文章目录
- 特征工程
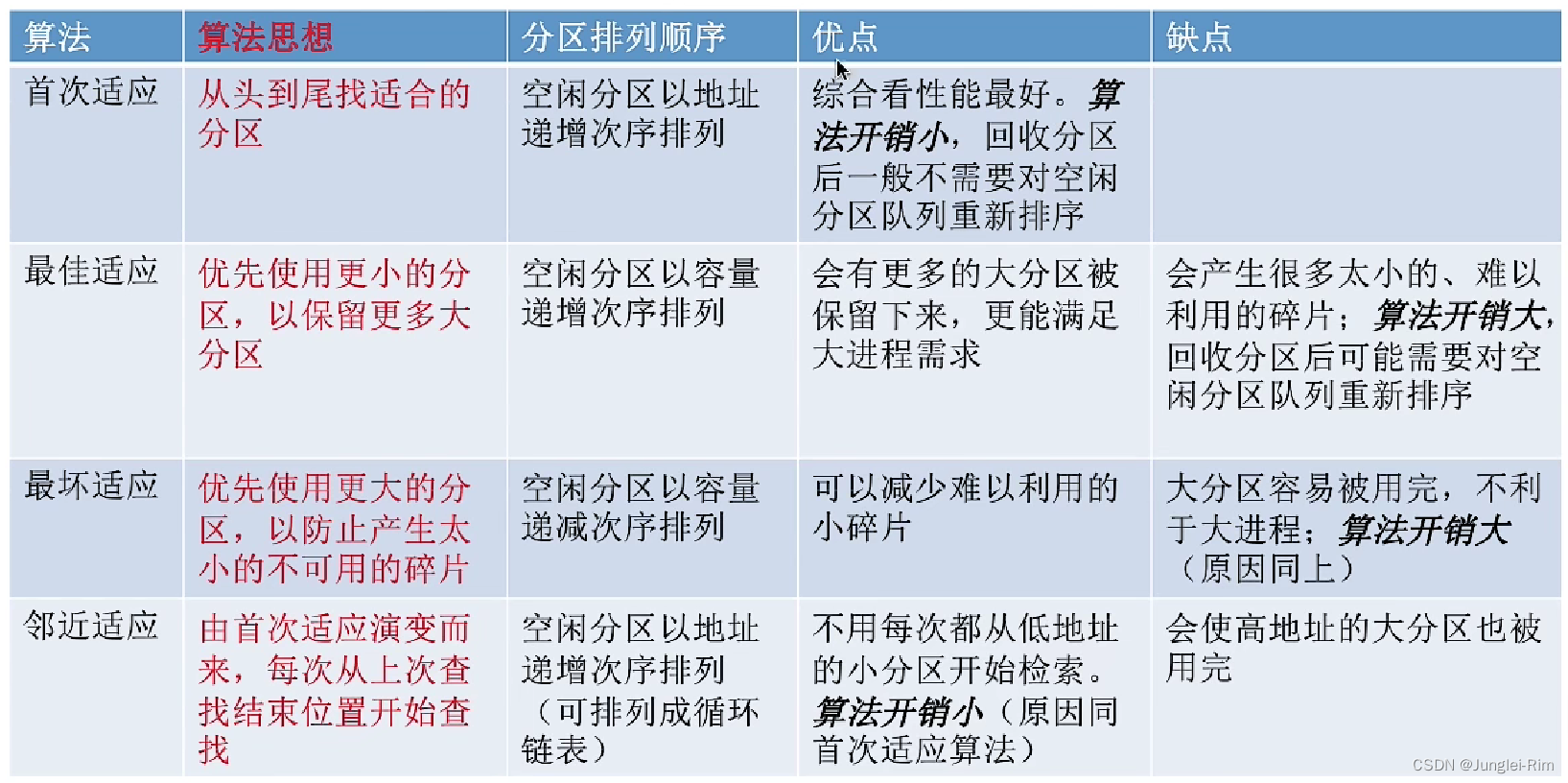
- 过滤法(Filter)
- 方差过滤
- 相关性过滤
- 卡方过滤
- F验表
- 互信息法
- 小结
- 嵌入法(Embedded)
- 包装法(Wrapper)
特征工程
| 特征提取(feature extraction) | 特征创造(feature creation) | 特征选择(feature selection) |
|---|---|---|
| 从文字,图像,声音等其他非结构化数据中提取新信息作为特征。比如说,从淘宝宝贝的名称中提取出产品类别,产品颜色,是否是网红产品等等。 | 把现有特征进行组合,或互相计算,得到新的特征。比如说,我们有一列特征是速度,一列特征是距离,我们就可以通过让两列相除,创造新的特征:通过距离所花的时间。 | 从所有的特征中,选择出有意义,对模型有帮助的特征,以避免必须将所有特征都导入模型去训练的情况。 |
特征选择是特征工程中最为简单的一个,在做特征选择时,第一步是根据我们的目标,用业务常识来选择特征,做一些基本的判断,也就是需要理解业务。
理解业务,对特征做出基本的判断,只适用于特征量不多且好分辨的数据集,多特征不易分辨的数据集,可以采用四种方法可以用来选
择特征:过滤法,嵌入法,包装法,和降维算法。
本文主要对过滤法,嵌入法,包装法进行解释说明,并用sklearn进行实践操作,降维算法可以看下一篇博客详解。
过滤法(Filter)
过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。它是根据各种统计检验中的分数以及相关。
 选择特征时不管模型,该方法基于特征的通用表现去选择,比如: 目标相关性、自相关性和发散性等。
选择特征时不管模型,该方法基于特征的通用表现去选择,比如: 目标相关性、自相关性和发散性等。
方差过滤
方差越大的特征,那么我们可以认为它是比较有用的。如果方差较小,比如小于1,那么这个特征可能对我们的算法作用没有那么大。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃。
方差过滤,就是设置一个阈值,方差小于这个阈值的全部过滤掉,舍弃掉。sklearn中使用类VarianceThreshold,只需要填写一个阈值参数,不填默认0,就是把毫无关联的特征删除掉。
VarianceThreshold(阈值).fit_transform(特征矩阵数据集)
比如说,我要删除一半的特征,那么我们需要找到所有特征方差的中位数来作为阈值:
from sklearn.feature_selection import VarianceThreshold
import numpy as np
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X) # X.var()每一列的方差
当特征是二分类时,特征的取值就是伯努利随机变量,这些变量的方差可以计算为:
V
[
x
]
=
p
(
1
−
p
)
V[x] = p(1-p)
V[x]=p(1−p)
其中X是特征矩阵,p是二分类特征中的一类在这个特征中所占的概率。
二分类特征中某种分类占到80%以上的时候,删除该特征:
X_bvar = VarianceThreshold(.8 * (1 - .8)).fit_transform(X)
可以对进行方差过滤后的特征集进行交叉验证,看看效果如何:效果其实主要看超参数threshold阈值的选取
| 阈值很小 被过滤掉得特征比较少 | 阈值比较大 被过滤掉的特征有很多 | |
|---|---|---|
| 模型表现 | 不会有太大影响 | 可能变更好,代表被滤掉的特征大部分是噪音 也可能变糟糕,代表被滤掉的特征中很多都是有效特征 |
| 运行时间 | 可能降低模型的运行时间基于方差很小的特征有多少当方差很小的特征不多时对模型没有太大影响 | 一定能够降低模型的运行时间算法在遍历特征时的计算越复杂,运行时间下降得越多 |
现实中,我们只会使用阈值为0或者阈值很小的方差过滤,来为我们优先消除一些明显用不到的特征,然后我们会选择更优的特征选择方法继续削减特征数量。
相关性过滤
望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪音。
sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。
再结合feature_selection.SelectKBest这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目的无关的特征。
卡方值 X2的计算公式如下:

observed是实际值,expected是理论值。卡方值的目的是衡量理论和实际的差异程度。
卡方值高,说明两变量之间具有相关性的可能性更大。
from sklearn.ensemble import RandomForestClassifier as RFC # 随机森林
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.feature_selection import SelectKBest #选出前K个分数最高的特征
from sklearn.feature_selection import chi2 # 卡方
# 通过卡方=》排序=》选择300个相关性最高的特征
X_fschi = SelectKBest(chi2, k=300).fit_transform(X_fsvar, y)
# 用随机森林验证一下
cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()
如果交叉验证的结果比之前的准确率低,说明删除了与模型相关且有效的特征,k值设置的太小了,如果模型的表现提升,则说明我们的相关
性过滤是有效的,是过滤掉了模型的噪音的,这时候我们就保留相关性过滤的结果。
如何选择超参数k?
一个一个试,画学习曲线:
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(390,200,-10):
X_fschi = SelectKBest(chi2, k=i).fit_transform(X_fsvar, y)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()
score.append(once)
plt.plot(range(350,200,-10),score)
plt.show()
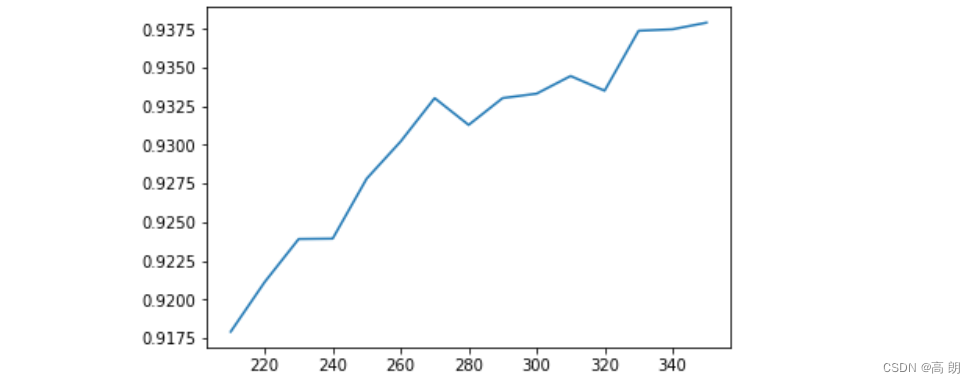 随着K值的不断增加,模型的表现不断上升,这说明,K越大越好,数据中所有的特征都是与标签相关的。
随着K值的不断增加,模型的表现不断上升,这说明,K越大越好,数据中所有的特征都是与标签相关的。
上面学习曲线选不出k值,还可以通过:看p值选择k
卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和P值两个统计量,其中卡方值很难界定有效的范围,而p值,我们一般使用0.01或0.05作为显著性水平,即p值判断的边界,具体我们可以这样来看:
| P值 | <=0.05或0.01 | >0.05或0.01 |
|---|---|---|
| 数据差异 | 差异不是自然形成的 | 这些差异是很自然的样本误差 |
| 相关性 | 两组数据是相关的 | 两组数据是相互独立的 |
| 原假设 | 拒绝原假设,接受备择假设 | 接受原假设 |
从特征工程的角度,我们希望选取卡方值很大,p值小于0.05的特征,即和标签是相关联的特征。
chivalue, pvalues_chi = chi2(X_fsvar,y)
# chivalue卡方值 pvalues_chi p值
F验表
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。它即可以做回归也可以做分类,因此包含
feature_selection.f_classif(F检验分类)和feature_selection.f_regression(F检验回归)两个类。其中F检验分类用于标签是离散型变量的数据,而F检验回归用于标签是连续型变量的数据。
F检验的本质是寻找两组数据之间的线性关系,其原假设是”数据不存在显著的线性关系“。它返回F值和p值两个统计量。和卡方过滤一样,我们希望选取p值小于0.05或0.01的特征,这些特征与标签时显著线性相关的,而p值大于0.05或0.01的特征则被我们认为是和标签没有显著线性关系的特征,应该被删除。
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar,y)
互信息法
互信息是衡量变量之间相互依赖程度,它的计算公式如下:
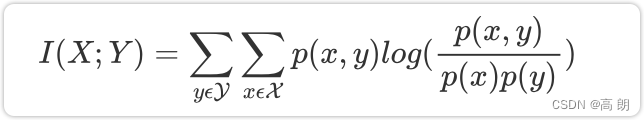


它既可以做回归也可以做分类,并且包含两个类
feature_selection.mutual_info_classif(互信息分类)和
feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。
互信息法不返回p值或F值类似的统计量,它返回“每个特征与目标之间的互信息量的估计”,这个估计量在[0,1]之间取值,为0则表示两个变量独立,为1则表示两个变量完全相关。
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y)
小结
现实中:先使用方差过滤,然后使用互信息法来捕捉相关性。
| 类 | 说明 | 超参数的选择 |
|---|---|---|
| VarianceThreshold | 方差过滤,可输入方差阈值,返回方差大于阈值的新特征矩阵 | 看具体数据究竟是含有更多噪声还是更多有效特征一般就使用0或1来筛选也可以画学习曲线或取中位数跑模型来帮助确认 |
| SelectKBest | 用来选取K个统计量结果最佳的特征,生成符合统计量要求的新特征矩阵 | 看配合使用的统计量 |
| chi2 | 卡方检验,专用于分类算法,捕捉相关性 | 追求p小于显著性水平的特征 |
| f_classif | F检验分类,只能捕捉线性相关性要求数据服从正态分布 | 追求p小于显著性水平的特征 |
| f_regression | F检验回归,只能捕捉线性相关性要求数据服从正态分布 | 追求p小于显著性水平的特征 |
| mutual_info_classif | 互信息分类,可以捕捉任何相关性不能用于稀疏矩阵 | 追求互信息估计大于0的特征 |
| mutual_info_regression | 互信息回归,可以捕捉任何相关性不能用于稀疏矩阵 | 追求互信息估计大于0的特征 |
嵌入法(Embedded)
特征选择被嵌入进学习器训练过程中,得到各个特征的权值系数,根据权值系数从大到小选择特征。
SelectFromModel是一个元变换器,可以与任何在拟合后具有coef_,feature_importances_属性或参数中可选惩罚项的评估器一起使用(比如随机森林和树模型就具有属性feature_importances_,逻辑回归就带有Ll和L2惩罚项,线性支持向量机也支持l2惩罚项)。
对于有feature_importances_的模型来说,若重要性低于提供的阈值参数,则认为这些特征不重要并被移除。
feature_importances_的取值范围是[0,1],如果设置阈值很小,比如0.001,就可以删除那些对标签预测完全没贡献的特征。如果设置得很接近1,可能只有一两个特征能够被留下。
参数:
- estimator:使用的模型评估器,只要是带feature_importances_或者coef_属性,或带有L1和L2惩罚项的模型都可以使用。
- threshold:特征重要性的阈值,重要性低于这个阈值的特征都将被删除。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators =10,random_state=0)
X_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y)
学习曲线找阈值:
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(X,y).feature_importances_
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
包装法(Wrapper)
将要使用的学习器的性能作为特征子集的评价准则,目的是为给的学习器选择“量身定做”的特征子集。
依赖于算法自身的选择,比如
coef_属性或feature_importances_属性来完成特征选择。我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。包装法在初始特征集上训练评估器,并且通过
coef_属性或通过feature_importances_属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的特征。在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。区别于过滤法和嵌入法的一次训练解决所有问题,包装法要使用特征子集进行多次训练,因此它所需要的计算成本是最高的。
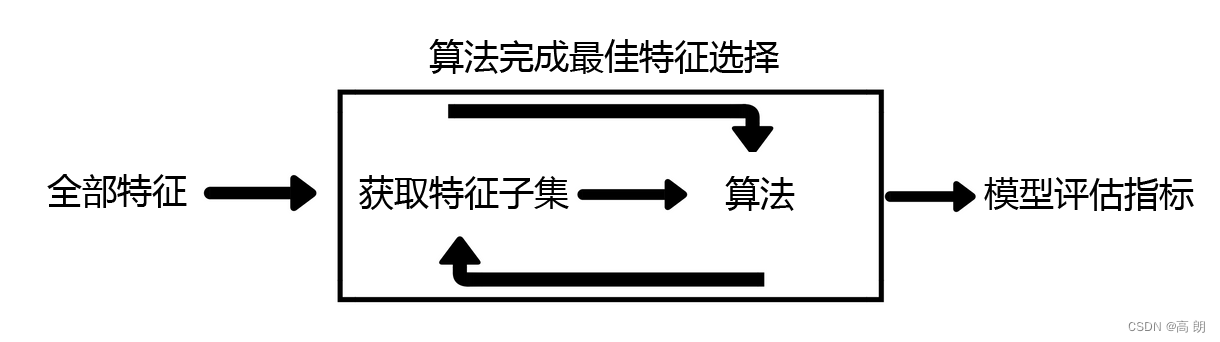
在这个图中的“算法”,指的不是我们最终用来导入数据的分类或回归算法(即不是随机森林),而是专业的数据挖掘算法,即我们的目标函数。这些数据挖掘算法的核心功能就是选取最佳特征子集。
最典型的目标函数是递归特征消除法(Recursive feature elimination, 简写为RFE)。它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。 它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。 然后,它根据自己保留或剔除特征的顺序来对特征进行排名,最终选出一个最佳子集。包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。除此之外,在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更见缓慢,所以也不适用于太大型的数据。相比之下,包装法是最能保证模型效果的特征选择方法。
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators =10,random_state=0)
selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X, y)
![[Vue]之Jwt的入门和Jwt工具类的使用及Jwt集成spa项目](https://img-blog.csdnimg.cn/4e618115b3b7456baa15dd7a15dfa326.gif)