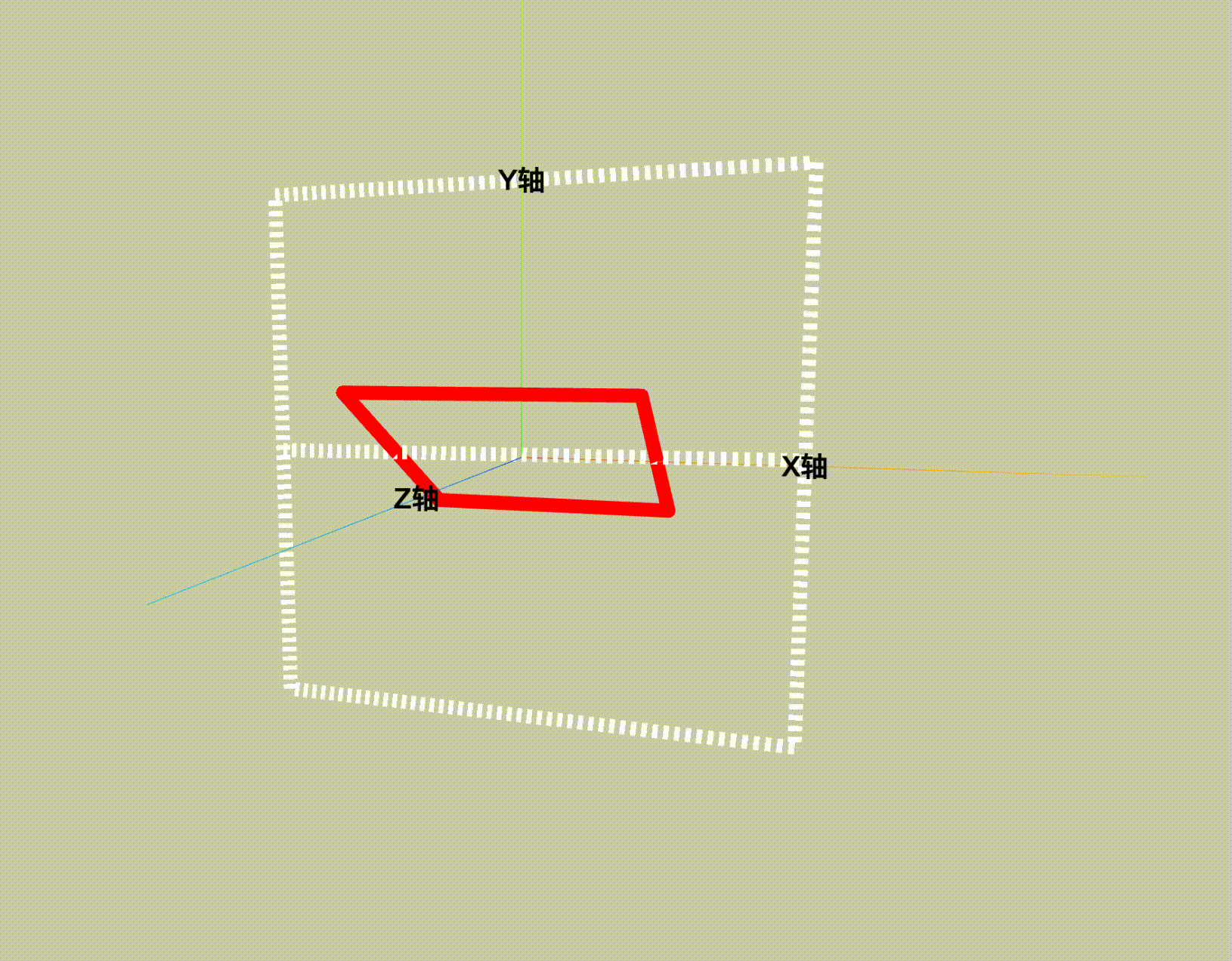
下面是一个 UML 图,你可以看到 QueryByExampleExecutor 是 JpaRepository 的父接口,也就是 JpaRespository 里面继承了 QueryByExampleExecutor 的所有方法。
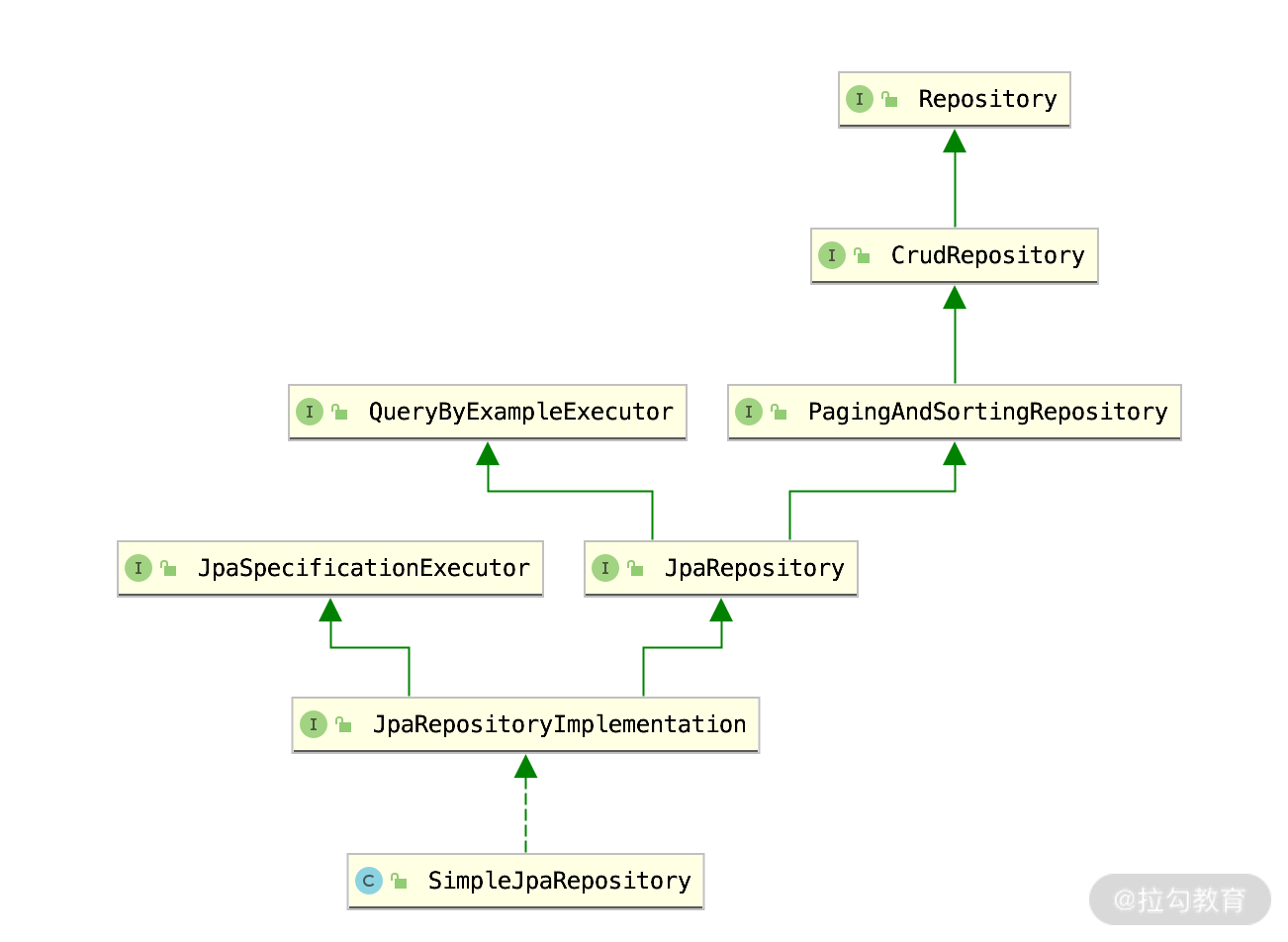
图一:Repository 类图
QBE 的基本语法
QBE 的基本语法可以分为下述几种。
复制代码
public interface QueryByExampleExecutor<T> {
//根据“实体”查询条件,查找一个对象
<S extends T> S findOne(Example<S> example);
//根据“实体”查询条件,查找一批对象
<S extends T> Iterable<S> findAll(Example<S> example);
//根据“实体”查询条件,查找一批对象,可以指定排序参数
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
//根据“实体”查询条件,查找一批对象,可以指定排序和分页参数
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
//根据“实体”查询条件,查找返回符合条件的对象个数
<S extends T> long count(Example<S> example);
//根据“实体”查询条件,判断是否有符合条件的对象
<S extends T> boolean exists(Example<S> example);
}
你可以看到这几个语法其实差不多,下面我们用 Page`` findAll 写一个分页查询的例子,看一下效果。
QueryByExampleExecutor 的使用案例
我们还用先前的 User 实体和 UserAddress 实体,并把 User 变丰富一点,这样方便测试。两个实体关键代码如下。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "address")
public class User implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
@Enumerated(EnumType.STRING)
private SexEnum sex;
private Integer age;
private Instant createDate;
private Date updateDate;
@OneToMany(mappedBy = "user",fetch = FetchType.EAGER,cascade = {CascadeType.ALL})
private List<UserAddress> address;
}
enum SexEnum {
BOY,GIRL
}
//User实体我们扩充了一些字段去了不同的类型,方便测试
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserAddress {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String address;
@ManyToOne(cascade = CascadeType.ALL)
@JsonIgnore
private User user;
}
//UserAddress基本上不变
可以看出两个实体我们加了些字段。UserAddressRepository 继承 JpaRepository,从而也继承了 QueryByExampleExceutor 里面的方法,如下所示。
复制代码
public interface UserAddressRepository extends JpaRepository<UserAddress,Long> {
}
那么我们写一个测试用例,来熟悉一下 QBE 的语法,看一下完整的测试用例的写法。
复制代码
package com.example.jpa.example1;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.collect.Lists;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestInstance;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.ExampleMatcher;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.test.annotation.Rollback;
import javax.transaction.Transactional;
import java.time.Instant;
import java.util.Date;
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserAddressRepositoryTest {
@Autowired
private UserAddressRepository userAddressRepository;
private Date now = new Date();
/**
* 负责添加数据,假设数据库里面已经有的数据
*/
@BeforeAll
@Rollback(false)
@Transactional
void init() {
User user = User.builder()
.name("jack")
.email("123456@126.com")
.sex(SexEnum.BOY)
.age(20)
.createDate(Instant.now())
.updateDate(now)
.build();
userAddressRepository.saveAll(Lists.newArrayList(UserAddress.builder().user(user).address("shanghai").build(),
UserAddress.builder().user(user).address("beijing").build()));
}
@Test
@Rollback(false)
public void testQBEFromUserAddress() throws JsonProcessingException {
User request = User.builder()
.name("jack").age(20).email("12345")
.build();
UserAddress address = UserAddress.builder().address("shang").user(request).build();
ObjectMapper objectMapper = new ObjectMapper();
// System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(address)); //可以打印出来看看参数是什么
//创建匹配器,即如何使用查询条件
ExampleMatcher exampleMatcher = ExampleMatcher.matching()
.withMatcher("user.email", ExampleMatcher.GenericPropertyMatchers.startsWith())
.withMatcher("address", ExampleMatcher.GenericPropertyMatchers.startsWith());
Page<UserAddress> u = userAddressRepository.findAll(Example.of(address,exampleMatcher), PageRequest.of(0,2));
System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(u));
}
}
其中,方法 testQBEFromUserAddress 负责测试 QBE,那么假设我们要写 API 的话,前端给我们的查询参数如下。
复制代码
{
"id" : null,
"address" : "shang",
"user" : {
"id" : null,
"name" : "jack",
"email" : "12345",
"sex" : null,
"age" : 20,
"createDate" : null,
"updateDate" : null
}
}
想要满足 email 前缀匹配、地址前缀匹配的动态查询条件,我们可以跑一下测试用例看一下结果。
复制代码
Hibernate: select useraddres0_.id as id1_2_, useraddres0_.address as address2_2_, useraddres0_.user_id as user_id3_2_ from user_address useraddres0_ inner join user user1_ on useraddres0_.user_id=user1_.id where user1_.age=20 and (user1_.email like ? escape ?) and user1_.name=? and (useraddres0_.address like ? escape ?) limit ?
2020-09-20 23:04:24.391 TRACE 62179 --- [ Test worker] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [VARCHAR] - [12345%]
2020-09-20 23:04:24.391 TRACE 62179 --- [ Test worker] o.h.type.descriptor.sql.BasicBinder : binding parameter [2] as [CHAR] - [\]
2020-09-20 23:04:24.392 TRACE 62179 --- [ Test worker] o.h.type.descriptor.sql.BasicBinder : binding parameter [3] as [VARCHAR] - [jack]
2020-09-20 23:04:24.392 TRACE 62179 --- [ Test worker] o.h.type.descriptor.sql.BasicBinder : binding parameter [4] as [VARCHAR] - [shang%]
2020-09-20 23:04:24.393 TRACE 62179 --- [ Test worker] o.h.type.descriptor.sql.BasicBinder : binding parameter [5] as [CHAR] - [\]
其中我们可以看到,传进来的参数和最终执行的 SQL,还挺符合我们的预期的,所以我们也能得到正确响应的查询结果,如下图:
也就是一个地址带一个 User 结果。
那么接下来我们分析一下 Example 这个参数,看看它具体的语法是什么。
Example 语法详解
关于 Example 的语法,我们直接看一下它的源码吧,比较简单。
复制代码
public interface Example<T> {
static <T> Example<T> of(T probe) {
return new TypedExample<>(probe, ExampleMatcher.matching());
}
static <T> Example<T> of(T probe, ExampleMatcher matcher) {
return new TypedExample<>(probe, matcher);
}
//实体参数
T getProbe();
//匹配器
ExampleMatcher getMatcher();
//回顾一下我们上一课时讲解的类型,这个是返回实体参数的Class Type;
@SuppressWarnings("unchecked")
default Class<T> getProbeType() {
return (Class<T>) ProxyUtils.getUserClass(getProbe().getClass());
}
}
而 TypedExample 这个类不是 public 的,看如下源码。
复制代码
@ToString
@EqualsAndHashCode
@RequiredArgsConstructor(access = AccessLevel.PACKAGE)
@Getter
class TypedExample<T> implements Example<T> {
private final @NonNull T probe;
private final @NonNull ExampleMatcher matcher;
}
其中我们发现三个类:Probe、ExampleMatcher 和 Example,分别做如下解释:
- Probe:这是具有填充字段的域对象的实际实体类,即查询条件的封装类(又可以理解为查询条件参数),必填。
- ExampleMatcher:ExampleMatcher 有关如何匹配特定字段的匹配规则,它可以重复使用在多个实例中,必填。
- Example:Example 由 Probe 探针和 ExampleMatcher 组成,它用于创建查询,即组合查询参数和参数的匹配规则。
通过 Example 的源码,我们发现想创建 Example 的话,只有两个方法:
- static
Exampleof(T probe):需要一个实体参数,即查询的条件。而里面的 ExampleMatcher 采用默认的 ExampleMatcher.matching(); 表示忽略 Null,所有字段采用精准匹配。 - static
Exampleof(T probe, ExampleMatcher matcher):需要两个参数构建 Example,也就表示了 ExampleMatcher 自由组合规则,正如我们上面的测试用例里面的代码一样。
那么现在又遇到个类:ExampleMatcher,我们分析一下它的语法。
ExampleMatcher 语法分析
我们通过分析 ExampleMatcher 的源码来分析一下其用法。
首先打开 Structure 视图,看看里面对外暴露的方法都有哪些。
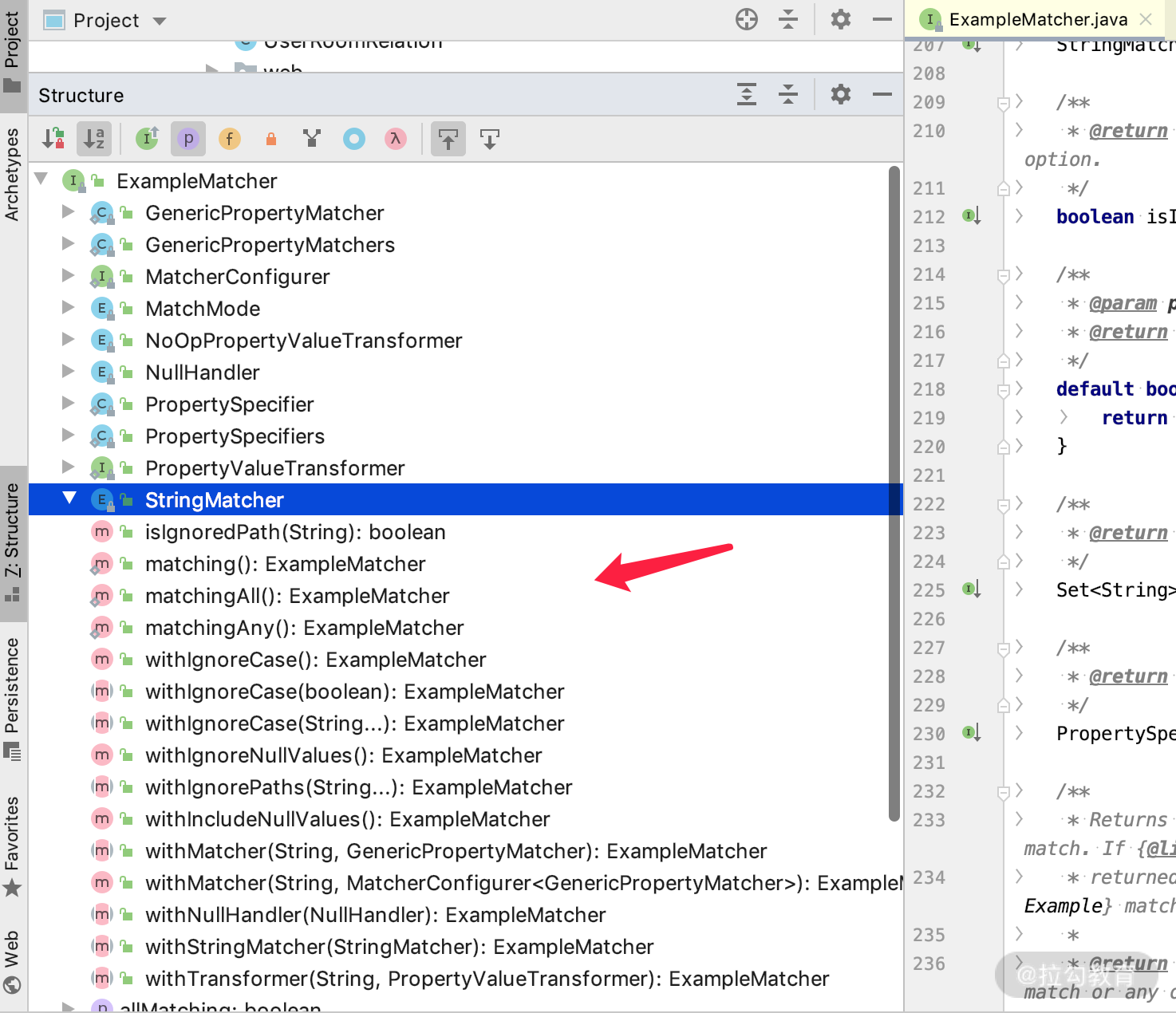
通过 Structure 视图可以很容易地发现,我们要关心的方法都是这些 public 类型的返回 ExampleMatcher 的方法,那么我们把这些方法搞明白了是不是就可以掌握其详细用法了呢?下面看看它的实现类。

TypedExampleMatcher 不是 public 类型的,所以我们可以基本上不用看了,主要看一下接口里面给我们暴露了哪些实例化方法。
初始化 ExampleMatcher 实例的方法
查看初始化 ExampleMatcher 实例的方法时,我们发现只有如下三个。
先看一下前两个方法:
复制代码
//默认matching方法
static ExampleMatcher matching() {
return matchingAll();
}
//matchingAll,默认的方法
static ExampleMatcher matchingAll() {
return new TypedExampleMatcher().withMode(MatchMode.ALL);
}
我们看到上面的两个方法所表达的意思是一样的,只不过一个是默认,一个是方法名上面有语义的。两者采用的都是 MatchMode.ALL 的模式,即 AND 模式,生成的 SQL 为如下形式:
复制代码
Hibernate: select useraddres0_.id as id1_2_, useraddres0_.address as address2_2_, useraddres0_.user_id as user_id3_2_ from user_address useraddres0_ inner join user user1_ on useraddres0_.user_id=user1_.id where user1_.age=20 and user1_.name=? and (user1_.email like ? escape ?) and (useraddres0_.address like ? escape ?) limit ?
可以看到,这些查询条件之间都是 AND 的关系。
我们再看一下方法三:
复制代码
static ExampleMatcher matchingAny() {
return new TypedExampleMatcher().withMode(MatchMode.ANY);
}
第三个方法和前面两个方法的区别在于:第三个 MatchMode.ANY,表示查询条件是 or 的关系,我们看一下 SQL:
复制代码
Hibernate: select count(useraddres0_.id) as col_0_0_ from user_address useraddres0_ inner join user user1_ on useraddres0_.user_id=user1_.id where useraddres0_.address like ? escape ? or user1_.age=20 or user1_.email like ? escape ? or user1_.name=?
以上就是三个初始化 ExampleMatcher 实例的方法,你在运用中需要注意 and 和 or 的关系。
那么,我们再看一下 ExampleMatcher 语法给我们暴露的方法有哪些。
ExampleMatcher 语法给我们暴露的方法
忽略大小写
关于忽略大小写,我们看下代码:
复制代码
//默认忽略大小写的方式,默认 False。
ExampleMatcher withIgnoreCase(boolean defaultIgnoreCase);
//提供了一个默认的实现方法,忽略大小写;
default ExampleMatcher withIgnoreCase() {
return withIgnoreCase(true);
}
//哪些属性的paths忽略大小写,可以指定多个参数;
ExampleMatcher withIgnoreCase(String... propertyPaths);
NULL 值的 property 怎么处理
暴露的 Null 值处理方式如下:
复制代码
ExampleMatcher withNullHandler(NullHandler nullHandler);
我们直接看参数 NullHandler枚举值即可,有两个可选值:INCLUDE(包括)、IGNORE(忽略),其中要注意:
- 标识作为条件的实体对象中,一个属性值(条件值)为 Null 时,是否参与过滤;
- 当该选项值是 INCLUDE 时,表示仍参与过滤,会匹配数据库表中该字段值是 Null 的记录;
- 若为 IGNORE 值,表示不参与过滤。
复制代码
//提供一个默认实现方法,忽略 NULL 属性;
default ExampleMatcher withIgnoreNullValues() {
return withNullHandler(NullHandler.IGNORE);
}
//把 NULL 属性值作为查询条件
default ExampleMatcher withIncludeNullValues() {
return withNullHandler(NullHandler.INCLUDE);
}
到这里看一下,把 NULL 属性值作为查询条件,会执行什么样的 SQL:
复制代码
Hibernate: select useraddres0_.id as id1_2_, useraddres0_.address as address2_2_, useraddres0_.user_id as user_id3_2_ from user_address useraddres0_ inner join user user1_ on useraddres0_.user_id=user1_.id where (user1_.id is null) and (user1_.update_date is null) and user1_.age=20 and (user1_.create_date is null) and lower(user1_.name)=? and (lower(user1_.email) like ? escape ?) and (user1_.sex is null) and (lower(useraddres0_.address) like ? escape ?) and (useraddres0_.id is null) limit ?
这样就会导致我们一条数据都查不出来了。
忽略某些 Paths,不参加查询条件
复制代码
//忽略某些属性列表,不参与查询过滤条件。
ExampleMatcher withIgnorePaths(String... ignoredPaths);
字符串字段默认的匹配规则
复制代码
ExampleMatcher withStringMatcher(StringMatcher defaultStringMatcher);
关于默认字符串的匹配方式,枚举类型有 6 个可选值,DEFAULT(默认,效果同 EXACT)、EXACT(相等)、STARTING(开始匹配)、ENDING(结束匹配)、CONTAINING(包含,模糊匹配)、REGEX(正则表达式)。
字符串匹配规则,我们和 JPQL 对应到一起举例,如下表所示:
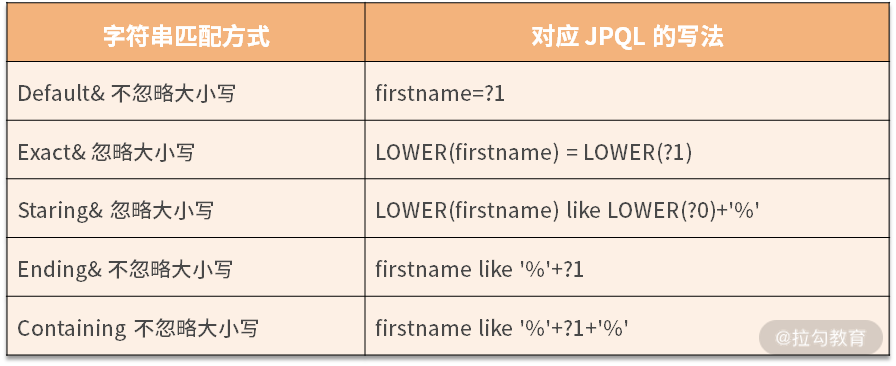
相关代码如下:
复制代码
ExampleMatcher withMatcher(String propertyPath, GenericPropertyMatcher genericPropertyMatcher);
这里显示的是指定某些属性的匹配规则,我们看一下 GenericPropertyMatcher 是什么东西,它都提供了哪些方法。
如下图,基本可以看出来都是针对字符串属性提供的匹配规则,也就是可以通过这个方法定制不同属性的 StringMatcher 规则。
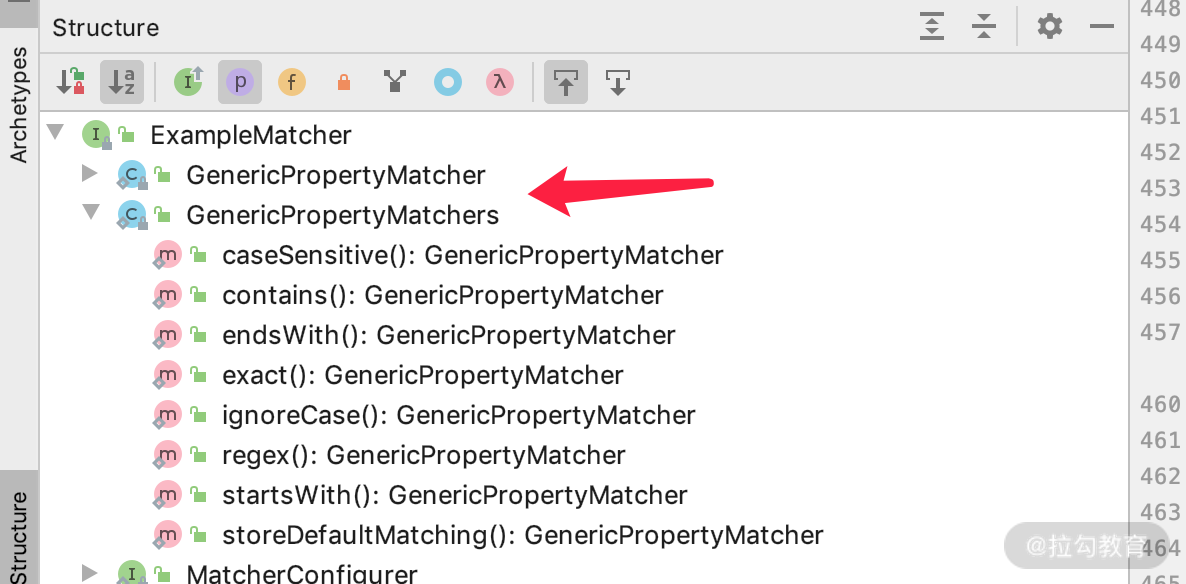
到这里,语法部分我们就学习完了,下面看一个完整的例子感受一下。
完整的例子
下面是一个关于咱们上面所说的暴露的方法的使用的例子,你可以跟着我的步骤自己动手练习一下。
复制代码
//创建匹配器,即如何使用查询条件
ExampleMatcher exampleMatcher = ExampleMatcher
//采用默认and的查询方式
.matchingAll()
//忽略大小写
.withIgnoreCase()
//忽略所有null值的字段
.withIgnoreNullValues()
.withIgnorePaths("id","createDate")
//默认采用精准匹配规则
.withStringMatcher(ExampleMatcher.StringMatcher.EXACT)
//级联查询,字段user.email采用字符前缀匹配规则
.withMatcher("user.email", ExampleMatcher.GenericPropertyMatchers.startsWith())
//特殊指定address字段采用后缀匹配
.withMatcher("address", ExampleMatcher.GenericPropertyMatchers.endsWith());
Page<UserAddress> u = userAddressRepository.findAll(Example.of(address,exampleMatcher), PageRequest.of(0,2));
这时候可能会有同学问了,我是怎么知道默认值的呢?我们直接看类的构造方法就可以了,如下所示:
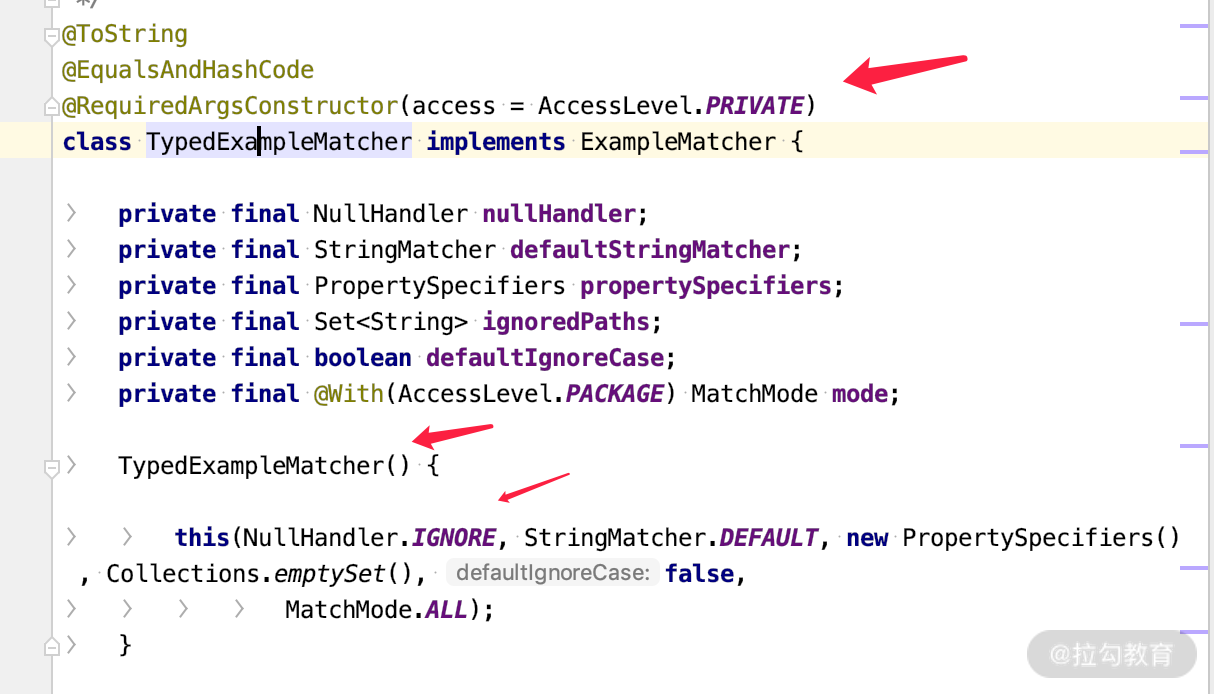
从源码中我们可以看到,实现类的构造方法只有一个,就是“赋值默认”的方式。下面我整理了一些在使用这个语法时需要考虑的细节。
ExampleExceutor 使用中需要考虑的因素
- Null 值的处理:当某个条件值为 Null 时,是应当忽略这个过滤条件,还是应当去匹配数据库表中该字段值是 Null 的记录呢?
- 忽略某些属性值:一个实体对象,有许多个属性,是否每个属性都参与过滤?是否可以忽略某些属性?
- 不同的过滤方式:同样是作为 String 值,可能“姓名”希望精确匹配,“地址”希望模糊匹配,如何做到?
那么接下来我们分析一下源码看看其原理,说了这么半天,它到底和 JpaSpecificationExecutor 什么关系呢?我们接着看。
QueryByExampleExecutor 源码分析
怎么分析源码也很简单,我们看一下上面的我们 findAll 的方法调用之处。

从而找到 findAll 方法的实现类,如下所示:
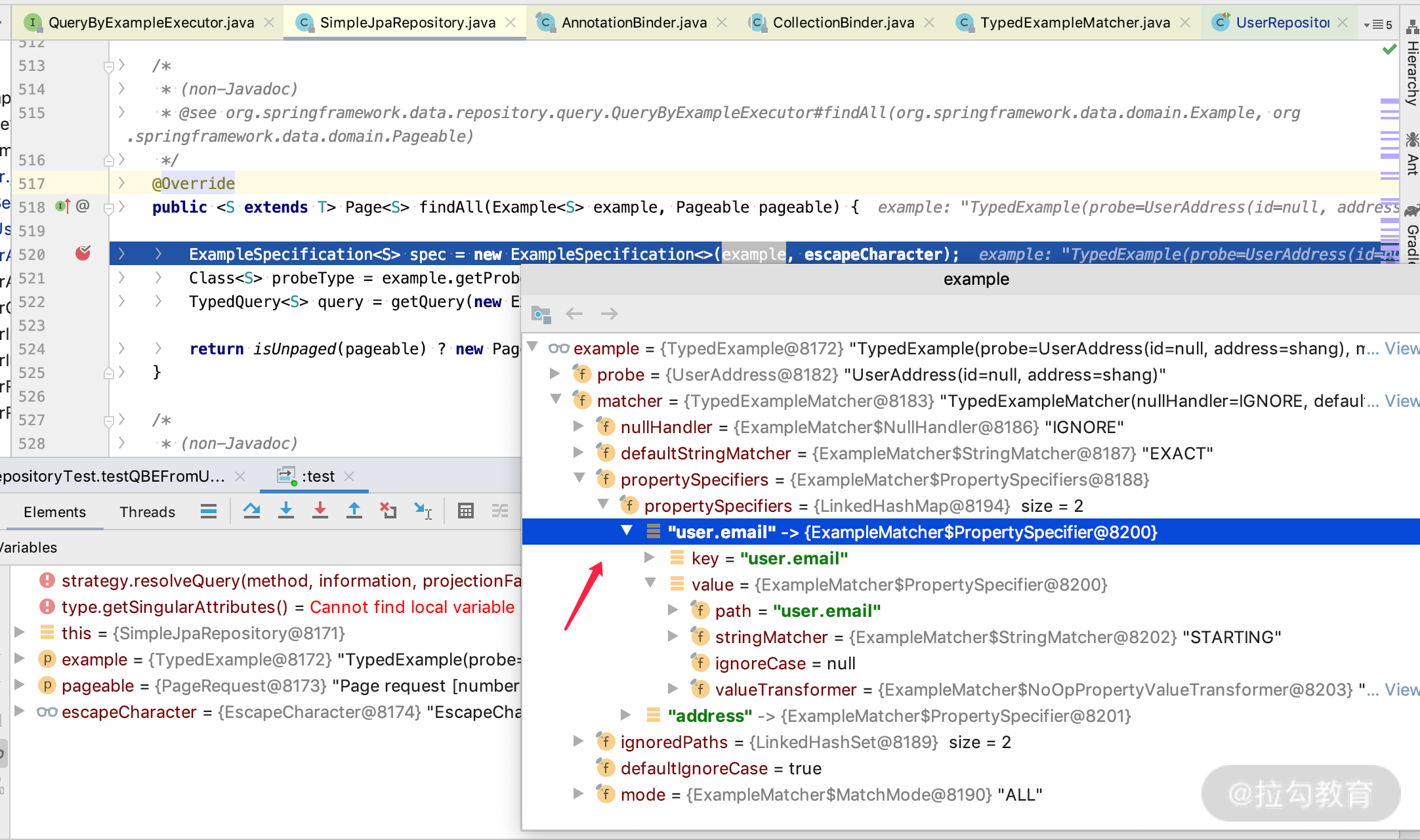
通过 Debug 断点我们可以看到,我们刚才组合出来的 Example 对象,这个时候被封装成了 ExampleSpecification 对象,那么我们接着往下看方法里面的关键内容。
复制代码
TypedQuery<S> query = getQuery(new ExampleSpecification<>(example, escapeCharacter), probeType, pageable);
getQuery 方法是创建 Query 的关键,因为它里面做了条件的转化逻辑。那么我们再看一下参数 ExampleSpecification 的源码,发现它是接口 Specification 的实现类,并且是非公开的实现类,可以通过接口对外暴露 and、or、not、where 等组合条件的查询条件。
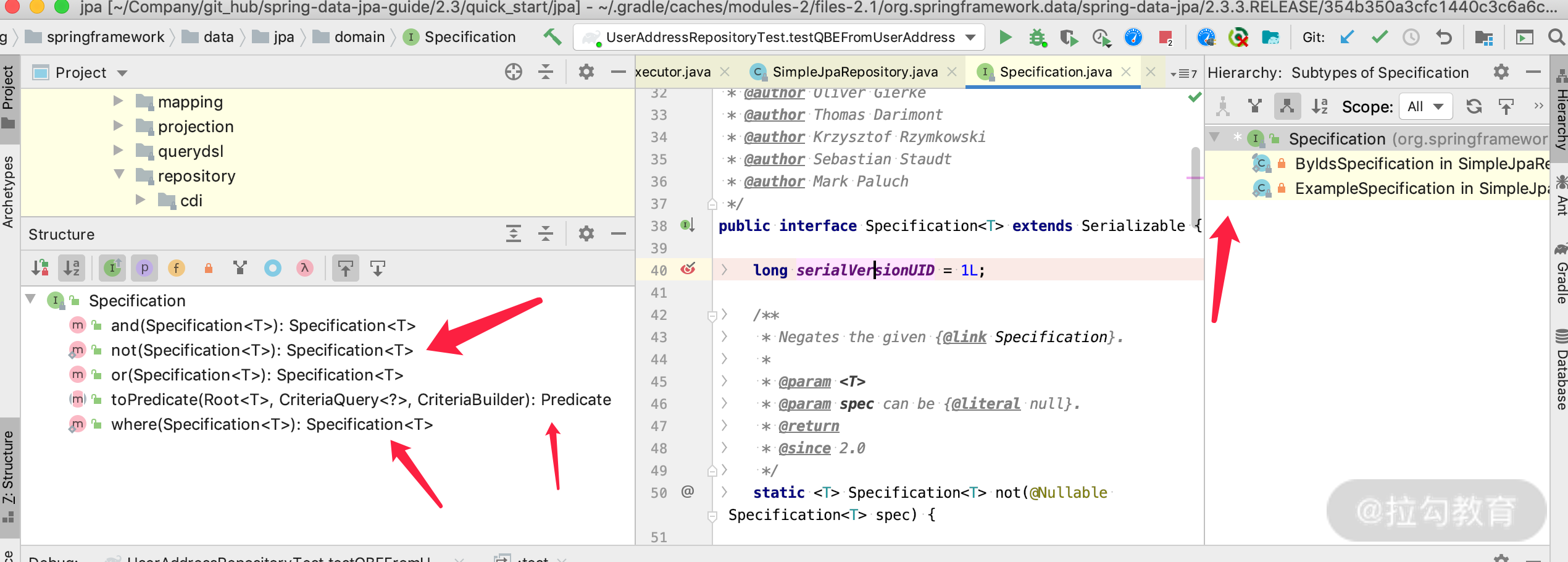
我们接着看上面的 getQuery 方法的实现,可以看到接收的参数是 Specification``接口,所以不用关心实现类是什么。

我们接着再看这个断点的 getQuery 方法:
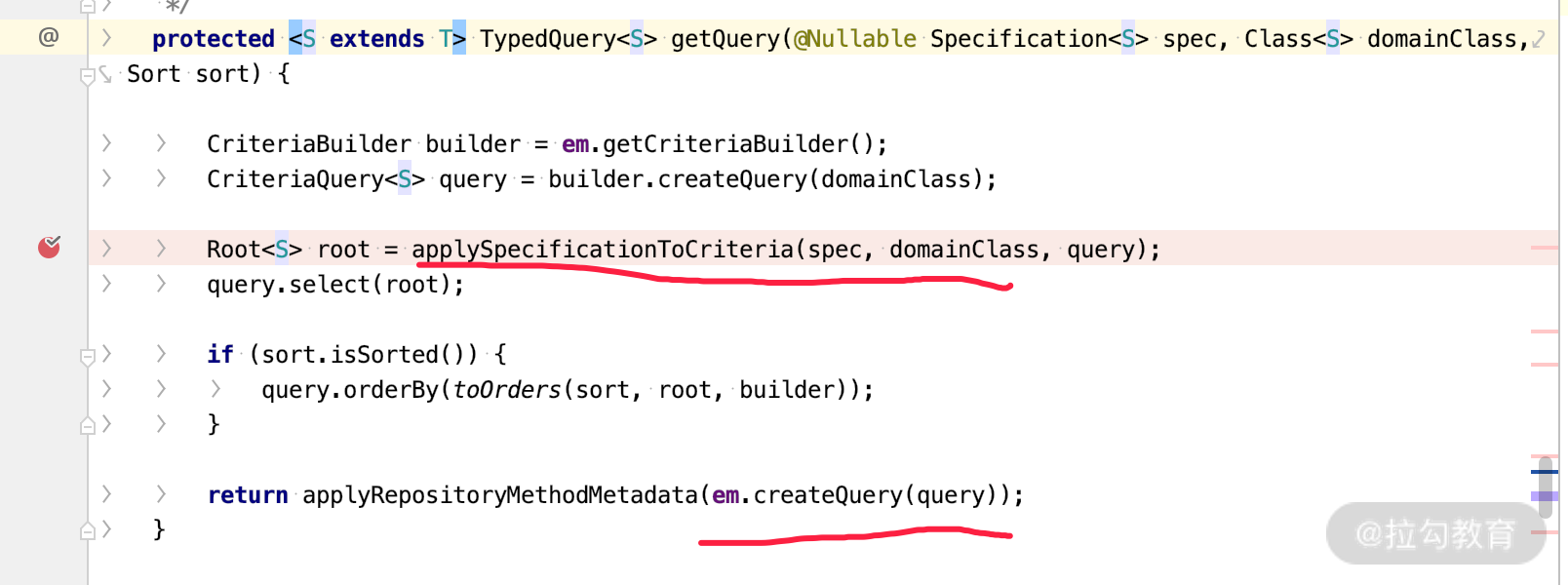
里面有一段代码会调用 applySpecificationToCriteria 生成 root,并由 Root 作为参数生成 Query,从而交给 EM(EntityManager)进行查询。
我们再来看一下关键的 applySpecificationToCriteria 方法。
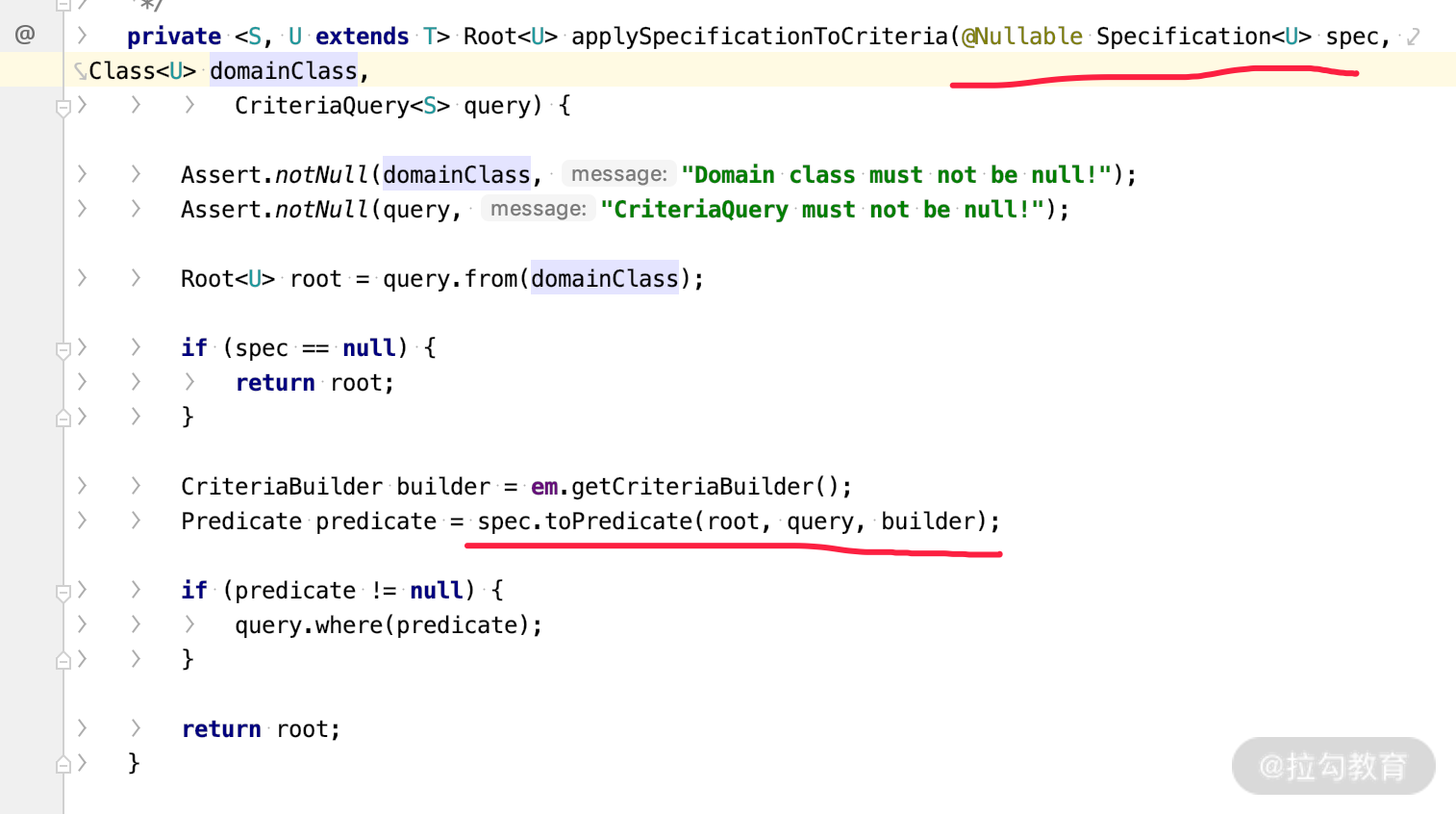
根据 Specification 调用 toPredicate 方法,生成 Predicate,从而实现查询需求。
现在我们已经对 QueryByExampleExecutor 的用法和实现原理基本掌握了,我们再来看一个十分相似的接口:JpaSpecificationExecutor 是干什么用的。
JpaSpecificationExecutor 接口结构
正如我们开篇提到的【图一:Repository 类图】,JpaSpecificationExecutor 是 JPA 里面的另一个接口分支。我们先来看看它的基本语法。
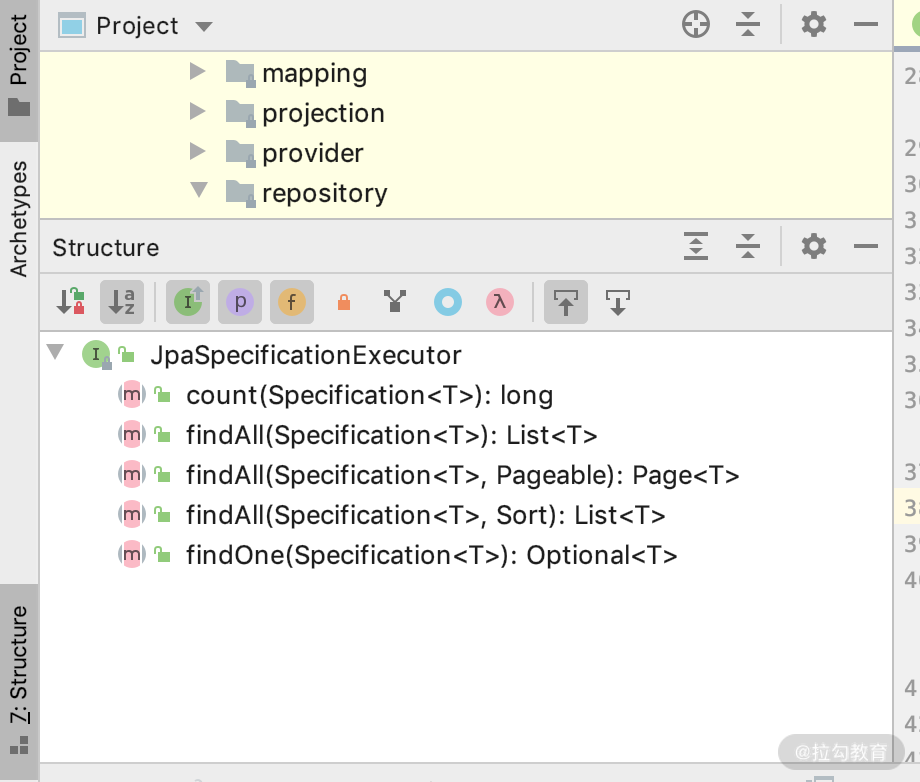
我们通过查看 JpaSpecificationExecutor 的 Structure 图会发现,方法就有这么几个,细心的同学这个时候会发现它的参数 Specification,正是我们分析 QueryByExampleExecutor 的原理时候使用的 Specification。
那么 JpaSpecificationExecutor 帮我们解决了哪些问题呢?
JpaSpecificationExecutor 解决了哪些问题
- 我们通过 QueryByExampleExecutor 的使用方法和原理分析,不难发现,JpaSpecificationExecutor 的查询条件 Specification 十分灵活,可以帮我们解决动态查询条件的问题,正如 QueryByExampleExecutor 的用法一样;
- 它提供的 Criteria API 的使用封装,可以用于动态生成 Query 来满足我们业务中的各种复杂场景;
- 既然QueryByExampleExecutor 能利用 Specification 封装成框架,我们是不是也可以利用 JpaSpecificationExecutor 封装成框架呢?这样就学会了举一反三。