目录
一、部署 prometheus 环境
1.1 下载安装包
1.2 解压安装
1.3 修改配置文件
1.3.1 hadoop-env.sh
1.3.2 prometheus_config.yml
1.3.3 zkServer.sh
1.3.4 prometheus_zookeeper.yaml
1.3.5 alertmanager.yml
1.3.6 prometheus.yml
1.3.7 config.yml
1.3.8 template.tmpl
1.3.9 告警规则
1.3.10 /etc/profile
1.3.11 prometheus_spark.yml
1.3.12 spark-env.sh
1.3.13 hive
1.3.14 prometheus_metastore.yaml、prometheus_hs2.yaml
1.4 创建 systemd 服务
1.4.1 创建 prometheus 用户
1.4.2 alertmanager.service
1.4.3 prometheus.service
1.4.4 node_exporter.service
1.4.5 pushgateway.service
1.4.6 grafana.service
1.5 启动服务
二、补充
2.1 告警规则和 grafana 仪表盘文件下载
2.2 服务进程监控脚本
2.2.1 prometheus-webhook-dingtalk
2.2.2 hive
2.2.3 日志切割
2.3 常用命令
2.4 参考文档
2.5 内网环境
2.5.1 nginx(公网)
2.5.2 config
2.5.3 /etc/hosts
Hadoop 集群规模:Hadoop YARN HA 集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
Spark 集群规模:Spark-3.2.4 高可用集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
| IP | 主机名 | 运行角色 |
| 192.168.170.136 | hadoop01 | namenode datanode resourcemanager nodemanager JournalNode DFSZKFailoverController QuorumPeerMain spark hive |
| 192.168.170.137 | hadoop02 | namenode datanode resourcemanager nodemanager JournalNode DFSZKFailoverController QuorumPeerMain spark |
| 192.168.170.138 | hadoop03 | datanode nodemanage JournalNode QuorumPeerMain spark |
一、部署 prometheus 环境
1.1 下载安装包
-
prometheus、alertmanager、pushgateway、node_exporter:https://prometheus.io/download/
-
prometheus-webhook-dingtalk:https://github.com/timonwong/prometheus-webhook-dingtalk/tree/main
-
grafana:https://grafana.com/grafana/download
-
jmx_exporter:https://github.com/prometheus/jmx_exporter

1.2 解压安装
新建一个 /monitor 目录,把上面下载的 tar.gz 包都解压安装在 /monitor 目录下,并重命名如下名字:

1.3 修改配置文件
1.3.1 hadoop-env.sh
修改完后要把这个文件 scp 给各个 Hadoop 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hadoop-env.sh
if ! grep -q <<<"$HDFS_NAMENODE_OPTS" jmx_prometheus_javaagent; then
HDFS_NAMENODE_OPTS="$HDFS_NAMENODE_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30002:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_DATANODE_OPTS" jmx_prometheus_javaagent; then
HDFS_DATANODE_OPTS="$HDFS_DATANODE_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30003:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$YARN_RESOURCEMANAGER_OPTS" jmx_prometheus_javaagent; then
YARN_RESOURCEMANAGER_OPTS="$YARN_RESOURCEMANAGER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30004:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$YARN_NODEMANAGER_OPTS" jmx_prometheus_javaagent; then
YARN_NODEMANAGER_OPTS="$YARN_NODEMANAGER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30005:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_JOURNALNODE_OPTS" jmx_prometheus_javaagent; then
HDFS_JOURNALNODE_OPTS="$HDFS_JOURNALNODE_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30006:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_ZKFC_OPTS" jmx_prometheus_javaagent; then
HDFS_ZKFC_OPTS="$HDFS_ZKFC_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30007:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_HTTPFS_OPTS" jmx_prometheus_javaagent; then
HDFS_HTTPFS_OPTS="$HDFS_HTTPFS_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30008:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$YARN_PROXYSERVER_OPTS" jmx_prometheus_javaagent; then
YARN_PROXYSERVER_OPTS="$YARN_PROXYSERVER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30009:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$MAPRED_HISTORYSERVER_OPTS" jmx_prometheus_javaagent; then
MAPRED_HISTORYSERVER_OPTS="$MAPRED_HISTORYSERVER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30010:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi1.3.2 prometheus_config.yml
修改完后要把这个文件 scp 给各个 Hadoop 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4]# vim prometheus_config.yml
rules:
- pattern: ".*"1.3.3 zkServer.sh
修改完后要把这个文件 scp 给各个 zookeeper 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/zookeeper/zookeeper-3.7.1/bin/
[root@hadoop01 /bigdata/hadoop/zookeeper/zookeeper-3.7.1/bin]# vim zkServer.sh
if [ "x$JMXLOCALONLY" = "x" ]
then
JMXLOCALONLY=false
fi
JMX_DIR="/monitor"
JVMFLAGS="$JVMFLAGS -javaagent:$JMX_DIR/jmx_prometheus_javaagent-0.19.0.jar=30011:/bigdata/hadoop/zookeeper/zookeeper-3.7.1/prometheus_zookeeper.yaml"1.3.4 prometheus_zookeeper.yaml
修改完后要把这个文件 scp 给各个 zookeeper 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/zookeeper/zookeeper-3.7.1/
[root@hadoop01 /bigdata/hadoop/zookeeper/zookeeper-3.7.1]# vim prometheus_zookeeper.yaml
rules:
- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+)><>(\\w+)"
name: "zookeeper_$2"
type: GAUGE
- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+)><>(\\w+)"
name: "zookeeper_$3"
type: GAUGE
labels:
replicaId: "$2"
- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+), name2=(\\w+)><>(Packets\\w+)"
name: "zookeeper_$4"
type: COUNTER
labels:
replicaId: "$2"
memberType: "$3"
- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+), name2=(\\w+)><>(\\w+)"
name: "zookeeper_$4"
type: GAUGE
labels:
replicaId: "$2"
memberType: "$3"
- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+), name2=(\\w+), name3=(\\w+)><>(\\w+)"
name: "zookeeper_$4_$5"
type: GAUGE
labels:
replicaId: "$2"
memberType: "$3"
- pattern: "org.apache.ZooKeeperService<name0=StandaloneServer_port(\\d+)><>(\\w+)"
type: GAUGE
name: "zookeeper_$2"
- pattern: "org.apache.ZooKeeperService<name0=StandaloneServer_port(\\d+), name1=InMemoryDataTree><>(\\w+)"
type: GAUGE
name: "zookeeper_$2"1.3.5 alertmanager.yml
[root@hadoop01 ~]# cd /monitor/alertmanager/
[root@hadoop01 /monitor/alertmanager]# ls
alertmanager alertmanager.yml amtool data LICENSE NOTICE
[root@hadoop01 /monitor/alertmanager]# vim alertmanager.yml
global:
resolve_timeout: 5m
templates:
- '/monitor/prometheus-webhook-dingtalk/contrib/templates/legacy/*.tmpl'
route:
group_by: ['job', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: 'webhook1'
receivers:
- name: 'webhook1'
webhook_configs:
- url: 'http://192.168.170.136:8060/dingtalk/webhook1/send'
send_resolved: true1.3.6 prometheus.yml
[root@hadoop01 ~]# cd /monitor/prometheus
[root@hadoop01 /monitor/prometheus]# ls
console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtool rule
[root@hadoop01 /monitor/prometheus]# vim prometheus.yml
# my global config
global:
scrape_interval: 30s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 30s # Evaluate rules every 15 seconds. The default is every 1 minute.
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.170.136:9093']
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rule/*.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: "prometheus"
scrape_interval: 30s
static_configs:
- targets: ["hadoop01:9090"]
# zookeeper 集群配置
- job_name: "zookeeper"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30011', 'hadoop02:30011', 'hadoop03:30011']
# node_exporter 配置
- job_name: "pushgatewawy"
scrape_interval: 30s
static_configs:
- targets: ["hadoop01:9091"]
# node_exporter 配置
- job_name: "node_exporter"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:9100', 'hadoop02:9100', 'hadoop03:9100']
- job_name: " namenode "
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30002', 'hadoop02:30002']
# labels:
# instance: namenode 服务器
- job_name: "datanode"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30003', 'hadoop02:30003', 'hadoop03:30003']
- job_name: "resourcemanager"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30004', 'hadoop02:30004']
- job_name: "nodemanager"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30005', 'hadoop02:30005', 'hadoop03:30005']
- job_name: "journalnode"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30006', 'hadoop02:30006', 'hadoop03:30006']
- job_name: "zkfc"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30007', 'hadoop02:30007']
- job_name: "jobhistoryserver"
scrape_interval: 30s
static_configs:
- targets: ["hadoop01:30010"]
- job_name: "spark_master"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30012', 'hadoop02:30012']
- job_name: "spark_worker"
scrape_interval: 30s
static_configs:
- targets: ['hadoop01:30013', 'hadoop02:30013', 'hadoop03:30013']
- job_name: "hive_metastore"
scrape_interval: 30s
static_configs:
- targets: ["hadoop01:30014"]
- job_name: "hive_hs2"
scrape_interval: 30s
static_configs:
- targets: ["hadoop01:30015"] 1.3.7 config.yml
[root@hadoop01 ~]# cd /monitor/prometheus-webhook-dingtalk/
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# ls
config.example.yml config.yml contrib LICENSE nohup.out prometheus-webhook-dingtalk
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# vim config.yml
## Request timeout
# timeout: 5s
## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true
## Customizable templates path
templates:
- /monitor/prometheus-webhook-dingtalk/contrib/templates/legacy/template.tmpl
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=0d6c5dc25fa3f79cf2f83c92705fe4594dcxxx
# secret for signature
secret: SECecdbfff858ab8f3195dc34b7e225fee9341bc9xxx
message:
title: '{{ template "ops.title" . }}'
text: '{{ template "ops.content" . }}'1.3.8 template.tmpl
[root@hadoop01 ~]# cd /monitor/prometheus-webhook-dingtalk/contrib/templates/legacy/
[root@hadoop01 /monitor/prometheus-webhook-dingtalk/contrib/templates/legacy]# vim template.tmpl
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.severity }}
**故障主机**: {{ .Labels.instance }}
**告警信息**: {{ .Annotations.description }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.severity }}
**故障主机**: {{ .Labels.instance }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间**: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "ops.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "ops.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ops.link.title" }}{{ template "ops.title" . }}{{ end }}
{{ define "ops.link.content" }}{{ template "ops.content" . }}{{ end }}
{{ template "ops.title" . }}
{{ template "ops.content" . }}1.3.9 告警规则
在第二点下面的文件里下载即可。
1.3.10 /etc/profile
修改完后要把这个文件 scp 给各个 Hadoop 节点!
# JDK 1.8
JAVA_HOME=/usr/java/jdk1.8.0_381
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib
export JAVA_HOME PATH CLASSPATH
# hadoop
export HADOOP_HOME=/bigdata/hadoop/server/hadoop-3.2.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# spark
export SPARK_HOME=/bigdata/spark-3.2.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PYSPARK_PYTHON=/usr/local/anaconda3/envs/pyspark/bin/python3.10
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native1.3.11 prometheus_spark.yml
修改完后要把这个文件 scp 给各个 spark 节点!
(base) [root@hadoop01 ~]# cd /bigdata/spark-3.2.4/
(base) [root@hadoop01 /bigdata/spark-3.2.4]# vim prometheus_spark.yml
rules:
# These come from the master
# Example: master.aliveWorkers
- pattern: "metrics<name=master\\.(.*), type=counters><>Value"
name: spark_master_$1
# These come from the worker
# Example: worker.coresFree
- pattern: "metrics<name=worker\\.(.*), type=counters><>Value"
name: spark_worker_$1
# These come from the application driver
# Example: app-20160809000059-0000.driver.DAGScheduler.stage.failedStages
- pattern: "metrics<name=(.*)\\.driver\\.(DAGScheduler|BlockManager|jvm)\\.(.*), type=gauges><>Value"
name: spark_driver_$2_$3
type: GAUGE
labels:
app_id: "$1"
# These come from the application driver
# Emulate timers for DAGScheduler like messagePRocessingTime
- pattern: "metrics<name=(.*)\\.driver\\.DAGScheduler\\.(.*), type=counters><>Count"
name: spark_driver_DAGScheduler_$2_total
type: COUNTER
labels:
app_id: "$1"
- pattern: "metrics<name=(.*)\\.driver\\.HiveExternalCatalog\\.(.*), type=counters><>Count"
name: spark_driver_HiveExternalCatalog_$2_total
type: COUNTER
labels:
app_id: "$1"
# These come from the application driver
# Emulate histograms for CodeGenerator
- pattern: "metrics<name=(.*)\\.driver\\.CodeGenerator\\.(.*), type=counters><>Count"
name: spark_driver_CodeGenerator_$2_total
type: COUNTER
labels:
app_id: "$1"
# These come from the application driver
# Emulate timer (keep only count attribute) plus counters for LiveListenerBus
- pattern: "metrics<name=(.*)\\.driver\\.LiveListenerBus\\.(.*), type=counters><>Count"
name: spark_driver_LiveListenerBus_$2_total
type: COUNTER
labels:
app_id: "$1"
# Get Gauge type metrics for LiveListenerBus
- pattern: "metrics<name=(.*)\\.driver\\.LiveListenerBus\\.(.*), type=gauges><>Value"
name: spark_driver_LiveListenerBus_$2
type: GAUGE
labels:
app_id: "$1"
# These come from the application driver if it's a streaming application
# Example: app-20160809000059-0000.driver.com.example.ClassName.StreamingMetrics.streaming.lastCompletedBatch_schedulingDelay
- pattern: "metrics<name=(.*)\\.driver\\.(.*)\\.StreamingMetrics\\.streaming\\.(.*), type=gauges><>Value"
name: spark_driver_streaming_$3
labels:
app_id: "$1"
app_name: "$2"
# These come from the application driver if it's a structured streaming application
# Example: app-20160809000059-0000.driver.spark.streaming.QueryName.inputRate-total
- pattern: "metrics<name=(.*)\\.driver\\.spark\\.streaming\\.(.*)\\.(.*), type=gauges><>Value"
name: spark_driver_structured_streaming_$3
labels:
app_id: "$1"
query_name: "$2"
# These come from the application executors
# Examples:
# app-20160809000059-0000.0.executor.threadpool.activeTasks (value)
# app-20160809000059-0000.0.executor.JvmGCtime (counter)
# filesystem metrics are declared as gauge metrics, but are actually counters
- pattern: "metrics<name=(.*)\\.(.*)\\.executor\\.filesystem\\.(.*), type=gauges><>Value"
name: spark_executor_filesystem_$3_total
type: COUNTER
labels:
app_id: "$1"
executor_id: "$2"
- pattern: "metrics<name=(.*)\\.(.*)\\.executor\\.(.*), type=gauges><>Value"
name: spark_executor_$3
type: GAUGE
labels:
app_id: "$1"
executor_id: "$2"
- pattern: "metrics<name=(.*)\\.(.*)\\.executor\\.(.*), type=counters><>Count"
name: spark_executor_$3_total
type: COUNTER
labels:
app_id: "$1"
executor_id: "$2"
- pattern: "metrics<name=(.*)\\.(.*)\\.ExecutorMetrics\\.(.*), type=gauges><>Value"
name: spark_executor_$3
type: GAUGE
labels:
app_id: "$1"
executor_id: "$2"
# These come from the application executors
# Example: app-20160809000059-0000.0.jvm.threadpool.activeTasks
- pattern: "metrics<name=(.*)\\.([0-9]+)\\.(jvm|NettyBlockTransfer)\\.(.*), type=gauges><>Value"
name: spark_executor_$3_$4
type: GAUGE
labels:
app_id: "$1"
executor_id: "$2"
- pattern: "metrics<name=(.*)\\.([0-9]+)\\.HiveExternalCatalog\\.(.*), type=counters><>Count"
name: spark_executor_HiveExternalCatalog_$3_total
type: COUNTER
labels:
app_id: "$1"
executor_id: "$2"
# These come from the application driver
# Emulate histograms for CodeGenerator
- pattern: "metrics<name=(.*)\\.([0-9]+)\\.CodeGenerator\\.(.*), type=counters><>Count"
name: spark_executor_CodeGenerator_$3_total
type: COUNTER
labels:
app_id: "$1"
executor_id: "$2"1.3.12 spark-env.sh
修改完后要把这个文件 scp 给各个 spark 节点!
(base) [root@hadoop01 ~]# cd /bigdata/spark-3.2.4/conf/
(base) [root@hadoop01 /bigdata/spark-3.2.4/conf]# vim spark-env.sh
export SPARK_MASTER_OPTS="$SPARK_MASTER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30012:/bigdata/spark-3.2.4/prometheus_spark.yml"
export SPARK_WORKER_OPTS="$SPARK_WORKER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30013:/bigdata/spark-3.2.4/prometheus_spark.yml"1.3.13 hive
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim bin/hive
···
if [[ "$SERVICE" =~ ^(help|version|orcfiledump|rcfilecat|schemaTool|cleardanglingscratchdir|metastore|beeline|llapstatus|llap)$ ]] ; then
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30014:/bigdata/apache-hive-3.1.2/prometheus_metastore.yaml"
SKIP_HBASECP=true
fi
···
if [[ "$SERVICE" =~ ^(hiveserver2|beeline|cli)$ ]] ; then
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30015:/bigdata/apache-hive-3.1.2/prometheus_hs2.yaml"
# If process is backgrounded, don't change terminal settings
if [[ ( ! $(ps -o stat= -p $$) =~ "+" ) && ! ( -p /dev/stdin ) && ( ! $(ps -o tty= -p $$) =~ "?" ) ]]; then
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Djline.terminal=jline.UnsupportedTerminal"
fi
fi
···1.3.14 prometheus_metastore.yaml、prometheus_hs2.yaml
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim prometheus_metastore.yaml
---
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
rules:
- pattern: ".*"
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim prometheus_hs2.yaml
---
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
rules:
- pattern: ".*"1.4 创建 systemd 服务
1.4.1 创建 prometheus 用户
各个节点都需要创建!!!(也可以不创建 prometheus 用户,把后面 service 文件的 prometheus 改为 root 即可!)
useradd -M -s /usr/sbin/nologin prometheus
chown -R prometheus:prometheus /monitor1.4.2 alertmanager.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
Documentation=https://prometheus.io/docs/alerting/alertmanager/
After=network-online.target
Wants=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/monitor/alertmanager/alertmanager \
--config.file=/monitor/alertmanager/alertmanager.yml \
--storage.path=/monitor/alertmanager/data \
--web.listen-address=0.0.0.0:9093
ExecReload=/bin/kill -HUP $MAINPID
Restart=always
[Install]
WantedBy=multi-user.target1.4.3 prometheus.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/monitor/prometheus
ExecStart=/monitor/prometheus/prometheus \
--web.listen-address=0.0.0.0:9090 \
--storage.tsdb.path=/monitor/prometheus/data \
--storage.tsdb.retention.time=30d \
--config.file=prometheus.yml \
--web.enable-lifecycle
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target1.4.4 node_exporter.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
Documentation=https://github.com/prometheus/node_exporter
After=network-online.target
Wants=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/monitor/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target1.4.5 pushgateway.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/pushgateway.service
[Unit]
Description=Pushgateway Server
Documentation=https://github.com/prometheus/pushgateway
After=network-online.target
Wants=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/monitor/pushgateway/pushgateway \
--web.listen-address=:9091 \
--web.telemetry-path=/metrics
Restart=always
[Install]
WantedBy=multi-user.target1.4.6 grafana.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/grafana.service
[Unit]
Description=Grafana Server
Documentation=http://docs.grafana.org
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
User=prometheus
Group=prometheus
ExecStart=/monitor/grafana/bin/grafana-server \
--config=/monitor/grafana/conf/defaults.ini \
--homepath=/monitor/grafana
Restart=on-failure
RestartSec=10
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=grafana
Environment=GRAFANA_HOME=/monitor/grafana \
GRAFANA_USER=prometheus \
GRAFANA_GROUP=prometheus
[Install]
WantedBy=multi-user.target1.5 启动服务
把上述服务启动即可!
注意:prometheus-webhook-dingtalk 服务需要用下面方式启动:
cd /monitor/prometheus-webhook-dingtalk/
nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --config.file="/monitor/prometheus-webhook-dingtalk/config.yml" &二、补充
2.1 告警规则和 grafana 仪表盘文件下载
[root@hadoop01 ~]# cd /monitor/prometheus/
[root@hadoop01 /monitor/prometheus]# ls
console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtool rule
[root@hadoop01 /monitor/prometheus]# ls rule/
HDFS.yml node.yml spark_master.yml spark_worker.yml yarn.yml zookeeper.yml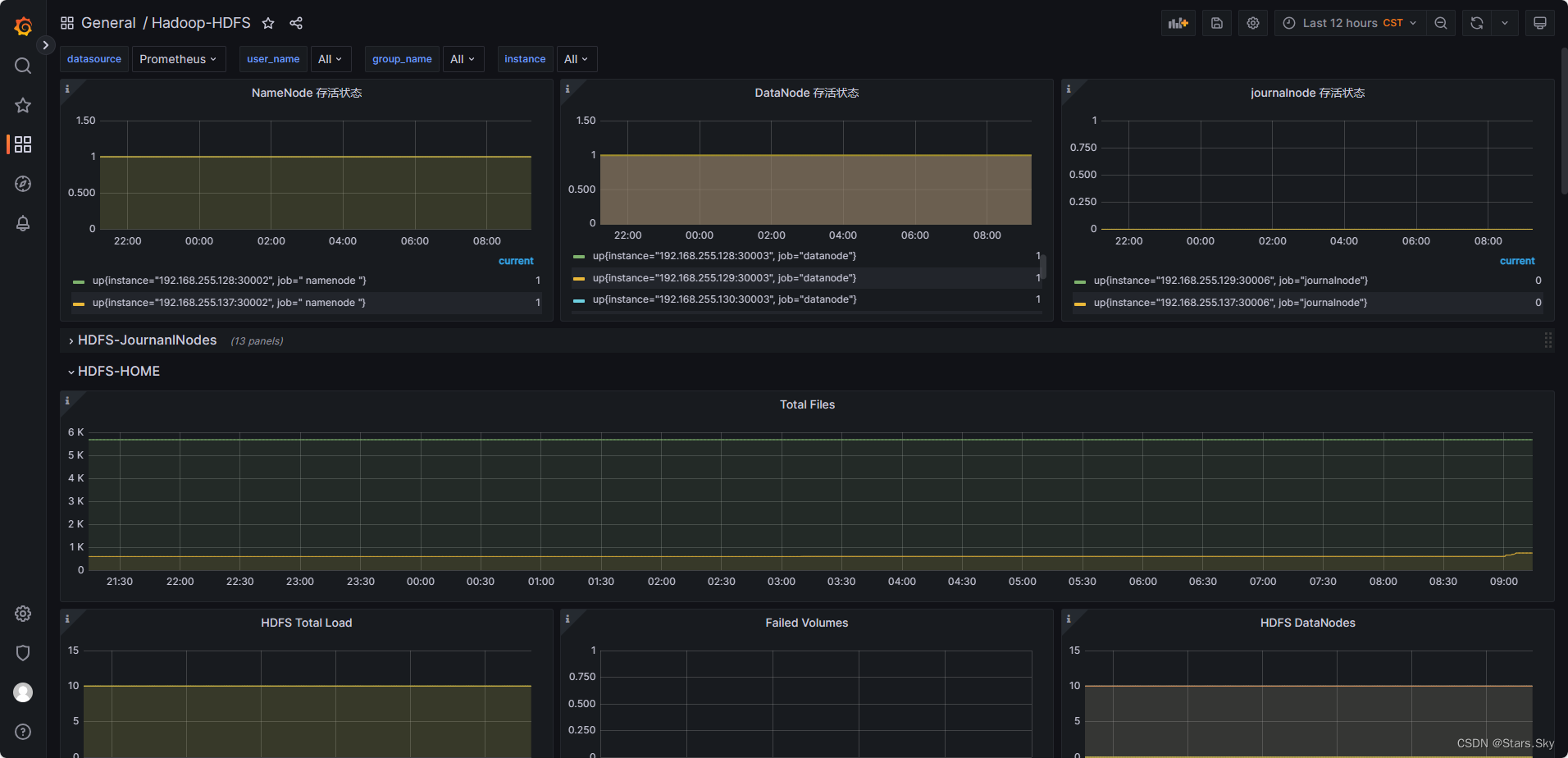
文件下载链接:【免费】prometheus告警规则文件和grafana仪表盘文件资源-CSDN文库
2.2 服务进程监控脚本
2.2.1 prometheus-webhook-dingtalk
[root@hadoop01 ~]# cd /monitor/prometheus-webhook-dingtalk/
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# vim monitor_prometheus_webhook_dingtalk.sh
#!/bin/bash
# 获取当前系统时间
current_time=$(date "+%Y-%m-%d %H:%M:%S")
# 定义日志文件路径
log_file="/monitor/prometheus-webhook-dingtalk/monitor.log"
echo "[$current_time] Checking if prometheus-webhook-dingtalk process is running..." >> $log_file
# 检查进程是否在运行
if ! /usr/bin/pgrep -fx "/monitor/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --web.listen-address=0.0.0.0:8060 --config.file=/monitor/prometheus-webhook-dingtalk/config.yml" >> $log_file; then
echo "[$current_time] prometheus-webhook-dingtalk process is not running. Starting it now..." >> $log_file
# 使用绝对路径和 nohup 在后台启动进程
/usr/bin/nohup /monitor/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --config.file="/monitor/prometheus-webhook-dingtalk/config.yml" >> /monitor/prometheus-webhook-dingtalk/output.log 2>&1 &
else
echo "[$current_time] prometheus-webhook-dingtalk process is running." >> $log_file
fi
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# chmod 777 monitor_prometheus_webhook_dingtalk.sh
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# crontab -e
* * * * * /usr/bin/bash /monitor/prometheus-webhook-dingtalk/monitor_prometheus_webhook_dingtalk.sh2.2.2 hive
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim monitor_hive.sh
#!/bin/bash
# 获取当前系统时间
current_time=$(date "+%Y-%m-%d %H:%M:%S")
# 定义日志文件路径
log_file_metastore="/bigdata/apache-hive-3.1.2/monitor_metastore.log"
log_file_hs2="/bigdata/apache-hive-3.1.2/monitor_hs2.log"
echo "[$current_time] Checking if hive metastore and hs2 processes are running..."
# 检查 Hive Metastore 是否在运行
echo "[$current_time] Checking if hive metastore process is running..." >> $log_file_metastore
if ! /usr/bin/pgrep -f "hive-metastore-3.1.2.jar" >> $log_file_metastore; then
echo "[$current_time] hive metastore process is not running. Starting it now..." >> $log_file_metastore
# 使用绝对路径和 nohup 在后台启动进程
/usr/bin/nohup /bigdata/apache-hive-3.1.2/bin/hive --service metastore >> /bigdata/apache-hive-3.1.2/metastore_output.log 2>&1 &
# 等待一点时间以确保 metastore 完全启动
sleep 30
else
echo "[$current_time] hive metastore process is running." >> $log_file_metastore
fi
# 检查 HiveServer2 是否在运行
echo "[$current_time] Checking if hive hs2 process is running..." >> $log_file_hs2
if ! /usr/bin/pgrep -f "HiveServer2" >> $log_file_hs2; then
echo "[$current_time] hive hs2 process is not running. Starting it now..." >> $log_file_hs2
# 使用绝对路径和 nohup 在后台启动进程
/usr/bin/nohup /bigdata/apache-hive-3.1.2/bin/hive --service hiveserver2 >> /bigdata/apache-hive-3.1.2/hs2_output.log 2>&1 &
else
echo "[$current_time] hive hs2 process is running." >> $log_file_hs2
fi
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# chmod 777 montior_metastore.sh
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# crontab -e
* * * * * /usr/bin/bash /bigdata/apache-hive-3.1.2/monitor_hive.sh2.2.3 日志切割
[root@hadoop01 ~]# vim /etc/logrotate.d/prometheus-webhook-dingtalk
/monitor/prometheus-webhook-dingtalk/monitor.log \
/bigdata/apache-hive-3.1.2/monitor_metastore.log \
/bigdata/apache-hive-3.1.2/monitor_hs2.log {
daily
rotate 7
size 150M
compress
maxage 30
missingok
notifempty
create 0644 root root
copytruncate
}
# 测试调式 logrotate 配置
[root@hadoop01 ~]# logrotate -d /etc/logrotate.d/prometheus-webhook-dingtalk
# 手动执行日志轮换
logrotate -f /etc/logrotate.d/prometheus-webhook-dingtalk2.3 常用命令
# 检查 prometheus 配置文件,包括告警规则文件
[root@hadoop01 ~]# cd /monitor/prometheus
./promtool check config prometheus.yml
# 重启 prometheus 配置
curl -X POST http://localhost:9090/-/reload
# 测试发送信息到机器人
curl 'https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text","text": {"content":"我就是我, 是不一样的烟火"}}'2.4 参考文档
-
Hadoop 官方监控指标:https://hadoop.apache.org/docs/r3.2.4/hadoop-project-dist/hadoop-common/Metrics.html
-
阿里云监控指标:https://help.aliyun.com/zh/emr/emr-on-ecs/user-guide/hdfs-metrics?spm=a2c4g.11186623.0.0.11ba6daalnmBWn
-
阿里云 grafana 仪表盘:https://help.aliyun.com/document_detail/2326798.html?spm=a2c4g.462292.0.0.4c4c5d35uXCP6k#section-1bn-bzq-fw3
-
jmx_exporter 配置文件参考:https://github.com/prometheus/jmx_exporter/tree/main/example_configs
-
钉钉机器人文档:https://open.dingtalk.com/document/robots/custom-robot-access
2.5 内网环境
2.5.1 nginx(公网)
需要一台可以访问公网的 nginx 服务器来代理钉钉 api:
[root@idc-master-02 ~]# cat /etc/nginx/conf.d/uat-prometheus-webhook-dingtalk.conf
server {
listen 30080;
location /robot/send {
proxy_pass https://oapi.dingtalk.com;
proxy_set_header Host oapi.dingtalk.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}2.5.2 config
[root@localhost-13 ~]# cat /opt/prometheus-webhook-dingtalk/config.yml
targets:
webhook1:
url: http://10.0.4.11:30080/robot/send?access_token=0d6c5dc25fa3f79cf2f83c92705fe4594dcc5b3xxx
secret: SECecdbfff858ab8f3195dc34b7e225fee93xxx
message:
title: '{{ template "ops.title" . }}'
text: '{{ template "ops.content" . }}'2.5.3 /etc/hosts
[root@localhost-13 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.4.11 oapi.dingtalk.com