语义分割网络纯 TRF 结构:VIT主干作为编码器,设计一个基于 TRF 架构的解码器。
今天学习swin transformer
源码地址: https://github.com/microsoft/Swin-Transform
哔哩哔哩讲解:12.1 Swin-Transformer网络结构详解_哔哩哔哩_bilibili
博文地址:Swin-Transformer网络结构详解_swin transformer-CSDN博客
up主的github地址:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
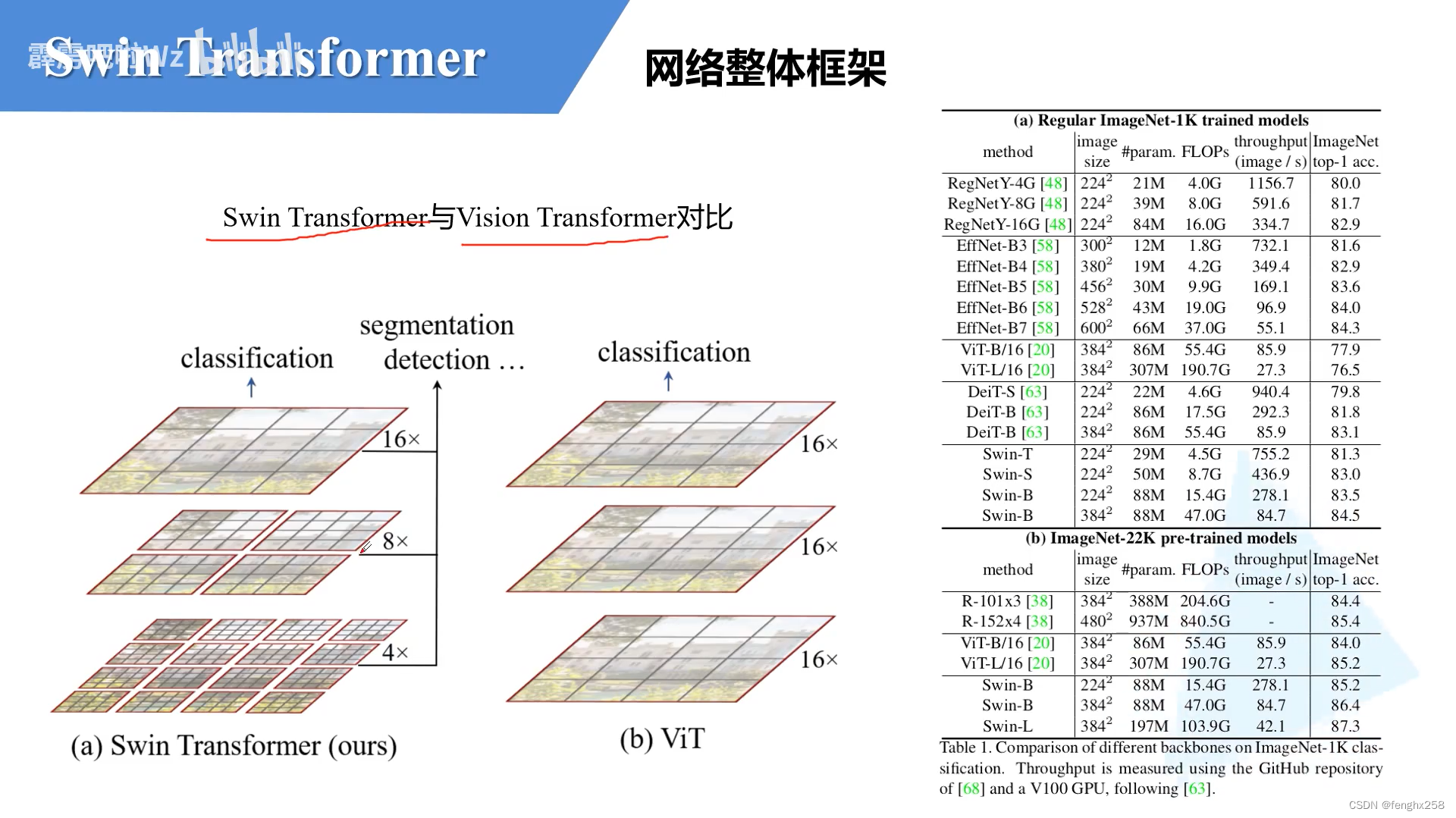
对比:下采样不一样;窗口分割
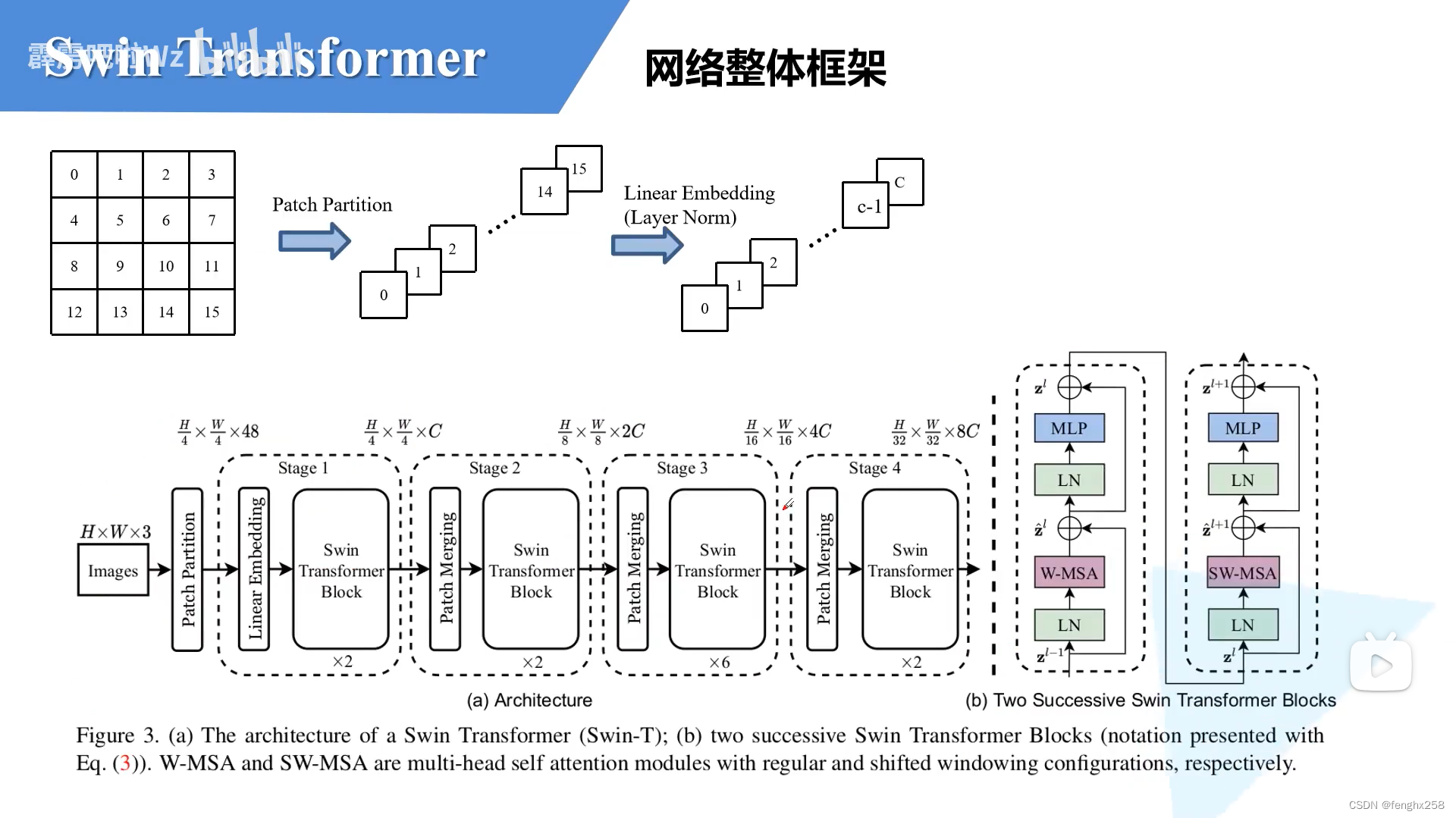
卷积完成以下操作:48个卷积核为4*4,步长为4的进行卷积(听到这发现不太懂,回到了这一步学习Vision Transformer详解-CSDN博客)
通过Patch Partition ,图像宽高缩减为1/4,通道变为48(16个patch*3个通道)
通过Linear embedding (Layer Norm),图像channel变为C
然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样(后面会细讲)。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数(因为成对使用)。
图(表7)是原论文中给出的关于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large),其中:
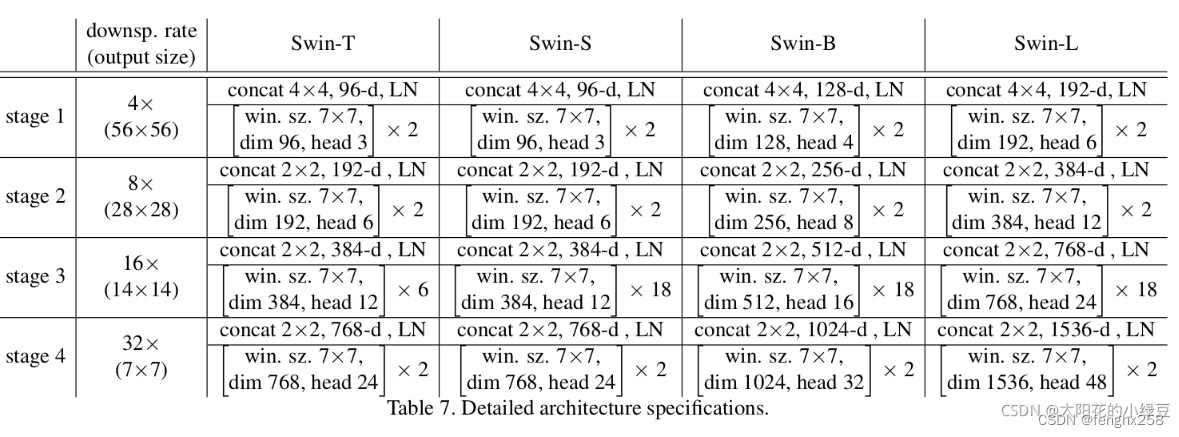
win. sz. 7x7表示使用的窗口(Windows)的大小
dim表示feature map的channel深度(或者说token的向量长度)
head表示多头注意力模块中head的个数
最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。图中没有画,但源码中是这样做的。
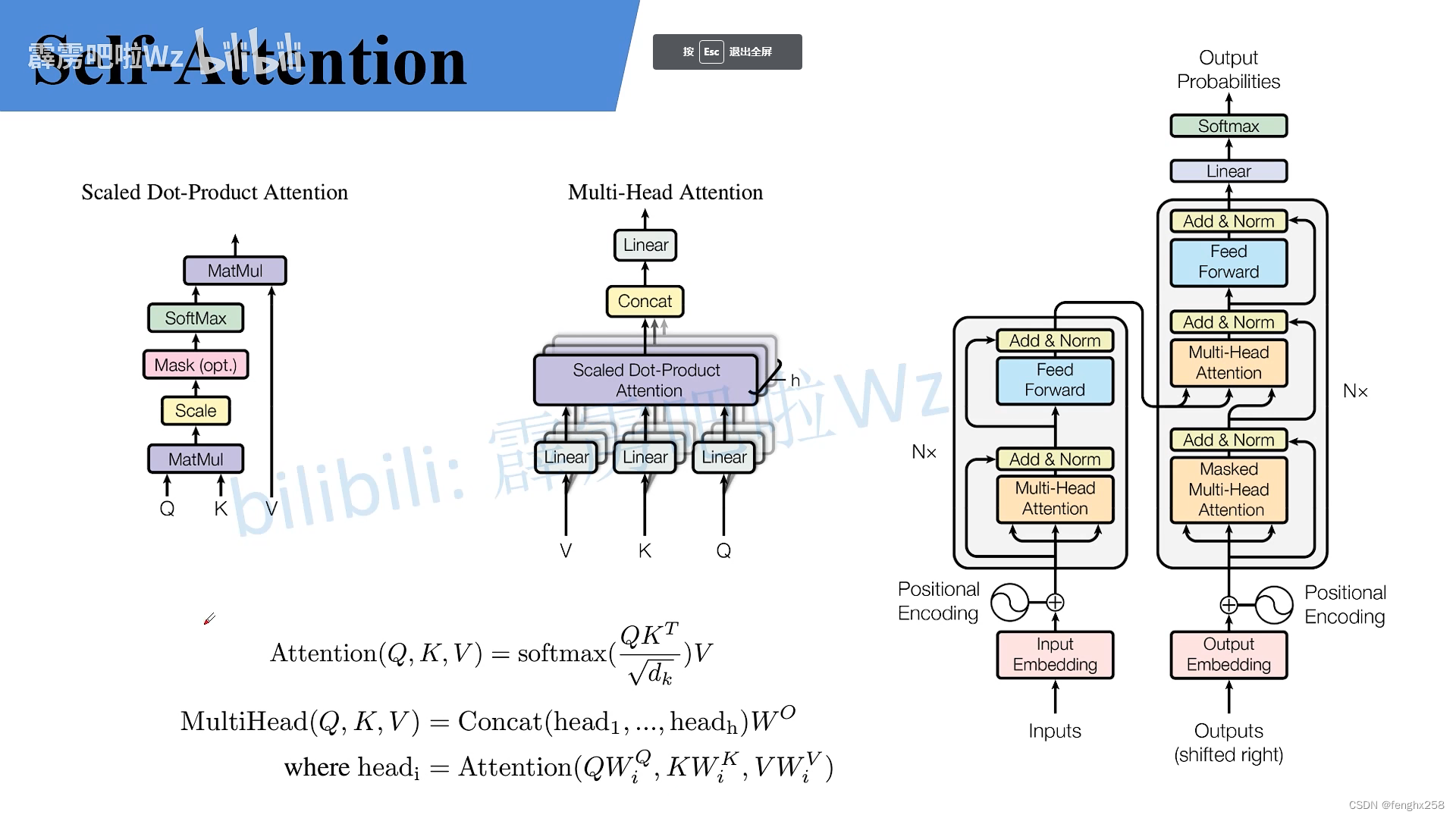
Multi-Head Attention
Transformer中Self-Attention以及Multi-Head Attention详解_哔哩哔哩_bilibili